
Abstract
In incremental learning, reducing catastrophic forgetting always adds additional weights to the classification layer when a new task comes. Moreover, it focuses on prediction accuracy, ignores mislabeling differences, and causes the learned features to be scattered. This paper removes the softmax and integrates depth metric learning to compute image embeddings, which doesn’t need to add extra weights or additional space for new classes. The distances of the data mapped in the old and new task spaces are calculated separately. Then, the distillation of depth metric learning is used to make the two distances as similar as possible to improve the performance of the old knowledge. The experimental results on Cifar10 and Tiny-ImageNet show that the proposed method can effectively alleviate catastrophic forgetting and enhance the effectiveness of incremental learning.
The work was supported by National Natural Science Foundation of China under Grants 61702383.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

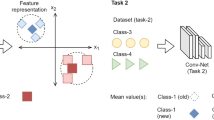

References
Van de Ven, G.M., Tolias, A.S.: Three scenarios for continual learning. ar**v preprint ar**v:1904.07734 (2019)
Yu, L., et al.: Semantic drift compensation for class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6982–6991 (2020)
Tao, X., Hong, X., Chang, X., Dong, S., Wei, X., Gong, Y.: Few-shot class-incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12183–12192 (2020)
Hu, J., Lu, J., Tan, Y.P.: Discriminative deep metric learning for face verification in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1875–1882 (2014)
**ng, E., Jordan, M., Russell, S.J., Ng, A.: Distance metric learning with application to clustering with side-information. Adv. Neural. Inf. Process. Syst. 15, 521–528 (2002)
Yu, L., Yazici, V.O., Liu, X., Weijer, J.V.D., Cheng, Y., Ramisa, A.: Learning metrics from teachers: compact networks for image embedding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2907–2916 (2019)
Wu, Y., et al.: Large scale incremental learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 374–382 (2019)
Benjamin, A.S., Rolnick, D., Kording, K.: Measuring and regularizing networks in function space. ar**v preprint ar**v:1805.08289 (2018)
Chaudhry, A., Gordo, A., Dokania, P.K., Torr, P., Lopez-Paz, D.: Using hindsight to anchor past knowledge in continual learning. ar**v preprint ar**v:2002.08165, vol. 2, no. 7 (2020)
Hsu, Y.C., Liu, Y.C., Ramasamy, A., Kira, Z.: Re-evaluating continual learning scenarios: a categorization and case for strong baselines. ar**v preprint ar**v:1810.12488 (2018)
Pentina, A., Lampert, C.H.: Lifelong learning with non-IID tasks. Adv. Neural. Inf. Process. Syst. 28, 1540–1548 (2015)
De Lange, M., et al.: Continual learning: a comparative study on how to defy forgetting in classification tasks. ar**v preprint ar**v:1909.08383, vol. 2, no. 6 (2019)
Isele, D., Cosgun, A.: Selective experience replay for lifelong learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32 (2018)
Rebuffi, S.A., Kolesnikov, A., Sperl, G., Lampert, C.H.: ICARL: incremental classifier and representation learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2001–2010 (2017)
Robins, A.: Catastrophic forgetting, rehearsal and pseudorehearsal. Connect. Sci. 7(2), 123–146 (1995)
Bengio, Y., LeCun, Y. (eds.): 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014, Conference Track Proceedings (2014). https://openreview.net/group?id=ICLR.cc/2014
Shin, H., Lee, J.K., Kim, J., Kim, J.: Continual learning with deep generative replay. ar**v preprint ar**v:1705.08690 (2017)
Silver, D.L., Mercer, R.E.: The task rehearsal method of life-long learning: overcoming impoverished data. In: Cohen, R., Spencer, B. (eds.) AI 2002. LNCS (LNAI), vol. 2338, pp. 90–101. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-47922-8_8
Li, Z., Hoiem, D.: Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 40(12), 2935–2947 (2017)
Rannen, A., Aljundi, R., Blaschko, M.B., Tuytelaars, T.: Encoder based lifelong learning. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1320–1328 (2017)
Kirkpatrick, J., et al.: Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. 114(13), 3521–3526 (2017)
Zenke, F., Poole, B., Ganguli, S.: Improved multitask learning through synaptic intelligence
Aljundi, R., Babiloni, F., Elhoseiny, M., Rohrbach, M., Tuytelaars, T.: Memory aware synapses: learning what (not) to forget. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 139–154 (2018)
Farquhar, S., Gal, Y.: Towards robust evaluations of continual learning. ar**v preprint ar**v:1805.09733 (2018)
Chopra, S., Hadsell, R., LeCun, Y.: Learning a similarity metric discriminatively, with application to face verification. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), vol. 1, pp. 539–546. IEEE (2005)
Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: a unified embedding for face recognition and clustering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 815–823 (2015)
DaWaK’10: Proceedings of the 12th International Conference on Data Warehousing and Knowledge Discovery. Springer, Heidelberg (2010)
Li, J., Zhao, R., Huang, J.T., Gong, Y.: Learning small-size DNN with output-distribution-based criteria. In: Fifteenth Annual Conference of the International Speech Communication Association (2014)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. ar**v preprint ar**v:1503.02531 (2015)
Mirzadeh, S.I., Farajtabar, M., Li, A., Levine, N., Matsukawa, A., Ghasemzadeh, H.: Improved knowledge distillation via teacher assistant. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 5191–5198 (2020)
Cho, J.H., Hariharan, B.: On the efficacy of knowledge distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4794–4802 (2019)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
Le, Y., Yang, X.: Tiny imagenet visual recognition challenge. CS 231N 7(7), 3 (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Schwarz, J., et al.: Progress & compress: a scalable framework for continual learning. In: International Conference on Machine Learning, pp. 4528–4537. PMLR (2018)
Chaudhry, A., Dokania, P.K., Ajanthan, T., Torr, P.H.: Riemannian walk for incremental learning: understanding forgetting and intransigence. In: Proceedings of the Proceedings of the European Conference on Computer Vision (ECCV), pp. 532–547 (2018)
Masana, M., Ruiz, I., Serrat, J., van de Weijer, J., Lopez, A.M.: Metric Learning for Novelty and Anomaly Detection. ar**v preprint ar**v:1808.05492 (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Yu, P., He, J., Min, Q., Zhu, Q. (2022). Metric Learning with Distillation for Overcoming Catastrophic Forgetting. In: Pan, L., Cui, Z., Cai, J., Li, L. (eds) Bio-Inspired Computing: Theories and Applications. BIC-TA 2021. Communications in Computer and Information Science, vol 1566. Springer, Singapore. https://doi.org/10.1007/978-981-19-1253-5_17
Download citation
DOI: https://doi.org/10.1007/978-981-19-1253-5_17
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-1252-8
Online ISBN: 978-981-19-1253-5
eBook Packages: Computer ScienceComputer Science (R0)