
Abstract
Although the latent spaces learned by distinct neural networks are not generally directly comparable, even when model architecture and training data are held fixed, recent work in machine learning [13] has shown that it is possible to use the similarities and differences among latent space vectors to derive “relative representations” with comparable representational power to their “absolute” counterparts, and which are nearly identical across models trained on similar data distributions. Apart from their intrinsic interest in revealing the underlying structure of learned latent spaces, relative representations are useful to compare representations across networks as a generic proxy for convergence, and for zero-shot model stitching [13].
In this work we examine an extension of relative representations to discrete state-space models, using Clone-Structured Cognitive Graphs (CSCGs) [16] for 2D spatial localization and navigation as a test case in which such representations may be of some practical use. Our work shows that the probability vectors computed during message passing can be used to define relative representations on CSCGs, enabling effective communication across agents trained using different random initializations and training sequences, and on only partially similar spaces. In the process, we introduce a technique for zero-shot model stitching that can be applied post hoc, without the need for using relative representations during training. This exploratory work is intended as a proof-of-concept for the application of relative representations to the study of cognitive maps in neuroscience and AI.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
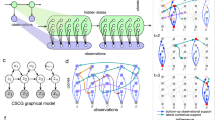

Notes
- 1.
The selection of both suitable anchor points and similarity metrics is discussed at length in [5.
In practice, a softmax with a low temperature worked best for reconstruction.
- 6.
If \(\textbf{M} = \mathcal {A}\), this term is a representational similarity matrix in the sense of [10].
- 7.
In the present setting, one might even draw a parallel between the linear projection of transformer inputs to the key, query and value matrices and the linear projection of observations and prior beliefs onto messages via likelihood and transition tensors.
- 8.
It is worth noting that this is essentially a one-of-N classification task, with effective values of N around 48 in most cases. This is because (following [16]) most experiments were performed on \(6 \times 8\) rooms, and there is one “active” clone corresponding to each location in a converged CSCG.
- 9.
There is a variation on this in which multiple matches exist in the anchor set, but the result is the same as we then combine n identical anchor points.
- 6.
References
Da Costa, L., et al.: Active inference on discrete state-spaces: a synthesis. J. Math. Psychol. 99, 102447 (2020). ISSN: 0022-2496. https://doi.org/10.1016/j.jmp.2020.102447, https://www.sciencedirect.com/science/article/pii/S0022249620300857
Dabagia, M., Kording, K.P., Dyer, E.L.: Aligning latent representations of neural activity. Nat. Biomed. Eng. 7, 337–343 (2023). https://doi.org/10.1038/s41551-022-00962-7
Dedieu, A., et al.: Learning higher-order sequential structure with cloned HMMs (2019). ar**v:1905.00507 [stat.ML]
Dimsdale-Zucker, H.R., Ranganath, C.: Chapter 27 - Representational similarity analyses: aăPractical guide for functional MRI applications. In: Manahan-Vaughan, D. (ed.) Handbook of in Vivo Neural Plasticity Techniques, vol. 28. Handbook of Behavioral Neuroscience, pp. 509–525. Elsevier (2018). https://doi.org/10.1016/B978-0-12-812028-6.00027-6, https://www.sciencedirect.com/science/article/pii/B9780128120286000276
George, D., et al.: Clone-structured graph representations enable flexible learning and vicarious evaluation of cognitive maps. Nat. Commun. 12(1), 2392 (2021)
Hafner, D., et al.: Mastering Atari with Discrete World Models. CoRR abs/2010.02193 (2020). ar**v: 2010.02193. https://arxiv.org/abs/2010.02193
Haxby, J.V., Connolly, A.C., Guntupalli, J.S.: Decoding neural representational spaces using multivariate pattern analysis. Annu. Rev. Neurosci. 37, 435–56 (2014). https://api.semanticscholar.org/CorpusID:6794418
Heins, C., et al.: Pymdp: a python library for active inference in discrete state spaces. CoRR abs/2201.03904 (2022). ar**v: 2201.03904, https://arxiv.org/abs/2201.03904
Kiefer, A., Hohwy, J.: Representation in the prediction error minimization framework. In: Robins, S.K., Symons, J., Calvo, P. (ed.), The Routledge Companion to Philosophy of Psychology, 2nd ed., pp. 384–409 (2019)
Kriegeskorte, N., Mur, M., Bandettini, P.A.: Representational similarity analysis connecting the branches of systems neuroscience. Front. Syst. Neurosci. 2, 4 (2008). https://doi.org/10.3389/neuro.06.004.2008
Kriegeskorte, N., et al.: Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron 60, 1126–1141 (2008). https://api.semanticscholar.org/CorpusID:313180
Millidge, B., et al.: Universal hopfield networks: a general framework for single-shot associative memory models. In: Proceedings of the 39th International Conference on Machine Learning, vol. 162. Baltimore, Maryland, USA, pp. 15561–15583, July 2022
Moschella, L., et al.: Relative representations enable zero-shot latent space communication (2023). ar**v: 2209.15430 [cs.LG]
Pearl, J.: Reverend Bayes on inference engines: a distributed hierarchical approach. In: Proceedings of the Second AAAI Conference on Artificial Intelligence. AAAI’82. Pittsburgh, Pennsylvania: AAAI Press, pp. 133–136 (1982)
Ramsauer, H., et al.: Hopfield Networks is All You Need (2021). ar** (G-SLAM) as unification framework for natural and artificial intelligences: towards reverse engineering the hippocampal/entorhinal system and principles of high-level cognition, October 2021. https://doi.org/10.31234/osf.io/tdw82. psyarxiv.com/tdw82
Smith, R., Friston, K.J., Whyte, C.J.: A step-by-step tutorial on active inference and its application to empirical data. J. Math. Psychol. 107, 102632 (2022). ISSN: 0022-2496. https://doi.org/10.1016/j.jmp.2021.102632. https://www.sciencedirect.com/science/article/pii/S0022249621000973
Stachenfeld, K., Botvinick, M., Gershman, S.: The hippocampus as a predictive map, July 2017. https://doi.org/10.1101/097170
Swaminathan, S., et al.: Schema-learning and rebinding as mechanisms of in-context learning and emergence (2023). ar**v: 2307.01201 [cs.CL]
Teh, Y., Roweis, S.: Automatic alignment of local representations. In: Becker, S., Thrun, S., Obermayer, K. (ed.) Advances in Neural Information Processing Systems, vol. 15. MIT Press (2002). https://proceedings.neurips.cc/paper_files/paper/2002/file/3a1dd98341fafc1dfe9bcf36360e6b84-Paper.pdf
Whittington, J., et al.: How to build a cognitive map. Nat. Neurosci. 25, 1–16 (2022). https://doi.org/10.1038/s41593-022-01153-y
Whittington, J.C.R., Warren, J., Timothy, E.J.B.: Relating transformers to models and neural representations of the hippocampal formation. CoRR abs/2112.04035 (2021). ar**v: 2112.04035, https://arxiv.org/abs/2112.04035
Whittington, J.C.R., et al.: The tolman-eichenbaum machine: unifying space and relational memory through generalization in the hippocampal formation. Cell 183(5), 1249–1263.e23 (2020). ISSN: 0092–8674. https://doi.org/10.1016/j.cell.2020.10.024, https://www.sciencedirect.com/science/article/pii/S009286742031388X
Wills, T.J., et al.: Attractor dynamics in the hippocampal representation of the local environment. Science 308(5723), 873–876 (2005). https://doi.org/10.1126/science.1108905. eprint: https://www.science.org/doi/pdf/10.1126/science.1108905, https://www.science.org/doi/abs/10.1126/science.1108905
Winn, J., Bishop, C.M.: Variational message passing. J. Mach. Learn. Res. 6, 661–694 (2005). ISSN: 1532–4435
Zinszer, B.D., et al.: Semantic structural alignment of neural representational spaces enables translation between English and Chinese words. J. Cogn. Neurosci. 28, 1749–1759 (2016). https://api.semanticscholar.org/CorpusID:577366
Acknowledgements
Alex Kiefer is supported by VERSES Research. CLB is supported by BBRSC grant number BB/P022197/1 and by Joint Research with the National Institutes of Natural Sciences (NINS), Japan, program No. 0111200.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Ethics declarations
Code Availability
The CSCG implementation is based almost entirely on the codebase provided in [16]. Code for reproducing our experiments and analysis can be found at: https://github.com/exilefaker/cscg-rr.
Appendices
Appendix A: Effect of Anchor Set Size on Reconstruction

Average cosine similarity (\(\frac{u \cdot v}{\Vert u \Vert \Vert v \Vert }\)) between ground-truth CSCG beliefs (messages) and their reconstructions from those of a distinct CSCG model trained on the same room and receiving the same sequence of observations, using the method in Eq. 2, plotted against number N of anchors used to define the relative representations. We begin by setting N to the dimensionality of the model’s hidden state. The average is across all 5000 messages in a test sequence.
Appendix B: Visualizing the Correspondence of Relative Representations Across Models

Example representational similarity matrix comparing relative representations of analogous message sequences (i.e. inferred from the same observation sequence) from two distinct models trained on the same environment. This differs from the (dis)similarity matrices typically used in RSA [10], as rows and columns in this case represent distinct sets of first-order representations, i.e. cell (i, j) represents the cosine similarity between \(\textbf{r}^A_i\) and \(\textbf{r}^B_j\). Thus the diagonal symmetry illustrates the empirical equivalence of these two sets of relative representations.
Appendix C: Comparison to LLC
Locally Linear Coordination (LLC) [22] is a method for aligning the embeddings of multiple dimensionality-reducing models so that they project to the same global coordinate system. While its aims differ somewhat from the procedure outlined in the present study, LLC is also an approach to translating multiple source embeddings to a common representational format. As noted above, there is an interesting formal resemblance between the two approaches, which we explore in this Appendix.
The LLC Representation
LLC presupposes a mixture model of experts trained on N D-dimensional input datapoints \(\mathcal {X} = [ x _1, x _2, ..., x _N]\), in which each expert \(m_k\) is a dimensionality reducer that produces a local embedding \(z_{n_k} \in \mathbb {R}^{d_k}\) of datapoint \(x_n\). The mixture weights or “responsibilities” for the model can be derived, for example, as posteriors over each expert’s having generated the data, in a probabilistic setting.
Given the local embeddings and responsibilities, LLC proposes an algorithm for discovering linear map**s \(L_k \in \mathbb {R}^{d \times d_k}\) from each expert’s embedding to a common (lower-dimensional) output representation \(\mathcal {Y} \in \mathbb {R}^{N \times d}\), which can then be expressed as a responsibility-weighted mixture of these projections. That is to say, leaving out bias terms for simplicity: each output image \( y _n\) of datapoint \( x _n\) is computed as
Crucially for what follows, with the help of a flattened (1D) index that spans the “batch” dimension N as well as the experts k, we can express this in simpler terms as \(\mathcal {Y} = UL\). We define matrices \(U \in \mathbb {R}^{N \times \sum _k{d_k}}\) and \(L \in \mathbb {R}^{\sum _k{d_k} \times d}\) in terms of, respectively: (a) vectors \(u_n\), where \(u_{n_j} = r_{n_k}z^i_{n_k}\) (i.e. the jth element of \(u_n\) is the ith element of k’s embedding of \( x _n\) scaled its responsibility term) — and (b) re-indexed, transposed columns \(l_j = l^i_k\) of the \(L_k\) matrices. Intuitively, each row \(u_n\) of U concatenates the experts’ responsibility-weighted embeddings \(r_{n_k}z_{n_k}\) of datapoint \( x _n\), while each of L’s d columns is a concatenation of the corresponding row of the projection matrices \(L_k\), so that the matrix product UL returns a responsibility-weighted prediction for \( y _n\) in each row (see Fig. 6).
Relationship to Our Proposal
Ignoring the motivation of dimensionality reduction which is irrelevant for present purposes, there is a precise conceptual and formal equivalence between this model and the procedure for reconstructing model B’s embeddings given those of model A described above in Sect. 5.2.

Visual schematic of the computation of a single entry of the output of (A) the projection of input \( x _n\) to output \( y _n\) as in the Locally Linear Coordinates (LLC) map** procedure; (B) the reconstruction of a latent embedding \(\textbf{e}^B_n\) in model B’s embedding space given input \( x _n\) to model A. The grou**s in brackets in (A) illustrate the concatenations of vector embeddings (scaled by responsibility terms \(r_{n_k}\)) in \(u_n\), and of projection columns in \(l_j\). \(\textbf{1}_k\) in (B) denotes a row of k 1s (where k in this case denotes the number of anchors, i.e. is set to \(|\mathcal {A} |\)). Each entry in the column vector \({\big [\textbf{E}^B_\mathcal {A}\big ]}^T_j\) is the jth dimension of one of model B’s anchor embeddings.
Specifically, we can regard each of model A’s anchor embeddings \(\textbf{e}^A_{x_k}\) as an “expert” in a fictitious mixture model, with an associated responsibility term measuring its fidelity to the input \( x_i \), which in this case is given by the cosine similarity between the anchor embedding and the input embedding. Then like the rows of U, each row of \(\sigma \big [\textbf{R}^A_X\big ]\), which is a relative representation \(\textbf{r}^A_i = \textbf{E}^A_\mathcal {A}{\textbf{e}^A_i}\) of input i after application of the softmax, acts as a responsibility-weighted mixture of multiple “views” of the input. Similarly, since the rows of \(\textbf{E}^B_\mathcal {A}\) are anchor embeddings in the output space, its columns j act precisely as do the columns of L, i.e. as columns in a projection matrix, so that \(\sigma [\textbf{r}^A_i] \cdot {\textbf{E}^B_\mathcal {A}}_j\) outputs dimension j of the reconstructed target embedding \(\textbf{e}^B_i\).
There is at least one important difference between LLC and our procedure: in LLC each expert uses an internal transform to generate an input-dependent embedding, which is then scaled by its responsibility term, which also depends on the input. Reconstruction via relative representations instead employs fixed stored embeddings, so that each “expert” contributes a scalar value rather than an embedding vector to the final output. However, the expression of LLC in terms of a linear index demonstrates that this makes no essential difference mathematically (conceptually, these scalar “votes” are 1D vectors; cf. Figure 6).
The point is not that these two algorithms are doing precisely the same thing (they are not, as LLC aims to align multiple embedding spaces by deriving a map** to a distinct common space, while our approach aims to recover the contents of one embedding space from another). The use of LLC to reconstruct input data \(\mathcal {X}\) from its “global” embedding \(\mathcal {Y}\) as in [22] is quite closely related to our procedure, however, and at this level of abstraction the approaches may be regarded as the same, with a difference in the nature of the “experts” used in the mixture model and the attendant multiple “views” of the data. The relative representation reconstruction procedure, while presumably not as expressive, may compensate to some extent for the use of scalar “embeddings” by using a large number of “experts”, and has the virtue of eschewing the need for a mixture model to assign responsibilities, or indeed for multiple intermediate embedding models, to perform such a map**.
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Kiefer, A.B., Buckley, C.L. (2024). Relative Representations for Cognitive Graphs. In: Buckley, C.L., et al. Active Inference. IWAI 2023. Communications in Computer and Information Science, vol 1915. Springer, Cham. https://doi.org/10.1007/978-3-031-47958-8_14
Download citation
DOI: https://doi.org/10.1007/978-3-031-47958-8_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-47957-1
Online ISBN: 978-3-031-47958-8
eBook Packages: Computer ScienceComputer Science (R0)