
Abstract
The last few decades brought upon a technological revolution that has been generating data by users with an ever increasing variety of digital devices, resulting in such an incredible volume of data, that we are unable to make any sense of it any more. One solution to decrease the required execution time of these algorithms would be the preprocessing of the data by sampling it before starting the exploration process. That indeed does help, but one issue remains when using the available Machine Learning and Data Mining algorithms: they all have parameters. That is a big problem for most users, because a lot of these parameters require expert knowledge to be able to tune them. Even for expert users a lot of the parameter configurations highly depend on the data. In this work we will present a system that tackles that data exploration process from the angle of parameter space exploration. Here we use the active learning approach and iteratively try to query the user for their opinion of an algorithm execution. For that an end-user only has to express a preference for algorithm results presented to them in form of a visualisations. That way the system is iteratively learning the interest of the end-user, which results in good parameters at the end of the process. A good parametrisation is obviously very subjective here and only reflects the interest of an user. This solution has the nice ancillary property of omitting the requirement of expert knowledge when trying to explore an data set with Data Mining or Machine Learning algorithms. Optimally the end-user does not even know what kind of parameters the algorithms require.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction and Motivation
The last few decades brought upon a technological revolution that has been generating data by users with an ever increasing variety of digital devices, resulting in such an incredible volume of data, that we are unable to make any sense of it any more. This trend will not stop and it has been confirmed, that huge amounts of data have been generated at unprecedented and ever increasing scales. In 2012 it was already estimated that 2.5 exabytes of data are generated each day and the number is doubling every 40 months. Besides the sheer size of the data, almost nothing is known about the data itself. Data Mining and Machine Learning algorithms are normally good at hel** us make sense out of this large volume of data. While Data Mining algorithms extract useful information out of the data, Machine Learning aims to learn from the data and make predictions. These algorithms are quite powerful learning devices, but are of high algorithmic complexity. That means, that executing them can be extremely time consuming. Because we do not know anything about the data itself, we have to use exploration tools (algorithms) to analyse the data. To make that exploration process as flexible as possible, we want to be able to efficiently apply different algorithms on the same data.
A good way to conduct that exploration process would be by applying the active learning approach [20] and embrace an iterative process, that would allow an end-user to analyse the data step-by-step and to intervene into the exploration process by steering it into different directions or to focus it to some interesting data areas. The combination of large data and the computational complexity, makes such a process almost impossible. To make the execution less time consuming, we have multiple possibilities: either improve the algorithmic complexity or reduce the data size. Reducing algorithm complexity only works to a certain degree, and even if we were able to decrease their execution time for that specific data size, this problem will persist in the future, because the data volume is probably going to continue to grow. The other option is decreasing the data size. To do so, we have to assume that every part of the data is equally important [10]. This will allow us to uniformly sample the data, and reduce it to a size our algorithm is comfortable working with. This reduction step is only done once, and the resulting data set can then be used for the Data Mining and Machine Learning algorithms.
Ideally, an end-user wants to influence the analytical process as much as possible. Since we are using Data Mining and Machine Learning algorithms, we can parametrize these to allow better control of their executions. In order to analyse the data, we are exploring the parameter space of the algorithms in the end. The goal of an end-user is to find a good parametrisation for an algorithm, so that they can get something meaningful out of the data.
Let us look at that problem from an end-user perspective: Alice has a large data set containing two features. Alice wants to know how many clusters that data set contains. Now Alice decided to use the K-Means clustering algorithm that seems to solve that issue, and only requires one parameter (named k) which is the number of clusters K-Means is trying to find in the data set. Assuming we have n entries in the data, k can be in the range of 1 to n. Now, if Alice is not applying some clever way to set the parameter, depending on what value is considered as optimal by Alice, it could take n executions of the K-Means algorithm, until Alice finds something interesting in the data.
That is obviously not an optimal way to explore a parameter space. With only a single parameter one could employ a binary search exploration, and that would decrease the required number of executions dramatically. Generally, we are not dealing with just a single parameter. In most cases the algorithms have many more parameters. Finding a parametrisation yielding interesting results in these higher dimensions is much harder, and a simple binary search can not be employed any more. The issue in higher dimensional parameter spaces is simply the sheer size of possible parameter combinations. Depending on the types of the parameters the number of combinations could be infinite. Let us assume three parameters and the discrete case where every parameter can take one-hundred different values. This would already create a parameter space with one-million different parameter combinations. In the case of continuous parameter values we are dealing with real numbers, where even between zero and one, there are an infinite amount of numbers.
Note that the very concept of a good parametrisation is vague, because good in our use case is highly subjective to the end-user’s opinion. A parametrisation is good, if an end-user thinks that an end-result is meaningful. The estimation of meaningfulness of the end-result and quality of the parametrisation are mutually dependent on each other. A less meaningful end-result would make a parametrisation less good, a more meaningful end-result would make a parametrisation better. Two users exploring the same data with the same algorithm, could produce vastly different parametrisations. Taking into account that the subjectiveness of the end-result’s quality estimation is a very important requirement.
This work will present a system that allows the analysis of these large data in a workflow manner by using an visual analytics server as the algorithm execution infrastructure. In that workflow each step is working with the results of the previous steps. That allows us to reduce our problem to single tasks, where our first step would be the data retrieval. The next step is the data reduction, where uniform sampling methods are used to achieve the reduction. Following that is the execution of the algorithms with some parametrizations. Within the workflow multiple steps can be executed at the same time, so that capability can be used to execute the same algorithm with different parametrizations in parallel. The parametrizations is done by an optimizations process, that takes the user preferences of end-results into account, to try other algorithm parametrizations. That means, it tries to learn the interests of the user by applying the active learning approach, i.e. iteratively querying the user for feedback. We present two different processes to achieve that. The presentation of the end-result to the end-user is done in form of a visualisations, where an end-user may express their preference. The full details of our implementation can be found in [2].
2 Related Work
This section is going to outline the related work that affect and are within the scope of this work. We will first position our work within the active learning field, because this is closely related to our work. Then we will relate our active learning component to the visualisations and data reduction. After that we will look into different approaches to visual interactive parameter space exploration, parameter tuning, and pure parameter optimization. Following that we will explore different preference gallery approaches. Then we will shorty look into the data reduction problem and an central infrastructure component for this work. We end the section by distancing ourselves from recommender systems.
2.1 Active Learning
A research area closely related to our iterative feedback process is active learning. In the literature it is often also called “query learning” or “optimal experimental design” [20]. The idea behind active learning is that the learning component can achieve greater prediction accuracy when it can choose from which data it learns. This is generally done by allowing the learning component (active learner) to iteratively pose queries to an oracle (usually a human), and learn from the feedback of that oracle [16, 20]. The active learning query strategies can be organized into different categories. Most of the optimization strategies in our system would likely fall under the one called “Balance exploration and exploitation” [20], where the choice of new query points is a dilemma between choosing points near regions of high certainty and points near regions of high uncertainty in the parameter space. Since the query strategy can be changed any time in our system, this categorisation is not applicable to the whole process in our system, but only to single optimization strategies.
2.2 User-Centered Visual Analysis
The idea of user interaction loop in an visual analysis process is not a new one. The well known Card model [5, 13] described this process already a long time ago. This approach provides means to transform and represent data in a form that allows human interaction. Users can therefore analyse data by exploration rather than pure reasoning. Because of the visualisations users can also immediately observe effects of their interactions with the system, resulting in easier development of an understanding for structures and connections in the data. We also want to allow an end-user to observe immediate effects of their interactions with the system, that is why we also make use of that model in some way. In later chapters we present our adoption of that model.
2.3 Interactive Parameter Space Exploration and Tuning
There are already a few approaches to achieve an interactive parameter space exploration and tuning, three of these we will discuss here. One approach to explore the parameter space was done by Pretorius et al. [17], where they provide the a tool, that allows the exploration of the parameter space in a almost real-time manner. In this approach users are actively involved in tuning the number of samples per parameter the algorithm should generate. In our work we want the algorithm to deduce on itself which parameters to tune based on the feedback given by the user. The system should also remove all the bias the user could have when going through the process, which includes hiding the concrete parameter values that generated the visualisation. Another approach to that was done by Marks et al. [14], here they choose the parameters in a way that they optimally disperse the resulting outputs. This approach has two problems: First, we are working with a black-box function of which we don’t know the output values. Secondly, we do not know, how the visualizations will look like, so we can’t compare them.
Torsney-Weir et al. [23] developed a tool called “Tuner”, which helps with the parameter space exploration of image segmentation algorithms. This tool introduces a two-stage process, where the first stage can be seen as the pre-processing stage. Here, it first samples the complete parameter space as densely as possible within a certain time frame, and acquires all the corresponding segments. This is generally done over-night. In the second stage the user is then able to interactively explore the results of the first step.
They also employ an Gaussian Process with an acquisition function to sample the parameter space for their pre-processing [11], which is nothing else but an automatically guided Bayesian optimization. In our work the exploration of the parameter space should be guided by incorporating the feedback of the user and not constrain the exploration strategy to only Bayesian Optimization. That’s also why no preprocessing steps concerning the exploration can be made. A preprocessing step by sampling the large data first would be possible.
2.4 Parameter Optimization
Grid Search is a simple methodology for finding appropriate parameter values for objective functions, which are functions of which we know nothing about. It is an exhaustive or brute-force search in an parameter space, where the points are located on a grid in the parameter space. This method can usually find good parameters in the grid, and because of it’s brute force nature it does a complete search of every point in the parameter grid. To achieve that, it sets up a grid of parameter combinations and evaluates the values of the objective function at each grid point. A grid search is guided by some performance metric, typically measured by cross-validation [7]. The point with the best value is considered to be the optimum solution [9]. This method has the problem, that the objective function has to be executed an incredible amount of times, depending on the number of parameters [1]. That is a big problem in our case, since we want to reduce the number of executions necessary to a minimum.
Bayesian Optimization is a global optimization strategy for black-box functions. The goal is finding a global maximum in as less iterations as possible [4], this motivation comes from the assumption, that evaluating the objective function is very expensive. Either because of it’s computational complexity, or because of its general resource requirements. It assumes a very general prior over functions, which when combined with observed parameter values and corresponding outputs describes a distribution over functions, which can easily be used to draw samples. This method works in a iterative manner, which in every iteration evaluates a objective function with parameters drawn from the distribution. These parameters are picked by using an acquisition function, which makes a trade-off between exploitation (regions where the expected value is high) and exploration (regions that are of high uncertainty).
It has been shown, that this methodology of doing parameter optimization obtains better results in fewer iterations than grid search [8, 21], the reason being the ability to reason about the quality of parameters. We will look into that optimization strategy in more detail in later sections of this work, because we will make use of it in our system.
2.5 Visualization Gallery
The system should provide the user with multiple different parameter configurations in form of visualizations, from which the user can express it’s preference. This gives the system the necessary data to perform the next round of calculations. There are a lot of different ways to present these to the user, the most effective would be in form of a gallery, that just shows the visualization without the user knowing the parameter configuration of it. This removes all the pre-conceptions and influences the user might have about the parameter configurations [14]. As interesting as this approach is, it is not applicable in our case, since the system can’t pre-calculate all the available input configurations, as this would require depending on the number of parameters and parameter space and incredible number of visualizations. The arrangement algorithm as described in that paper is also not applicable here, since we do not know how the visualization should look like, so there is no conclusion and comparison that could be derived from the output visualizations.
2.6 Preference Gallery for Material Design
In their work Eric et al. [6] also explored the possibilities to use the end-user feedback to find an optimal parametrisation for an algorithm. They too present the user with visualisations generated from different parametrisations and also use the Bayesian optimization method for the optimization. However they only present the user with two visualisations at every iteration and applied the method only to the Bidirectional Reflectance Distribution Function, which is a function used to render reflection on different materials. In our work depending on the strategy and iteration a diverse amount of visualisations is generated. The visualisation and the algorithm that should be optimized can also be chosen freely in our system. Further more in our system we did some improvements on the Bayesian optimization and use this optimization method merely as one of the methods that can be used for the parameter optimization. That means that our system provides a framework in which many different parameter optimization strategies can be used. So we am making a lot of use of that same method in our work, with a few improvements, and also apply it to the problem of extracting interesting or useful information from an extremely large data set by optimizing the parameters of the data analysis algorithm.
2.7 Data Reduction
The user should be provided with galleries of different parameter configurations to let the user give feedback about their preference. That means the given algorithm has to be executed many times with different parametrisations. To be able to do that within an acceptable time frame the large data set would have to be sampled first, that would allow the system to use the data for the process. Since the main part or even the focus of this work is not the data quality, a simple random sampling algorithm is sufficient for now. This does not mean, that sampling is not an important factor for assisting a user in the parameter tuning process. The quality of data can probably influence the quality of the visualizations for the gallery immensely. One random sampling algorithm would be the “Reservoir sampling”, also known as “Algorithm R” by Vitter [24], which requires to iterate through all the data at least once to get a random sampling of an large data set. The same problem arises in Bernoulli and Poisson sampling, in these it is additionally necessary, that each item passes the “independent Bernoulli trial” [22], which requires even more calculation time.
2.8 Visual Analytics Server
The idea to split the work that needs to be done for data analysis into separate tasks is not a new one. The Visual Analytics Server, developed at Fraunhofer IGD, manifested the idea into a system that manages these separate tasks in form of an workflow [12, 15]. We refer to this server later as our Workflow Execution Environment. This server provides the necessary infrastructure for our system to execute the data analysis algorithms by separating process the tasks into data retrieval, data reduction and algorithm execution steps in a workflow. A workflow generally consists of multiple steps, where each step has inputs, outputs and parameters. Theses steps can be connected to each others via their inputs and outputs. So depending on the connections, which also defines their dependencies, steps can be executed in parallel or sequentially. In a workflow, a step being triggered to execute will also trigger its predecessors to execute. The execution results will then be propagated down the tree branches again to the step triggering the execution. Generally the successor steps of the step triggering a run will not be triggered to execute. This allows the workflow to have a nice auxiliary property of allowing partial execution of an workflow. The re-execution of a step is only being performed, if either the parameters were changed or an explicit re-execution was requested, otherwise the step just outputs the cached result from the last run. The combination of result caching, parallel and partial execution makes this an extremely powerful and useful tool, especially for our use case.
2.9 Recommender Systems
From the first glance at the given problem of this work, one could think, that a recommender system would help to solve the problem [3]. This is not really the case, since recommender systems work on historical and community collected data [19], which are both not available here. Therefore recommender systems are also called “collaborative filtering” [18]. We are working with a black-box algorithm (or function) of which we neither know the output type nor the quality measurement. The only data we have are boolean values mapped to parameter configurations, which is the feedback data given by the user. From this and the input data we have to deduce the next round of parameter configurations. With that it should be clear, that we are not working in the same scope in this work as recommender systems do.

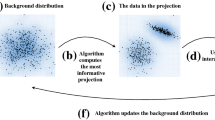
The left side shows the process when applied to machine learning algorithms, on the right side the same process can be observed when applied to the algorithm generating the visualisations.
3 Concept
Our concept is based on a fairly simple idea: we want to help an end-user find something interesting in a data-set by providing an easy-to-use interface. That interface should allow the user insight into the data-set by providing visualizations. Because the user does not necessary know what it is looking for and is only able to provide feedback to visualizations, this interface should give an end-user the opportunity to express preferences. Hel** the user find something interesting, would then require that we learn from these preferences of the user, and try to present the user with more visualizations which should theoretically be more interesting to the user. That creates an iterative feedback process, which can be stopped by the user at any point, when they found something interesting.
This learning process can either be applied to some machine learning algorithm, the algorithm that generates the visualisations or anything else that would influence the visualisations. In this work we are only going to focus on the parametrisation of the machine learning algorithms and the visualisations. In both cases we would be able to change the visualisations presented to the user by altering the parameters of these algorithms (Fig. 1).

A diagram of the workflow as it is being configured for the execution server. The green nodes are the algorithm execution steps, and there are a flexible number of these depending of how many visualisations should be presented to the user. Because the executions can take some time, every execution step would have to be polled for a status report periodically. To prevent that the results of the execution steps are combined together, so that at the last step at the bottom the results of all the execution steps are joined together. That would allow us to only having to poll the last step at the bottom of the workflow for a status report periodically.
The overview of the whole system can be seen in the above figure as a schematic representation. On the left side, the process can be seen when applied to machine learning algorithms, here the parameter optimizer sets the parameters of the machine learning algorithm by incorporating the feedback from the frontend. While on the right side the same process is applied on the visualisations itself, here the machine learning algorithm execution is completely omitted. The iterative feedback process can be observed in both cases, while in the first case it starts at the algorithm execution, in the second case it starts at the frontend. The system that is managing and performing that process is divided into three different parts: the application, the parameter optimizer and the workflow execution environment.
-
The Application can be seen as the controller of the whole system. It bootstraps the whole process, provides a frontend to the end-user and propagates user interactions within the system to the appropriate parts.
-
The Parameter optimizer takes the process configuration and the feedback data and generates parameters for the next round of algorithm executions.
-
The Workflow Execution Environment executes the parametrized algorithms in a workflow-manner, where each step is dependent on the result of the previous step and the first step is the data retrieval.
This can be done in a completely distributed fashion, because of its workflow nature (Fig. 2).
3.1 Application
The application is the conductor of the whole orchestra of components that makes the system work together. This means it has to handle the user interaction in form of feedback and manage the whole process configuration, which includes the configuration of the data source, algorithm and visualisation. The end-user should be able to freely choose a data source, the algorithm and a visualisation. By incorporating all the meta information the frontend receives from the execution server, it can provide the end-user with configuration options of all the process steps. This process configuration is organized in a wizard kind of way, where the end-user is guided through the process step-by-step:
-
1.
First the data source is chosen and depending on the data source additional parameters like table name or database have to be set
-
2.
Next, the algorithm that the end-user wants to use for the exploration process is chosen
-
3.
After choosing an algorithm a user can decide which parameters should be optimized and which should be fixed to a certain value
-
4.
For the end-result display, a user can choose which visualisation it wants to use
-
5.
Since the chosen visualisation can have their own specific data map**s, the user has to map the algorithm result features to the visualisation features
After performing the configuration, the preparations for the exploration process is done and the process can be started. The exploration process consists of the following steps:
-
1.
Take the feedback data and generate parametrizations with the parameter optimizer (the feedback data can be empty in the first iteration)
-
2.
Create the workflow for the execution server by incorporating the configurations set by the user and the parametrizations of step 1
-
3.
Generate visualisations from the workflow execution and present them to the user
-
4.
Create feedback data from the user interaction with the visualisation
-
5.
Repeat from step 1, if user wishes to continue
This creates the iterative feedback loop, which can be stopped any time the user does not want to continue. The end-user is also able to change the process configuration at any point in the exploration. Changing the data-source in the middle of an exploration process is certainly a bad idea, because that could also change the visualisations greatly, and with that the preferences of an user would probably also change. This would cause an incorrect preference learning model for the parameter optimizer. None the less, the possibility for that exists, but has to be used with caution.
The great advantage of being able to change the configuration within the exploration process is the possibility to fixate specific parameters to a certain value at any point. That could improve the performance of the process (in terms of number of iterations), since the user may observe an optimal value for an parameter and help the optimizer by reducing the number of parameters the optimizer would otherwise have to optimize.
Switching the visualisation at any point in the process is also a very important feature. Just because it generally is not a good idea for example to use a bar-chart visualisation with the k-means algorithm, does not mean that it is not interesting to the user. Bar-charts normally visualise grouped data, which would mean in this k-means example that it would categories the data into cluster numbers and then show how many data items belong to each of the clusters. While when visualising the k-means with a scatter plot, it would show the data split into the different cluster groups.

First iteration
From this example we can already deduce one very important property for the exploration process: by choosing different visualisations, the user is able to look at the data with the same algorithm from different perspectives. Perhaps the simple categorisation and counting the number of cluster items is more interesting and intuitive to the user. The parametrisation the user found with the bar-chart would probably also yield a good result in the scatter plot visualisation. This interaction process is nearly identical to the visualisation reference model described by Card et al. [5]. The difference to the Card model is the additional possibility to indirectly influence the algorithm execution by providing visual feedback (expressing preferences) to a parameter optimizer, which parameterizes the algorithm execution.
Full details of our implementation can be found in [2].
4 Results
4.1 Process Applied to the K-Means Clustering Algorithm
First we will try to use the K-Means clustering algorithm with the iris flowers data set, because the K-Means algorithm has only one numerical parameter, and the iris data set can be visualized really well. The process is configured the following way:
-
Fixed parameters: attributes = petal_length, petal_width
-
Visualisation: Scatter Plot
-
Visual Map**: x = petal_length, y = petal_width
So we are using the K-Means to cluster on the given attributes, and generate scatter plots by map** the end-results to the visual features. The first iteration generated already a few good parameters (Fig. 3). On the top right, the third visualisation, already looks quite good, it is already possible to clearly distinguish a few groups. In the next iteration (Fig. 4) we have a really good result:

Second iteration

The first iteration when applying the process on the visualisation itself. The preference is marked here with the grey rectangle. It was chosen because it had a nicer grou** and node distance.
We found a good parametrisation for the k-means; in only two iterations we were able to find a k = 3 or k = 2 for the iris flowers data set. Two iterations means, the end-user only had to express it’s own preference only a single time! But more importantly our system was able to improve the visualisations from the first to the second iteration based on the feedback from the user.

The second iteration when applying the process on the visualisation itself. The marked item was chosen because some nice blue groups are forming. (Color figure online)

The third iteration when applying the process on the visualisation itself. Again the blue group formed, and it just looks better than the others. (Color figure online)
4.2 Process Applied to Visualisations
Next let us try to use our system to find a good parametrisation for the visualisations itself. To keep the changes to the implementation of the system to a minimum we had to create a “pseudo”-Step that does not do any real work, but mostly just returns the given step parameters as a data output. This data can then be used as the parameters for the visualisation. As a visualisation let us use the force directed graph layout, which has seven numerical parameters, each with different bounds. The process would then be configured the following way:
-
Fixed parameters: None, we want to optimize all the parameters
-
Visualisation: Force directed graph layout
-
Visual Map**: Visual map**s correspond to the step parameters
The system generates the following visualisations, depending on the iteration and the feedback given by the user (Figs. 5, 6, 7 and 8):

The fourth iteration when applying the process on the visualisation itself. Here we can see great group formations and positioning in the selected visualisation. Another thing that happened here is that the system mixed in additional visualisations, because it detected that the parametrisations in the last view iterations were to similar to each other.
In the fourth iteration (Fig. 8) we already found something really good. Even though we were using the process to optimize seven parameters, it only took us four iterations to find the parametrisation that generated the last visualisation. Now, we obviously were quite lucky here right now, that it only took us four iterations to find something interesting, it does not always work so well and could take much longer, or not work at all. If a user does not find anything in the current process it started, it can restart the process to try it again, that often improves the exploration process immensely. Also note that in Fig. 8 we were not just simply generating parameters in the natural number space, but in the real number space!
5 Conclusions
In this work we presented a system that solved the particular problem in data analysis of extracting interesting or useful information out of an extremely large data set by using different methods for parameter space exploration. We first looked into the concept of the solution and came to the realisation that a good way to steer an exploration process is by using the feedback a user can provide to us, because we do not know anything about the data or the data analysis methods. But before applying any exploration we first had to find a method to reduce the large data set to a data size we are able to handle within our system more easily. We presented a simple uniform sampling method, that was able to reduce our data extremely fast. This reduced data could now be used for the data analysis process, by applying some parametrisation to the data analysis algorithms. These parametrisations were generated by an optimizer that was incorporating the feedback from an end-user. A very effective way to get good feedback from an end-user is by iteratively showing it visualisations and asking it to express their preference. Humans are exceptionally good at providing good feedback by expressing preferences from visual stimulations, especially because we are dealing with highly subjective quality measurements like “useful” and “interesting”. This feedback provided by the user allowed us to perform a parameter space exploration, and helped us find a good parametrisation that generated a visualisation, which a user found “useful” or “interesting”. We presented two different methods to find a good parametrisations based on the feedback data, one more sophisticated than the other. The first one is called Bayesian Optimization, which uses sophisticated probability models to infer the preferences from the user feedback and then make predictions based on these. The second method is simpler but still quite effective, which makes predictions by maximising a classifier. In the end we saw two use cases in how our system was able to find a good parametrisation for a given problem:
-
In the first use case we took the K-Means clustering algorithm and the full iris-flower data set. We then iteratively let the system generate visualisations for different k-values. In the first iteration we already found quite good results, and in the second iteration we already found a really good k-value. Now the K-Means clustering algorithm has only one single parameter, which motivated the second use case.
-
In the second use case we wanted to use our system to explore a bigger amount of parameters and apply the exploration on the visualisations itself. For that were took a smaller graph based data set and used the force directed layout algorithm for the visualisation generation. This algorithm has eight numerical parameters. Here the process took a few more iteration, but we were still able to show, that even with eight parameters, we found something interesting within 10 Iterations.
This concludes that our system is able to extract useful information out of an large data set by performing a guided parameter space exploration with the feedback provided by an end-user.
References
Bergstra, J., Bengio, Y.: Random search for hyper-parameter optimization. J. Mach. Learn. Res. 13, 281–305 (2012)
Brakowski, A.: Visual guidance to find the right spot in the parameter space. Technical report, TU Darmstadt (2015)
Breyer, M., Nazemi, K., Stab, C., Burkhardt, D., Kuijper, A.: A comprehensive reference model for personalized recommender systems. In: Smith, M.J., Salvendy, G. (eds.) Human Interface 2011. LNCS, vol. 6771, pp. 528–537. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-21793-7_60
Brochu, E., Cora, V.M., de Freitas, N.: A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. CoRR abs/1012.2599 (2010)
Card, S.K., Mackinlay, J.D., Shneiderman, B. (eds.): Readings in Information Visualization: Using Vision to Think. Morgan Kaufmann Publishers Inc., San Francisco (1999)
Eric, B., de Freitas, N., Ghosh, A.: Active preference learning with discrete choice data. In: Advances in Neural Information Processing Systems, vol. 20, pp. 409–416. MIT Press, Cambridge (2007)
Hsu, C.W., Chang, C.C., Lin, C.J.: A Practical Guide to Support Vector Classification (2010)
Hutter, F., Hoos, H.H., Leyton-Brown, K.: Sequential model-based optimization for general algorithm configuration. In: Coello, C.A.C. (ed.) LION 2011. LNCS, vol. 6683, pp. 507–523. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-25566-3_40
Kuijper, A.: On detecting all saddle points in 2D images. Pattern Recogn. Lett. 25(15), 1665–1672 (2004)
Kuijper, A.: Using catastrophe theory to derive trees from images. J. Math. Imaging Vis. 23(3), 219–238 (2005)
Kuijper, A., Florack, L.: The relevance of non-generic events in scale space models. Int. J. Comput. Vis. 57(1), 67–84 (2004)
von Landesberger, T., Bremm, S., Kirschner, M., Wesarg, S., Kuijper, A.: Visual analytics for model-based medical image segmentation: opportunities and challenges. Expert Syst. Appl. 40(12), 4934–4943 (2013)
von Landesberger, T., Fiebig, S., Bremm, S., Kuijper, A., Fellner, D.W.: Interaction taxonomy for tracking of user actions in visual analytics applications. In: Huang, W. (ed.) Handbook of Human Centric Visualization, pp. 653–670. Springer, New York (2014). https://doi.org/10.1007/978-1-4614-7485-2_26
Marks, J., Andalman, B., Beardsley, P.A., Freeman, W., Gibson, S., Hodgins, J., Kang, T., Mirtich, B., Pfister, H., Ruml, W., Ryall, K., Seims, J., Shieber, S.: Design galleries: a general approach to setting parameters for computer graphics and animation. In: Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH), pp. 389–400 (1997)
Nazemi, K., Stab, C., Kuijper, A.: A reference model for adaptive visualization systems. In: Jacko, J.A. (ed.) HCI 2011. LNCS, vol. 6761, pp. 480–489. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-21602-2_52
Osugi, T., Kim, D., Scott, S.: Balancing exploration and exploitation: a new algorithm for active machine learning. In: Fifth IEEE International Conference on Data Mining (ICDM 2005), p. 8 (2005)
Pretorius, A.J., Bray, M.A., Carpenter, A.E., Ruddle, R.A.: Visualization of parameter space for image analysis. IEEE Trans. Vis. Comput. Graph. 17(12), 2402–2411 (2011)
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., Riedl, J.: GroupLens: an open architecture for collaborative filtering of netnews. In: Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, CSCW 1994, pp. 175–186. ACM, New York (1994)
Resnick, P., Varian, H.R.: Recommender systems. Commun. ACM 40(3), 56–58 (1997)
Settles, B.: Active learning literature survey. Technical report, University of Wisconsin (2010)
Snoek, J., Larochelle, H., Adams, R.P.: Practical Bayesian optimization of machine learning algorithms. In: Proceedings of the 25th International Conference on Neural Information Processing Systems, NIPS 2012, vol. 2, pp. 2951–2959. Curran Associates Inc., New York (2012)
Tille, Y.: Sampling Algorithms. Springer, New York (2006). https://doi.org/10.1007/0-387-34240-0
Torsney-Weir, T., Saad, A., Moller, T., Hege, H.C., Weber, B., Verbavatz, J.M., Bergner, S.: Tuner: principled parameter finding for image segmentation algorithms using visual response surface exploration. IEEE Trans. Vis. Comput. Graph. 17(12), 1892–1901 (2011)
Vitter, J.S.: Random sampling with a reservoir. ACM Trans. Math. Softw. 11(1), 37–57 (1985)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Brakowski, A., Maier, S., Kuijper, A. (2018). Visual Guidance to Find the Right Spot in Parameter Space. In: Yamamoto, S., Mori, H. (eds) Human Interface and the Management of Information. Interaction, Visualization, and Analytics. HIMI 2018. Lecture Notes in Computer Science(), vol 10904. Springer, Cham. https://doi.org/10.1007/978-3-319-92043-6_43
Download citation
DOI: https://doi.org/10.1007/978-3-319-92043-6_43
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-92042-9
Online ISBN: 978-3-319-92043-6
eBook Packages: Computer ScienceComputer Science (R0)