
Zusammenfassung
Die folgenden Abschnitte sollen gleichzeitig die grundlegenden Datenstrukturen in R sowie Möglichkeiten zur deskriptiven Datenauswertung erläutern. Die Reihenfolge der Themen ist dabei so gewählt, dass die abwechselnd vorgestellten Datenstrukturen und darauf aufbauenden deskriptiven Methoden Schritt für Schritt an Komplexität gewinnen.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
Als Indizes dürfen in diesem Fall keine fehlenden Werte (NA) oder Indizes mit positivem Vorzeichen vorkommen, ebenso darf der Indexvektor nicht leer sein.
- 2.
Allgemein gesprochen werden alle Elemente in den umfassendsten Datentyp umgewandelt, der notwendig ist, um alle Werte ohne Informationsverlust zu speichern (Abschn. 1.3.5).
- 3.
Mit Zufallszahlen sind hier immer Pseudozufallszahlen gemeint. Diese kommen nicht im eigentlichen Sinn zufällig zustande, sind aber von tatsächlich zufälligen Zahlenfolgen im Ergebnis fast nicht zu unterscheiden. Pseudozufallszahlen hängen deterministisch vom Zustand des die Zahlen produzierenden Generators ab. Wird sein Zustand über
 festgelegt, kommt bei gleicher
festgelegt, kommt bei gleicher  bei späteren Aufrufen von Zufallsfunktionen immer dieselbe Folge von Werten zustande.
bei späteren Aufrufen von Zufallsfunktionen immer dieselbe Folge von Werten zustande. - 4.
Für x kann auch eine Matrix übergeben werden, deren jeweils z-transformierte Spalten dann die Spalten der ausgegebenen Matrix ausmachen (Abschn. 3.7).
- 5.
Vergleiche auch Desc() aus dem PaketDescTools.
- 6.
Hier ist zu beachten, dass x tatsächlich ein etwa mit c(...) gebildeter Vektor ist: Der Aufruf mean(1, 7, 3) gibt nämlich anders als mean(c(1, 7, 3)) nicht den Mittelwert der Daten 1, 7, 3 aus. Stattdessen ist die Ausgabe gleich dem ersten übergebenen Argument.
- 7.
Als Alternative ließe sich cov.wt() verwenden (Abschn. 3.7.6).
- 8.
Allgemein gesprochen werden alle Elemente in den umfassendsten Datentyp umgewandelt, der notwendig ist, um alle Werte ohne Informationsverlust zu speichern (Abschn. 1.3.5).
- 9.
Da Matrizen numerisch effizienter als Objekte der Klasse data.frame verarbeitet werden können, sind sie dagegen bei der Analyse sehr großer Datenmengen vorzuziehen.
- 10.
Hervorzuheben sind etwa DAAG und HSAUR3 (Hothorn und Everitt 2020).
- 11.
Der Operator == eignet sich nicht zur Prüfung auf fehlende Werte, da das Ergebnis von
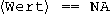 selbst NA ist.
selbst NA ist. - 12.
Eine so ermittelte Matrix kann auch nicht positiv semidefinit sein, und ist dann keine Kovarianzmatrix bzw. Korrelationsmatrix im engeren Sinne.
- 13.
Das Paket stringr (Wickham 2019b) stellt für viele der im Folgenden aufgeführten Funktionen Alternativen bereit, die den Umgang mit Zeichenketten erleichtern und konsistenter gestalten sollen.
- 14.
Für die Auswertung von Zeitreihen vgl. Shumway und Stoffer (2016), Hyndman (2019) sowie den Abschnitt Time Series Analysis der CRAN Task Views (Hyndman 2020).
- 15.
Für eine einführende Behandlung der vielen für Zeitangaben existierenden Subtilitäten vgl. Grothendieck und Petzoldt (2004) sowie ?DateTimeClasses. Der Umgang mit Zeit- und Datumsangaben wird durch Funktionen des Pakets lubridate (Grolemund und Wickham 2011) erleichtert, das Wickham und Grolemund (2017, Kap. 16) eingehend vorstellen: http://r4ds.had.co.nz/dates-and-times.html.
- 16.
Vergleiche ?strptime für weitere mögliche Elemente des Format-String. Diese Hilfe-Seite erläutert auch, wie mit Namen für Wochentage und Monate in unterschiedlichen Sprachen umzugehen ist.
 festgelegt, kommt bei gleicher
festgelegt, kommt bei gleicher  bei späteren Aufrufen von Zufallsfunktionen immer dieselbe Folge von Werten zustande.
bei späteren Aufrufen von Zufallsfunktionen immer dieselbe Folge von Werten zustande.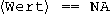 selbst
selbst Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Copyright information
© 2021 Springer-Verlag GmbH Deutschland, ein Teil von Springer Nature
About this chapter

Cite this chapter
Wollschläger, D. (2021). Elementare Datenverarbeitung. In: R kompakt. Springer Spektrum, Berlin, Heidelberg. https://doi.org/10.1007/978-3-662-63075-4_3
Download citation
DOI: https://doi.org/10.1007/978-3-662-63075-4_3
Published:
Publisher Name: Springer Spektrum, Berlin, Heidelberg
Print ISBN: 978-3-662-63074-7
Online ISBN: 978-3-662-63075-4
eBook Packages: Life Science and Basic Disciplines (German Language)