
Abstract
Collaborative filtering (CF) has been widely used in quality of service (QoS) prediction. However, most of traditional CF-based methods always suffer from overestimation of similarity computation and invalid neighbors. To address these problems, we propose a two-phase QoS prediction approach based on restricted Boltzmann machine (RBM). In the first phase, we propose an RBM-based approach to predict missing QoS values for invalid neighbors, which can identify similar neighbors with high accuracy. In the second phase, we propose a user-based CF method to predict, which utilizes user similar neighbors. Experimental results conducted in a real-world dataset show that our approaches can produce superior prediction accuracy and are not sensitive to parameter settings.
The two authors Yuyu Yin and Lu Chen contribute equally to this paper, so they are co-first authors.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
With the number of Web services growing dramatically, different service providers offer many Web services with the same or similar functions. It has been an urgent task to recommend suitable services for users from a large number of service candidates [1]. There are two types of properties for a service, functional properties and non-functional properties. The non-functional properties are also known as quality-of-service (QoS). It is a spotlight of how to improve the prediction accuracy of QoS and how to provide service recommendation with high quality [2].
In recent years, many researchers have applied collaborative filtering (CF) to QoS prediction and obtained better prediction accuracy [2]. A crucial task of CF-based methods is to identify neighbors. The prediction accuracy largely relies on the quality of the identified neighbors. To improve the quality of identified neighbors, some existing works focus on the improvement of similarity computation. But in the case of high data sparsity, we notice that the number of neighbors of a user is quite limited. Also, there exist some invalid neighbors that need to be filtered, which did not invoke the target service or are not observed by the target user (we name these neighbors as invalid neighbors) and those neighbors will be not used to predict missing QoS values. Such filtering is likely to lead to low prediction accuracy because of lack of available neighbors.
To address these problems, we propose a two-phase approach for QoS prediction, which is based on restricted Boltzmann machine (RBM). The first prediction phase is to predict missing values for invalid neighbors, and further identify similar neighbors. The second prediction phase is to compute the final prediction results by user-based CF method. From the experimental results, it can be seen that our approach can make better use of identified neighbors and alleviate data sparsity problem.
In summary, the main contributions of this paper are as follows.
-
1.
It proposes a novel neighbors selection method. It employs RBM model to predict missing values for invalid neighbors, and further filters the neighbors with network location and geographical information. The proposed method can complete the task of selecting high-quality neighbors.
-
2.
It conducts sufficient experiments on a real-world dataset, and compares the proposed methods to many existing methods. The experimental results demonstrate the effectiveness and high robustness to parameter values of our method.
The rest of this paper is organized as follows. Section 2 discusses the related work. Sections 3 and 4 elaborate the proposed approach, and the experimental results are presented in Sect. 5. Section 6 concludes the whole paper.
2 Related Work
The traditional CF methods can be classified into two categories: neighbor-based methods and model-based methods [2]. Many neighbor-based CF methods have achieved success in recommendation systems [3]. Wu et al. [4] proposed a ratio-based method to compute similarity, which improved the prediction accuracy and could be computed faster than other compared methods.
One difficulty in neighbor-based CF methods is the data sparsity problem [5]. Owing to the high sparsity of data, the neighbor-based CF methods cannot accurately obtain similar neighbors. In recent years, some studies try to solve this problem. Wu et al. [5] proposed a time-aware neighbor-based CF approach with better accuracy at high sparsity. These earlier works put attention to similarity computation, but this paper also focuses the selection of neighbors.
Moreover, it is difficult for neighbor-based methods to handle large amount of data. Therefore, researchers turned to study model-based CF methods. There are several representative model-based approaches, including Matrix Factorization (MF) [6] and restricted Boltzmann machine (RBM) [7]. In recent years, some researchers exploited the potential of RBM in extracting features and solving data sparsity problem [8].
To fully take advantage of neighbor-based methods and model-based methods, some researchers tried to combine the two types of approaches. Inspired by such an idea, in this paper, we propose a novel model by both leveraging the RBM-based model and neighbor-based model to predict missing QoS values.
3 The Whole Framework
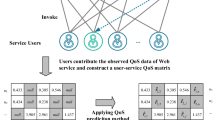
We present the proposed whole framework in Fig. 1, which consists of two phases.

The whole framework
In the first phase, we use the Euclidean distance to compute the similarity among users. The similarity computation result is used to build the initial similar neighbors set. Next, we employ RBM model to predict all missing QoS values for invalid neighbors. We further identify fine-grained neighbors from the initial neighbors set based on network location and geographical information. In the second phase, we propose the user-based CF model to predict final results.
4 The Proposed Prediction Approach
4.1 The First-Phase Prediction
Similarity Computation.
In this section, we propose a Euclidean distance in similarity computation.
where \( S_{u,v} \) is the similarity of user u and user v. \( M = M_{u} { \cap }M_{v} \) is the set of services that are invoked by both user u and user v, \( q_{u,i} \) is the QoS value of target service i invoked by target user u, and \( q_{v,i} \) is the QoS value of target service i invoked by user v. We add a one value in the denominator to prevent the denominator from being zero. \( \bar{q}_{u} \) is the average QoS of user u and \( \bar{q}_{v} \) is the average QoS of user v.
Neighbors Selection.
After the similarity computation between different users and different services, we could have directly chosen the top K most similar neighbors. However, in the current neighbors set, some neighbors are not applicable, because such neighbors probably do not have invoked each target service, which lowers the number of available neighbors and further damages prediction accuracy. To fix this issue, we propose to use RBM model to predict missing QoS values for those neighbors which have not invoked a target service (in user side). Our aim is to ensure that all neighbors can be applicable for reliable prediction. Meanwhile, we further filter some other neighbors by utilizing the network location and geographical information. Such filtering can improve the quality of similar neighbors. Then, a similar neighbors’ set N(u) of user u is finally formed. N(u) is composed of two subsets N1(u) and N2(u). N1(u) is the set of predicted neighbors and N2(u) is the set of valid neighbors.
Prediction Based on RBM Model.
The next task is the missing QoS values prediction for the users in set N1(u). We propose an RBM model to finish this task. Suppose that we have M services, N users, rounded QoS values from 1 to K, and a user invoked m services. Each user is treated as a single training case of an RBM, and we still use an RBM to predict missing values. Each RBM shares the same number of hidden units H that represent features, but an RBM only has visible softmax units U for the services invoked by that user. An RBM can only have a few connections in high sparsity of the real case of services invocation. Let U be a \( K \times m \) observed binary indicator matrix with \( u_{i}^{k} = 1 \) if the user u has invoked service i as the value of being k, and 0 otherwise. The energy function of user-oriented RBM is defined as
where \( W_{i,j}^{k} \) is a symmetric interaction parameter between the QoS value k of the i-th service and the j-th feature. \( b_{i}^{k} \) and bj are two biases to reflect the innovation preference of services i and j. \( Z_{i} = \sum\limits_{k = 0}^{K} {\exp (b_{i}^{k} + \sum\limits_{j} {h_{j} W_{i,j}^{k} } )} \) is the normalization term that ensures \( \sum\limits_{k = 0}^{K} {P(u_{i}^{k} = 1|h)} = 1 \). According to the conditional multinomial distribution and conditional Bernoulli distribution, the distributions of services and features are
where \( \sigma (x) = 1/1 + \exp ( - x) \) is the sigmoid activation function. With the conditional distributions in Eqs. (3) and (4), we can directly use the contrastive divergence algorithm for training [9], in which the updates for each parameter are as follows.
where \( \left\langle \cdot \right\rangle_{data} \) represents the probability distribution of a hidden layer in the case of a visible unit. \( \left\langle \cdot \right\rangle_{rec} \) represents the probability distribution of the model definition after the reconstruction using the contrastive divergence algorithm, and \( \varepsilon \) is the learning rate. Among these, \( u_{i} > 0 \) ensures that only the data that satisfy \( u_{i} > 0 \) are used in the model.
After the model is trained, the probability that a user v invokes a service i with a QoS value being k can be obtained directly based on the known QoS values set U. The RBM prediction of the missing QoS value \( \hat{q}_{v,i} \) is:
where \( \hbox{max} (P(v_{i}^{k} = 1|V)_{l} ) \) is the maximum value of the probability that the user v invoked the service i and the received QoS is k, and l is the score corresponding to the maximum value of the probability.
4.2 The Second-Phase Prediction
To improve the final prediction accuracy, we also propose a user-based CF method to predict in the second phase.
The neighbors set N(u) for target user u is generated in the first-phase, which has two subsets, that is, the predicted neighbors set N1(u) and valid neighbors set N2(u). The final prediction result is computed as follows.
where \( \hat{q}_{{v_{1} ,i}} \) represents the first-phase prediction results of target service i after being invoked by user v1. \( S_{{u,v_{1} }} \) is the similarity of target user u and user v1. \( q_{{v_{2} ,i}} \) is the QoS value of target service i after being invoked by user v2. \( S_{{u,v_{2} }} \) is the similarity of target user u and user v2.
5 Experiment and Evaluation
We use the public dataset WSDream to conduct the experiments [10]. This dataset has been widely used by many researchers. WSDream dataset contains 5825 services and 339 users, including two QoS attributes: response time and throughput.
5.1 Evaluation Metric and Parameter Setting
We use the mean absolute error (MAE) and normalized mean absolute error (NMAE) metrics to evaluate the prediction accuracy. MAE and NMAE are computed as
where \( q_{u,i} \) represents the real QoS value, \( \hat{q}_{u,i} \) represents the prediction result, and N is the number of values in test set.
5.2 Performance Comparison
In order to reflect the real case of service invocation, we randomly select a part of data from the original WSDream dataset as training set, and the rest data form the test set. In this study, we generate four training sets with different sparsities, where the sparsity degree d is 2.5%, 5%, 10%, 15%, and 20%, respectively.
To better evaluate the performance of the proposed method, we compare our methods with the following state-of-the-art competitive QoS prediction methods. The experimental results are present in Table 1. The parameters in the compared methods are set according to the default settings in their original papers.
-
1.
RBM (restricted Boltzmann machine) [7]: This method uses the RBM-based CF algorithm to predict missing values.
-
2.
WSRec [10]: A hybrid model composed of user-based CF and item-based CF.
-
3.
LFM (latent factor model) [6]: LFM decomposes the user-service matrix by dimensionality reduction to learn implicit features and produce predictions.
-
4.
CAP (credibility-aware prediction model) [11]: CAP is a novel credibility-aware QoS prediction method, which employs two-phase K-means clustering algorithm.
-
5.
JLMF [12]: JLMF is an MF model based on network location information and influence of neighbors.
-
6.
LE-MF (location-enhanced matrix factorization) [13]: A matrix decomposition model that introduces location information and trust mechanism.
-
7.
U-RBM (user-oriented RBM): Our proposed model with being named as U-RBM.
In Table 1, MAE is the mean absolute error, NMAE is the normalized mean absolute error, and d is the sparsity of training sets. We can have following observations.
-
1.
The proposed prediction methods U-RBM is superior to the compared methods in on both MAE and NMAE measures.
-
2.
In all cases of training set densities, our proposed models achieve consistently lower errors. Specially, in the case of high data sparsity (e.g., d = 2.5% and 5%), the prediction accuracy of U-RBM model is still the highest, which indicates that U-RBM can better deal with data sparsity problem.
5.3 Sensitivity Analysis of Parameters
Impact of TopKUser.
The parameter TopKUser denotes the number of similar neighbors. A higher sparsity means less available training data. The evaluated value of TopKUser is from 4 to 20.
As shown in Fig. 2, with the increase of TopKUser, MAE values decrease initially. This is because as the number of similar neighbors increases, the probability of selecting the real similar neighbors of a target user becomes larger. Also, the similar neighbor filtering adds those users that are highly similar to the target user. This is because there are no public invocation records, and those users are prevented from being similar neighbors on account of other users who do not have a strong similarity but are still selected. So the reliability of similar neighbors is enhanced.

Impact of TopKUser
6 Conclusions
In this paper, we propose an approach for QoS prediction based on RBM model. We proposed a novel similarity computation method. Then, the RBM was proposed to predict missing values for invalid neighbors. We also employed network location and geographical information to further improve the selection quality of neighbors. The extensive experiments conducted in a real-world dataset verified the effectiveness of our models.
References
Wu, Y., **e, F., Chen, L., Chen, C., Zheng, Z.: An embedding based factorization machine approach for web service QoS prediction. In: Maximilien, M., Vallecillo, A., Wang, J., Oriol, M. (eds.) ICSOC 2017. LNCS, vol. 10601, pp. 272–286. Springer, Cham (2017a). https://doi.org/10.1007/978-3-319-69035-3_19
Zheng, Z., Ma, H., Lyu, M.R.: QoS-aware web service recommendation by collaborative filtering. IEEE Trans. Serv. Comput. 1(2), 140–152 (2010)
Yin, Y., Yu, F., Xu, Y., et al.: Network location-aware service recommendation with random walk in cyber-physical systems. Sensors 17(9), 2059 (2017)
Wu, X., Cheng, B., Chen, J.L.: Collaborative filtering service recommendation based on a novel similarity computation method. IEEE Trans. Serv. Comput. 10(3), 352–365 (2017b)
Wu, C., Qiu, W., Wang, X., et al.: Time-aware and sparsity-tolerant QoS prediction based on collaborative filtering. In: IEEE ICWS, pp. 637–640 (2016)
Koren, Y., Bell, R., Volinsky, C.: Matrix factorization techniques for recommender systems. ACM Comput. 42(8), 30–37 (2009)
Salakhutdinov, R., Mnih, A., Hinton, G.: Restricted Boltzmann machines for collaborative filtering. In: International Conference on Machine Learning, pp. 791–798 (2007)
Tramel, E.W., Manoel, A., Caltagirone, F., et al.: Inferring sparsity: compressed sensing using generalized restricted Boltzmann machines. In: Information Theory Workshop, pp. 265–269 (2016)
Hinton, G.E.: Training products of experts by minimizing contrastive divergence. Neural Comput. 14(8), 1771–1800 (2002)
Zheng, Z., Ma, H., Lyu, M.R., et al.: WSRec: a collaborative filtering based web service recommender system. In: IEEE ICWS, pp. 437–444 (2009)
Wu, C., Qiu, W., Zheng, Z., et al.: QoS prediction of web services based on two-phase K-means clustering. In: IEEE ICWS, pp. 161–168 (2015)
Yin, Y., Song, A., Min, G., et al.: QoS prediction for web service recommendation with net-work location-aware neighbor selection. Int. J. Softw. Eng. Knowl. Eng. 26(4), 611–632 (2016)
Xu, Y., Yin, J., Deng, S., et al.: Context-aware QoS prediction for web service recommendation and selection. Expert Syst. Appl. 53(C), 75–86 (2016)
Acknowledgments
This paper is supported by National Natural Science Foundation of China (No. 61702391), Natural Science Foundation of Zhejiang Province (No. LY12F02003) and Shaanxi Province (No. 2018JQ6050), National Key Technology Support Program (No. 2015 BAH17F02) and Fundamental Research Funds for Central Universities (JBX171007).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Chen, L., Yin, Y., Xu, Y., Chen, L., Wan, J. (2018). Two-Phase Web Service QoS Prediction with Restricted Boltzmann Machine. In: Pahl, C., Vukovic, M., Yin, J., Yu, Q. (eds) Service-Oriented Computing. ICSOC 2018. Lecture Notes in Computer Science(), vol 11236. Springer, Cham. https://doi.org/10.1007/978-3-030-03596-9_43
Download citation
DOI: https://doi.org/10.1007/978-3-030-03596-9_43
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-03595-2
Online ISBN: 978-3-030-03596-9
eBook Packages: Computer ScienceComputer Science (R0)