
Abstract
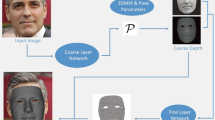
In this paper, we propose a convolutional encoder network to learn a map** function from a noisy depth image to a 3D expressive facial model. We formulate the task as an embedding problem and train the network in an unsupervised manner by exploiting the consistent fitting of the 3D mesh and the depth image. We use the 3DMM-based representation and embed depth images to code vectors concerning facial identities, expressions, and poses. Without semantic textural cues from RGB images, we exploit geometric and contextual constraints in both the depth image and the 3D surface for reliable map**. We combine the multi-level filtered point cloud pyramid and semantic adaptive weighting for fitting. The proposed system enables the 3D expressive face completion and reconstruction in poor illuminations by leveraging a single noisy depth image. The system realizes a full correspondence between the depth image and the 3D statistical deformable mesh, facilitating landmark location and feature segmentation of depth images.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Amberg, B., Romdhani, S., Vetter, T.: Optimal step nonrigid ICP algorithms for surface registration. In: IEEE CVPR, pp. 1–8 (2007)
Baltrušaitis, T., Robinson, P., Morency, L.P.: 3D constrained local model for rigid and non-rigid facial tracking. In: IEEE CVPR, pp. 2610–2617 (2012)
Bas, A., Huber, P., Smith, W.A., Awais, M., Kittler, J.: 3D morphable models as spatial transformer networks. In: ICCV Workshop on Geometry Meets Deep Learning, pp. 904–912 (2017)
Blanz, V., Basso, C., Poggio, T., Vetter, T.: Reanimating faces in images and video. Comput. Graph. Forum 22, 641–650 (2003)
Blanz, V., Vetter, T.: A morphable model for the synthesis of 3D faces. In: SIGGRAPH 1999, pp. 187–194 (1999)
Borghi, G., Venturelli, M., Vezzani, R., Cucchiara, R.: Poseidon: face-from-depth for driver pose estimation. In: IEEE CVPR, pp. 5494–5503 (2017)
Bulat, A., Tzimiropoulos, G.: How far are we from solving the 2D 3D face alignment problem? (and a dataset of 230,000 3D facial landmarks). In: IEEE ICCV, pp. 1021–1030 (2017)
Cao, C., Weng, Y., Zhou, S., Tong, Y., Zhou, K.: FaceWarehouse: a 3D facial expression database for visual computing. IEEE Trans. VCG 20(3), 413–425 (2014)
Chang, F.J., Tran, A.T., Hassner, T., Masi, I., Nevatia, R., Medioni, G.: ExpNet: landmark-free, deep, 3D facial expressions. In: IEEE FG 2018, pp. 122–129 (2018)
Deng, Y., Yang, J., Xu, S., Chen, D., Jia, Y., Tong, X.: Accurate 3D face reconstruction with weakly-supervised learning: from single image to image set. In: IEEE CVPR Workshops (2019)
Fanelli, G., Dantone, M., Gall, J., Fossati, A., Van Gool, L.: Random forests for real time 3D face analysis. Int. J. Comput. Vis. 101(3), 437–458 (2013). https://doi.org/10.1007/s11263-012-0549-0
Fanelli, G., Gall, J., Van Gool, L.: Real time head pose estimation with random regression forests. In: CVPR, pp. 617–624 (2011)
Feng, Y., Wu, F., Shao, X., Wang, Y., Zhou, X.: Joint 3D face reconstruction and dense alignment with position map regression network. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) Computer Vision – ECCV 2018. LNCS, vol. 11218, pp. 557–574. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01264-9_33
Ghiass, R.S., Arandjelović, O., Laurendeau, D.: Highly accurate and fully automatic head pose estimation from a low quality consumer-level RGB-D sensor. In: Proceedings of the 2nd Workshop on Computational Models of Social Interactions: Human-Computer-Media Communication, pp. 25–34 (2015)
Groueix, T., Fisher, M., Kim, V.G., Russell, B.C., Aubry, M.: 3D-CODED: 3D correspondences by deep deformation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11206, pp. 235–251. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01216-8_15
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: IEEE CVPR, pp. 770–778 (2016)
Jaderberg, M., Simonyan, K., Zisserman, A., et al.: Spatial transformer networks. In: NIPS, pp. 2017–2025 (2015)
**, X., Tan, X.: Face alignment in-the-wild: a survey. Comput. Vis. Image Underst. 162, 1–22 (2017)
Kundu, A., Li, Y., Rehg, J.M.: 3D-RCNN: instance-level 3D object reconstruction via render-and-compare. In: IEEE CVPR, pp. 3559–3568 (2018)
Li, S., Ngan, K.N., Paramesran, R., Sheng, L.: Real-time head pose tracking with online face template reconstruction. IEEE Trans. PAMI 38(9), 1922–1928 (2016)
Lu, S., Cai, J., Cham, T.J., Pavlovic, V., Ngan, K.N.: A generative model for depth-based robust 3D facial pose tracking. In: IEEE CVPR (2017)
Martin, M., Camp, F.V.D., Stiefelhagen, R.: Real time head model creation and head pose estimation on consumer depth cameras. In: 3DV (2015)
Meyer, G.P., Gupta, S., Frosio, I., Reddy, D., Kautz, J.: Robust model-based 3D head pose estimation. In: ICCV, pp. 3649–3657 (2015)
Morency, L.P.: 3D constrained local model for rigid and non-rigid facial tracking. In: IEEE CVPR (2012)
Padeleris, P., Zabulis, X., Argyros, A.A.: Head pose estimation on depth data based on particle swarm optimization. In: IEEE CVPR Workshops, pp. 42–49 (2012)
Paysan, P., Knothe, R., Amberg, B., Romdhani, S., Vetter, T.: A 3D face model for pose and illumination invariant face recognition. In: IEEE International Conference on Advanced Video and Signal Based Surveillance, pp. 296–301 (2009)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: PointNet: deep learning on point sets for 3D classification and segmentation. In: IEEE CVPR, pp. 652–660 (2017)
Richardson, E., Sela, M., Kimmel, R.: 3D face reconstruction by learning from synthetic data. In: 3DV, pp. 460–469 (2016)
Richardson, E., Sela, M., Or-El, R., Kimmel, R.: Learning detailed face reconstruction from a single image. In: IEEE CVPR, pp. 5553–5562 (2017)
Shin, D., Fowlkes, C.C., Hoiem, D.: Pixels, voxels, and views: a study of shape representations for single view 3D object shape prediction. In: IEEE CVPR, pp. 3061–3069 (2018)
Tewari, A., et al.: Self-supervised multi-level face model learning for monocular reconstruction at over 250 Hz. In: IEEE CVPR, pp. 2549–2559 (2018)
Tewari, A., et al.: MoFA: model-based deep convolutional face autoencoder for unsupervised monocular reconstruction. In: IEEE ICCV, vol. 2, p. 5 (2017)
Thies, J., Zollhofer, M., Stamminger, M., Theobalt, C., Nießner, M.: Face2Face: real-time face capture and reenactment of RGB videos. In: IEEE CVPR, pp. 2387–2395 (2016)
Tran, A.T., Hassner, T., Masi, I., Medioni, G.: Regressing robust and discriminative 3D morphable models with a very deep neural network. In: IEEE CVPR, pp. 1493–1502 (2017)
Wang, N., Gao, X., Tao, D., Yang, H., Li, X.: Facial feature point detection: a comprehensive survey. Neurocomputing 275, 50–65 (2017). https://www.sciencedirect.com/science/article/abs/pii/S0925231217308202
Wang, W., Ceylan, D., Mech, R., Neumann, U.: 3DN: 3D deformation network. In: IEEE CVPR, pp. 1038–1046 (2019)
Weise, T., Bouaziz, S., Li, H., Pauly, M.: Realtime performance-based facial animation. ACM Trans. Graph. 30, 77 (2011)
Yan, X., Yang, J., Yumer, E., Guo, Y., Lee, H.: Perspective transformer nets: learning single-view 3D object reconstruction without 3D supervision. In: NIPS, pp. 1696–1704 (2016)
Zhu, X., Liu, X., Lei, Z., Li, S.Z.: Face alignment in full pose range: a 3D total solution. IEEE Trans. PAMI 41(1), 78–92 (2017)
Acknowledgments
This work was supported by NSFC 61876008.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Li, P. et al. (2020). An Unsupervised Approach for 3D Face Reconstruction from a Single Depth Image. In: Magnenat-Thalmann, N., et al. Advances in Computer Graphics. CGI 2020. Lecture Notes in Computer Science(), vol 12221. Springer, Cham. https://doi.org/10.1007/978-3-030-61864-3_18
Download citation
DOI: https://doi.org/10.1007/978-3-030-61864-3_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-61863-6
Online ISBN: 978-3-030-61864-3
eBook Packages: Computer ScienceComputer Science (R0)