
Abstract
Automatic parsing of anatomical objects in X-ray images is critical to many clinical applications in particular towards image-guided invention and workflow automation. Existing deep network models require a large amount of labeled data. However, obtaining accurate pixel-wise labeling in X-ray images relies heavily on skilled clinicians due to the large overlaps of anatomy and the complex texture patterns. On the other hand, organs in 3D CT scans preserve clearer structures as well as sharper boundaries and thus can be easily delineated. In this paper, we propose a novel model framework for learning automatic X-ray image parsing from labeled CT scans. Specifically, a Dense Image-to-Image network (DI2I) for multi-organ segmentation is first trained on X-ray like Digitally Reconstructed Radiographs (DRRs) rendered from 3D CT volumes. Then we introduce a Task Driven Generative Adversarial Network (TD-GAN) architecture to achieve simultaneous style transfer and parsing for unseen real X-ray images. TD-GAN consists of a modified cycle-GAN substructure for pixel-to-pixel translation between DRRs and X-ray images and an added module leveraging the pre-trained DI2I to enforce segmentation consistency. The TD-GAN framework is general and can be easily adapted to other learning tasks. In the numerical experiments, we validate the proposed model on 815 DRRs and 153 topograms. While the vanilla DI2I without any adaptation fails completely on segmenting the topograms, the proposed model does not require any topogram labels and is able to provide a promising average dice of \(85\%\) which achieves the same level accuracy of supervised training (88%).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Semantic understanding of anatomical objects in X-ray images is critical to many clinical applications, such as pathological diagnosis, treatment evaluation and surgical planning. It serves as a fundamental step for computer-aided diagnosis and can enable intelligent workflows including organ-based autocollimation, infinite-capture range registration, motion compensation and automatic reporting. In this paper, we study one of the most important problems in semantic understanding of X-ray image, i.e., multi-organ segmentation.
While X-ray understanding is of great clinical importance, it remains a very challenging task, mainly due to the projective nature of X-ray imaging, which causes large overlap** of anatomies, fuzzy object boundaries and complex texture patterns. Conventional methods rely on prior knowledge of the procedure (e.g., anatomical motion pattern from a sequence of images [1]) to delineate anatomical objects from X-ray images. Modern approaches utilize deep convolutional networks and have shown superior performance [2]. However, they typically require a large amount of pixel-level annotated training data. Due to the heterogeneous nature of X-ray images, accurate annotating becomes extremely difficult and time-consuming even for skilled clinicians. On the other hand, large pixel-level labeled CT data are more accessible. Thousands of X-ray like images, the so-called Digitally Reconstructed Radiographs (DRRs), are generated from labeled CTs and used in [3] to train an X-ray depth decomposition model. While using automatically generated DRRs/labels for training has merits, the trained model cannot be directly applied on X-ray images due to their appearance
Generalization of image segmentation models trained on DRRs to X-ray images requires unsupervised domain adaptation. While many effective models [4, 5] have been studied, most of them focus on feature adaptation which naturally suits for recognition and detection. However, segmentation task desires pixel-wise classification which requires delicate model design and is substantially different. Recently, pixel-level adaptation models [6, 7] have been proposed which utilize generative adversarial networks and achieve promising results on image synthesis and recognition. Still, continuing study on image segmentation especially for medical applications remains blank.
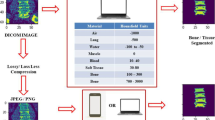
In this paper, we present a novel model framework to address this challenge. Specifically, we first create DRRs and their pixel-level labeling from the segmented pre-operative CT scans. A Dense Image-to-Image network (DI2I) [8, 9] is then trained for multi-organ (lung, heart, liver, bone) segmentation over these synthetic data. Next, inspired by the recent success of image style transfer by cycle generative adversarial network (cycle-GAN) [7], we introduce a task driven generative adversarial network (TD-GAN) to achieve simultaneous image synthesis and automatic segmentation on X-ray images, see Fig. 1 for an overview. We emphasize that the training X-ray images are unpaired with previous DRRs and are totally unlabeled. TD-GAN consists of a modified cycle-GAN substructure for pixel-to-pixel translation between DRRs and X-ray images. Meanwhile, TD-GAN incorporates the pre-trained DI2I to obtain deep supervision and enforce consistent performance on segmentation. The intuition behind TD-GAN is indeed simple: we transfer X-ray images in the same appearance as DRRs and hence leverage the pre-trained DI2I model to segment them. Furthermore, the entire transfer is guided by the segmentation supervision network.
The contributions of our work are: (1) We propose a novel model pipeline for X-ray image segmentation from unpaired synthetic data (DRRs). (2) We introduce an effective deep architecture TD-GAN for simultaneously image synthesis and segmentation without any labeling effort necessary from X-ray images. To our best knowledge, this is the first end-to-end framework for unsupervised medical image segmentation. (3) The entire model framework can be easily adjusted for unsupervised domain adaptation problem where labels from one domain is completely missing. (4) We conduct numerical experiments and demonstrated the effectiveness of the proposed model with over 800 DRRs and 150 X-ray images.

Overview of the proposed task driven generative model framework.
2 Methodology
2.1 Problem Overview
In this paper, our goal is to learn a multi-organ segmentation model on unlabeled X-ray images using pixel-wise annotated DRRs data. Furthermore, these images are not paired, which means they are not taken from the same group of patients. We collected X-ray images that contain targeted organs such lung, heart, liver and bone (or a subset of them). The DRRs of the same region of interest (ROI) are generated by placing 3D labeled CT volumes in a virtual imaging system that simulates the actual X-ray geometry. Meanwhile, the pixel-level labeling of DRRs are generated by projecting 3D CT labels along the same trajectories. While most public datasets for multi-organ segmentation only consists of tens of cases, our dataset covers a richer variety of scanning ranges, contrast phases as well as morphological differences. In the next subsections, we first train a DI2I on the DRRs and then adapt it to the X-ray images with TD-GAN to provide deep segmentation supervision during the image synthesis.
2.2 Dense Image to Image Network for Segmentation on DRRs
We train a Dense Image-to-Image network (DI2I) on the labeled DRRs data. As is depicted in Fig. 2, the network employs an encoder-decoder UNet structure with dense blocks [2, 8, 9]. The network consists of dense blocks which are generalizations from ResNets [10] by iteratively concatenating all feature outputs in a feed-forward fashion. This helps alleviating the vanishing gradient problem and thus can obtain a deeper model with higher level feature extraction. Despite these appealing properties, empirically we found that it achieved superior performance than classical UNet. The final output feature map has five channels which consists of a background channel \(x_0\) and four channels \(x_1,...,x_4\) corresponding to the four organs. By doing so, we alleviate the challenge of segmenting overlapped organs and simplify the problem into binary classifications. We further use a customized loss term which is a weighted combination of binary cross entropies between each organ channel and background channel,
where \(y_i\) is the ground truth binary label map for each organ and \(p_i\) is calculated as \( \exp (x_i)/(\exp (x_0) + \exp (x_i))\) for \(i=1,2,3,4\).

Illustration of the DI2I for segmentation on DRRs.

Proposed TD-GAN architecture. Real X-ray images and DRRs are passed through 4 different paths for simultaneously synthesis and segmentation.
2.3 Task Driven Generative Adversarial Networks (TD-GAN)
We now describe the main deep architecture of TD-GAN. The network has a modified cycle-GAN [7] sub-structure with add-on segmentation supervisions. As is depicted in Fig. 3, the base structure consists of two generators \(G_1, G_2\) and two discriminators \(D_1, D_2\) to achieve pixel-to-pixel image synthesis. The generators try to synthesize images in the appearance of the other protocol while the discriminators need to distinguish the generated images (fake) against the reals. When the cyclic training converges to optimal, the network will be able to transfer X-ray images to DRRs through \(G_2\) and transfer back through \(G_1\). This also holds for DRRs. However, image synthesis only serves for a general purpose of appearance transfer and is not segmentation focused. Important prior knowledge such as organ boundaries, shapes and local variations are not carefully treated and could possibly lose during the synthesis process. We therefore add supervision modules to enforce the segmentation consistency, that is, during the transfer process we require the X-ray images that not only have the appearance of DRRs but also can be segmented by the pre-trained DI2I network. This is done by introducing conditional adversarial training on the translation of X-ray images and cycle segmentation consistency on DRRs. We detail this later on.
The proposed TD-GAN involves 4 different paths that transfer and reconstruct images between the two protocols: real DRR \(\rightarrow \) fake X-ray, real X-ray \(\rightarrow \) fake DRR, real X-ray \(\rightarrow \) reconstructed X-ray and real DRR \(\rightarrow \) reconstructed DRR. Different losses are proposed for each path. We discuss the meaning of these paths in a top-down topological order that is shown in Fig. 3. We denote the data distribution \(d\sim p_d\) and \(x \sim p_x\) for DRRs and X-ray images. Our main contribution comes in the segmentation driven losses in path real X-ray \(\rightarrow \) fake DRR and real DRR \(\rightarrow \) reconstructed DRR.
Real DRR \(\rightarrow \) Fake X-ray. Given a real DRR image, the generator \(G_1\) tries to produce the corresponding image in the appearance of X-ray images. The discriminator \(D_1\) will need to distinguish the generated fake X-ray image and the real. Since we do not have any paired X-ray images with the DRRs, this real X-ray image is randomly selected from the training dataset. A successful generation from \(G_1\) will confuse \(D_1\) to make the wrong prediction. The loss function involved is a standard GAN loss for image style transfer,
Real X-ray \(\rightarrow \) Fake DRR. The other generator \(G_2\) will produce a fake DRR to challenge \(D_2\). We could also randomly select a real DRR in the training of \(D_2\). However, this is suboptimal since the labels of DRRs will be unused which contain important organ information such as size, shape and location and are crucial to our final segmentation task. Inspired by the conditional GANs [11], we leverage the pre-trained DI2I to predict the organ labels on the fake DRRs. The fake DRRs combined with their predicted labels are then fed into \(D_2\) to compare with the real pairs. Therefore \(D_2\) needs to not only distinguish the fake DRRs and the reals but also determine whether the image-label pairs are realistic. To confuse \(D_2\), the generator \(G_2\) will particularly focus on the organs of interest during the image transfer. We hence will obtain a more powerful generator in the task of segmentation. Finally, to make the involved loss function differentiable, we only obtain the predicted probability map from the DI2I and do not binarize them. Denote \(U(\cdot )\) as the pre-trained DI2I, we have the following loss function for this path,
We remark that the pre-trained DI2I is frozen during the training of TD-GAN, otherwise the supervision will be disturbed by the fake DRRs. Furthermore, TD-GAN can be easily adapted to other tasks by replacing \(U(\cdot )\).
Real X-ray \(\rightarrow \) Reconstructed X-ray. The idea behind this path is that once we transferred a X-ray image to a fake DRR through \(G_2\), we should be able to transfer this DRR back to X-ray image through \(G_1\). The final (reconstructed) X-ray image should be the same as the original one. This is called cycle-consistency. The corresponding loss function is calculated by \(l_1\) distance,
Real DRR \(\rightarrow \) Reconstructed DRR. Same argument also applies to the DRR reconstruction. Moreover, we enforce the reconstructed DRR to maintain cycle segmentation consistency by adding a segmentation loss as a regularization term. The implies that we would like that the reconstructed DRR is not only close to the original but maintain the same segmentation performance under DI2I. The two losses involved in this path are as follows,
where the segmentation loss \(\mathcal {L}_{seg}\) is the same as in Eq. (1).
The total loss for TD-GAN is then a weighted summation of all the losses in the above paths. We demonstrate the effectiveness of these two losses in the experiments. We employ the same parameter setting as is suggested in [7]. The generator \(G_1\) and \(G_2\) utilize a same Resnet20 structure. The discriminator \(D_1\) and \(D_2\) contains four consecutive convolutional layers with increasing number of filters from 64 to 512 and a final output layer with sigmoid activation.
3 Experiments and Results
In this section we validate our methodology on a dataset of 815 labeled DRRs and 153 topograms. The topograms are acquired before the CT scan for isocentering and therefore co-registered with the CT. The CT scans are labeled pixel-wisely and the labels of topograms are generated in a same way as the aforementioned DRRs masks. The co-registered CT is not used in training and the labels on topograms are used only for evaluation purpose. Our model is among the first approaches to address unsupervised domain adaptation for segmentation with unpaired data. We compare with the state-of-the-art image synthesis model cycle-GAN [7] since both can be used in our problem except ours are task driven. To further show the effectiveness of the deep architecture and the proposed losses, we also compare our models with TD-GAN adversarial (TD-GAN-A) and TD-GAN reconstruction segmentation (TD-GAN-S) by enabling either one of the conditional adversarial loss (2) and the cycle segmentation consistency loss (3).
We first train a DI2I for multi-organ segmentation on the labeled DRRs. A standard 5 fold cross-validation scheme is used to find the best learned weights. We evaluate the dice score on the testing dataset, summarized as follows (mean ± std): lung 0.9417 ± 0.017, heart 0.923 ± 0.056, liver 0.894 ± 0.061 and bone 0.910 ± 0.020. All the experiments are run on an 12GB NVIDIA TITAN X GPU.

Visualization of segmentation results on topograms (bottom) against direct application of DI2I (top). The red curves stands for the boundary of the ground truth. The colored fill-in parts are the predictions by TD-GAN and DI2I.
Next we load the pretrained DI2I into TD-GAN with weights all frozen and train the model to segment the topograms. We use all the DRRs as well as 73 topograms for training, 20 topograms for validation and 60 for testing. We visualize one example and compare the proposed method against vanilla setting (where the DI2I is tested directly on topograms) in Fig. 4. For better visualization purpose, we only show the ground the truth labeling for lung, heart and liver. The numerical results are summarized in Table 1. To better understand the performance of our model, we also train the DI2I on the topograms using their labels under the same data splitting setting, listed as Supervised in Table 1.
While the direct application of the learned DI2I on topograms fails completely, it can be seen that our model significantly improved the segmentation accuracy and even provided the same level of accuracy compared with the supervised training with labeled topograms. Compared with the cycle-GAN which only performs image style transfer, both the partially task driven nets TD-GAN-A and TD-GAN-S can improve the performance. Furthermore, the final TD-GAN combines the advantages of all the three models and achieves the best.
4 Discussions and Conclusions
In this paper, we studied the problem on multi-organ segmentation over totally unlabeled X-ray images with labeled DRRs. Our model leverages a cycle-GAN substructure to achieve image style transfer and carefully designed add-on modules to simultaneously segment organs of interest. The proposed model framework is general. By replacing the DI2I with other types of supervision networks, it can be easily adapted to many scenarios in computer-aided diagnosis such as prostate lesion classification, anatomical landmark localization and abnormal motion detection. We leave this for the future direction.
References
Zhu, Y., Prummer, S., Wang, P., Chen, T., Comaniciu, D., Ostermeier, M.: Dynamic layer separation for coronary DSA and enhancement in fluoroscopic sequences. In: Yang, G.-Z., Hawkes, D., Rueckert, D., Noble, A., Taylor, C. (eds.) MICCAI 2009. LNCS, vol. 5762, pp. 877–884. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-04271-3_106
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Albarqouni, S., Fotouhi, J., Navab, N.: X-Ray in-depth decomposition: revealing the latent structures. In: Descoteaux, M., Maier-Hein, L., Franz, A., Jannin, P., Collins, D.L., Duchesne, S. (eds.) MICCAI 2017. LNCS, vol. 10435, pp. 444–452. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-66179-7_51
Bousmalis, K., et al.: Domain separation networks. In: NIPs (2016)
Tzeng, E., et al.: Adversarial discriminative domain adaptation. In: CVPR (2017)
Bousmalis, K., et al.: Unsupervised pixel-level domain adaptation with generative adversarial networks. In: CVPR (2017)
Zhu, J.Y., et al.: Unpaired image-to-image translation using cycle-consistent adversarial networks. ar**v preprint ar**v:1703.10593 (2017)
Huang, G., et al.: Densely connected convolutional networks. In: CVPR (2017)
Jégou, S., et al.: The one hundred layers tiramisu: fully convolutional densenets for semantic segmentation. In: CVPRW (2017)
He, K., et al.: Deep residual learning for image recognition. In: CVPR (2016)
Mirza, M., et al.: Conditional generative adversarial nets. ar**v preprint ar**v:1411.1784 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Additional information
Disclaimer: This feature is based on research, and is not commercially available. Due to regulatory reasons its future availability cannot be guaranteed.
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, Y., Miao, S., Mansi, T., Liao, R. (2018). Task Driven Generative Modeling for Unsupervised Domain Adaptation: Application to X-ray Image Segmentation. In: Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C., Fichtinger, G. (eds) Medical Image Computing and Computer Assisted Intervention – MICCAI 2018. MICCAI 2018. Lecture Notes in Computer Science(), vol 11071. Springer, Cham. https://doi.org/10.1007/978-3-030-00934-2_67
Download citation
DOI: https://doi.org/10.1007/978-3-030-00934-2_67
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-00933-5
Online ISBN: 978-3-030-00934-2
eBook Packages: Computer ScienceComputer Science (R0)