
Abstract
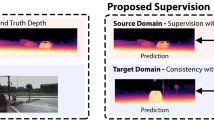
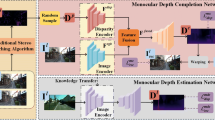
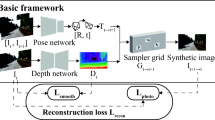
For monocular depth estimation, acquiring ground truths for real data is not easy, and thus domain adaptation methods are commonly adopted using the supervised synthetic data. However, this may still incur a large domain gap due to the lack of supervision from the real data. In this paper, we develop a domain adaptation framework via generating reliable pseudo ground truths of depth from real data to provide direct supervisions. Specifically, we propose two mechanisms for pseudo-labeling: 1) 2D-based pseudo-labels via measuring the consistency of depth predictions when images are with the same content but different styles; 2) 3D-aware pseudo-labels via a point cloud completion network that learns to complete the depth values in the 3D space, thus providing more structural information in a scene to refine and generate more reliable pseudo-labels. In experiments, we show that our pseudo-labeling methods improve depth estimation in various settings, including the usage of stereo pairs during training. Furthermore, the proposed method performs favorably against several state-of-the-art unsupervised domain adaptation approaches in real-world datasets.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
References
Amiri, A.J., Loo, S.Y., Zhang, H.: Semi-supervised monocular depth estimation with left-right consistency using deep neural network. In: IEEE International Conference On Robotics and Biomimetics (ROBIO) (2019)
Atapour-Abarghouei, A., Breckon, T.P.: Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Cao, Y., Wu, Z., Shen, C.: Estimating depth from monocular images as classification using deep fully convolutional residual networks. IEEE Trans. Circ. Syst. Video Technol. (TCSVT) 28, 3174–3182 (2017)
Chen, C., et al.: Progressive feature alignment for unsupervised domain adaptation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Chen, X., Wang, Y., Chen, X., Zeng, W.: S2R-DepthNet: learning a generalizable depth-specific structural representation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Chen, Y.C., Lin, Y.Y., Yang, M.H., Huang, J.B.: CrDoCo: pixel-level domain transfer with cross-domain consistency. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Chen, Z., Zhang, R., Zhang, G., Ma, Z., Lei, T.: Digging into pseudo label: a low-budget approach for semi-supervised semantic segmentation. IEEE Access 8, 41830–41837 (2020)
Cordts, M., et al.: The cityscapes dataset for semantic urban scene understanding. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. Ar**v:1406.2283 (2014)
Fan, H., Su, H., Guibas, L.J.: A point set generation network for 3d object reconstruction from a single image. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Fu, H., Gong, M., Wang, C., Batmanghelich, K., Tao, D.: Deep ordinal regression network for monocular depth estimation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Gaidon, A., Wang, Q., Cabon, Y., Vig, E.: Virtual worlds as proxy for multi-object tracking analysis. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Garg, R., B.G., V.K., Carneiro, G., Reid, I.: Unsupervised CNN for single view depth estimation: geometry to the rescue. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9912, pp. 740–756. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46484-8_45
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? The kitti vision benchmark suite. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2012)
Godard, C., Mac Aodha, O., Brostow, G.J.: Unsupervised monocular depth estimation with left-right consistency. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Godard, C., Mac Aodha, O., Firman, M., Brostow, G.J.: Digging into self-supervised monocular depth estimation. In: IEEE International Conference on Computer Vision (ICCV) (2019)
Guizilini, V., Li, J., Ambrus, R., Pillai, S., Gaidon, A.: Robust semi-supervised monocular depth estimation with reprojected distances. In: Conference on Robot Learning (CoRL) (2020)
Hu, Z., Yang, Z., Hu, X., Nevatia, R.: Simple: similar pseudo label exploitation for semi-supervised classification. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: IEEE International Conference on Computer Vision (ICCV) (2017)
Ji, R., et al.: Semi-supervised adversarial monocular depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 42, 2410–2422 (2019)
Jiao, J., Cao, Y., Song, Y., Lau, R.: Look deeper into depth: monocular depth estimation with semantic booster and attention-driven loss. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11219, pp. 55–71. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01267-0_4
Karsch, K., Liu, C., Kang, S.B.: Depth transfer: depth extraction from video using non-parametric sampling. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 36, 2144–2158 (2014)
Kundu, J.N., Uppala, P.K., Pahuja, A., Babu, R.V.: AdaDepth: unsupervised content congruent adaptation for depth estimation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Kuznietsov, Y., Stuckler, J., Leibe, B.: Semi-supervised deep learning for monocular depth map prediction. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Laina, I., Rupprecht, C., Belagiannis, V., Tombari, F., Navab, N.: Deeper depth prediction with fully convolutional residual networks. In: International Conference on 3D Vision (3DV) (2016)
Lee, D.H., et al.: Pseudo-label: the simple and efficient semi-supervised learning method for deep neural networks. In: International Conference on Machine Learning (ICML) (2013)
Li, Y., Yuan, L., Vasconcelos, N.: Bidirectional learning for domain adaptation of semantic segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Liu, F., Shen, C., Lin, G., Reid, I.: Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 38, 2024–2039 (2015)
Lopez-Rodriguez, A., Mikolajczyk, K.: DESC: domain adaptation for depth estimation via semantic consistency. Ar**v:2009.01579 (2020)
Mahjourian, R., Wicke, M., Angelova, A.: Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Menze, M., Geiger, A.: Object scene flow for autonomous vehicles. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
Pastore, G., Cermelli, F., **an, Y., Mancini, M., Akata, Z., Caputo, B.: A closer look at self-training for zero-label semantic segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Paul, S., Tsai, Y.-H., Schulter, S., Roy-Chowdhury, A.K., Chandraker, M.: Domain adaptive semantic segmentation using weak labels. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12354, pp. 571–587. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58545-7_33
PNVR, K., Zhou, H., Jacobs, D.: SharinGAN: combining synthetic and real data for unsupervised geometry estimation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: PointNet: deep learning on point sets for 3d classification and segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Richter, S.R., Vineet, V., Roth, S., Koltun, V.: Playing for data: ground truth from computer games. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 102–118. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_7
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Saito, K., Ushiku, Y., Harada, T.: Asymmetric tri-training for unsupervised domain adaptation. In: International Conference on Machine Learning (ICML) (2017)
Saxena, A., Sun, M., Ng, A.Y.: Make3d: learning 3d scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 31, 824–840 (2008)
Shin, I., et al.: MM-TTA: multi-modal test-time adaptation for 3d semantic segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Taherkhani, F., Dabouei, A., Soleymani, S., Dawson, J., Nasrabadi, N.M.: Self-supervised Wasserstein pseudo-labeling for semi-supervised image classification. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Tosi, F., Aleotti, F., Poggi, M., Mattoccia, S.: Learning monocular depth estimation infusing traditional stereo knowledge. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Vu, T.H., Jain, H., Bucher, M., Cord, M., Pérez, P.: ADVENT: adversarial entropy minimization for domain adaptation in semantic segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Wang, P., Shen, X., Lin, Z., Cohen, S., Price, B., Yuille, A.L.: Towards unified depth and semantic prediction from a single image. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
**ang, R., Zheng, F., Su, H., Zhang, Z.: 3dDepthNet: point cloud guided depth completion network for sparse depth and single color image. Ar**v:2003.09175 (2020)
Yang, J., Alvarez, J.M., Liu, M.: Self-supervised learning of depth inference for multi-view stereo. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021)
Yin, W., Liu, Y., Shen, C., Yan, Y.: Enforcing geometric constraints of virtual normal for depth prediction. In: IEEE International Conference on Computer Vision (ICCV) (2019)
Yuan, W., Khot, T., Held, D., Mertz, C., Hebert, M.: PCN: point completion network. In: International Conference on 3D Vision (3DV) (2018)
Zhan, H., Garg, R., Weerasekera, C.S., Li, K., Agarwal, H., Reid, I.: Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
Zhang, Z.: Microsoft kinect sensor and its effect. IEEE Multimedia 19, 4–10 (2012)
Zhao, S., Fu, H., Gong, M., Tao, D.: Geometry-aware symmetric domain adaptation for monocular depth estimation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Zhao, X., Schulter, S., Sharma, G., Tsai, Y.-H., Chandraker, M., Wu, Y.: Object detection with a unified label space from multiple datasets. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12359, pp. 178–193. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58568-6_11
Zheng, C., Cham, T.-J., Cai, J.: T\(^2\)Net: synthetic-to-realistic translation for solving single-image depth estimation tasks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 798–814. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_47
Zhou, T., Brown, M., Snavely, N., Lowe, D.G.: Unsupervised learning of depth and ego-motion from video. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
Zou, Y., Yu, Z., Vijaya Kumar, B.V.K., Wang, J.: Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11207, pp. 297–313. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01219-9_18
Zou, Y., et al.: PseudoSeg: designing pseudo labels for semantic segmentation. Ar**v:2010.09713 (2020)
Acknowledgement
This project is supported by MOST (Ministry of Science and Technology, Taiwan) 111-2636-E-A49-003 and 111-2628-E-A49-018-MY4.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Yen, YT., Lu, CN., Chiu, WC., Tsai, YH. (2022). 3D-PL: Domain Adaptive Depth Estimation with 3D-Aware Pseudo-Labeling. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13687. Springer, Cham. https://doi.org/10.1007/978-3-031-19812-0_41
Download citation
DOI: https://doi.org/10.1007/978-3-031-19812-0_41
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19811-3
Online ISBN: 978-3-031-19812-0
eBook Packages: Computer ScienceComputer Science (R0)