
Abstract
Worldwide, catastrophic landslides are occurring as a result of abnormal climatic conditions. Since a landslide is caused by a combination of the triggers of rainfall and the vulnerability of spatial information, a study that can suggest a method to analyze the complex relationship between the two factors is required. In this study, the relationship between complex factors (rainfall period, accumulated rainfall, and spatial information characteristics) was designed as a system dynamics model as variables to check the possibility of occurrence of vulnerable areas according to the rainfall characteristics that change in real-time. In contrast to the current way of predicting the collapse time by analysing rainfall data, the developed model can set the precipitation period during rainfall. By setting the induced rainfall period, the researcher can then assess the susceptibility of the landslide-vulnerable area. Further, because the geospatial information features and rainfall data for the 672 h before the landslide's occurrence were combined, the results of the susceptibility analysis could be determined for each topographical characteristic according to the rainfall period and cumulative rainfall change. Third, by adjusting the General cumulative rainfall period (DG) and Inter-event time definition (IETD), the preceding rainfall period can be adjusted, and desired results can be obtained. An analysis method that can solve complex relationships can contribute to the prediction of landslide warning times and expected occurrence locations.
Similar content being viewed by others


Introduction
Increased rainfall brought on by climate change triggers landslides at vulnerable locations, thus causing public damage. Therefore, a prominent global academic effort is underway with regard to disaster preparedness. The majority of research on landslide-occurrence prediction and susceptibility is divided into two categories: rainfall analysis and spatial information-based research. Rainfall analysis studies identify the rainfall thresholds based on regression analysis of rainfall intensity and period data. Spatial information-based research is based on utilizing the frequency ratio of susceptible factors, regression, and machine learning analysis.
The sensitivity function has been studied using critical rainfall1, and a relationship between the rainfall intensity and total cumulative rainfall has been suggested2,3 to predict landslide occurrence probability. Rainfall analysis can be used for alerting, monitoring, emergency-response planning, and other purposes4,5. Therefore, based on the literature review and researchers’ understanding, the rainfall thresholds were determined and examined while considering different rainfall conditions1,2,3,4,6,7.
Geographic information system (GIS) is mainly used for landslide analysis to support decision-making owing to its visual advantages. GIS-based landslide-related studies from 1999 to 2018 are the most widely used in contemporary research and applications6. Landslide susceptibility has been analysed using GIS to predict landslide occurrence based on spatial information such as geomorphology, geology, hydrology characteristics, and rainfall7,8,9,10,11,12,13. The relationship of geospatial information factors which affect the landslide has been evaluated using regression analysis and GIS technology7,11,14,15,16,17. These analyses primarily use a frequency-ratio method based on pixel units, which was achieved using artificial intelligence-based methods8,18,19,20 and MATLAB21. Research on the integration of machine learning and GIS technology is underway to increase forecast accuracy.
Convolutional neural network, deep neural network, long short-term memory, and recurrent neural network were used to forecast landslides using deep learning algorithms by analysing the frequency ratios of pixels22. Furthermore, predictions with 90% accuracy were produced by integrating K-nearest neighbour, multi-layer perceptron, random forest, and support vector machine23. Various analysis techniques are being tested using different conditions for points, circles, and polygons24. However, accuracy may differ based on the choice of non-landslide site. The key argument is that each location requires a different appropriate model and that using a single model across all regions is not feasible.
Rainfall was considered in conjunction with spatial information in previous studies25 because it is difficult to anticipate the time and location of occurrence solely using spatial information-based analysis. Landslide susceptibility caused by rainfall differs depending on weathered soil type26 and geomorphological characteristics27 of shallow landslides in Italy28. The dynamic susceptibility map for extreme rainfall changed by performing a logistic regression analysis based on rainfall and GIS in the Deokjeok-ri and Chuncheon regions in the Republic of Korea7. The National Disaster Management Research Institute in the Republic of Korea conducted a risk map study of rainfall by applying a three-dimensional limit equilibrium analysis model of cancer species and a soil depth prediction model to determine spatial characteristic information29,30,31. It is difficult for the aforementioned studies, which combine geographical and meteorological data, to adapt to real-time changes utilizing fixed variables. In this study, we performed probability-based modelling to understand the relationship between rainfall duration, amount of cumulative rainfall, and spatial information according to changes in rainfall conditions. The proposed method considers region-based rainfall characteristics to reflect dynamic rainfall factors. A linkage model between rainfall and spatial information and a probability model considering changes in the rainfall conditions of the geospatial information (GSI) were developed. As a consequence, it was feasible to detect the spatial information's detailed geospatial information (DGSI) susceptibility by modelling. Therefore, this study can contribute to reducing the damage resulting from landslides by establishing alarm standards of hourly and duration rainfall amount that consider regional characteristics.
Research procedure
Figure 1 shows the research methodology flowchart of this study. We collected landslide cases have occurrence time for dynamic landslide susceptibility analysis and constructed the spatial information, analysed the cases, and collected the rainfall data. First, a rainfall model was developed considering the period between the general rainfall model and the rainfall event. Thereafter, a spatial information convergence model was developed. This study was conducted according to a step-by-step procedure that combined rainfall and spatial information.

Research methodology flow chart of this study.
Materials and methods
Data
Landslide event data of South Korea
With an increase in torrential and frequent rains due to abnormal weather, the mountainous regions, which constitute approximately 70% of the Republic of Korea, have been adversely affected due to heavy rainfall accompanied by annual typhoons, notably Rusa in 2002 and Mitag in 2019. The precipitation level in 2020 exceeded twice the annual average from late July to mid-August because of heavy rainfall. In Korea, numerous landslides occur due to unusual weather, which includes frequent typhoons, heavy downpours, and long-term rainfalls. Therefore, there’s a scope of landslide cases from 2007 to 2020 in Korea. There is a high frequency of landslide occurrences in the Republic of Korea, and damage has occurred owing to debris flow and shallow slides. In contrast to naturally occurring ground movement, rainfall is the primary cause of landslides in the Republic of Korea.
We focused on collecting the locations (coordinates), dates, and occurrence times as accurately as possible. Referring to Drone images, Google Earth images, and Naver Road Map view, 241 landslide points were verified. Out of initially-collected 241 data points, 174 data points were finalised after excluding the data points where the date and time of occurrence were unknown, and coordinates or rainfall data were missing.
The data which was used to create Fig. 2 was sourced from on-site surveys performed using drones in the 2019–2020 landslide areas, National Disaster Management Research Institute reports, Ministry of the Interior and Safety reports, and media surveys. A total of 107 landslide data points were obtained through field surveys during 2019 and 2020. Figure 2 shows some of the drone survey sites to confirm the exact triggering point.

Dronographs of a few significant landslides that occurred at (A) Sun-chang, (B) Asan, (C) Gok-seong, and (D) Jang-Su in 2020(created using DJI INSPIRE 2 Drone, PIX4Dmapper and DroneDeploy software, https://www.pix4d.com, www.dronedeploy.com).
Geospatial data
DGSI data were extracted from the GSI built in point data where the collapse occurred. The data utilised spatial information from slopes, aspect, curvature, soil, forests, trees, and drainage ratings used32,33,34,35. In addition, the parent rock and bedrock lithology was used in landslide analysis15,36. Altitude is considered a major factor in landslide analysis but was excluded in this study because we also considered landslide history data in mountainous areas with low altitudes around roads and residential areas. Forest location soil maps and stock maps are vector files that contain a considerable amount of field information. Each GSI was first converted into a raster file and later extracted at the point of landslide occurrence using the GIS analysis tool. The procedure for constructing the data on landslide occurrence is shown in Fig. 3. The data source was a digital elevation model with a 5 M spatial resolution developed based on a 1:5000 map provided by the National Geographic Agency and a forest stock map provided by the Korea Forest Service, which uses a 1:5000 map to utilise clinical types, clinical density, and clinical economy data. The 1:25,000 forest stock map was created through contour modification using a digital aerial photograph and five pieces of information, as shown in Fig. 3. All GSI related to landslide event is constructed to extract the characteristics of event points, as shown in Fig. 4.

GSI collection procedure of landslide site data.

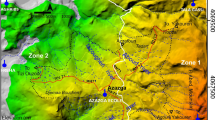
(left) Rain gauge and landslide 174 sites during 2007–2020 in South Korea, (right) rainfall data collection procedure (created using ArcGIS Pro, 2.9.2, https://www.esri.com).
Rainfall data
Reliable rainfall data are required to confirm the GSI of the collapse point, precipitation, and possibility of collapse and to prepare a risk map. Rainfall data were extracted from the automatic weather system and automated synoptic weather system in Korea. The yellow colour on the left in Fig. 4 indicates the weather system used to extract data. Recently, radar data have been collected to facilitate precise rainfall prediction37,38,39,40,41, but the information on landslide occurrence points built in this study used information from 174 points since 2007. Therefore, we had no choice but to rely on past data recorders.
Selecting duration
In general, the most frequently used period for rainfall data analysis in landslide disasters is 24 and 48 h. However, 5 and 20 day-periods were used based on the researcher’s judgment9,43. Following previous research43, 14 days were used to extend the analysis period of the model as much as possible. Therefore, researchers need to make an effort to provide the results from a variety of perspectives by diversifying the rainfall analysis period. This study used 28 days (672 h) of rainfall to confirm that landslides can occur even when the site is exposed to weak rainfall for a long duration.
Selecting the station
Ground observation stations for rainfall data collection are operated by the Meteorological Administration. Rainfall data were collected based on the procedure shown on the right side of Fig. 4. This procedure is as follows: First, a ground observation station nearest to the landslide occurrence location was selected for the study. Second, the presence or absence of rainfall data on the date of collapse was checked. Some data points were excluded because there were cases where the data at the time of collapse was not available. Third, we except for the missing hourly rainfall data rate for 14 days (336 h) before the collapse was larger than 5%. Errors may have occurred if missing data were considered in the study because the effective cumulative rainfall cannot be accurately measured as the time between rainfall events is affected. Observation stations were selected, and rainfall data for the site were collected by determining if there was at least 550 h of data from the time of the collapse (Fig. 4). The rain gauge station was geo-coded. The locations and selected points are shown on the left-hand side of Fig. 4. A total of 114 rain gauge stations were selected as the observation stations closest to the 174 collapse case points in this study using a near tool loaded in ArcGIS Pro. However, 26 rain gauge stations were not available due to missing data, discontinued operations, and loss of historical data. Finally, 88 rain gauge stations based on the rainfall-measurement-station selection process on the right-hand side of Fig. 4 were used.
Methods
Random variable
Despite its inherent complexity, disaster prediction has been studied using probability distributions based on past experiences. In probability theory, a random variable is a measurable function from one probability space to another, and its value is determined by the outcome of the trial. Specifically, a random variable can have predictive value for events that have not occurred and is a function that provides the potential results of variables that cannot be accurately determined. If it applies to a countable set, it is called a discrete random variable. If it applies to an uncountable set, it is called a continuous random variable. The domain (Ω) of a random variable is its probability space, and the codomain (Ε, ε) of a random variable is its state space. The random variable X:Ω → Ε is derived in state space E. This represents the probability that X has a value S, and the equations are as follows:
Probability mass function
The probability mass function (PMF) represents the probability that a random variable has a specific discrete value, whereas the probability density function represents the probability of a random variable assuming continuous values. When variable X:S → R is a discrete random variable determined by sample space S, the PMF is expressed as Eqs. (3) and (4), given below. Here, xn is the number of cases in the sample space. If the random variable is X, the PMF corresponding to the random variable is expressed by Eqs. (3) and (4):
Cummulative distribution function
The cumulative distribution function (CDF) represents the probability that a given random variable is less than or equal to a specific value. The probability is obtained according to the given value of the function and random variable X, and the accumulated graph is called the CDF. The CDF is defined by Eq. (5). The CDF of the discrete random variable X with a probability distribution f(x) is denoted by FX(x).
This represents the cumulative probability of x, which denotes any one of the accidents. In the CDF operation, the condition in Eq. (6) holds for any value x of random variable X, and if the two random variables are such that a < b, Eq. (7) must be used instead.
The CDF has a lower limit value of zero and an upper limit value of 1. Specifically, the CDF represents an accumulation of probabilities, as shown in Eq. (8).
As shown in Eq. (9), CDF, being a right-up function, accumulates probability as the x value increases and always either has a positive or zero value.
The discrete random variable can be identified using the PMF in Eq. (10) using the CDF value, where ε denotes the value of the difference.
Joint probability distribution
A bivariate distribution refers to the joint probability distribution (JPD) of random variables. It is mainly used for weight analysis. It is expressed by Eqs. (11) and (12), and the sum of the coupling probabilities for two discrete random variables X and Y can be expressed as shown in Eq. (12).
When using the JPD, each occurrence frequency can be considered for each DGSI, which is the X value, and Y attempts to reflect the changed value of rainfall over time.
System dynamics model
System dynamics is a theory dealing with interactions between entities in dynamic systems and presenting concepts for system dynamics construction44,45. Powersim is an analytical design tool for reproducing system dynamics, and it can perform a simulation function that automatically converts rapidly changing input data to provide the desired output. System dynamics can set a range (time dependent like rainfall duration) to derive results by setting not only the relationship between single variables but also between several variables. The mathematical expression of the state in which the system state change occurs is Eq. (13), and the time variable is expressed as given in Eq. (14) so that the process of changing the time and variables can be calculated in a continuous and procedural order.
Model design principle
The model operation steps are depicted in succession in Fig. 5. As shown in Fig. 5a, the users select an option from the general rainfall duration (DG) and the effective rainfall duration (DE), which is calculated using the IETD time. Then, the users can select the rainfall period they want to investigate (Fig. 5b). If the user does not take into account the dry period, users may choose DG to input the times from the beginning of the rain to the present. Alternatively, the user can choose the preferred IETD time if it is assumed that effective rainfall influences the probability of landslides. Then the accumulated rainfall is calculated for each case during the selected period (Fig. 5c). The accumulated rainfall results of 174 cases are matched by DGSI grade in Fig. 5d to the accumulated rainfall that resulted in the landslide. For all DGSI factors, the cumulative distribution function converges to 1. Because the low-frequency area might have higher susceptibility at the same cumulative rainfall, the random variable outcomes of the high-frequency and low-frequency DGSI could not be reflected properly. As a consequence, the final random variable in Fig. 5f was derived by applying the frequency of occurrence results analysed by DGSI.

Model operation sequence and principle: (a) environmental setup, (b) time setting, (c) calculate cumulative rainfall, (d) calculate method of susceptibility, (e) result of susceptibility, and (f) the result applied occurrence frequency by DGSI.
Design model
Construction of dataset
The comprehensive data for the dynamic susceptibility analysis of landslides comprised the case number (ID), GSI, and hourly rainfall data, as shown in Fig. 6. There exists a total of 174 points in which each point has its own GSI and 672 h of rainfall data. The GSI consisted of aspect, curvature, slope, TWI (topographic wetness index), tree diameter, parent rock, forest density, soil depth, forest type, soil type, drainage class, and accumulated form. Rainfall data was composed of data collected over 28 days before the time of occurrence (D-day, 672 h).

Comprehensive data for dynamic susceptibility analysis. [Aspect (AS), curvature (CU), slope (SP), TWI, tree diameter (TD), parent rock (PR), forest density (FD), soil depth (SD), forest type (FT), soil type (ST), drainage class (DC), and accumulated form (AF)].
Rainfall model
There exist two configurations of data for analysing the possibility of occurrence of detailed GSI through system dynamics modelling. One is the graded GSI at the accident site, and the other is the previous hourly rainfall data recorded for 672 h from the time of the collapse.
First, only the rainfall data were processed. Output data according to the rainfall scenario (period setting) were determined by the cumulative rainfall time setting simulator ( ) combined with the constant variable (◇), which indicates a 672-h rainfall and is determined through the functional expression of the auxiliary variable (○). The rainfall model sets the cumulative rainfall time DG in two ways to derive the general cumulative rainfall (RG). Next, the effective cumulative rainfall (RE) result is derived by setting the time between rainfall events (IETD). Figure 7 shows a flow diagram of a powersim that can calculate rainfall amounts to link GSI before susceptibility analysis. Figure 8 shows a schematic of the difference between Fig. 8b in the case of RG and Fig. 8c in the case of RE values. It can be observed that cumulative rainfall is derived by recognising the data shaded in blue, and significantly different values can be obtained according to the arrangement of the rainfall data. Figure 8a shows the collected rainfall data, (b) shows the result of setting 24 h as a period, and (c) shows the results of the IETD model.
) combined with the constant variable (◇), which indicates a 672-h rainfall and is determined through the functional expression of the auxiliary variable (○). The rainfall model sets the cumulative rainfall time DG in two ways to derive the general cumulative rainfall (RG). Next, the effective cumulative rainfall (RE) result is derived by setting the time between rainfall events (IETD). Figure 7 shows a flow diagram of a powersim that can calculate rainfall amounts to link GSI before susceptibility analysis. Figure 8 shows a schematic of the difference between Fig. 8b in the case of RG and Fig. 8c in the case of RE values. It can be observed that cumulative rainfall is derived by recognising the data shaded in blue, and significantly different values can be obtained according to the arrangement of the rainfall data. Figure 8a shows the collected rainfall data, (b) shows the result of setting 24 h as a period, and (c) shows the results of the IETD model.

Flow diagram of DG and DE in the rainfall model.

Schematic diagram used for deciding RG and RE values: (a) collected rainfall data (b) the calculating method in RG, (c) the calculating method in RE.
DG analysis model design
The RG extraction model undergoes an eight-step state change process. The roles of (1) to (8), as shown in Fig. 9, are as follows. In (1), the amount of rainfall per case is recognised from the rainfall master data. In (2), the data are sorted. (3) acts as a simulator to select the DG. In (4), the selected DG is recognised. In (5), we recognise the set period. In (6), the general cumulative rainfall for each case is calculated. In (7), a range to be output is determined, and in (8), a conditional classification is performed to determine the analysis environment. Figure 9 shows the flow for the operation of the general cumulative rainfall model, and the functions used in each step are included in Eq. (A.1). Parts of calculated rainfall results are included in Eq. (A.4).

Flow diagram for determining RG by setted DG.
DE analysis model design
DE is the rainfall duration, which is included in calculating the cumulative rainfall determined by the IETD. DE modelling was designed to derive the effective cumulative rainfall (RE), excluding the rainfall-free period, by setting the time between rainfall events. Figure 10 shows the model design for deriving the effective cumulative rainfall and is used as input data for RE, depending on the case. To summarise the order of the effective cumulative rainfall analysis model, the non-rainfall period (TN) and rainfall period for each point were calculated. Then the integrated value was derived for 174 cases after the last period in which the cumulative rainfall time exceeded IETD. RE,i is the effective cumulative rainfall in case i, and Rt is the hourly rainfall. t = last is the last time when TN minus IETD is greater than zero, and t = event denotes the time until the accident occurs.
The DE's decision requires a procedure to count non-rainfall periods and valid rainfall periods for each case. Figure 10 shows a rainfall model that determines the RE according to the IETD time determination, and the calculation is performed according to the RE determination method provided in the bottom table in Fig. 8, which uses the function given in Eq. (A.2). Parts of calculated rainfall results are included in Eq. (A.5). RG was applied differently to each case in which DE and accumulated rainfall were influenced by the IETD setting for each case built in this study.

Flow diagram for determining RE by setted DE (IETD).
GSI-rainfall linkage model design
The logic behind the rainfall-geospatial information model is shown in Fig. 11. Figure 11a was used as an RG or RE data input variable, which is the rainfall simulation result. Figure 11b is a constant variable that plays a role in reading the first established GSI from MS Excel. Figure 11c recognises the detailed GSI for each case and plays a role in arranging the cumulative rainfall in the corresponding case. Figure 11d sorts and checks some data, and Fig. 11e checks the cumulative amount of DGSI as the cumulative rainfall increases for each case. Figure 11f provides the results of calculating the probability according to each rainfall event by DGSI grade. Figure 11g represents the step for calculating the cumulative probability, and the result thus obtained is provided for each DGSI using the results of Number 6 derived for each rainfall event. The design of the dynamic system for checking the dynamic susceptibility of each detailed GSI consists of processes, such as conditions, classification, arrangement, application, variable definition, cumulative sum, and result output. The roles and functions for each number described above are included in Eq. (A.3). The parameters within each system were extracted as array data with detailed values for the amount of GSI in each processing stage for 174 cases and 672 h. Finally, all results of the model were converted into Excel data. This approach has the advantage of being able to geocode and use GIS field data; therefore, it can effectively express visual outputs. In addition, data conversion is convenient; therefore, it is possible to continuously update the results by including landslide disaster cases.

Flow diagram for fusion of GSI and rainfall results (a) input data (accumulated rainfall from DG, DE model), (b) input data (geospatial information of 174 location), (c) ~ (g) function to draw susceptibility refer to A.3.
Results
Frequency ratio (FR) analysis for weight of DGSI
In this study, grading refers to the conversion of categorical data into a format that can be used for statistical analyses. In this paper, tree diameter, parent rock, forest density, forest type, soil types, drainage class, and accumulated form at the time of constructing spatial information were classified and utilized according to definitions because they are categorical spatial information data46. However, in the case of continuous variables, classes were classified based on the principle of equal distribution, referring to previous studies. Aspects are generally classified into nine classes12,29, curvature is sometimes classified into five classes46, and concave, straight, convex are sometimes used for analysis by classifying them into three classes13,47,48. The slope was classified into five classes49. In the case of TWI, three13,49, five29,47,48, and six50 types were used under the analysis and judgment of the researcher. In the case of soil depth, five categories were used47,48. Table 1 shows the frequency (F) of each DGSI where the landslide occurred. The analysed frequency was linked to each rainfall according to changes in general cumulative rainfall and effective cumulative rainfall and was used as a weight when analysing the results of the susceptibility of each DGSI due to rainfall-spatial information combination modelling.
Analysing the frequency analysis results, no difference between the negative and positive values in the case of curvature was observed, and an FR of 54.5% was observed at 16°–30° in the slope. There is a high frequency of occurrence at slopes below 30° because, in the Republic of Korea, the damage occurred owing to debris flow and shallow slide. The topographic wetness index was the most common, with an FR of 50% in the case of the 3rd grade. In terms of the tree diameter, FR was the highest for medium-sized wood. In terms of the parent rock, FR was the highest in the case of igneous rock, and FR was the highest at 86.2% in areas with high forest density. The FR was 66.7% for soil depth in the 4th grade, and it was the highest when the forest type was evenly distributed, except for bamboo groves. The bamboo grove, which was the 5th grade of the forest type, was not deep-rooted from the surface, and the soil layer was weathered. This caused landslides in the bamboo grove area of Jangseong-gun in 2020. It was expected to possess a high FR, but it demonstrated a low FR because only 0.3% of the country’s land area constitutes bamboo grove. In the case of soil type, FR was the highest at 61.5% in sandy loam soil. In the case of the drain class, it was the highest at a rate of 58% for the 2nd grade. The accumulated form exhibited the highest FR (52.9%) during creep.
Analysis of RG-GSI model
Figure 12 shows the susceptibility according to the increase in rainfall when DG is set to 12 h, as a result of analysing the possibility of occurrence based on RG and DGSI. The susceptibility when DG is set to 36 h is shown in Fig. 13. The two graphs represent 12 DGSI. The vertical and horizontal axes represent susceptibility and cumulative rainfall during the set rainfall period, respectively. One scale on the horizontal axis(X-axis) is divided into 20 mm, and the maximum cumulative rainfall in 672 h is 1300 mm; therefore, it has a scale of up to 65. Consequently, susceptibility is obtained as a discrete result based on changes in rainfall. The reason for the steeper slope at 36 h compared with that at 12 h stems from imperial analysis, which considers that landslides occur due to rainfall over a fixed period. None of the curves approach a probability of one because the weight mentioned in 1 is applied. The results of the dynamic modelling of DGSI considering DG as 12 h, 24 h, 36 h, 48 h, and 672 h, which are periods that are mainly used as antecedent fall periods, are included the Eq. (A.6).

Susceptibility according to cumulative rainfall considering DG = 12 h.

Susceptibility according to cumulative rainfall considering DG = 36 h.

Susceptibility according to cumulative rainfall considering IETD = 12 h.

Susceptibility according to cumulative rainfall considering IETD = 36 h.
Analysis of RE-GSI model
Based on the change in the IETD, we attempted to confirm the susceptibility of landslides to DGSI. The analysis was performed using the same fusion method as in the case of the RG-GSI model, and the RE results that were derived from the DE model were used as input data. The results of the susceptibility analysis of RE and DGSI are shown in Figs. 14 and 15, which represent cases where the IETD was set to 12 h and 36 h, respectively. Unlike the DG-GSI model, when the cumulative rainfall approached 560 mm, the susceptibility conversion was 1. The 12-h IETD usually considers an antecedent period of 12 h or more because the subsequent rainfall event is considered when the TN is more than 12 h. Therefore, it can be observed that the susceptibility is lower for the same rainfall than in the case where DG = 12 h. Although it is very difficult to observe regularity owing to the limited number of cases, which is 174 in this study, the analysis results are considered meaningful as a means of finding random variability in the relationship between rainfall characteristics and GSI. In addition, the results of the dynamic modelling for each detailed geomorphological factor considering the DE of 12 h, 24 h, 36 h, 48 h, and 672 h are included in Eq. (A.7).
Discussion
In order to predict landslides, previous research has gathered rainfall data that triggered landslides. This data has also been utilized to construct the rainfall threshold regression5,28,43,51,52 formula and waring criteria28,43,53,54 through analyses of rainfall period-rainfall intensity and rainfall period-accumulated rainfall. Previous studies about rainfall thresholds did not allow for dynamic adjustment of the effective rainfall duration and amount since they had been predetermined. The research was performed on combining rainfall data with geospatial information7,25,26,29,55, and a system that sent alerts over time56,57 was also established. It is challenging to find previous research on a model that simultaneously recognizes and analyses the variables of rainfall period and cumulative rainfall. Therefore, this study developed and applied a methodology that can consider spatial information and rainfall characteristics with complex causal relationships using system dynamics modeling58.
We started to estimate the possibility of landslides according to the change in rainfall period and accumulated rainfall for each detailed geospatial information characteristic. The model hypothesizes that landslides are triggered by rainfall events that occurred inside the previous period (defined period by the model) of the occurrence of landslides. The environment with the same rainfall, rainfall time, and geographical information is most likely to face landslides. Therefore, rather than confirming the possibility of landslides by determining the existing DG and IETD in advance through this study, it was determined that the landslide warning system could be developed if the susceptibility could be determined by immediately reflecting the rainfall characteristics that change in real-time. In addition, it was expected to predict the possibility of a landslide at a specific point because spatial information characteristics are reflected.
It is difficult to accurately predict natural landslides. Susceptibility analysis begins with the assumption that they occur under conditions similar to those of past landslides. In addition, it is challenging to derive true values through direct comparison with previous studies because of differences in study target sites, sensitivity derivation methods, analysis factors (GSI and DGSI), and statistical classification techniques13. Because natural disasters, such as landslides, floods, and earthquakes, often face difficulty to predict. During the study process, the proposed model offers trustworthy results but also introduces uncertainty59. Researchers carried out kee** in mind the uncertainty in landslide prediction60,61. Also, despite yielding considerable degrees of accuracy in landslide predictions, the outcomes of different landslide susceptibility models are prone to spatial disagreement; and therefore, uncertainties23.
Rather than focusing on deriving accurate results, this study started with the intention of predicting the areas that are more likely to have landslides according to the changing rainfall conditions through new trials.
The model can select a certain collapsed location from among those in the rainfall-affected area when the results of the rainfall are applied. The probability of collapse is larger than in other places if it is a site where several factors with high susceptibility are combined. There were 12 different sorts of listings of geospatial information that were broken down into 66 separate classes. The susceptibility result was calculated for 66 variables in relation to the total accumulation and duration of the rainfall. Since the likelihood of occurrence can be examined for each element, it is simple to comprehend how sensitive an unknown slope made up of several variables is to variations in rainfall. The results are exported as Ms Excel data and can be easily analysed later by linking with spatial visualization programs such as the GIS tool. It was possible to expand the prediction methodology through new attempts of the model. However, dependability issues occasionally surfaced after assessing the accuracy and validity.
-
In the case of environmental setup, it is necessary to select different DG and DE models according to the weather conditions and period. The DE model (taking into account IETD, which considers the no-rainfall period) will be appropriate in the case of a long rainy season, while the DG model must be taken into account in the case of damage brought on by heavy rain.
-
It was proven by checking the rainfall data that the model wasn't appropriate for an extremely short rainfall period. The collapse occurred even though there was no rainfall for 6–8 h before the collapse below, and 2 mm of rainfall occurred for 2 h thereafter. This is because, if the DG is set to 8 h or the IETD is set to 6 h or less, the susceptibility of each DGSI reaches the maximum value at 2 mm of rainfall. This is due to the fact that a cumulative rainfall of 2 mm makes it challenging to determine the occurrence of a landslide. There was no case of collapse due to rainfall only for 3 consecutive hours without preceding rainfall. However, since the model can set a period of 3 h or less, it is inevitably judged that the region has a very high probability of collapse even with a small rainfall, as shown in Figs. 16 and 17. This is considered to be an error of the DG model.

Susceptibility according to cumulative rainfall considering DG = 3 h.

Susceptibility according to cumulative rainfall considering IETD = 3 h.
-
The model relies on historical landslide-induced rainfall data. Therefore, although there is a possibility that a landslide may occur in the same rainfall and geospatial information circumstance, If the DG is entered for a little time just prior to the landslide, the prediction accuracy may be reduced. This is also because the number of cases is relatively small (174), and it depends a lot on the reliability of the rainfall data at the exact time of occurrence. Because it considers the drying period, the IETD model is frequently used in previous research, and the DE model is also seen to have better results. In addition, since there are cases where there are 10 h of no rainfall in the rainfall data, it is necessary to select an IETD of 10 h or more in order to judge the sensitivity more accurately in the cases collected in this study.
-
Researchers established an effective duration (ED) in advance, which they believed to have had an impact on the occurrence of landslides, and also suggested rainfall thresholds to anticipate landslides observed in the past. For IETD, the 12 h1, 24 h2,3,4,5,6,7,8, 48 h6,9,10, and 96 h6,10 are predetermined to assess and derive the study outcomes. Additionally, because it utilizes pre-confirmed rainfall data, research that combines geographical information, including studies that perform dynamic analysis, does not allow for the free setting of the time. Based on prior research, the researcher may choose an acceptable period for undertaking research. But because the pattern of rainfall and the features of certain spatial factors are complex, it was concluded that a study on the dynamic analysis approach using this model was required because the abnormal climatic phenomena will increase in the future. The number of cases may be insufficient because gathering accurate data is of the utmost importance, but if big data is established in the future, better outcomes are anticipated.
-
Conclusions
Landslides occur due to irregularities in natural phenomena and are difficult to predict. Thus, landslide studies rely on the anticipation of events using rainfall and spatial information characteristics based on historical data. Landslide prediction is due to a complex causal relationship where the characteristics of rainfall, rainfall duration, and spatial information act at the same time. This study tried to establish the relationship with variables by using the system dynamics model useful for analysing complex phenomena and finally to determine the susceptibility of each detailed spatial information according to the change in rainfall period and accumulated rainfall. Data construction and modelling (rainfall modelling design, combine rainfall and spatial information) were performed for susceptibility analysis. The validity of the data is directly related to the accuracy of the prediction. Therefore, in order to secure valid data at the time of construction, rainfall data was collected through a verification procedure. In order to take into account the characteristics of rainfall and spatial information with complicated causal connections, this work devised and utilized a technique employing system dynamics modelling58 that is appropriate for complex systems. As a consequence, improvements have been made in the current study that primarily conducts the analysis within the specified rainfall circumstances and individually examines the existing rainfall features and geospatial information. By reflecting the rainfall characteristics that change in real-time, the susceptibility of each spatial information factor can be determined. By introducing a new random variable based on the rainfall duration and cumulative rainfall in a region with complex terrain, combined geology, hydrology, and other factors, it was determined that this research validated the probability of a landslide.
However, this study has some limitations. The data itself is not sufficient because a relatively small number of cases were analysed to obtain accurate rainfall data and occurrence point information. In the future study, more accurate analysis of the susceptibility of the regional unit can be performed using the construction of data at the area unit or the area unit of the collapse occurrence point. In addition, although a new approach has been made with available materials, it is inevitable that accuracy problems arise in predicting natural phenomena. However, the results of this study are expected to contribute to the modification of regional rainfall evacuation standards as reference materials for future landslide warnings. Additionally, they are expected to be used as reference materials for presenting rainfall limits according to hourly rainfall changes by terrain space that has complex geomorphological elements to save lives.
Results may not be precise at this time, but a large amount of information enables it to validate the likelihood of collapse when the duration and amount of rainfall change in real-time. We expect that this research will help to reduce landslide damages by contributing to the landslide warning standards.
Data availability
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
References
Onodera, T., Yoshinaka, R. & Kazama, H. Slope failures caused by heavy rainfall in japan. J. Jpn Soc. Eng. Geol. 15, 191–200 (1974).
Govi, M. & Sorzana, P. Landslide susceptibility as function of critical rainfall amount in Piedmont basin (Northwestern Italy). Stud. Geomorphol. Carpatho-Balcanica 14, 43–60 (1980).
Jibson, R. W. Debris flows in southern Puerto Rico. In Landslide Processes of the Eastern United States and Puerto Rico (Geological Society of America, 1989). https://doi.org/10.1130/SPE236-p29.
Raymond, C. W. & Angela, S. J. Preliminary maps showing rainfall thresholds for debris-flow activity, San Francisco Bay Region, California. U. S. Geol. Surv. Open. File. Rep. 97–745, 1–20 (1997).
Aleotti, P. A warning system for rainfall-induced shallow failures. Eng. Geol. 73, 247–265 (2004).
Lee, S. Current and future status of GIS-based landslide susceptibility map**: A literature review. Korean J. Remote Sens. 35, 179–193 (2019).
Nedumpallile Vasu, N. et al. A new approach to temporal modelling for landslide hazard assessment using an extreme rainfall induced-landslide index. Eng. Geol. 215, 36–49 (2016).
Yilmaz, I. Landslide susceptibility map** using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat-Turkey). Comput. Geosci. 35, 1125–1138 (2009).
Pradhan, A. M. S. & Kim, Y. T. Rainfall-induced shallow landslide susceptibility map** at two adjacent catchments using advanced machine learning algorithms. ISPRS Int. J. Geo-Inf. 9, 569 (2020).
Aditian, A., Kubota, T. & Shinohara, Y. Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 318, 101–111 (2018).
Choi, J., Oh, H. J., Lee, H. J., Lee, C. & Lee, S. Combining landslide susceptibility maps obtained from frequency ratio, logistic regression, and artificial neural network models using ASTER images and GIS. Eng. Geol. 124, 12–23 (2012).
Dahal, R. K. Regional-scale landslide activity and landslide susceptibility zonation in the Nepal Himalaya. Environ. Earth Sci. 71, 5145–5164 (2014).
Pradhan, A. M. S. & Kim, Y. T. Relative effect method of landslide susceptibility zonation in weathered granite soil: A case study in Deokjeok-ri Creek, South Korea. Nat. Hazards 72, 1189–1217 (2014).
Bai, S., Lü, G., Wang, J., Zhou, P. & Ding, L. GIS-based rare events logistic regression for landslide-susceptibility map** of Lianyungang, China. Environ. Earth Sci. 62, 139–149 (2011).
Davis, J. C., Chung, C. J. & Ohlmacher, G. C. Two models for evaluating landslide hazards. Comput. Geosci. 32, 1120–1127 (2006).
Dai, F. C. & Lee, C. F. Landslide characteristics and slope instability modeling using GIS, Lantau Island, Hong Kong. Geomorphology 42, 213–228 (2002).
Reichenbach, P., Rossi, M., Malamud, B. D., Mihir, M. & Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth Sci. Rev. 180, 60–91 (2018).
Gómez, H. & Kavzoglu, T. Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng. Geol. 78, 11–27 (2005).
Biswajeet, P. & Saro, L. Utilization of optical remote sensing data and GIS tools for regional landslide hazard analysis using an artificial neural network model. Earth Sci. Front. 14, 143–151 (2007).
Pradhan, B. & Lee, S. Landslide risk analysis using artificial neural network model focussing on different training sites. Int. J. Phys. Sci. 4, 01–015 (2009).
Rezapour Andabili, N. & Safaripour, M. Identification of precipitation trend and landslide susceptibility analysis in Miandoab County using MATLAB. Environ. Monit. Assess. 194, 1–13 (2022).
Habumugisha, J. M. et al. Landslide susceptibility map** with deep learning algorithms. Sustain. 14, 1–22 (2022).
Adnan, M. S. G. et al. Improving spatial agreement in machine learning-based landslide susceptibility map**. Remote Sens. 12, 1–23 (2020).
Huang, F. et al. Uncertainty pattern in landslide susceptibility prediction modelling: Effects of different landslide boundaries and spatial shape expressions. Geosci. Front. 13, 101317 (2022).
Peruccacci, S. et al. Rainfall thresholds for possible landslide occurrence in Italy. Geomorphology 290, 39–57 (2017).
Kang, H.-S. & Kim, Y.-T. A study on warning level-based-landslide triggering rainfall criteria considering weathered soil type and landslide type. J. Korean Soc. Hazard Mitig. 16, 341–350 (2016).
Lee, H. G. & Kim, G. H. Landslide risk assessment in inje using logistic regression model. J. Korean Soc. Surv. Geod. Photogramm. Cartogr. 30, 313–321 (2012).
Vennari, C. et al. Rainfall thresholds for shallow landslide occurrence in Calabria, southern Italy. Nat. Hazards Earth Syst. Sci. 14, 317–330 (2014).
Kim, Y. T., Shin, H. S., Oh, G. T. & Yun, D. H. Development of Steep-slope Disaster Risk Evaluation System—Focused on Gyeonggi·Gyeongsang Province. https://www.ndmi.go.kr/research/research/view.jsp?DOC_ID=D0000016308 (2019).
Kim, Y. T., Shin, H. S., Oh, G. T. & Yun, D. H. Operation of Steep-slope Disaster Early Warning System—Focused on Gangwon Province. https://www.ndmi.go.kr/research/research/view.jsp (2018).
Lee, H. G., Lee, J. Y. & Lee, G. I. Steep Slope Disaster Forecasting Alarm System Actualization—Focused on Ulsan. https://www.ndmi.go.kr/research/research/view.jsp?DOC_ID=D0000015365 (2017).
Das, I., Sahoo, S., van Westen, C., Stein, A. & Hack, R. Landslide susceptibility assessment using logistic regression and its comparison with a rock mass classification system, along a road section in the northern Himalayas (India). Geomorphology 114, 627–637 (2010).
Quan, H. C. & Lee, B. G. GIS-based landslide susceptibility map** using analytic hierarchy process and artificial neural network in Jeju (Korea). KSCE J. Civ. Eng. 16, 1258–1266 (2012).
Bogaard, T. A. & Greco, R. Landslide hydrology: From hydrology to pore pressure. Wiley Interdiscip. Rev. Water 3, 439–459 (2016).
Bogaard, T. & Greco, R. Invited perspectives: Hydrological perspectives on precipitation intensity-duration thresholds for landslide initiation: Proposing hydro-meteorological thresholds. Nat. Hazards Earth Syst. Sci. 18, 31–39 (2018).
Lee, S.-J. & Ma, H.-S. Development of prediction technique of landslide using forest environmental factors. J. Agric. Life Sci. 52, 63–72 (2018).
Ciach, G. J. & Krajewski, W. F. On the estimation of radar rainfall error variance. Adv. Water Resour. 22, 585–595 (1999).
Krajewski, W. F. & Smith, J. A. Radar hydrology: Rainfall estimation. Adv. Water Resour. 25, 1387–1394 (2002).
Wilson, J. W. & Brandes, E. A. Radar measurement of rainfall—A summary. Bull. Am. Meteorol. Soc. 60, 1048–1060 (1979).
Tabary, P. The New French operational radar rainfall product. Part I: Methodology. Weather Forecast. 22, 393–408 (2007).
Marshall, J. S., Langille, R. C. & Palmer, W. M. K. Measurement of rainfall by radar. J. Atmos. Sci. 4, 186–192 (1947).
Naidu, S. et al. Early warning system for shallow landslides using rainfall threshold and slope stability analysis. Geosci. Front. 9, 1871–1882 (2018).
Guzzetti, F., Peruccacci, S., Rossi, M. & Stark, C. P. Rainfall thresholds for the initiation of landslides in central and southern Europe. Meteorol. Atmos. Phys. 98, 239–267 (2007).
Forrester, J. W. System dynamics, systems thinking, and soft OR. Syst. Dyn. Rev. 10, 245–256 (1994).
Forrester, J. Some basic concepts in system dynamics. Sloan Sch. Manag. 1–17 (2009).
Kritikos, T. & Davies, T. Assessment of rainfall-generated shallow landslide/debris-flow susceptibility and runout using a GIS-based approach: Application to western Southern Alps of New Zealand. Landslides 12, 1051–1075 (2015).
Oh, H., Lee, S. & Hong, S. Technique with iterative random sampling. J. Sens. 2017, 1–21 (2017).
Lee, D. H., Kim, Y. T. & Lee, S. R. Shallow landslide susceptibility models based on artificial neural networks considering the factor selection method and various non-linear activation functions. Remote Sens. 12, 1194 (2020).
Ahmad, H. et al. Geohazards susceptibility assessment along the upper indus basin using four machine learning and statistical models. ISPRS Int. J. Geo-Inf. 10, 315 (2021).
Pradhan, A. M. S., Lee, S. R. & Kim, Y. T. A shallow slide prediction model combining rainfall threshold warnings and shallow slide susceptibility in Busan, Korea. Landslides 16, 647–659 (2019).
Caine, N. The rainfall intensity: Duration control of shallow landslides and debris flows. Geogr. Ann. 62, 23–27 (1980).
Dahal, R. K. & Hasegawa, S. Representative rainfall thresholds for landslides in the Nepal Himalaya. Geomorphology 100, 429–443 (2008).
He, S., Wang, J. & Liu, S. Rainfall event-duration thresholds for landslide occurrences in China. Water (Switzerland) 12, 494 (2020).
Lee, W. Y., Park, S. K. & Sung, H. H. The optimal rainfall thresholds and probabilistic rainfall conditions for a landslide early warning system for Chuncheon, Republic of Korea. Landslides 18, 1721–1739 (2021).
Segoni, S., Tofani, V., Rosi, A., Catani, F. & Casagli, N. Combination of rainfall thresholds and susceptibility maps for dynamic landslide hazard assessment at regional scale. Front. Earth Sci. 6, 85 (2018).
Park, J. Y., Lee, S. R., Kim, Y. T., Kang, S. & Lee, D. H. A regional-scale landslide early warning system based on the sequential evaluation method: Development and performance analysis. Appl. Sci. 10, 5788 (2020).
Park, J. Y., Lee, S. R., Lee, D. H., Kim, Y. T. & Lee, J. S. A regional-scale landslide early warning methodology applying statistical and physically based approaches in sequence. Eng. Geol. 260, 105193 (2019).
Hong, S. B., Lee, B. W., Kim, C. H. & Yun, H. S. System dynamics modeling for estimating the locations of road icing using GIS. Appl. Sci. 11, 8537 (2021).
Rossi, M., Guzzetti, F., Reichenbach, P., Mondini, A. C. & Peruccacci, S. Optimal landslide susceptibility zonation based on multiple forecasts. Geomorphology 114, 129–142 (2010).
Guzzetti, F., Reichenbach, P., Ardizzone, F., Cardinali, M. & Galli, M. Estimating the quality of landslide susceptibility models. Geomorphology 81, 166–184 (2006).
Sterlacchini, S., Ballabio, C., Blahut, J., Masetti, M. & Sorichetta, A. Spatial agreement of predicted patterns in landslide susceptibility maps. Geomorphology 125, 51–61 (2011).
Acknowledgements
This research was supported by the Lower-level Core Disaster-Safety 329 Technology Development Program funded by the Ministry of Interior and Safety (MOIS, Korea) [Grant number 2019-MOIS33-005]. This work was supported by the National Research Foundation, Korea (NRF) under Grant [2021R1C1C2010999]. This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2021R1A6A1A03044326).
Author information
Authors and Affiliations
Contributions
J.-J.L.: Conceptualization, methodology, investigation, data curation, writing—original. M.-S.S.: Methodology, writing—review and editing. H.-S.Y.: Writing—review and editing. S.-G.Y.: Methodology, supervision, writing—review and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, JJ., Song, MS., Yun, HS. et al. Dynamic landslide susceptibility analysis that combines rainfall period, accumulated rainfall, and geospatial information. Sci Rep 12, 18429 (2022). https://doi.org/10.1038/s41598-022-21795-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-21795-z
- Springer Nature Limited