
Abstract
In high-end hospitality industries such as airline lounges, high star hotels, and high-class restaurants, employee service skills play an important role as an element of the brand identity. However, it is very difficult to train an intermediate employee into an expert employee who can provide higher value services which exceed customers’ expectations. To hire and develop employees who embody the value of the brand, it is necessary to clearly communicate the value of the brand to their employees. In the video analysis domain, especially analyzing human behaviors, an important task is the understanding and representation of human activities such as conversation, physical actions and their connections on the time. This paper addresses the problem of massively annotating video contents such as multimedia training materials, which then can be processed by human-interaction training support systems (such as VR training systems) as resources for content generation. In this paper, we propose a POC (proof of concept) system of a service skill assessing platform, which is a knowledge graph (KG) of high-end service provision videos massively annotated with human interaction semantics.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
- Video annotation
- Knowledge graph
- Behavior analysis
- Video retrieval
- Training support system
- Service excellence
1 Introduction
In high-end hospitality industries such as airline lounges, high star hotels, and high-class restaurants, employee service skills play an important role as an element of the brand identity. However, it is very difficult to train an intermediate employee who can provide the basic core value proposition specified in the manual into an expert employee who can provide higher value services which exceed customers’ expectations (Service excellence “Level 4 Surprising Service” [3]). To hire and develop people who embody the value of the brand, it is necessary to clearly communicate the value of the brand to employees. Companies are using scenario-based role-play and other customer service contests for training. However, the skills evaluated in role-play are conventionally accessible only by playing and viewing the movie selected from a huge video archive. Also, the skills evaluated depend on the context, and it is not easy to convey the evaluated points clearly to the trainees. This is a major problem for global companies when educating human resources at overseas branches and when providing education to its alliance companies where cultural background is not shared.
Recently, the video annotations have gained popularity in the area of video analysis, among the academic community as well industry for commercial applications that handles computer’s vision systems [15]. An increasing interest for understanding the actions that occur in the video clips for a wide number of applications have motivated the research in this area [18].
In the video analysis, specially analyzing human behaviors, an important task is the understanding and representation of human activities such as conversation, physical actions (pose, angle vision, spatial position in the scene, etc.). The discovery of skills, behaviors patterns or training learning base models might be computed easier by analyzing formal representations of human actions as knowledge graphs. Usually the video annotations are written manually which is a time-consuming task and requires special attention in fine details within small periods of time (scenes per second).
In this paper, we propose a POC (proof of concept) system of a service skill assessing platform, which is a knowledge graph (KG) [16] of high-end service provision videos massively annotated with human interaction semantics. The approach takes into account the conversation, physical actions, activities and skills presented in the scene. The main objective is to represent large amount of human information from a high number of video frames for further analysis and reasoning. The process of knowledge graph exploitation can be computed by ontology inferences, graph theory algorithms or machine learning (ML) techniques.
2 Related Work
Recently, a significant number of approaches addressed the problem of human activity recognition and its representation through several annotation techniques have been proposed. However, most of researches implemented machine learning (ML) techniques that in general require a large number of tagged data for their training. Acquiring large amount of labeled data has been an obstacle which these models depend their efficiency. Respect to automatic annotation on videos the work of Duchenne et al. [6] used movie scripts as a training data set but it was limited to annotated content using solely the video’s conversation. The work associated the text to the script discovering the action on the scene. One important issue was the lack of a proper video analysis of physical actions. Moreover, Kaiqiang Huang et al. [8] developed an empirical study of annotation models using machine learning and transfer model. This research presented an alternative that avoided the manual annotations in the training dataset. The works presented good performance for general and common actions. For specific cases of study many gaps could not been address though. Similarly, Fuhl et al. [7] proposed a transfer learning model for video annotation with the advantage of including a self training method that addressed the limitation of labeled image data. The algorithm achieved accurate point annotation focused mostly in eye gestures.
Regarding action recognition, the work of Das Srijan et al. [5] proposed a hybrid model with handcrafted approach (video’s frame descriptors) and machine learning. They focused primarily in action recognition instead of only objects identification, i.e., motion, pose and subject performing. The work included similar actions discrimination but the spatial-temporal processing was suggested to be explored. Additionally, Yang **ao et al. [17] proposed a CNN model for human-human and human-object interaction on dynamic image in depth videos. Whereas the works included spatial-temporal action handling. The researched mentioned the necessity of relaxing the strong requirement on training sample size.
Tackling the task of video summarization, the work of Zhang Ke et al. [19] implemented video long short-term memory for selecting automatically key frames. They introduced a technique that addressed the necessity of large amount of training data by reusing auxiliary annotated video summarization data sets.
Processing video annotation using natural language processing (NLP) and linguistic characteristics, the work of Hendricks Lisa et al. [1] localized moments (temporal segments) in the videos from natural language text descriptors. The work included temporal processing. The work integrates local and global features. The scope of the work was limited to the text descriptions.
Creation annotations as input to machine learning models, the method of **gkuan Song et al. [13] proposed a semi-supervised annotation approach for graph-based learning algorithms using partial tags (tagged and not tagged data). The work aimed to construct graphs that embed the relationships among data points in order to create image and video annotation. These annotations define concepts in the scene.
2.1 Discussion of the Related Work
Although many significant improvements have been achieved recently in video annotations and presentation, most of the research projects were focused on machine learning techniques for human action annotation missing temporal processing, representation in the semantic level and the interactions among physical behaviors and events. Nevertheless, the main disadvantage of these proposals is that they need an immense amount of tagged data for training to obtain a robust and reliable result. Moreover, many works were limited to annotated videos for specific purposes not considering external events, conversations and their connection to physical actions. In contrast, we processed and represented the video’s content for a wider range of characteristics described in a knowledge base (physical actions, skills and events). The novelty of the presented work is the conceptual-semantic representation of the human actions and skills, events occurred in the scene and their relation with other users or objects on the time. One advantage is that our approach does not need large training data set. The relation between annotations to physical behavior is straightforward captured and described through a knowledge bases and used to created video graphs.
Comparing our contribution with the related work, we processed the physical actions, comments and annotations such as skills and actions separately in the end connected as a final graph. The methodology generated relations among all the video’s components for a final representation as excerpt of knowledge. We took into account the spatial-temporal processing into the knowledge graphs.
3 Methodology
The system consists from DNN detectors and a set of service process annotation ontologies and a KG converter. The input video is splitted into image frames by the DNN detector and annotated with bounding boxes, 3D person poses information, face orientation axes, body orientation axes, and then annotated with the ontologies for what human interaction is occurring in the frame. The combined information is converted into a KG to store in a triple store for computation.
The generation of Knowledge Graph is composed from three stages. First, the video is processed in order to construct automatically its conceptual representation as knowledge graph that captures the video’s content, actions, conversations and user’s behavior of each scene. Secondly, once the knowledge graphs were created the staff’s behavior is measured and his/her customer service performance is calculated by consulting the knowledge graph. This step scores users and creates their profile. Finally, the performance of the staff members can be visualized and profiled via a skill assessing platform (Fig. 1).

System overview.
3.1 Knowledge Graph Construction
In order to generate the knowledge graph, the system processes two different sources: 1) the human skills and actions manually annotated on video files using the software ELAN [2]. For the skills and actions annotation, an ontology for skills and services in the domain of airline industry was developed [10]. 2) The physical behavior presented in the video is analyzed by machine learning techniques using Python [11] packages such as YOLO [4] and 3DMPPE multi-person 3D pose estimation [9]. After obtaining the video’s content from the previous sources the representation as knowledge graph is computed by graph theory algorithms (expansion and edges creation). As complementary, process their metadata information is also generated. For each frame a representation (knowledge graph) is created. In the end, all the sub graphs are interconnected on time lapses and stored in a graph database that provide efficient mechanism of the inclusion and extraction (see Fig. 2).

General methodology.
The main goal of this stage is to provide an automatic method for describing the video’s content and explicitly create linking among annotations, actor’s comments and their physical behaviors in the video frames. The result of the implementation (system) creates graphs that describe frames, actions, and skills on temporal domain in the conceptual level (semantic) for each video clips. Furthermore, the metadata is generated in order facilitate the retrieval and indexing of video files. It is important to mention that the annotations are based on the description of the all scenarios and human behaviors in the case of study which are stored as knowledge base (KB).
In Fig. 3 the video’s components are separately analyzed and transformed as sub graphs which in the end are joined on the time (occurrence of events).

Video clips sections analyzed.
Regarding the processing of human dialog, the comments are represented as graphs by means of lexical dependencies produced by natural language processing (NLP). Each concept that composes the comment can provide information such of context, domain or type of entity.
The general diagram that contains all the elements described in the knowledge graph are presented at the Fig. 4. The elements are grouped as: 1) video file’s general information obtained from ELAN annotation, 2) the conversations transformed to graph also generates a corpus, 3) the catalogue of actions and skills that occur in the video and 4) the video analysis of human physical activity.

General diagram knowledge graph representation.
After conducting the automatic knowledge graph creation, the methodology is able to create metadata as a graph as well. Figure 5 represents the elements considered (video’s technical information, scene’s content and summary) auto-generated for the moment only from 1) ELAN files.

Video metadata generated.
3.2 Analysis on the Knowledge Graphs
After processing the 1) video’s sources and generating their 2) formal representations, the next step is to 3) inspect the knowledge graphs stored by SPARQL queries [12]. In order to accomplish this task, the staffs’ skills, conversation and actions are analyzed using metrics that measure the level of expertise.
In order to assign a score to users, several metrics were taken into account. In our case study the metrics considered are: 1) in the conversation for instance; if the staff member mentions the customer’s name. 2) The action and activities that correspond to the correct service (understanding in requesting a flight cancellation). 3) Physical behaviors such as bowing (Japanese polite manners) and talk in direction to the customer.
As result of this process, the excellence of service deployed by the employees (namely, company representatives) can be explicitly assessed and profiled to support training the skills that are required.
4 Example
By massively annotating customer service video clips and creating a knowledge graph, it is now not only possible to retrieve specific “episodes” of human interaction but also to calculate the content of the delivered customer service, and it has become possible to evaluate the context that would have been impossible in the past when a human had to perform a very time-consuming task of repeatedly and finely replaying the video to check the content. In this section an example of the massive semantic video annotation is presented.
4.1 Experiment
Four grand staffs of an air-line company (two experts and two intermediates) were asked to go through the same training scenario in the company’s training facility and were video recorded. The scenario was as follows: a customer arrived late to the check-in counter and the boarding time had already passed. The grand staff had to tell the customer that he/she cannot board the booked flight and had to offer alternative options, which are all not ideal for the customer (i.e. have to pay extra money to be on time at the destination or be late for 2 or 3 h). The challenge was a kind of “service recovery” [14] process, i.e., how to manage the customers anger, deliver memorable experience and gain customer loyalty at the same time.
4.2 Observations
The following three features differentiated expert and intermediate ground staffs. All four grand staffs suggested the same 4 alternatives (however, the order of the offerings and the order of presenting accompanying information were different).
-
1)
The experts not only listen to the customer’s requests, but also recites back to the customer, while the intermediate recites less. One expert (Exp_1) recited four requests of the customer and the other expert (Exp_2) recited eight times, while one intermediate staff (Int_1) repeated zero times and the other (Int_2) recited only one time during a five minutes discourse.
-
2)
Experts always provide follow-up information when they had to present information unfavorable to the customer. Exp_1 provided optional information to help the customer’s decision immediately after the negative information. The ratio for Exp_1 was 100% and Exp_2 provided 60%. On the contrary, intermediates tended to wait for the customers response to the negative offering without any follow-up. The ratio of no follow-up for Int_1 was 63% and for Int_2, it was 67%. As a result, the customer understandably felt uncomfortable with unfavorable information.
-
3)
All experts leaned a little forward toward customers, while intermediates generally leaned away from customers or stood straight.
4.3 Querying the Knowledge Graph
-
1)
Calling the customer’s name:
The following query (Fig. 6) show the difference in how often an expert and intermediate call the customer’s name.
 from the video file
from the video file
 called 6 times
called 6 times
 (Umemura) while the rest of the staff members that call once or zero times.
(Umemura) while the rest of the staff members that call once or zero times.Fig. 6. 
Calling the customer’s name.
-
2)
Empathy by humble words:
Similarly, the number of times that the expert staff says humble words was higher compared to the novice (Fig. 7). The cases considered were:

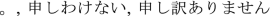 ,
,
 (I’m sorry)”, “
(I’m sorry)”, “

 (I’m terribly sorry)” and “
(I’m terribly sorry)” and “
 (I will tell you)”.
(I will tell you)”.Fig. 7. 
Empathy by humble words.
-
3)
Confirm read-back (times):
In this example the query counts the number of times that a staff read-back the customer’s request in the dialogue (Fig. 8).
Fig. 8. 
Confirm read-back.
 from the video file
from the video file
 called 6 times
called 6 times
 (Umemura) while the rest of the staff members that call once or zero times.
(Umemura) while the rest of the staff members that call once or zero times.

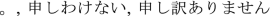 ,
,
 (I’m sorry)”, “
(I’m sorry)”, “

 (I’m terribly sorry)” and “
(I’m terribly sorry)” and “
 (I will tell you)”.
(I will tell you)”.

5 Knowledge Graph Exploitation
In this section a set of users (airline staff members) were profiled after analyzing and representing their behavior on several video clips. The staffs’ statistics are displayed via a web system (skill assessment platform). This tool has the goal of capturing the staffs’ expertise in customer service from multiple measures.
The underlining assumption is that service excellence is an art orchestrated from multiple skills and the same level of excellence is conducted by different sets of skills by different experts. Thus, if a training support system can profile the combination of skills deployed by each expert, then the system aids the human resource department to provide an evidence based, and more precise and effective training calcium to the intermediates of different personalities.
5.1 Web System for User Analysis
The visualization system displays staff members’ information regarding to their customer service. Based on this analysis the company might create strategies in order to improve interaction between customer and company’s representatives. The Fig. 9 presents the dashboard that summarizes the number of users as “expert” or “intermediate”.

Dashboard for statistics (type and number of users)
In addition, the Fig. 10 displays charts of the user’s profile pointing the main metrics (skills and actions) performed in the video clip.

User’s profile
Complementing the previous charts, Fig. 11 and Fig. 12 list the staffs and the metadata respectively produced after processing the video clip.

Table users

Table metadata
6 Conclusions
In this paper, we proposed a methodology that aims automatic representation of human behaviors presented in video clips via knowledge graphs. Our approach combined video analysis (physical actions), descriptions (annotations) such as actions, skills and events and conversation analysis. The goal was to create knowledge graphs based on the video’s content. The graph created can be analyzed by several methods such as machine learning, graph-based reasoning, etc. As an introductory method of exploitation, the graphs were retrieved and analyzed by SPARQL queries.
The methodology can be applied to any kind of scenarios presented in the video and different languages. And for our case of study, the video analysis (human behavior and interactions) was focused in airline’s customer service (interaction between staff members and customers) and the language processed was Japanese.
The results obtained after implementing the methodology were: the 1) fast and automatic representation of human behaviors as well the explicit description of interactions among events, users, actions and conversation in video scenes. 2) The optimization in representing a massive number of graphs that describe the entire video clip (one graph for each scene).
An additional knowledge graph exploitation tool was proposed for analyzing staff members in the area of customer service and in consequence classify them as experts or intermediates.
Our long-term goal is to make the values derived from human interaction computable. To this end, we developed a POC system that assesses the value of airline ground operation experts. Experiencing the service provided by the experts (“value in use”) is a medium to convey the value of the company and representing the context as a knowledge graph enables the computation of those values. The annotation procedure includes manual annotations, but the platform helps to identify new challenges for DNN detection and is designed to incorporate new achievement in DNN as modules.
Future efforts can be focused on optimization the graph’s storage with techniques such as graph embedding.
References
Anne Hendricks, L., et al.: Localizing moments in video with natural language. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 5803–5812 (2017)
Brugman, H., Russel, A., Nijmegen, X.: Annotating multi-media/multi-modal resources with ELAN. In: LREC (2004)
CEN/TS 16880:2015 Service Excellence
Chandan, G., Jain, A., Jain, H., et al.: Real time object detection and tracking using deep learning and OpenCV. In: 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), pp. 1305–1308. IEEE (2018)
Das, S., et al.: A new hybrid architecture for human activity recognition from RGB-D videos. In: Kompatsiaris, I., Huet, B., Mezaris, V., Gurrin, C., Cheng, W.-H., Vrochidis, S. (eds.) MMM 2019. LNCS, vol. 11296, pp. 493–505. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-05716-9_40
Duchenne, O., Laptev, I., Sivic, J., Bach, F., Ponce, J.: Automatic annotation of human actions in video. In: 2009 IEEE 12th International Conference on Computer Vision, pp. 1491–1498. IEEE (2009)
Fuhl, W., et al.: MAM: transfer learning for fully automatic video annotation and specialized detector creation. In: Leal-Taixé, L., Roth, S. (eds.) ECCV 2018. LNCS, vol. 11133, pp. 375–388. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-11021-5_23
Huang, K., Delany, S.J., McKeever, S.: Human action recognition in videos using transfer learning. In: IMVIP 2019: Irish Machine Vision & Image Processing, Technological University Dublin, Dublin, Ireland, 28–30 August 2019. https://doi.org/10.21427/mfrv-ah30
Moon, G., Chang, J.Y., Lee, K.M.: Camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 10133–10142 (2019)
Nishimura, S., Oota, Y., Fukuda, K.: Ontology construction for annotating skill and situation of airline services to multi-modal data. In: Proceedings of International Conference on Human-Computer Interaction (2020, in press)
Oliphant, T.E.: Python for scientific computing. Comput. Sci. Eng. 9(3), 10–20 (2007)
Quilitz, B., Leser, U.: Querying distributed RDF data sources with SPARQL. In: Bechhofer, S., Hauswirth, M., Hoffmann, J., Koubarakis, M. (eds.) ESWC 2008. LNCS, vol. 5021, pp. 524–538. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-68234-9_39
Song, J., et al.: Optimized graph learning using partial tags and multiple features for image and video annotation. IEEE Trans. Image Process. 25(11), 4999–5011 (2016)
Stuart, F.I., Tax, S.: Toward an integrative approach to designing service experiences lessons learned from the theatre. J. Oper. Manage. 22, 609–627 (2004)
Thomas, A.O., Antonenko, P.D., Davis, R.: Understanding metacomprehension accuracy within video annotation systems. Comput. Hum. Behav. 58, 269–277 (2016)
Villazon-Terrazas, B., et al.: Knowledge graph foundations. Exploiting Linked Data and Knowledge Graphs in Large Organisations, pp. 17–55. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-45654-6_2
**ao, Y., Chen, J., Wang, Y., Cao, Z., Zhou, J.T., Bai, X.: Action recognition for depth video using multi-view dynamic images. Inf. Sci. 480, 287–304 (2019)
Xu, Y., Dong, J., Zhang, B., Xu, D.: Background modeling methods in video analysis: a review and comparative evaluation. CAAI Trans. Intell. Technol. 1(1), 43–60 (2016)
Zhang, K., Chao, W.-L., Sha, F., Grauman, K.: Video summarization with long short-term memory. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9911, pp. 766–782. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46478-7_47
Acknowledgments
Part of this work was supported by Council for Science, Technology and Innovation, “Cross-ministerial Strategic Innovation Promotion Program (SIP), Big-data and AI-enabled Cyberspace Technologies” (funding agency: NEDO).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Fukuda, K., Vizcarra, J., Nishimura, S. (2020). Massive Semantic Video Annotation in High-End Customer Service. In: Nah, FH., Siau, K. (eds) HCI in Business, Government and Organizations. HCII 2020. Lecture Notes in Computer Science(), vol 12204. Springer, Cham. https://doi.org/10.1007/978-3-030-50341-3_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-50341-3_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-50340-6
Online ISBN: 978-3-030-50341-3
eBook Packages: Computer ScienceComputer Science (R0)