
Abstract
Recent Knowledge distillation (KD) studies show that different manually designed schemes impact the learned results significantly. Yet, in KD, automatically searching an optimal distillation scheme has not yet been well explored. In this paper, we propose DistPro, a novel framework which searches for an optimal KD process via differentiable meta-learning. Specifically, given a pair of student and teacher networks, DistPro first sets up a rich set of KD connections from the transmitting layers of the teacher to the receiving layers of the student, and in the meanwhile, various transforms are also proposed for comparing feature maps along their pathways for distillation. Then, each combination of connection and transform (pathway) is associated with a stochastic weighting process which indicates its importance at every step during the distillation. At the searching stage, the process can be effectively learned through our proposed bi-level meta-optimization strategy. At the distillation stage, DistPro adopts the learned processes for knowledge distillation, which significantly improves the student accuracy especially when faster training is required. Lastly, we find the learned processes can be generalized between similar tasks and networks. In our experiments, DistPro produces state-of-the-art (SoTA) accuracy under varying number of learning epochs on popular datasets, i.e. CIFAR100 and ImageNet, which demonstrates the effectiveness of our framework. Codes are available at https://github.com/xdeng7/DistPro.
X. Deng and D. Sun—These authors contributed equally to this work.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

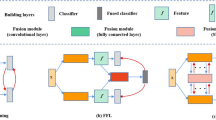

References
Andrychowicz, M., et al.: Learning to learn by gradient descent by gradient descent. In: Advances in Neural Information Processing Systems, pp. 3981–3989 (2016)
Buciluă, C., Caruana, R., Niculescu-Mizil, A.: Model compression. In: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 535–541 (2006)
Chen, G., Choi, W., Yu, X., Han, T., Chandraker, M.: Learning efficient object detection models with knowledge distillation. Adv. Neural Inf. Process. Syst. 30 (2017)
Chen, P., Liu, S., Zhao, H., Jia, J.: Distilling knowledge via knowledge review. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5008–5017 (2021)
Chen, Z., Liu, B.: Lifelong machine learning. Synth. Lect. Artif. Intell. Mach. Learn. 12(3), 1–207 (2018)
Cordts, M., et al.: The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale Hierarchical Image Database. In: CVPR09 (2009)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: pre-training of deep bidirectional transformers for language understanding. ar**v preprint ar**v:1810.04805 (2018)
Dosovitskiy, A., et al.: An image is worth 16 x 16 words: transformers for image recognition at scale. ar**v preprint ar**v:2010.11929 (2020)
Franceschi, L., Frasconi, P., Salzo, S., Grazzi, R., Pontil, M.: Bilevel programming for hyperparameter optimization and meta-learning. In: International Conference on Machine Learning, pp. 1568–1577. PMLR (2018)
Gou, J., Yu, B., Maybank, S.J., Tao, D.: Knowledge distillation: a survey. Int. J. Comput. Vision 129(6), 1789–1819 (2021)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Heo, B., Kim, J., Yun, S., Park, H., Kwak, N., Choi, J.Y.: A comprehensive overhaul of feature distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1921–1930 (2019)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network (2015)
Hoffer, E., Hubara, I., Soudry, D.: Train longer, generalize better: closing the generalization gap in large batch training of neural networks. Adv. Neural Inf. Process. Syst. 30 (2017)
Howard, A.G., et al.: Mobilenets: efficient convolutional neural networks for mobile vision applications. ar**v preprint ar**v:1704.04861 (2017)
Huang, Z., Wang, N.: Like what you like: knowledge distill via neuron selectivity transfer. ar**v preprint ar**v:1707.01219 (2017)
Jang, Y., Lee, H., Hwang, S.J., Shin, J.: Learning what and where to transfer. In: International Conference on Machine Learning, pp. 3030–3039. PMLR (2019)
Ji, M., Heo, B., Park, S.: Show, attend and distill: Knowledge distillation via attention-based feature matching. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 7945–7952 (2021)
Kimura, A., Ghahramani, Z., Takeuchi, K., Iwata, T., Ueda, N.: Few-shot learning of neural networks from scratch by pseudo example optimization. ar**v preprint ar**v:1802.03039 (2018)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. ar**v preprint ar**v:1412.6980 (2014)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
Le, Y., Yang, X.: Tiny imagenet visual recognition challenge. CS 231N 7(7), 3 (2015)
Lee, S., Song, B.C.: Graph-based knowledge distillation by multi-head attention network. ar**v preprint ar**v:1907.02226 (2019)
Liu, H., Simonyan, K., Yang, Y.: Darts: differentiable architecture search. In: International Conference on Learning Representations (2019)
Liu, Y., Chen, K., Liu, C., Qin, Z., Luo, Z., Wang, J.: Structured knowledge distillation for semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2604–2613 (2019)
Liu, Y., et al.: Search to distill: Pearls are everywhere but not the eyes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7539–7548 (2020)
Lyu, L., Chen, C.H.: Differentially private knowledge distillation for mobile analytics. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1809–1812 (2020)
Ma, F., Karaman, S.: Sparse-to-dense: depth prediction from sparse depth samples and a single image. In: 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 4796–4803. IEEE (2018)
Ma, N., Zhang, X., Zheng, H.T., Sun, J.: Shufflenet v2: practical guidelines for efficient CNN architecture design. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 116–131 (2018)
Müller, R., Kornblith, S., Hinton, G.E.: When does label smoothing help? Adv. Neural Inf. Process. Syst. 32 (2019)
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from RGBD images. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7576, pp. 746–760. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33715-4_54
Oord, A., et al.: Parallel wavenet: fast high-fidelity speech synthesis. In: International Conference on Machine Learning, pp. 3918–3926. PMLR (2018)
Ren, M., Zeng, W., Yang, B., Urtasun, R.: Learning to reweight examples for robust deep learning. In: International Conference on Machine Learning, pp. 4334–4343. PMLR (2018)
Romero, A., Ballas, N., Kahou, S., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: hints for thin deep nets. CoRR abs/1412.6550 (2015)
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv 2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510–4520 (2018)
Shang, Y., Duan, B., Zong, Z., Nie, L., Yan, Y.: Lipschitz continuity guided knowledge distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10675–10684 (2021)
Shen, Z., **ng, E.: A fast knowledge distillation framework for visual recognition. ar**v preprint ar**v:2112.01528 (2021)
Tian, Y., Krishnan, D., Isola, P.: Contrastive representation distillation. In: International Conference on Learning Representations (2020)
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International Conference on Machine Learning, pp. 10347–10357. PMLR (2021)
Tung, F., Mori, G.: Similarity-preserving knowledge distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1365–1374 (2019)
Urner, R., Shalev-Shwartz, S., Ben-David, S.: Access to unlabeled data can speed up prediction time. In: ICML (2011)
Wang, X., Zhang, R., Sun, Y., Qi, J.: Kdgan: knowledge distillation with generative adversarial networks. In: NeurIPS, pp. 783–794 (2018)
Wang, Y., Zhou, W., Jiang, T., Bai, X., Xu, Y.: Intra-class feature variation distillation for semantic segmentation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12352, pp. 346–362. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58571-6_21
**ang, L., Ding, G., Han, J.: Learning from multiple experts: self-paced knowledge distillation for long-tailed classification. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12350, pp. 247–263. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58558-7_15
**e, S., Zheng, H., Liu, C., Lin, L.: SNAS: stochastic neural architecture search. In: International Conference on Learning Representations (2019). https://openreview.net/forum?id=rylqooRqK7
Xu, G., Liu, Z., Li, X., Loy, C.C.: Knowledge distillation meets self-supervision. In: European Conference on Computer Vision (ECCV) (2020)
Yao, L., Pi, R., Xu, H., Zhang, W., Li, Z., Zhang, T.: Joint-detnas: upgrade your detector with NAS, pruning and dynamic distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10175–10184 (2021)
Yim, J., Joo, D., Bae, J., Kim, J.: A gift from knowledge distillation: fast optimization, network minimization and transfer learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4133–4141 (2017)
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. ar**v preprint ar**v:1612.03928 (2016)
Zagoruyko, S., Komodakis, N.: Wide residual networks. ar**v preprint ar**v:1605.07146 (2016)
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: an extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6848–6856 (2018)
Zhu, Y., Wang, Y.: Student customized knowledge distillation: bridging the gap between student and teacher. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 5057–5066 (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Deng, X., Sun, D., Newsam, S., Wang, P. (2022). DistPro: Searching a Fast Knowledge Distillation Process via Meta Optimization. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13694. Springer, Cham. https://doi.org/10.1007/978-3-031-19830-4_13
Download citation
DOI: https://doi.org/10.1007/978-3-031-19830-4_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19829-8
Online ISBN: 978-3-031-19830-4
eBook Packages: Computer ScienceComputer Science (R0)