
Abstract
Seismologists are increasingly adopting data mining and machine learning techniques to detect weak earthquake signals in large seismic data sets. The detection performance of these new methods, especially their sensitivity and false detection rate, depends on the choice of feature representation for waveform data. We have previously introduced Fingerprint and Similarity Thresholding (FAST), a new method for waveform-similarity-based earthquake detection that uses a pattern mining approach to detect earthquake signals without template waveforms. FAST has two key steps: fingerprint extraction and efficient indexing for similarity search. In this work, we focus on FAST fingerprint extraction: the method used to map short-duration waveforms to a set of features, called waveform fingerprints, used for detection. We describe the FAST fingerprint extraction method, a data-adaptive variation on the Waveprint audio fingerprinting method tailored for use in continuous seismic data. We compare the performance of the FAST fingerprint extraction method with existing fingerprinting techniques designed for audio identification. To overcome the challenges associated with using limited or incomplete event catalogs to evaluate detection algorithms, we propose a framework for quantifying the performance of different fingerprint extraction methods in the context of blind similarity-based detection. Our framework uses computational experiments on benchmark data sets, constructed with known event waveforms, to compute a measure of fingerprint effectiveness. We use this framework to show that, among the audio fingerprinting schemes considered in this work, our proposed FAST fingerprint extraction method achieves the most consistent performance in distinguishing similar, low signal-to-noise earthquake waveforms from noise in waveform data sets from eight stations in the Northern California Seismic Network.











Similar content being viewed by others


Notes
FAST code available at https://github.com/stanford-futuredata/FAST.
References
Alías, F., Socoró, J. C., & Sevillano, X. (2016). A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Applied Sciences, 6(5), 143.
Allen, R. (1982). Automatic phase pickers: Their present use and future prospects. Bulletin of the Seismological Society of America, 72(6B), S225–S242.
Andoni, A., & Indyk, P. (2006). Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. In Foundations of Computer Science, 2006. FOCS’06. 47th Annual IEEE Symposium on, (pp. 459–468). IEEE.
Baluja, S., & Covell, M. (2008). Waveprint: Efficient wavelet-based audio fingerprinting. Pattern Recognition, 41(11), 3467–3480.
Bengio, Y., Courville, A., & Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1798–1828.
Bentley, J. L. (1975). Multidimensional binary search trees used for associative searching. Communications of the ACM, 18(9), 509–517.
Bergen, K., Yoon, C., & Beroza, G. C. (2016). Scalable similarity search in seismology: a new approach to large-scale earthquake detection. In International Conference on Similarity Search and Applications (pp. 301–308). Springer, Cham.
Bergen, K. J. (2018). Big Data for Small Earthquakes: Detecting Earthquakes over a Seismic Network with Waveform Similarity Search. PhD thesis, Stanford University, Stanford, CA.
Bergen, K. J., & Beroza, G. C. (2018). Detecting earthquakes over a seismic network using single-station similarity measures. Geophysical Journal International, 213(3), 1984–1998. https://doi.org/10.1093/gji/ggy100.
Beyreuther, M., Barsch, R., Krischer, L., Megies, T., Behr, Y., & Wassermann, J. (2010). ObsPy: A Python toolbox for seismology. Seismological Research Letters, 81(3), 530–533.
Bradley, A. P. (1997). The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition, 30(7), 1145–1159.
Broder, A. Z. (1993). Some applications of Rabin’s fingerprinting method. In Sequences II, (pp. 143–152). Springer.
Broder, A.Z. (1997). On the resemblance and containment of documents. In Compression and Complexity of Sequences 1997. Proceedings, (pp. 21–29). IEEE.
Cano, P., Batlle, E., Kalker, T., & Haitsma, J. (2005). A review of audio fingerprinting. Journal of VLSI Signal Processing Systems for Signal, Image, and Video Technology, 41(3 SPEC. ISS.), 271–284.
Datar, M., Immorlica, N., Indyk, P., & Mirrokni, V. S. (2004). Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the twentieth annual symposium on computational geometry, (pp. 253–262). ACM.
Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer, T. K., & Harshman, R. (1990). Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41(6), 391.
Díaz, J., Ruiz, M., Sánchez-Pastor, P. S., & Romero, P. (2017). Urban seismology: On the origin of earth vibrations within a city. Scientific Reports, 7(1), 15296.
Donoho, D. L., & Johnstone, J. M. (1994). Ideal spatial adaptation by wavelet shrinkage. Biometrika, 81(3), 425–455.
Gibbons, S. J., & Ringdal, F. (2006). The detection of low magnitude seismic events using array-based waveform correlation. Geophysical Journal International, 165(1), 149–166.
Haitsma, J., & Kalker, T. (2002). A highly robust audio fingerprinting system. Proceedings of the 3rd international society for music information retrieval conference (ISMIR02), (pp. 107–115).
Hampel, F. R. (1974). The influence curve and its role in robust estimation. Journal of the American Statistical Association, 69(346), 383–393.
He, H., & Garcia, E. A. (2009). Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 21(9), 1263–1284.
Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504–507.
Holtzman, B. K., Paté, A., Paisley, J., Waldhauser, F., & Repetto, D. (2018). Machine learning reveals cyclic changes in seismic source spectra in Geysers geothermal field. Science Advances, 4(5), eaao2929.
Lee, D. D., & Seung, H. S. (1999). Learning the parts of objects by non-negative matrix factorization. Nature, 401(6755), 788.
Lee, H., Battle, A., Raina, R., & Ng, A. Y. (2007). Efficient sparse coding algorithms. In Advances in neural information processing systems, (pp. 801–808).
Leskovec, J., Rajaraman, A., & Ullman, J. D. (2014). Mining of massive datasets (2nd ed.). New York, NY, USA: Cambridge University Press.
Mallat, S. (2008). A wavelet tour of signal processing: the sparse way. Cambridge: Academic press.
Manber, U. (1994). Finding similar files in a large file system. In USENIX Winter 1994 Technical Conference, (pp. 1–10).
Meng, H. & Ben-Zion, Y. (2018). Characteristics of airplanes and helicopters recorded by a dense seismic array near Anza California. Journal of Geophysical Research: Solid Earth. https://doi.org/10.1029/2017JB015240.
NCEDC. (2014). Northern California Earthquake Data Center. UC Berkeley Seismological Laboratory. Dataset. https://doi.org/10.7932/NCEDC.
Pankanti, S., Prabhakar, S., & Jain, A. K. (2002). On the individuality of fingerprints. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(8), 1010–1025.
Perol, T., Gharbi, M., & Denolle, M. (2018). Convolutional neural network for earthquake detection and location. Science Advances, 4(2), e1700578.
Rong, K., Yoon, C. E., Bergen, K. J., Elezabi, H., Bailis, P., Levis, P., et al. (2018). Locality-sensitive hashing for earthquake detection: A case study of scaling data-driven science. Proceedings of the VLDB Endowment, 11(11), 1674–1687.
Valentine, A. P., & Trampert, J. (2012). Data space reduction, quality assessment and searching of seismograms: Autoencoder networks for waveform data. Geophysical Journal International, 189(2), 1183–1202.
Wang, A. (2003). An industrial strength audio search algorithm. In ISMIR, Vol. 2003, (pp. 7–13). Washington, DC.
Wang, A. (2006). The Shazam music recognition service. Communications of the ACM, 49(8), 44–48.
Wang, J., Kumar, S., & Chang, S. -F. (2010). Semi-supervised hashing for scalable image retrieval. In Computer vision and pattern recognition (CVPR), 2010 IEEE conference on, (pp. 3424–3431). IEEE.
Wang, J., Shen, H.T., Song, J., & Ji, J. (2014). Hashing for similarity search: A survey. ar**v preprint ar**v:1408.2927.
Wang, J., Zhang, T., Song, J., Sebe, N., & Shen, H. T. (2018). A survey on learning to hash. IEEE Transactions on Pattern Analysis and Machine Intelligence, PP(99):1–1.
Weiss, Y., Torralba, A., & Fergus, R. (2009). Spectral hashing. In Advances in neural information processing systems, (pp. 1753–1760).
Willett, P., Barnard, J. M., & Downs, G. M. (1998). Chemical similarity searching. Journal of Chemical Information and Computer Sciences, 38(6), 983–996.
Yoon, C. E., O'Reilly, O., Bergen, K. J., & Beroza, G. C. (2015). Earthquake detection through computationally efficient similarity search. Science Advances, 1(11), e1501057.
Acknowledgements
This research is supported by National Science Foundation Grants EAR-1551462 and EAR-1818579. Computing resources were provided by the Center for Computational Earth and Environmental Science, Stanford University. Waveform data, metadata, or data products for this study were accessed through the Northern California Earthquake Data Center (NCEDC 2014). The ObsPy Python toolbox (Beyreuther et al. 2010) was used to retrieve and process waveform data.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Signal-to-Noise Ratio
In this work, the signal-to-noise ratio (SNR) is computed using a 15-s interval of waveform data following the P-wave arrival. For signal x and noise n, each of duration \(M = 300\) samples (15 s of data sampled at 20 samples per second), the SNR is given by:
1.2 Noise Segment Classification
Noise segments are assigned one of these three labels based on two criteria: (1) an STA/LTA threshold, and (2) a uniform energy criterion that quantifies how uniform the energy is across the 2-min interval. A noise segment is labeled as “clean” noise if the maximum STA/LTA ratio in the interval is below 3.0 and the uniform energy score is below 0.1. A noise segment is labeled as “non-noise” if the maximum STA/LTA ratio in the interval exceeds 6.0 or the uniform energy score exceeds 0.2. All other noise segments are labeled “lively” noise. The parameters for short and long windows used in the STA/LTA ratio are 3 and 45 s, respectively. The uniform energy score, \(u^{(j)}\), associated with a noise segment \(n^{(j)}\) of length M samples is defined as:
and \(n^{(j)}\) is normalized such that \(|| n^{(j)} ||^{2}_{2} = 1\). This value represents the difference between the cumulative signal energy over the interval and the cumulative energy for a signal with uniform energy, and u takes values between 0 and 0.5, with larger values associated with larger deviations from uniform signal energy.
1.3 Events in Benchmark Data Set, by Station
The list of events in the benchmark data set and the corresponding earthquake waveform and noise data matrices, by station, are available upon request (see Figs. 12, 13).

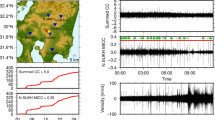
Map plots show the epicenter locations for the events in the earthquake waveform benchmark data set for stations NC.CCOB, NC.MCB, NC.GDXB, and NC.CBR. The location of each station is marked with a blue triangle, and the event epicenters are shown in red. The set of earthquakes is selected independently for each station depending on whether a P-phase arrival was recorded in the NCSN phase-pick catalog for a given event

Map plots show the epicenter locations for the events in the earthquake waveform benchmark data set for stations BK.CVS, BK.JRSC, BK.PKD, and BK.SAO. The location of each station is marked with a blue triangle, and the event epicenters are shown in red. The set of earthquakes is selected independently for each station depending on whether a P-phase arrival was recorded in the NCSN phase-pick catalog for a given event
Rights and permissions
About this article

Cite this article
Bergen, K.J., Beroza, G.C. Earthquake Fingerprints: Extracting Waveform Features for Similarity-Based Earthquake Detection. Pure Appl. Geophys. 176, 1037–1059 (2019). https://doi.org/10.1007/s00024-018-1995-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-018-1995-6