
Abstract
Globally, the Manila clam (Ruditapes philippinarum) stands as the second most important bivalve species in fisheries and aquaculture. Native to the Pacific coast of Asia, it is now well-established in North America and Europe, where its on-going management reflects local economic interests. The historic record of transfers spans the 20th century and suggests sequential movement from Japan to North America, as a hitch-hiker on oysters, and then intentional introduction in Europe, but global genetic data are missing. We have studied mitochondrial DNA and microsatellite markers in nine populations from Asia, North America and Europe. The results from the two types of markers indicated a good concordance of present-day genetic structure with the reported history of clam transfers across continents, and no evidence of relevant concealed introductions from continental Asia in Europe and North America. However, European populations showed a loss of genetic variability and significant genetic differentiation as compared to their American counterparts. Our study shows that in spite of the increasing ease for species to spread out of their native range, in the case of the Manila clam this has not resulted in new invasion waves in the two studied continents.
Similar content being viewed by others
Introduction
One of the consequences of global change on marine ecosystems is the sudden introduction of species in new areas, which often show an invasive behavior and interact strongly with native species leading to changes in the ecosystem function1,2. In some cases, a species is introduced intentionally to expand the economy of the region3,4, or it creates an economic opportunity in the newly-colonized area5. In all situations, the management of the species has to deal with complex interactions between ecosystem health and human economic and social interests. Genetic characterization of species in this context is of special importance to achieve adequate management strategies6. Genetic resources of the introduced species can be constrained by the geographic source of the colonizers, founder effects, the size of the founder population (propagule size), the number of independent introductions and the initial demography7,8,9,10,11. However, species-specific studies focused on genetic structure often fail to align with predictions based on the known introduction history (e.g.: refs 12 and 13). In general, it seems necessary to test specifically in each introduced species the reported introduction history and the genetic structure of the populations in both the native range and in the invaded area in order to obtain a useful population genetic framework that can be applied to management plans.
The Manila clam (Ruditapes philippinarum) (Adams and Reeve, 1850), which is one of the most appreciated shellfish species, is a good example of this type of situation. Manila clam culture represented 25% of global mollusk production in 2014. The natural distribution of the Manila clam extends over the western coasts of the Pacific Ocean ranging from the Philippines to Russia14. The majority of the world clam production comes from this area, with China as the first worldwide producer (98.9%). However, the species has been introduced in North America and Europe, which now produce 4701 t and 31651 t, respectively (all data from FAO, year 2014; http://www.fao.org/fishery/statistics/global-aquaculture-production/query).
In North America, the Manila clam was recorded for the first time in British Columbia (Canada) in 1936, and it is widely accepted that it came as an unnoticed hitchhiker with oysters imported from Japan15. In later years it expanded to the south, reaching its southern limit in California in 196416. In Europe, clams were introduced in France to cope with production problems with the native clam species in 1972–1974, and later they were further introduced in the UK for experimental trials, in both cases from a Canadian stock3,17. Subsequently, clams of French and British origin were transported to Italy, Spain and Norway17,18,19,20. The expansion of the species does not seem to have stopped, as shown by the recent establishment of self-recruiting populations in southern UK and the records from areas located far away from exploitation grounds such as Turkey21,22.
While the expansion of the Manila clam has been facilitated by its biological traits, such as high fecundity, a long larval phase (ca. 3 weeks), and broad salinity (15–50 PSU) and temperature tolerance (6–30 °C)23, the expansion of the species has been boosted by the development of hatcheries for artificial reproduction24,25. Spat produced in hatcheries have been used frequently to replenish exhausted wild beds or to grow-out in licensed suitable coastal sand plots wherever the species has been introduced.
In North America and Europe the Manila clam became naturalized immediately after its introduction and has shown a typical invasive character. The syndrome of ecological problems caused by invasive species is emerging in places where the Manila clam has established. This include an increase of clam numbers and the displacement of native species16,23,26,27,28,29, but also, in Europe, hybridization with the native clam R. decussatus and subsequent introgression30,31.
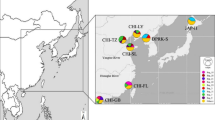
In contrast with the expansion experienced in North America and Europe, the situation of the Manila clam in its native range in Asia is characterized by stock reductions attributed to overexploitation and coastal pollution32. Solutions taken by Asian fishermen to face clam declines include imports of clams from other regions within Asia, with the consequent population admixture between stocks of China, Korea and Japan at localities where clam fisheries are important33,34,35,20,34,35,37,33,34,35,33,33,33,33,33,33, which had very low sample sizes (N = 5–7) (Supplementary Table S2 and Fig. 2a).

(a) Nucleotide diversity estimated from the whole set of COI sequences (grey bars), and from the clade A sequences only (white bars). Lack of a white bar in some populations indicates the absence of clade A, not zero diversity. The averages across populations are shown as a horizontal thick line (all clades) or a dashed one (clade A). (b) Heterozygosity at microsatellites. The horizontal black line shows the average across populations. (c) Allelic richness at microsatellites. In all figures, alternate white and gray backgrounds separate groups of populations belonging to different geographic regions (China, Japan, North America, Europe).
Neutrality tests
Neutrality tests (Supplementary Table S2) rendered significant (P < 0.05) values for Tajima’s D in only 1 population, indicating no significant departures from neutrality in the COI data set.
Population genetic differentiation
Significant (P < 0.05) pair wise FST ranged between 0.041 and 0.246, and in most cases were significant after a sequential Bonferroni test (Table 1). No significant differentiation was found between pairs of European populations and between the two American populations. Chinese and European populations were the most differentiated, as indicated by pairwise FST values ranging from 0.111 to 0.246. Population pairs involving China and America gave slightly higher FST values than those involving China and Japan, and the Japanese JAP population was more differentiated from European than from American populations. These results indicate a gradient of genetic differentiation from China to Europe, as expected from the reported clam introduction history. The European EUR-2 sample was not significantly differentiated from both American samples.
We obtained a total FST value of 0.109 (Table 2). Within each region the highest variation among populations was found in China (FST = 0.063, P < 0.001) and Japan (FST = 0.041, P < 0.01), followed by Europe (FST = 0.034, P < 0.05).
AMOVA48 and hierarchical F-statistics gave very similar results, and here we present F-statistics only, because they allow a direct comparison with microsatellites. Using a hierarchical model with four regions (Table 2), we obtained a total FST of 0.126, and interregional differentiation accounted for the majority of interpopulation variability (FCT = 0.081). A hierarchical model was also used to extract the among-population, within-regions component in genetic differentiation tests between pairs of regions. China and Europe were the most differentiated regions (FCT = 0.132; P < 0.001). No significant differentiation between Japan and America was found (FCT = 0.033, P > 0.05). America and Europe showed a high but non-significant interregional differentiation (FCT = 0.093).
Microsatellites
The 7 polymorphic microsatellites yielded a total of 114 allelic variants in the 9 scored populations (Supplementary Table S3). Null alleles were detected in all populations at loci K22 and A54, with frequencies ranging from 0.16 to 0.42, and at locus K8 in two populations (CHI-S and NAM-1) with estimated frequencies of 0.06 and 0.08 respectively (Supplementary Table S3). None of the Linkage disequilibrium tests performed on the 189 gene pair comparisons were significant after sequential Bonferroni correction. Significant departures from Hardy Weinberg equilibrium were found in 15 tests after Bonferroni correction, with FIS values ranging from −0.132 in EUR-4 to 0.183 in NAM-1 (Supplementary Table S4), but no clear pattern of variation across populations or loci was observed.
Genetic diversity
Microsatellite allele number (Na) and expected heterozygosity (He) showed average values of 9.5 ± 0.3 and 0.7 ± 0.01, with little variation among populations, except slightly lower diversities in China (Supplementary Table S4 online and Fig. 2b). Allelic richness (A) over loci ranged from 9.8 ± 4.1 in NAM-1 to 7.7 ± 3.2 in EUR-3, with the lowest values observed in European populations (Fig. 2C and Supplementary Table S4).
Private allelic richness (Ap) was lowest in European populations and CHI-S (Table 3). The lowest Ap was found at EUR-3. Estimates for each region showed that Ap was highest in America and lowest in Europe (Table 3).
Population genetic differentiation
The neighbor-joining tree based on microsatellite DA distances49 is shown in Fig. 3. Populations from China formed a separate cluster, with the highest distance and bootstrap support. European populations formed another cluster with high bootstrap support. American populations were basal to the European cluster. The Japanese population appeared equidistant between the Chinese and the American.

Bootstrap proportions obtained from 10,000 replications are shown above branches.
Significant FST values were obtained in 24 out of 36 pair-wise tests, of which 22 were significant after Bonferroni correction (Table 1). Non-significant values fell on pairs of American and European populations and on comparisons inside these regions. The total FST was 0.045 (P < 0.001) (Table 2). In agreement with pair-wise FST values, when FST was computed within each region it was non-significant in America and Europe, and it was low but significant in China.
The hierarchical analysis of variance based on a model of four regions (Table 2) showed that the variability among regions (FCT) accounted for 5.4% of the total variation among populations. FCT values obtained with hierarchical analysis of F-statistics for two-region models indicated that the most differentiated regions were both Europe and America with respect to China, and the less differentiated were America and Europe, as expected from the reported history of clam introductions.
Results of Bayesian model-based clustering (BMBC) of genotype data50 are shown in Fig. 4. The Evanno et al. method51 indicated a most probable K of two clusters (Supplementary Fig. S1a), but the results of the Pritchard method showed a posterior probability of data reaching a plateau in K values of 2, 3 and 4, suggesting a more complex hierarchical structure (Supplementary Fig. S1b). We present therefore the results of the analysis for K = 2–4 (Fig. 4). With K = 2, individuals were classified geographically in two groups. One group was formed by the individuals from Asian populations and characterized by a high frequency of cluster 1. The other group was formed by the individuals from the other regions and was characterized by a high frequency of cluster 2. With K = 4, regions showed a characteristic pattern of cluster frequencies (Fig. 4). For example, cluster 1 was more abundant in China and almost absent in the other regions. Cluster 3 was most abundant in Japan and America, and almost absent from China, and clusters 2 and 4 were most abundant in Europe.

Estimated membership fractions for each individual and population are shown for K = 2, K = 3 and K = 4 clusters. Membership fractions corresponding to each cluster in each population for K = 4 are given below the chart, with the most common cluster marked in bold. For K = 4, clusters 1, 2, 3 and 4 are shown in pink, green, purple and blue, respectively.
Assignment tests
Results of assignment tests are given in Table 4. In Asian and American populations most individuals (63% to 82%) were assigned to the populations where they were sampled or to a population in the same region (3% to 23%), although a small fraction (less than 10%) was assigned to populations in a neighbor region, and 7 individuals were assigned to populations in a non-neighbor region. A few individuals sampled in America were assigned to European populations. In Europe the majority of the individuals were assigned to populations where they were not sampled, although usually within the same region. However, a substantial proportion (30–44%) of individuals sampled in European populations were assigned to American populations, with the highest proportion observed in the EUR-2 population. Moreover, 2 European individuals were assigned to JAP and 2 to CHI-N. Assignment of individuals to regions showed a similar pattern (Table 4). Values o the DLR statistic52 higher than 3 were observed in 8 cases, all comprising comparisons between Chinese populations and American or European populations. This result indicates that the power to distinguish an individual from a given reference population in the assayed sample was sufficiently high (>50%) as to allow relatively robust inferences from these comparisons.
Non-random association of mitochondrial haplotypes and microsatellites
This test could be carried out only in the JAP population, where mitochondrial clades A and C were in sufficient frequencies. We tested the difference in the estimated membership fraction of the genotype cluster 3, obtained from the BMBC analysis, in clams carrying clade A COI haplotypes and in clams carrying COI haplotypes of other clades (Supplementary Table S5). A Student t test indicated that differences between the two groups were not statistically significant (P = 0.65).
Discussion
Population genetics of Manila clams in their native range has been described elsewhere, but a specific discussion of the results obtained from our Asian samples is necessary before using them as a reference in the study of American and European populations. Previous studies33,33. However, the Mik sample had clade A haplotypes only (Fig. 1c). This suggests that the population from which the JAP sample was taken might have been originated by a transplantation to Ise Bay of clams collected elsewhere, which had a high proportion of genes of Chinese ancestry. The presence of haplotypes C-4 and A-11 in JAP suggests that the collection place of the putative transplanted clams could be located in SE Japan, since those haplotypes are characteristic of this area (Supplementary Table S1).
Microsatellite data also support this view. We have found that most microsatellite alleles were present in the samples from both regions, and only a small proportion were exclusive of Japanese or Chinese samples, in agreement with previous studies32. However, the BMBC analysis of genetic structure with K = 4 showed that there is a clear differentiation at nuclear loci between China and Japan which affects microsatellite clusters 1 and 3. The high frequency of cluster 1 observed in the clams from JAP indicates that the Chinese ancestry is present in the nuclear genome of these clams, in agreement with the COI results. The absence of significant non-random association between nuclear alleles and mitochondrial haplotypes shows that the admixture between Chinese and Japanese genetic backgrounds in JAP occurred several generations ago, otherwise there would not have been time enough for the associations established when founding the population to disappear53.
The COI data support the Japanese ancestry of North American populations. All the individual clams from North America analysed in this study, with only two exceptions, carried clade A haplotypes, as expected if they originated from Japan. In the case of the two individuals that carried haplotypes of other clades, the haplotype was C-4 in both cases. This was the most abundant haplotype of clade C, and has been documented in some localities from Japan in previous33,61, and KTp8 and KTp2262. Microsatellite amplification was carried out in total volume of 20 μl, containing a mixture of 1 μl of template DNA, 10 μM primers (Applied Biosystems), 2.5 mM MgCl2, 1xBuffer (Invitrogen), 10 mM of each dNTP and 0.75 units of Taq polymerase. The forward primer was fluorescently labeled with one of NED, VIC, PET or FAM fluorochromes. Each PCR started with a denaturation step of 3 minutes at 94 °C, followed by 35 cycles of 30 seconds each, consisting of denaturation at 94 °C, annealing at 58 °C and extension at 72 °C. A final step of 72 °C was carried out during 2 minutes. The PCR products were electrophoresed on an automated sequencer (ABI 3730 or ABI3730XL) at the genomics facilities of the SCSIE (University of Valencia, Spain).
Mitochondrial DNA data analysis
The sequences obtained were edited with Bioedit63 and aligned using Clustal W64. The number of haplotypes (h), their frequencies, number of segregating sites (S), measures of haplotype diversity (Hd) and nucleotide diversity (π), and their standard deviations, were determined with the software package DnaSP v565,66.
The evolutionary relationships among COI sequences were represented with a phylogenetic network constructed with the program Network (fluxus-engineering.com), using a median-joining algorithm67 for multi-state sites. The parameter epsilon was set to 10 to explore all possible shortest trees, subsequently unnecessary median vectors and links were deleted with the MP option68.
Pair-wise FST, hierarchical F-statistics69 and AMOVA were used to study the genetic differentiation of populations with the software package Arlequin v.3.548. In hierarchical F-statistics, the total genetic differentiation among populations (FST) was partitioned in among-regions (FCT) and among-populations, within-regions (FSC) components. The significance of the statistics was tested with a non-parametric permutation approach run for 30000 permutations.
Microsatellite genoty** and data analysis
Genoty** was performed with the software GeneMapper v.4.1 (Applied Biosystems). Allele calling was achieved by adjusting the automated allele binning to a known internal size standard run alongside the PCR fragments. Low quality genoty** scores were revised manually. The program ALLELOGRAM70 was used for normalization of data from different runs. Internal controls were used in each run of samples for the automated binning. Genoty** errors like non-amplified alleles, allelic dropout, short allele dominance and stutter products were detected with the program Micro-checker71.
Allelic frequency estimation and Hardy Weinberg (HW) equilibrium tests were performed with the program Genepop'00772. The frequencies of null alleles were estimated, and the observed allele and genotype frequencies adjusted, with the program Micro-Checker71, using the Brookfield 2 estimator73. Exact P-Values were obtained by means of the Markov chain algorithm74, with 10000 dememorization steps, 20 batches and 500 iterations per batch. Estimates of FIS were obtained across loci and population69. Expected heterozygosity65 and allele number per locus and populations were calculated with the program Arlequin ver 3.548. Allelic richness per locus, population and overall populations, was obtained with the program Fstat v.2.9.375. A linkage disequilibrium test was done for each pair of loci in each population and across all populations by means of a G-test implemented in the program Genepop ‘00772. Significant levels were obtained with a Markov chain algorithm76 with 10000 dememorization steps, 100 batches and 5000 iterations per batch.
We studied the private allele richness (Ap) across populations by means of a rarefaction procedure implemented in the program ADZE77. We used the extended rarefaction method78, which allows correction for sample size differences, and computed the generalized private allele richness statistic77.
Genetic differentiation and population subdivision were studied with pairwise FST and hierarchical F-statistics, as described for mitochondrial marker. We also estimated DA distances79, which were used to construct a neighbor-joining tree80. When working with a small number of microsatellite loci, this distance measure has higher probabilities of obtaining a more reliable population trees than other distances81. Statistical support was attained with a Bootstrap test of 10000 replicates. All calculations were done with the program POPTREE282.
A different analysis of population genetic structure was carried out by means of a Bayesian model-based clustering (BMBC) method with the software STRUCTURE, version 2.3.450. By this method we obtained the estimates of the membership fractions of each individual to the inferred ancestors of the current populations. Individual genotypes of each population were analyzed under a model of admixture with correlated allele frequencies among populations, and no prior information on sample locations was assumed. With this model any of the inferred clusters is allowed to be the ancestor of an individual’s genome fraction, and genotypes of source clam populations are equally involved in the inference of the population structure of recent introductions. Data were analyzed with clustering models from K = 1 to K = 10, with 8 replicates of 100000 iterations and previous burning of 150000. Assignment of the most probable clustering of the inferred ancestral populations was analyzed with two methods51,83 implemented in the website Structure Harvester84. Results of the 8 replicates obtained with STRUCTURE were ordered and averaged with CLUMPP85 and graphically represented with DISTRUCT86.
Assignment tests were performed on individual multilocus genotypes in order to estimate the probabilities of individual clams to be resident to a reference population. Individual assignation likelihoods were computed with the program GENECLASS287 using the frequency criterion based on Paetkau et al. formula52. For the alleles that were absent in reference populations but present in the to-be-assigned sample, the allelic frequency in the reference population was set to 0.01. In order to obtain the probabilities of residence, assignation likelihoods were compared with the distribution of likelihoods obtained for the population under the resampling Monte Carlo method52. The DLR statistic, a measure of the power of successful assignment88, was also calculated. Values higher than 3 indicate 50% power to distinguish an individual from a given reference population in the assayed sample.
Additional Information
Accession codes: GenBank accessions of COI sequences are LT600424-LT600470.
How to cite this article: Cordero, D. et al. Population genetics of the Manila clam (Ruditapes philippinarum) introduced in North America and Europe. Sci. Rep. 7, 39745; doi: 10.1038/srep39745 (2017).
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
Mack, R. N. et al. Issues in Ecology. Bull. Ecol. Soc. Am. 86, 249–250 (2005).
Rilov, G. & Crooks, J. A. Biological Invasions in Marine Ecosystems. Ecological, Management and Geographic Perspectives. (Springer-Verlag Berlin Heidelberg, 2009).
Utting, S. D. & Spencer, B. E. Introductions of marine bivalve molluscs into the United Kingdom for commercial culture- case histories. ICES Mar. Sci. Symp. 194, 84–91 (1992).
Savini, D. et al. The top 27 animal alien species introduced into Europe for aquaculture and related activities. J. Appl. Ichthyol. 26, 1–7 (2010).
Mann, R. The role of introduced bivalve mollusc species in mariculture. In J. World Maricult. Soc. 14, 546–559 (1983).
Handley, L. J. L., Manica, A., Goudet, J. & Balloux, F. Going the distance: human population genetics in a clinal world. Trends Genet. 23, 432–439 (2007).
Dlugosch, K. M. & Parker, I. M. Founding events in species invasions: Genetic variation, adaptive evolution, and the role of multiple introductions. Mol. Ecol. 17, 431–449 (2008).
Ramachandran, S. et al. Support from the relationship of genetic and geographic distance in human populations for a serial founder effect originating in Africa. Proc. Natl. Acad. Sci. USA 102, 15942–15947 (2005).
Roman, J. & Darling, J. A. Paradox lost: genetic diversity and the success of aquatic invasions. Trends Ecol. Evol. 22, 454–464 (2007).
Geller, J. B., Darling, J. A. & Carlton, J. T. Genetic Perspectives on Marine Biological Invasions. Ann. Rev. Mar. Sci. 2, 367–393 (2010).
Uller, T. & Leimu, R. Founder events predict changes in genetic diversity during human-mediated range expansions. Glob. Chang. Biol. 17, 3478–3485 (2011).
Hoos, P. M., Whitman Miller, A., Ruiz, G. M., Vrijenhoek, R. C. & Geller, J. B. Genetic and historical evidence disagree on likely sources of the Atlantic amethyst gem clam Gemma gemma (Totten, 1834) in California. Divers. Distrib. 16, 582–592 (2010).
Fischer, M. L. et al. Historical invasion records can be misleading: Genetic evidence for multiple introductions of invasive raccoons (Procyon lotor) in Germany. PLoS One 10, 1–17 (2015).
Ponurovsky, S. K. & Yakovlev, Y. M. The reproductive biology of the Japanese littleneck, Tapes philippinarum. J. Shellfish Res. 11, 265–277 (1992).
Quayle, D. B. Distribution of introduced marine mollusca in British Columbia waters. J. Fish. Res. Board Canada 21, 1155–1181 (1964).
Cohen, A. N. & Carlton, J. T. Nonindigenous aquatic species in a United States estuary: a case study of the biological invasions of the San Francisco Bay and Delta. Report, US Fish and Wildlife Service (1995).
Flassch, J. & Leborgne, Y. Introduction in Europe, from 1972 to 1980, of the Japanese Manila clam. ICES mar. Sci. Symp 194, 92–96 (1992).
Breber, P. L’introduzione e l’allevamento in Italia dell’Arsella del Pacifico, Tapes semidecussatus Reeve (Bivalvia: Veneridae). Oebalia 9, 675–680 (1985).
Hopkins, C. Actual and potential effects of introduced marine organisms in Norwegian waters, including Svalbard. Directorate for Nature Management (Norway) (2001).
Chiesa, S. et al. A history of invasion: COI phylogeny of Manila clam Ruditapes philippinarum in Europe. Fish. Res. 186, 25–35 (2017).
Albayrak, S., Aslan, H. & Balkis, H. A contribution to the Aegean Sea fauna: Ruditapes philippinarum (Adams & Reeve, 1850) [Bivalvia: Veneridae]. Isr. J. Zool. 47, 299–300 (2001).
Jensen, A. C., Humphreys, J. & Grisley, C. Naturalization of the Manila clam (Tapes philippinarum), an alien species, and establishment of a clam fishery within Poole Harbour, Dorset. J. Mar. Biol. Ass. U. K. 84, 1069–1073 (2004).
Breber, P. In Invasive Aquatic species of Europe (eds. Leppäkoski, E., Gollasch, S. & Olenin, S. ) 120–126 (Kluwer, 2002).
Walne, P. R. Culture of Bivalve molluscs. (John wiley and Sons, 1970).
Jones, G. G., Sanford, C. L. & Jones, B. L. Manila Clams : Hatchery and Nursery Methods. Innovative Aquaculture Products Ltd. (Innovative Aquaculture Products Ltd., 1993).
Auby, I. Evolution of the Biologic Richness in the Arcachon Basin. Report. Ifremer/Société Scientifique d’Arcachon (1993).
Bendell, L. I. Evidence for declines in the native Leukoma staminea as a result of the intentional introduction of the non-native Venerupis philippinarum in coastal British Columbia, Canada. Estuaries and Coasts 1–12, doi: 10.1007/s12237-013-9677-1 (2013).
Juanes, J. A. et al. Differential distribution pattern of native Ruditapes decussatus and introduced Ruditapes phillippinarum clam populations in the Bay of Santander (Gulf of Biscay): Considerations for fisheries management. Ocean Coast. Manag. 69, 316–326 (2012).
Bidegain, G. & Juanes, J. A. Does expansion of the introduced Manila clam Ruditapes philippinarum cause competitive displacement of the European native clam Ruditapes decussatus? J. Exp. Mar. Bio. Ecol. 445, 44–52 (2013).
Hurtado, N. S., Pérez-García, C., Morán, P. & Pasantes, J. J. Genetic and cytological evidence of hybridization between native Ruditapes decussatus and introduced Ruditapes philippinarum (Mollusca, Bivalvia, Veneridae) in NW Spain. Aquaculture 311, 123–128 (2011).
Habtemariam, B. T., Arias, A., García-Vázquez, E. & Borrell, Y. J. Impacts of supplementation aquaculture on the genetic diversity of wild Ruditapes decussatus from northern Spain. Aquac. Environ. Interact. 6, 241–254 (2015).
Kitada, S. et al. Molecular and morphological evidence of hybridization between native Ruditapes philippinarum and the introduced Ruditapes form in Japan. Conserv. Genet. 14, 717–733 (2013).
Sekine, Y., Yamakawa, Y., Takazawa, S., Ying**, L. & Toba, M. Geographic variation in the COXI gene of the Short-neck clam Ruditapes philippinarum in coastal regions of Japan and china. Venus 65, 229–224 (2006).
Vargas, K. et al. Allozyme variation of littleneck clam Ruditapes philippinarum and genetic mixture analysis of foreign clams in Ariake Sea and Shiranui Sea off Kyushu Island, Japan. Fish. Sci. 74, 533–543 (2008).
Liu, X. et al. AFLP analysis revealed differences in genetic diversity of four natural populations of Manila clam (Ruditapes philippinarum) in China. Acta Oceanol. Sin. 26, 150–158 (2007).
Mao, Y., Gao, T., Yanagimoto, T. & **ao, Y. Molecular phylogeography of Ruditapes philippinarum in the Northwestern Pacific Ocean based on COI gene. J. Exp. Mar. Bio. Ecol. 407, 171–181 (2011).
An, H. S., Park, K. J., Cho, K. C., Han, H. S. & Myeong, J. I. Genetic structure of Korean populations of the clam Ruditapes philippinarum inferred from microsatellite marker analysis. Biochem. Syst. Ecol. 44, 186–195 (2012).
**ng, K., Gao, M. L. & Li, H. J. Genetic differentiation between natural and hatchery populations of Manila clam (Ruditapes philippinarum) based on microsatellite markers. Genet. Mol. Res. 13, 237–45 (2014).
Cigarrı́a, J. & Fernández, J. M. Management of Manila clam beds. Aquaculture 182, 173–182 (2000).
Bald, J. et al. A system dynamics model for the management of the Manila clam, Ruditapes philippinarum (Adams and Reeve, 1850) in the Bay of Arcachon (France). Ecol. Modell. 220, 2828–2837 (2009).
Choi, Y. et al. The study of stock assessment and management implications of the Manila clam, Ruditapes philippinarum in Taehwa river of Ulsan. 27, 107–114 (2011).
Chiesa, S. et al. The invasive Manila clam Ruditapes philippinarum (Adams and Reeve, 1850) in Northern Adriatic Sea: Population genetics assessed by an integrated molecular approach. Fish. Res. 110, 259–267 (2011).
Mura, L. et al. Genetic variability in the Sardinian population of the manila clam, Ruditapes philippinarum . Biochem. Syst. Ecol. 41, 74–82 (2012).
Steele, E. N. The inmigrant oyster. (Pacific Oyster Growers Association, 1964).
Hedgecock, D., Chow, V. & Waples, R. S. Effective population numbers of shellfish brood stocks estimated from temporal variances in allelic frequencies. Aquaculture 108, 215–232 (1992).
Borrell, Y. J. et al. Microsatellites and multiplex PCRs for assessing aquaculture practices of the grooved carpet shell Ruditapes decussatus in spain. Aquaculture 426–427, 49–59 (2014).
Ni, G., Li, Q., Kong, L. & Yu, H. Comparative phylogeography in marginal seas of the northwestern Pacific. Mol. Ecol. 23, 534–548 (2014).
Excoffier, L. & Lischer, H. E. L. Arlequin suite ver 3.5: A new series of programs to perform population genetics analyses under Linux and Windows. Mol. Ecol. Resour. 10, 564–567 (2010).
Tamura, K., Nei, M. & Kumar, S. Prospects for inferring very large phylogenies by using the neighbor-joining method. Proc. Natl. Acad. Sci. USA 101, 11030–5 (2004).
Pritchard, J. K., Stephens, M. & Donnelly, P. Inference of population structure using multilocus genotype data. Genetics 155, 945–959 (2000).
Evanno, G., Regnaut, S. & Goudet, J. Detecting the number of clusters of individuals using the software STRUCTURE: A simulation study. Mol. Ecol. 14, 2611–2620 (2005).
Paetkau, D., Slade, R., Burden, M. & Estoup, A. Genetic assignment methods for the direct, real-time estimation of migration rate: A simulation-based exploration of accuracy and power. Mol. Ecol. 13, 55–65 (2004).
Arnold, J. Cytonuclear Disequilibria in Hybrid Zones. Annu. Rev. Ecol. Syst. 24, 521–553 (1993).
White, J., Ruesink, J. L. & Trimble, A. C. The nearly forgotten oyster: Ostrea lurida Carpenter 1864 (Olympia oyster) history and management in Washington state. J. Shellfish Res. 28, 43–49 (2009).
Jarne, P. & Lagoda, P. J. L. Microsatellites, from molecules to populations and back. Trends in Ecology and Evolution 11, 424–429 (1996).
Nei, M., Maruyama, T. & Chakraborty, R. The Bottleneck Effect and Genetic Variability in Populations. Evolution (N. Y). 29, 1–10 (1975).
Maruyama, T. & Fuerst, P. A. Population bottlenecks and nonequilibrium models in population genetics. II. Number of alleles in a small population that was formed by a recent bottleneck. Genetics 111, 675–689 (1985).
Hedrick, P. W. Perspective : Highly Variable Loci and Their Interpretation in Evolution and Conservation. Evolution (N. Y). 53, 313–318 (1999).
Toews, D. P. L. & Brelsford, A. The biogeography of mitochondrial and nuclear discordance in animals. Mol. Ecol. 21, 3907–3930 (2012).
Folmer, O., Black, M., Hoeh, W., Lutz, R. & Vrijenhoek, R. DNA primers for amplification of mitochondrial cytochrome c oxidase subunit I from diverse metazoan invertebrates. Mol. Mar. Biol. Biotechnol. 3, 294–299 (1994).
Yasuda, N., Nagai, S., Yamaguchi, S., Lian, C. L. & Hamaguchi, M. Development of microsatellite markers for the Manila clam Ruditapes philippinarum . Mol. Ecol. Notes 7, 43–45 (2007).
An, H. S., Kim, E. M. & Park, J. Y. Isolation and characterization of microsatellite markers for the clam Ruditapes philippinarum and cross-species amplification with the clam Ruditapes variegate . Conserv. Genet. 10, 1821–1823 (2009).
Hall, T. BioEdit: a user-friendly biological sequence alignment editor and analysis program for Windows 95/98/NT. Nucleic Acids Symposium Series 41, 95–98 (1999).
Larkin, M. A. et al. Clustal W and Clustal X version 2.0. Bioinformatics 23, 2947–2948 (2007).
Nei, M. Molecular population genetics and evolution. (Columbia University Press, 1987).
Librado, P. & Rozas, J. DnaSP v5: A software for comprehensive analysis of DNA polymorphism data. Bioinformatics 25, 1451–1452 (2009).
Bandelt, H. J., Forster, P. & Röhl, A. Median-joining networks for inferring intraspecific phylogenies. Mol. Biol. Evol. 16, 37–48 (1999).
Polzin, T. & Vahdati Daneshmand, S. On Steiner trees and minimum spanning trees in hypergraphs. Oper. Res. Lett. 31, 12–20 (2003).
Weir, B. & Cockerham, C. C. Estimating F-Statistics for the Analysis of Population Structure Author (s): B. S. Weir and C. Clark Cockerham. Evolution (N. Y). 38, 1358–1370 (1984).
Morin, P. A., Manaster, C., Mesnick, S. L. & Holland, R. Normalization and binning of historical and multi-source microsatellite data: Overcoming the problems of allele size shift with allelogram. Mol. Ecol. Resour. 9, 1451–1455 (2009).
Van Oosterhout, C., Hutchinson, W. F., Wills, D. P. M. & Shipley, P. MICRO-CHECKER: Software for identifying and correcting genoty** errors in microsatellite data. Mol. Ecol. Notes 4, 535–538 (2004).
Rousset, F. GENEPOP’007: A complete re-implementation of the GENEPOP software for Windows and Linux. Mol. Ecol. Resour. 8, 103–106 (2008).
Brookfield, J. F. A simple new method for estimating null allele frequency from heterozygote deficiency. Mol. Ecol. 5, 453–455 (1996).
Guo, S. W. & Thompson, E. A. Performing the exact test of Hardy-Weinberg proportion for multiple alleles. Biometrics 48, 361–372 (1992).
Goudet, J. FSTAT: a computer program to calculate F-Statistics. J. Hered. 104, 586–590 (2013).
Raymond, M. & Rousset, F. An exact test for population differentiation. Evolution (N. Y). 49, 1280–1283 (1995).
Szpiech, Z. A., Jakobsson, M. & Rosenberg, N. A. ADZE: A rarefaction approach for counting alleles private to combinations of populations. Bioinformatics 24, 2498–2504 (2008).
Kalinowski, S. T. Counting alleles with rarefaction: Private alleles and hierarchical sampling designs. Conserv. Genet. 5, 539–543 (2004).
Nei, M., Tajima, F. & Tateno, Y. Accuracy of estimated phylogenetic trees from molecular data. II. Gene frequency data. J. Mol. Evol. 19, 153–170 (1983).
N, S. & Nei, M. The Neighbor-joining Method: A New Method for Reconstructing Phylogenetic Trees’. Mol. Biol. Evol. 4, 406–425 (1987).
Takezaki, N. & Nei, M. Empirical tests of the reliability of phylogenetic trees constructed with microsatellite DNA. Genetics 178, 385–392 (2008).
Takezaki, N., Nei, M. & Tamura, K. POPTREE2: Software for constructing population trees from allele frequency data and computing other population statistics with windows interface. Mol. Biol. Evol. 27, 747–752 (2010).
Pritchard, J. K., Stephens, M. & Donnelly, P. Inference of population structure using multilocus genotype data. Genetics 155, 945–959 (2000).
Earl, D. A. & vonHoldt, B. M. STRUCTURE HARVESTER: A website and program for visualizing STRUCTURE output and implementing the Evanno method. Conserv. Genet. Resour. 4, 359–361 (2012).
Jakobsson, M. & Rosenberg, N. A. CLUMPP: A cluster matching and permutation program for dealing with label switching and multimodality in analysis of population structure. Bioinformatics 23, 1801–1806 (2007).
Rosenberg, N. A. DISTRUCT: A program for the graphical display of population structure. Mol. Ecol. Notes 4, 137–138 (2004).
Piry, S. et al. GENECLASS2: A software for genetic assignment and first-generation migrant detection. J. Hered. 95, 536–539 (2004).
Paetkau, D., Calvert, W., Stirling, I. & Strobeck, C. Microsatellite analysis of population structure in Canadian polar bears. Mol. Ecol. 4, 347–354 (1995).
Acknowledgements
This study was financed by grants AGL2007-60049/ACU and AGL2013-49144-C3-3-R from the Secretaría de Estado de Investigación (Spanish Government) to C. S. We thank J. Molares (CIMA), J. M. Parada (CIMA) and J. J. Pasantes (University of Vigo) for providing clam samples, and Juan B. Peña for his help in the initial stages of this work.
Author information
Authors and Affiliations
Contributions
C.S. and D.C. designed the work, conducted the data analysis, and wrote the paper. D.C. carried out the laboratory work. M.D., B.L. and J.R. provided samples and important information on local populations, and also contributed substantially to improving the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Supplementary information
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Cordero, D., Delgado, M., Liu, B. et al. Population genetics of the Manila clam (Ruditapes philippinarum) introduced in North America and Europe. Sci Rep 7, 39745 (2017). https://doi.org/10.1038/srep39745
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep39745
- Springer Nature Limited