
Abstract
This study explored the effectiveness of multi-modal interaction techniques to enable dismounted soldiers to manage their digital information systems and Unmanned Ground Vehicles (UGV) in urban environments. The objective of using multi-modal techniques like speech and gesture was to reduce the physical and cognitive workload of the soldier whilst controlling a UGV. An evaluation was conducted to compare multi-modal interaction against a baseline interface on a smartphone.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Robots have been identified as key partners to the next generation of dismounted soldiers in the increasing complex battlefields of the future. However, the introduction of robots can add to the physical and cognitive loads on the soldier. This could lead to an earlier onset of fatigue for the dismounted soldier and adversely affect the accomplishment of his mission. The proposed system is designed with naturalistic interaction and information display strategies to enable the soldier to effectively control his wearable information system and robot-partner in challenging battlefield situations.
2 Objective
This study aims to explore the use of a binocular see-through HMD coupled with a multi-modal interface involving speech and gestures to enhance soldier performance and reduce workload when employing robots to perform room clearing tasks.
The multi-modal interaction approach to control the robot would be compared against a baseline interface.
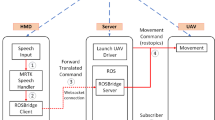
3 Interface and Interaction Design
Two distinct interfaces were developed; smartphone interface as well as the multi-modal interface to enable control of the robot. The operator would be able to move the robot in four distinct directions; Forward, Pivot left, Pivot right, Reverse. The operator would also be able to adjust robot speed and camera settings.
3.1 Smartphone Interface
Smartphone control of the robot was developed as an improvement to current soldier operations of man-portable robots. The current system requires soldiers to launch the robot before employing a bulky proprietary input device to control the robot. It is envisioned that implementing robot control on the smartphone enables the soldier to operate a smaller and familiar device form factor as well as allow consolidation of robot control with other soldier information systems currently deployed on smart devices. The smartphone GUI (Graphical User Interface) design for robot control deployed on an Android OS smart device is shown in Fig. 1 below.

Smartphone interface for robot control
3.2 Multi-modal Interface
The multi-modal interface enables operators to control the robots via speech and gesture. Display of robot information was presented to the operator via a GUI deployed on a binocular see-through Head Mounted Display (HMD).
GUI Design. The design of the display took into consideration system feedback with regards to speech and gesture input. The robot camera view is displayed on the central region of the GUI. Robot and input indicators were located on the peripheral of the GUI. Figure 2 shows the GUI design schematic and actual GUI when implemented.

(Left) HMD GUI design schematic. (Right) Actual HMD GUI design
Speech Interaction Design.
Speech interfaces were explored as they are ideal for system interaction in situations where hands and eyes are otherwise occupied. The speech interface developed allows for operators to issue verbal commands to the robot to adjust speed and camera settings. It further enables operators to invoke deeply nested functions and effect system changes quickly. Speech interaction was enabled by a battlefield noise cancelling speech command recognition application.
The speech interface took into consideration the noisy operating environment as well as reduced interference to other tasks; it is thus proposed that the use of “Imperative Phrases” be employed. Imperative sentences are preferred as they are usually short, simple and direct. An example of an imperative statement would be “Shut the door” where shut is the imperative verb (Harris 2005). An example of a speech command employed is “Change Camera”.
Other considerations to speech interaction design include lexical priming and lexical density that improves system learnability. Lexical priming is supported when features in the GUI cues the operator to the types and syntax of speech commands understood by the system (Estes and Jones 2010). Lexical density is supported when semantically similar words are recognised and accepted by the system (Harris 2005).
Gesture Interaction Design.
A gestural interface allows for more direct interaction with the robots and eliminates the need for intermediate hand held devices/peripherals. Use of hand gestures enables greater flexibility as they do not require a pivot reference point such as those for joysticks (Baudel and Beaudion 1993; Tran 2009). Gesture interaction was enabled via an instrumented right-handed glove. This allowed for posture agnostic, non-vision based recognition of gestures.
The gestural interface allows the operator to control movement of the robots as well as perform menu navigation and item selection on the GUI. For robot movement, pantomimic gestures were used. For menu navigation and item selection, symbolic and deictic gestures were employed (Billinghurst 2009).
Robot Movement (Pantomimic Gestures).
These gestures are performed simulating the use of an invisible tool or object in the user’s hand. Pantomimic gestures designed allowed for the operator to move the robot forward, reverse, pivot left and pivot right. An example of a pantomimic gestures designed is shown in Table 1.
Menu Navigation and Item Selection (Symbolic and Deictic Gestures).
Symbolic gestures are gestures that possess a single meaning. An example of such a gesture would be the “Ok” sign. Deictic gestures on the other hand gestures are gestures of pointing or directing attention to an event. These gestures allowed operators to navigate the GUI and invoke functions and features. An example is shown in Table 2 below.
4 Method
4.1 Participants
Ten male participants were recruited for the study and their ages ranged from 21 to 23. All participants have infantry operational experience. The participants have computer and console gaming experience with frequency of play ranging from weekly to monthly.
Participants were provided training on the respective smartphone and multi-modal interfaces one day prior to the study.
4.2 Experiment Scenario
The experiment was a within-subjects study where participants were required to perform close quarter navigation of the robot in a room clearing task employing the smartphone and multi-modal interface. Participants were given three minutes to clear as many rooms as possible along a corridor. An undisclosed number of targets were planted in each room and participants had to detect and report to the experimenters.
The conditions were counter-balanced to mitigate learning effects. Figure 3 shows the room clearing task during a separate exercise whilst employing the multi-modal interface.

Robot operator controlling the robot via multi-modal interface
4.3 Independent and Dependent Variables
The smartphone and multi-modal interface designs were evaluated as independent variables. The dependent variables examined were participant workload and performance.
Participant workload was measured via the NASA-Task Load Index administered after each condition. Performance was measured by the number of rooms examined and cleared by the participant operating the robots within the allocated three minutes.
5 Results
A Wilcoxon Signed-Ranks Test indicated that participants cleared fewer rooms when employing multi-modal interaction (M = 1.0, SD = 1.41) compared to the runs when smartphone interaction was employed (M = 2.7, SD = 3.37), Z = −2.579, p = 0.01. On the other hand, workload experienced whilst controlling via multi-modal interaction (M = 74.13, SD = 59.94) was significantly higher as compared to controlling the robot via smartphone (M = 55.33, SD = 38.81) Z = −2.193, p = 0.028 (see Table 3).
6 Discussion and Conclusion
The study involved the design and evaluation of a multi-modal interface to operate a robot. A multimodal interface was desirable as it reduces the hands-off weapon time for the dismounted soldier. The result unexpectedly shows a drop in performance and an increase in workload when compared to the baseline smartphone control.
This was attributed to participants unable to anticipate the robot’s turning maneuvers and perform fine movement adjustments with free-form pantomimic gestures as these gestures are unconstrained. Therefore, although participants were observed to be able to learn how to control the robot via gestures, the gestures were not mapped optimally to the robot’s behavior. It was thus recommended for future work to modify gesture design to increase sense of control over the robot. Current limitations of the gesture recognition glove resulted in unintended gestures being recognized due to challenges faced by the system to disambiguate the gestures. It is further recommended for future work to enhance gesture glove instrumentation as well as adjust the gesture interaction dialogue model.
Speech interaction was not frequently employed during robot room clearing as participants felt it was unnecessary to change robot speed or camera which speech interaction allows for. Participants were also not inclined to use speech as the right hand that was used to activate speech interaction was occupied to control the robot. It was thus recommended for future work to enable greater ease of access for speech interaction. It was also recommended to enhance the implemented dialogue models and explore natural/free speech interaction within the projects that follow.
Visualization of robot camera feed on the see-through HMD allowed for a hand held device free view of the robot’s perspective. Participants commented that strong sunlight/ambient light adversely affected the viewing experience. There was however no reports of discomfort or nausea resulting from viewing from the see-through HMD.
References
Billinghurst, M.: Gesture Based Interaction. Extract from “Haptic Input”, pp. 14.1–14.30 (2009)
Baudel, T., Beaudion, M.: Charade; remote control of objects using free-hand gestures. Commun. ACM 36, 28–35 (1993)
Harris, R.A.: Voice Interaction Design. Morgan Kaufmann Publishers, USA (2005)
Jones, L.J., Estes, Z.: Lexical Priming: Associative, Semantic and Thematic Influences on Word Recognition, Visual Word Recognition, vol. 2. Psychology Press, Hove (2012)
Tran, N., et al.: Wireless data glove for gesture based robotic control. In: Jacko, J.A. (ed.) Human Computer Interaction. Lecture Notes in Computer Science, vol. 5611, pp. 271–280. Springer, Heidelberg (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Soo, J.K.T., Tan, A.L.S., Ho, A.S.Y. (2016). Naturalistic Human-Robot Interaction Design for Control of Unmanned Ground Vehicles. In: Stephanidis, C. (eds) HCI International 2016 – Posters' Extended Abstracts. HCI 2016. Communications in Computer and Information Science, vol 618. Springer, Cham. https://doi.org/10.1007/978-3-319-40542-1_87
Download citation
DOI: https://doi.org/10.1007/978-3-319-40542-1_87
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-40541-4
Online ISBN: 978-3-319-40542-1
eBook Packages: Computer ScienceComputer Science (R0)