
Abstract
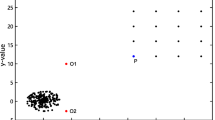
Outlier detection is concerned with discovering exceptional behaviors of objects in data sets. It is becoming a growingly useful tool in applications such as credit card fraud detection, discovering criminal behaviors in e-commerce, identifying computer intrusion, detecting health problems, etc. In this paper, we introduce a connectivity-based outlier factor (COF) scheme that improves the effectiveness of an existing local outlier factor (LOF) scheme when a pattern itself has similar neighbourhood density as an outlier. We give theoretical and empirical analysis to demonstrate the improvement in effectiveness and the capability of the COF scheme in comparison with the LOF scheme.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
A. Arning, R. Agrawal, P. Raghavan: ”A Linear Method for Deviation detection in Large Databases”, Proc. of 2nd Intl. Conf. On Knowledge Discovery and Data Mining, 1996, pp 164–169.
V. Barnett, T. Lewis: ”Outliers in Statistical Data”, John Wiley, 1994.
M. Breuning, Hans-Peter Kriegel, R. Ng, J. Sander: ”LOF: Identifying density based Local Outliers”, Proc. of the ACM SIGMOD Conf. On Management of Data, 2000.
W. DuMouchel, M. Schonlau: ”A Fast Computer Intrusion Detection Algorithm based on Hypothesis Testing of Command Transition Probabilities”, Proc.of 4th Intl. Conf. On Knowledge Discovery and Data Mining, 1998, pp. 189–193.
M. Ester, H. Kriegel, J. Sander, X. Xu: ”A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise”, Proc. of 2nd Intl. Conf. On Knowledge Discovery and Data Mining, 1996, pp 226–231.
T. Fawcett, F. Provost: ”Adaptive Fraud Detection”, Data Mining and Knowledge Discovery Journal, Kluwer Academic Publishers, Vol. 1, No. 3, 1997, pp 291–316.
D. Hawkins: ”Identification of Outliers”, Chapman and Hall, London, 1980.
E. Knorr, R. Ng: ”Algorithms for Mining Distance based Outliers in Large Datasets”, Proc. of 24th Intl. Conf. On Very Large Data Bases, 1998, pp 392–403.
E. Knorr, R. Ng: ”Finding Intensional Knowledge of Distance-based Outliers”, Proc. of 25th Intl. Conf. On Very Large Data Bases, 1999, pp 211–222.
R. Ng, J. Han: ”Efficient and Effective Clustering Methods for Spatial Data Mining”, Proc. of 20th Intl. Conf. On Very Large Data Bases, 1994, pp 144–155.
S. Ramaswamy, R. Rastogi, S. Kyuseok: ”Efficient Algorithms for Mining Outliers from Large Data Sets”, Proc. of ACM SIGMOD Intl. Conf. On Management of Data, 2000, pp 427–438.
N. Roussopoulos, S. Kelley, F. Vincent, ”Nearest Neighbor Queries”, Proc. of ACM SIGMOD Intl. Conf. On Management of Data, 1995, pp 71–79.
G. Sheikholeslami, S. Chatterjee, A. Zhang: ”WaveCluster: A multi-Resolution Clustering Approach for Very Large Spatial Databases”, Proc. of 24th Intl. Conf. On Very Large Data Bases, 1998, pp 428–439.
S. Guha, R. Rastogi, K. Shim: ”Cure: An Efficient Clustering Algorithm for Large Databases”, In Proc. of the ACM SIGMOD Conf. On Management of Data, 1998, pp 73–84.
J. Tang, Z. Chen, A. Fu and D. Cheung: ”A General Framework for Outlier Formulations: Density versus Connectivity”, Manuscript.
T. Zhang, R. Ramakrishnan, M. Linvy: ”BIRCH: An Efficient Data Clustering Method for Very Large Databases”, Proc. of ACM SIGMOD Intl. Conf. On Management of Data, 1996, pp 103–114.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2002 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Tang, J., Chen, Z., Fu, A.Wc., Cheung, D.W. (2002). Enhancing Effectiveness of Outlier Detections for Low Density Patterns. In: Chen, MS., Yu, P.S., Liu, B. (eds) Advances in Knowledge Discovery and Data Mining. PAKDD 2002. Lecture Notes in Computer Science(), vol 2336. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-47887-6_53
Download citation
DOI: https://doi.org/10.1007/3-540-47887-6_53
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-43704-8
Online ISBN: 978-3-540-47887-4
eBook Packages: Springer Book Archive