
Abstract
The huge amount of heterogeneous information in location-based social networks (LBSNs) creates great challenges for POI recommendation. User check-in behavior exhibits two properties, diversity and imbalance. To effectively model both properties, we propose an Aspect-aware Geo-Social Matrix Factorization (AGS-MF) approach to exploit various factors in a unified manner for more effective POI recommendation. Specifically, we first construct a novel knowledge graph (KG), named as Aspect-aware Geo-Social Influence Graph (AGS-IG), to unify multiple influential factors by integrating the heterogeneous information about users, POIs and aspects from reviews. We design an efficient meta-path based random walk to discover relevant neighbors of each user and POI based on multiple influential factors. The extracted neighbors are further incorporated into AGS-MF with automatically learned personalized weights for each user and POI. By doing so, both diversity and imbalance can be modeled for better capturing the characteristics of users and POIs. Experimental results on several real-world datasets demonstrate that AGS-MF outperforms state-of-the-art methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In location-based social networks (LBSNs), user check-in decision exhibits two critical properties: (1) diversity, a user’s check-in is often jointly affected by multiple influential factors [3, 11, 13]; (2) imbalance, i.e., various influences carry different levels of importance for a check-in decision. Early studies often project the heterogeneous information to a homogeneous representation, which may cause information loss and disobey the check-in decision making process [9, 11]. Recent studies thus explore heterogeneous representation such as knowledge graph (KG), to organize various types of information in a unified space, but fail to model the imbalance property [3, 4, 10, 13, 14].
Hence, to jointly capture the two properties of user check-in decision, we propose an Aspect-aware Geo-Social Matrix Factorization (AGS-MF) approach to leverage the capability of knowledge graph (KG) and matrix factorization (MF). AGS-MF is capable of unifying various influential factors as well as learning the saliences of them at the personalized level for each user and POI. In this paper, we employ geographical distance, social connection and user reviews to encode geographical, social and content influences, respectively. To accommodate various types of information in a unified representation space, we construct a novel knowledge graph – Aspect-aware Geo-Social Influence Graph (AGS-IG). Then, we design a meta-path based random walk process to efficiently discover reliable neighbors of each user and POI. The meta-paths are used to encode various influences. By assuming that neighbors should be closer to the given entity (either a user or POI) in the latent space, we incorporate regularizers into AGS-MF to constrain the distance of latent representations between them. To further capture the imbalance of various influential factors, personalized weights are further added to those regularizers, which represent the strength of neighbor relations regarding the corresponding meta-path. In this way, the latent representations of users and POIs can capture user preferences and POI characteristics, and preserve the heterogeneous information.
In summary, our major contribution lies in three folds: (1) We propose a novel knowledge graph (AGS-IG) to embed heterogeneous information of LBSNs in a unified space; (2) We propose AGS-MF to capture both diversity and imbalance properties of user check-in decision; (3) We conduct extensive experiments to evaluate our proposed approach on multiple real-world LBSN datasets, and empirical results demonstrate that our approach significantly outperforms state-of-the-art POI recommendation algorithms.
2 Aspect-Aware Geo-Social Influence Graph
Notations. Let U, L, C, A denote users, POIs, categories and aspects, respectively; u, l, c, a denote user, POI, category and aspect entities, respectively; the POIs visited by user \(u_i\) are defined as a preference vector \(\varvec{r}_{u_i}=(r_{u_i,l_1}, r_{u_i,l_2} \cdots r_{u_i,l_j}, \cdots , r_{u_i,l_{\vert L \vert }})\), where \(r_{u_i,l_j}\) is the rating given by user \(u_i\) to POI \(l_j\), and |L| is the number of total POIs; each triple \(<u_i\), \(l_j\), \(a_k>\) represents that user \(u_i\) has rated POI \(l_j\) with a review associated with aspect \(a_k\).
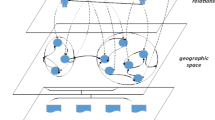
AGS-IG Construction. We exploit social network, geographical distance and aspects from user reviews to build a knowledge graph to incorporate different types of information into a unified space, expressed by \(\text {AGS-IG}=(U \cup L \cup A, E_{UU} \cup E_{UL} \cup E_{UA} \cup E_{LA} \cup E_{LL} \cup E_{AA})\). Specifically, E denotes the set of directed edges linking two entities; \(E_{UU}\) represents friendships; and \(E_{LL}\) represents POI-POI relations; \(E_{AA}\) denotes the semantic relations between aspects; \(E_{UL}\), \(E_{UA}\) and \(E_{LA}\) are the sets of edges representing user-POI, user-aspect and POI-aspect relations, respectively. Figure 1 is a running example to depict the graph structure. Given AGS-IG, for a target user \(u_i\), we can discover the relevant neighbors of each user and POI.

A running example for AGS-IG structure
3 Meta-path Based Random Walk
Due to the large amount of entities involved in AGS-IG, we develop an effective meta-path based random walk process to retrieve semantically related neighbors. As a very useful concept to characterize the semantic patterns for a knowledge graph, meta-path [8] is used for capturing the semantic relations in AGS-IG. Given a meta-path \(p=T_1 T_2 \cdots T_m \cdots \), where \(T_m\) is the type of the m-th entity, the transition probability between two linked entities is determined by the neighborhood size with constraint based by p, which is defined as follows:
where \(v_m\) is the \(m_{th}\) entity in p, \(T(v_m)\) returns the type of \(v_m\) and \(\mathcal {N}_{T_{m}}(v_{m-1})\) is the neighbor set of \(v_{m-1}\) in type \(T_{m}\). By following p with the transition probability, the random walker can generate a path until it reaches the walk length. The process terminates if enough paths are created. Finally, we extract the neighbors from those paths for a given user or POI.
Note that as our goal is to find reliable neighbors for users and POIs, all meta-paths should start with U (L) and reach U (L) eventually. We select the following meta-paths: ULU, UU, ULALU and UAU for users; LUL, LL and LAL for POIs. These meta-paths represent various influential factors that encode different semantic relations, e.g., UAU (LAL) can help discover neighbors sharing the same aspects while LL can find nearby POIs. Suppose we have two paths for \(u_1\): \(u_1 \rightarrow a_3 \rightarrow u_8\) and \(u_1 \rightarrow a_7 \rightarrow u_2\), \(u_8\) and \(u_2\) are thus included in the neighbor set of \(u_1\) regarding meta-path p, i.e., \(\{u_2, u_8\}\) \(\subset \mathcal {N}_{p}(u_1)\).
4 Aspect-Aware Geo-Social Matrix Factorization
Matrix factorization (MF) [7] is an efficient method widely applied in recommender systems. It factorizes the user-POI rating matrix \(R\in R^{|U|\times |L|}\) into low-rank user-latent matrix \(\mathcal {U} \in R^{|U|\times d}\) and POI-latent matrix \(\mathcal {V} \in R^{|V|\times d}\) (d is the dimension of latent vectors). The rating prediction of user \(u_i\) on a POI \(l_j\), i.e., \(\hat{r}_{i,j} = \mathcal {U}_i {\mathcal {V}_j}^\top \). Aspect-aware Geo-Social Matrix Factorization (AGS-MF) aims to incorporate the discovered neighbors that encode diverse influential factors into MF to better model users’ preference and POIs’ characteristics. By assuming that neighbors should be close to each other in the latent space, we integrate regularization terms into MF, so as to constrain the distance of latent feature vectors of the neighbors. Meanwhile, personalized meta-path weights for individual users are also incorporated to control the strength of regularization. Inspired by this idea, we also assign “personalized” weights of meta-paths for each POI. All the weights are jointly learned with user and POI latent feature vectors. By doing so, both diversity and imbalance properties of user check-in behavior can be effectively modeled in our unified framework. The objective function is thus defined as follows:
where \(I_{i,j}\) is an indicator function that equals 1 if user \(u_i\) rated POI \(l_j\) and equals 0 otherwise; \(r_{i,j} \in [0, 1]\) is the rating of user \(u_i\) on POI \(l_j\) after min-max normalization; \(g(x)=1 / (1+exp(-x))\) is the logistic function that bounds the range of prediction into [0, 1]; \(\alpha _u\) and \(\alpha _l\) are parameters to control the importance of user and item respectively; \(\mathcal {M}_u\) and \(\mathcal {M}_l\) represent the sets of meta-paths for users and POIs, i.e., \(\mathcal {M}_u = \{ULU,UU,ULALU,UAU\}\) and \(\mathcal {M}_l = \{LUL,LL,LAL\}\); \(s_{i,k}\) represents the personalized PageRank value of k after normalization (i.e., \(\sum \nolimits _{k \in \mathcal {N}_{p}(i)} s_{i,k} = 1\)); \(\varOmega _{i,p} \in \varOmega \) and \(\varTheta _{j,p} \in \varTheta \) represent the weights of meta-path p for \(u_i\) and \(l_j\) respectively, \(\varOmega \) and \(\varTheta \) are weight matrices for users and POIs respectively; \(||\cdot ||_F\) denotes the Frobenius norm; and \(\lambda _u\), \(\lambda _l\), \(\lambda _\varOmega \), \(\lambda _\varTheta \) are regularization coefficient for easing over-fitting. We adopt the stochastic gradient descent approach [1] to optimize AGS-MF formulated by Eq. 2.
5 Experiments
5.1 Experiment Setup
Datasets. YelpFootnote 1 dataset is utilized for evaluation. The toolbox developed in [15] is used for aspect extraction. Three cities are chosen for evaluation: Charlotte, Phoenix and Las Vegas. Table 1 summarizes the statistics of the three cities. Following the common preprocessing practice [4, 13], users who visited more than 4 POIs are selected for evaluation. The earlier 80% check-ins of each user are selected as training set and the remaining 20% are testing set.
Evaluation Metrics. To evaluate the performance of all methods, we adopt several widely used metrics [2, 12, 13]: Precision, Recall and Mean Average Precision (denoted as Pre@N, Rec@N and MAP@N) where N is the size of the Top-N recommended POI ranking list.
Comparison Methods. (1) UCF: It is the user-based collaborative filtering; (2) ICF: It is the item-based collaborative filtering. (3) MF [7]: It is the basic matrix factorization; (4) SRMF [6]: It integrates social influence into MF; (5) GeoMF [5]: It is a state-of-the-art POI recommendation method, which incorporates geographical influence into MF; (6) LFBCA [9]: It is a state-of-the-art graph based approach via conducting personalized PageRank (PPR) over social network; (7) TriRank [4]: It is a state-of-the-art graph based method based on a tripartite graph with users, POIs and aspects; (8) GeoSoCa [13]: It is a state-of-the-art POI recommendation approach by integrating multiple influential factors into a unified linear framework; (9) AGSRec [3]: It is anther state-of-the-art algorithm, a graph-based ranking algorithm considering various factors by meta-paths.
Parameter Settings. We tune parameters to achieve the best results, or set parameters as suggested by original papers. For AGS-MF, \(wn=100\), \(maxIter=200\), \(\gamma =0.002\) for three datasets; for Charlotte, \(d=40\), \(\lambda _u\), \(\lambda _l\), \(\lambda _\varOmega \), and \(\lambda _\varTheta \) are all set as 0.005, \(\alpha _u=0.08\) and \(\alpha _l=0.8\); for Phoenix and Las Vegas, \(d=30\), \(\lambda _u\), \(\lambda _l\), \(\lambda _\varOmega \), and \(\lambda _\varTheta \) are all set as 0.001, \(\alpha _u=0.02\) and \(\alpha _l=0.8\).
5.2 Results and Analysis
Results of AGS-MF Variants. Figure 2 presents the experimental results of different AGS-MF variants. We cumulatively incorporate the selected meta-paths into AGS-MF and record the performance change accordinglyFootnote 2.
Generally, it can be observed that the performance becomes better as more meta-paths are incorporated. Overall, the meta-paths starting with L deliver more significant enhancement than the ones starting with U. In particular, with the incorporation of meta-path LL which encodes geographical influence, the performance is enhanced significantly by 42.70%, 51.76% and 22.33% averagely in terms of precision, recall and MAP across different settings of N over three datasets. The great improvements by LL reinforce the effectiveness of geographical influence on user check-in behavior. Besides, the slight performance fluctuation reveals that certain meta-paths might be ineffective for some users, even cause some noises. This issue is eased by exploiting personalized weights for different meta-paths, i.e., AGS-MF can determine the saliency of each meta-path for each user and POI, implying it can well deal with noisy information. Thus, AGS-MF still consistently generates decent results with all meta-paths.

Effect of meta-paths on the three datasets when meta-paths are gradually incorporated into AGS-MF.
Comparative Results. Table 2 provides the performance of all comparison methods on the three real-world datasets. Unsurprisingly, UCF, ICF and MF perform worse than other methods as they only consider user-POI interactions without any other auxiliary information. By considering relevant influential factors, the state-of-the-arts (e.g., LFBCA, TriRank, AGSRec, GeoSoCa) outperform all baseline methods.
Compared with state-of-the-art methods, our proposed approach performs better. This implies that recommendation performance can be further enhanced by appropriately considering the three influences. Our approach incorporates various influential factors in a non-trivial manner, i.e., leverages AGS-IG to unify them seamlessly, and learns the personalized weights of each user and POI. In particular, AGS-MF promotes the recommendation performance by a large margin, i.e., precision, recall and MAP are improved by 18.28%, 12.82% and 21.71% on average across different settings of N on the three datasets (with \(p-value < 0.01\)), compared with the best of other comparison approaches. Moreover, AGS-MF consistently outperforms other state-of-the-art methods with any setting of d. In particular, by learning personalized weights for different meta-paths, AGS-MF outperforms AGSRec in most cases by significant percentages. The precision, recall and MAP are averagely boosted by 13.36%, 8.94%, 16.89% across different settings of N on the three datasets, respectively (with \(p-value < 0.01\)). Especially, AGS-MF consistently outperforms AGSRec in terms of MAP, indicating AGS-MF provides recommendations with better ranking quality by exploiting various influential factors via an integrate way.
6 Conclusion and Future Work
This paper focuses on exploiting the heterogeneous information in LBSNs to model both diversity and imbalance properties of user check-in behavior in a unified way. We first propose a novel knowledge graph (AGS-IG) by fusing social influence, geographical influence and aspects into a unified space, whereby we develop a novel POI recommendation approach – AGS-MF. It learns personalized weights of various influential factors in an automatic fashion. Empirical study on multiple real-world datasets demonstrates that our proposed method significantly outperforms state-of-the-art algorithms.
Notes
- 1.
- 2.
Due to space limitation, we only show the results with \(N =5,10\) (N is the number of POI recommendations) and similar trends can be observed when \(N = 20\).
References
Bottou, L.: Large-scale machine learning with stochastic gradient descent. In: Lechevallier, Y., Saporta, G. (eds.) COMPSTAT 2010, pp. 177–186. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-7908-2604-3_16
Cheng, C., Yang, H., King, I., Lyu, M.R.: Fused matrix factorization with geographical and social influence in location-based social networks. In: AAAI, vol. 12, p. 1 (2012)
Guo, Q., Sun, Z., Zhang, J., Chen, Q., Theng, Y.L.: Aspect-aware point-of-interest recommendation with geo-social influence. In: UMAP, pp. 17–22. ACM (2017)
He, X., Chen, T., Kan, M.Y., Chen, X.: TriRank: review-aware explainable recommendation by modeling aspects. In: CIKM (2015)
Jamali, M., Ester, M.: A matrix factorization technique with trust propagation for recommendation in social networks. In: RecSys, pp. 135–142. ACM (2010)
Ma, H., Zhou, D., Liu, C., Lyu, M.R., King, I.: Recommender systems with social regularization. In: WSDM, pp. 287–296. ACM (2011)
Salakhutdinov, R., Mnih, A.: Probabilistic matrix factorization. In: NIPS, vol. 1, pp. 1–2 (2007)
Sun, Y., Han, J., Yan, X., Yu, P.S., Wu, T.: Pathsim: meta path-based top-k similarity search in heterogeneous information networks. VLDB Endow. 4(11), 992–1003 (2011)
Wang, H., Terrovitis, M., Mamoulis, N.: Location recommendation in location-based social networks using user check-in data. In: SIGSPATIAL (2013)
**e, M., Yin, H., Wang, H., Xu, F., Chen, W., Wang, S.: Learning graph-based POI embedding for location-based recommendation. In: CIKM, pp. 15–24. ACM (2016)
Ye, M., Yin, P., Lee, W.C., Lee, D.L.: Exploiting geographical influence for collaborative point-of-interest recommendation. In: SIGIR, pp. 325–334. ACM (2011)
Yuan, Q., Cong, G., Sun, A.: Graph-based point-of-interest recommendation with geographical and temporal influences. In: CIKM, pp. 659–668. ACM (2014)
Zhang, J.D., Chow, C.Y.: Geosoca: Exploiting geographical, social and categorical correlations for point-of-interest recommendations. In: SIGIR, pp. 443–452. ACM (2015)
Zhang, J.D., Chow, C.Y., Zheng, Y.: ORec: an opinion-based point-of-interest recommendation framework. In: CIKM, pp. 1641–1650. ACM (2015)
Zhang, Y., Zhang, H., Zhang, M., Liu, Y., Ma, S.: Do users rate or review? Boost phrase-level sentiment labeling with review-level sentiment classification. In: SIGIR (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Guo, Q., Sun, Z., Zhang, J., Theng, YL. (2019). Modeling Heterogeneous Influences for Point-of-Interest Recommendation in Location-Based Social Networks. In: Bakaev, M., Frasincar, F., Ko, IY. (eds) Web Engineering. ICWE 2019. Lecture Notes in Computer Science(), vol 11496. Springer, Cham. https://doi.org/10.1007/978-3-030-19274-7_6
Download citation
DOI: https://doi.org/10.1007/978-3-030-19274-7_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-19273-0
Online ISBN: 978-3-030-19274-7
eBook Packages: Computer ScienceComputer Science (R0)