
Abstract
With the rapid advancements in deep learning technology, the Transformer-based attention neural network has shown promising performance in keyword spotting (KWS). However, this method suffers from high computational cost since the excessive parameters in the Transformer model and the computational burden of global attention, which limit its applicability in a resource-constrained KWS scenario. To overcome this issue, we propose a novel Swin-Transformer based KWS method. In this approach, first extract dynamic features using Temporal Convolutional Network (TCN) from input Mel-Frequency Cepstral Coefficients (MFCCs). Then, the Swin-Transformer is employed to capture hierarchical multi-scale features, where a window attention is designed to grasp dynamic time–frequency features. Furthermore, to enhance the extraction of contextual information from the spectrogram, a frame-level shifted window attention mechanism is proposed to enhance the inter-window interaction, thus extracting more contextual information from the spectrogram. Experimental results on the speech command V1 dataset verify the effectiveness of the proposal, which achieves a recognition accuracy of 98.01% with less model parameters, outperforming existing KWS methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Keyword spotting is a vital subfield of speech technology. It enables voice-controlled devices can wake up and recognize the keywords of the commands in the human–machine interface. Many smart devices use KWS, such as Apple’s “Hey Siri”, Google’s “Hey Google” and Baidu’s “**ao Du”. By focusing solely on keywords in speech streams, the KWS can effectively overcome the colloquial nature of natural speech and requires fewer computing resources than Automatic Speech Recognition (ASR). As a result, it is widely adopted in portable human–computer dialogue systems.
Traditional methods for KWS can be divided into two main categories: filler model and phoneme lattice [1]. The filler model method represents all negative keywords using a filler model, allowing for the creation of a lightweight real-time system. However, this method necessitates retraining the network model whenever there are modifications or updates to the keywords. In contrast, the phoneme lattice approach employs a phoneme recognizer to detect keywords within an audio stream, generating a phoneme lattice with intermediate states. Subsequently, the phoneme sequences corresponding to the keywords are sought within this lattice, and their confidence probabilities are calculated using the forward–backward algorithm. While this method facilitates easy customization and modification of keywords, it does have drawbacks, such as consuming substantial storage resources and requiring a two-stage process for obtaining results. Additionally, constructing a real-time system with streaming inputs using the phoneme lattice method proves challenging.
Early KWS systems commonly relied on Hidden Markov Models (HMM) for acoustic modeling of keywords [2]. However, since 2006, the landscape has shifted with the successful implementation of Deep Neural Networks (DNN) [3, 4], making DNN-based KWS the mainstream methods. Both Recurrent Neural Networks (RNN) [5] and Convolutional Neural Networks (CNN) [6, 7] have played pivotal roles in KWS network design. Yet, traditional CNNs face limitations due to their local receptive fields, making it challenging to capture global features adequately. Similarly, RNNs encounter issues related to parallel computing because of their auto-regressive structure, leading to problems like vanishing or exploding gradients. The Transformer [19] stands out by addressing the shortcomings of both CNNs and RNNs through the utilization of a self-attention mechanism. Nonetheless, it contends with a challenge: high model complexity, necessitating substantial computational resources for implementation.
Transformer stands out as a prominent deep learning model founded on attention mechanisms, allowing it to capture extensive contextual information within input sequences. Its efficacy becomes particularly pronounced in scenarios with an ample volume of data. Simultaneously, the Transformer exhibits robust capabilities in parallel training and sequence modeling. In recent years, Transformer models [8,9,10] have exhibited superior performance in KWS task. For instance, Martinc et al. [11] introduced a Transformer-based neural tagger for KWS, which utilizes transfer learning technology to reduce the needed amount of labeled data for training the keyword detector. Higuchi et al. [12] proposed a cross-attention-based KWS method, employing a two-stage model to accomplish phoneme transcription and keyword classification. **e et al. [13] presented a speech recognition method based on a TCN-Transformer-CTC model, which fuses TCN [20] and Transformer while employing Connectionist Temporal Classification (CTC) for sequence alignment. This fusion achieved high accuracy in speech recognition tasks.
Current Transformer-based methods are mainly divided into two categories: transducer-based method [14] and Joint Attention-CTC based method [15]. The former is a multi-level KWS framework, which includes a keyword detector based on the Transducer, a frame-level forced alignment module, and a decoder based on the Transformer. During model inference using the Transducer, streaming allows for phoneme-level output generation. This approach simplifies decoding graph reconstruction to meet user-defined keyword requirements without requiring iterative neural network retraining. On the other hand, the joint attention-CTC model [13] utilizes the CTC alignment to facilitate acoustic frames and identification tag alignment. By combining the attention mechanism with the CTC method in a one-way beam search algorithm during joint decoding, it effectively addresses irregular alignment issues encountered during training.
Swin-Transformer [16] is a backbone network developed by Microsoft. It has achieved state-of-the-art performance in image classification, object detection, semantic segmentation, and other computer vision tasks. Swin-Transformer restricts its attention to a local window to capture local features and acquires global relevant information by using a shifted window to establish contextual connections. Compared to the standard Transformer, Swin-Transformer effectively reduces computational complexity and improves learning efficiency. Chen et al. [17] were pioneers in applying Swin-Transformer to speech classification. Their Swin-Transformer-based HTS-AT model produces impressive results across multiple corpora, demonstrating the effectiveness and robustness of this architecture beyond the traditional backbone.
We believe the shifted window mechanism of Swin-Transformer is analogous to frame-by-frame speech processing method, making it well-suited for constructing a streaming speech system. Therefore, we propose a KWS method based on Swin-Transformer. This method initially extracts MFCCs and employs TCN to capture dynamic time–frequency features evolving along the temporal axis. TCN features (capturing time–frequency dynamical features) are extracted from the lower layer and then progress to abstract layer using Swin-Transformer. Finally, CNN is utilized to merge the output features of Swin-Transformer for KWS. Compared to the current mainstream KWS models, the proposed method demonstrates superior long-term speech feature extraction capability and effectively reduces computational complexity. Experiments on the Speech Command V1 dataset [18] substantiate the efficacy of our proposed approach.
As far as we know, this is the first time that the Swin-Transformer model has been used in the KWS field. Our proposed approach presents several distinct advantages:
-
(1)
Compared to standard Transformer, Swin-Transformer utilizes a window attention mechanism, which leads to less computational resources consumption. This mechanism facilitates the aggregation of global relevant information by establishing connections within the context through shifted windows. Moreover, attention is independently computed within each window. This ingenious strategy not only reduces the computational burden on the model but also notably enhances its capability to extract local features, consequently leading to improved accuracy in KWS tasks.
-
(2)
The effective combination of Swin-Transformer and TCN allows the model to extract dynamic features from the input MFCCs in parallel. Through the integration of a residual network, the model effectively addresses the challenge of vanishing gradient, thereby enabling the extraction of long-term feature information from speech signals. It greatly improves the long-time information perception ability of the model.
2 Methodology
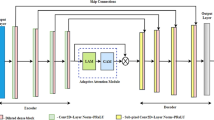
The proposed KWS method is mainly composed of TCN and Swin-Transformer in series. The core procedure is illustrated in Fig. 1. Firstly, MFCC features are extracted from speech signals. Subsequently, these features are fed into TCN for the initial extraction. The resulting feature map is then input into the Swin-Transformer for block processing and window attention calculation, facilitating further feature extraction. Ultimately, the KWS results are generated through a CNN classification operation.

System framework diagram of the proposed KWS method
2.1 Temporal Convolutional Network
During speech feature extraction, the temporal nature of speech signals requires greater consideration of the ability to extract features across the time dimension. Moreover, 1D convolution requires less computation than 2D convolution. At the same time, to enhance the capability of extracting multi-scale features and improve real-time performance, we utilize TCN for initial feature extraction from MFCCs. TCN not only effectively reduces the model parameters but also better captures long-term feature information in speech signals compared to the method using only MFCCs. The structure of the TCN is shown in Fig. 2.

TCN module for feature extraction
By padding zeros into the input, we maintain consistent input and output specifications. In addition, we employ causal convolution, ensuring that the output at each time step relies solely on the input at or before that time. We input a time series X and extract features using TCN, resulting in a time series Y of equivalent length to the initial input. Equation (1) delineates the calculation process.
2.1.1 Dilated Causal Convolution
The causal convolution is utilized in the network structure to ensure the causality of TCN. To augment the extraction of global features, we employ dilated convolutions, forming causal dilated convolutions. This approach effectively broadens the receptive field of TCN. As illustrated in Fig. 3, selectively skip** certain feature points can expand the convolutional receptive field without necessitating the addition of extra model layers.

Dilated causal convolution in the TCN module
2.1.2 Residual Network
The receptive field of TCN is closely related to the depth of the model, the expansion rate of the convolutional layer and the size of the convolutional kernel. To ensure the stability of the model when the speech is too long, we use a residual network, as shown in Eq. (2):
As shown in Fig. 4, the residual connection effectively mitigates the issues of vanishing gradient, complex training, and poor fitting.

Residual network in the TCN module
2.2 Swin-Transformer
To address the issue of the excessive complexity of the Transformer, we propose employing the Swin-Transformer [16] to extract hierarchical features from the input feature map for the KWS task. The architecture of the Swin-Transformer is depicted in Fig. 5 and is primarily divided into three parts: the dimension transformation module, feature extraction module, and classification prediction module.

The architecture of Swin-Transformer model
2.2.1 Dimension Transformation
The output size of the Temporal Convolutional Network (TCN) varies owing to the disparate durations of individual speech. To standardize the size and facilitate the use of the patch merge module, the output size of TCN is unified to 256 × 256 by linear interpolation and up-sampling. Compared with the dimension transformation method in HTS-AT [17], the one proposed in this paper can better preserves the feature information.
2.2.2 Feature Extraction Module
The feature extraction module is depicted in Fig. 5. The Swin-Transformer utilizes four-stage modules to conduct hierarchical feature extraction on the feature map. Each stage module includes a patch merge module and a Swin module.
In the initial stage, the patch merge module divides the input feature map into non-overlap** blocks. This module is used to perform a bisection operation on the feature maps and merge them in the channel dimensions, thus changing the channel dimensions from C to 4C. And halved it to 2C by a linear layer. Through a linear layer, channel dimension is reduced by half to 2C. Channel dimension is merged to ensure that channel dimension and feature dimension are equal, effectively preventing the loss of feature information. Through Patch Merge operation at each stage, the amount of data processed is halved, leading to a significant improvement in processing speed.
After the patch merge operation, the self-attention is calculated in each divided window, as shown in Formula (3). Here, Q, K, and V are obtained through a linear transformation of input X. Q represents the query of X, K represents the key of input X, V represents the value of input X, and represents the dimensions of Q and K.
The Swin module architecture is shown in Fig. 6, which includes two levels of Swin units. The first-level Swin unit utilizes the window self-attention mechanism, while the second-level Shift-Swin module employs the window self-attention mechanism with shifted window operation. Windowed self-attention calculation first divides feature map into a P × P grid, and then performs self-attention calculation on the feature map within each window. Compared to the multi-head self-attention mechanism of standard Transformer, the computation of the model is greatly reduced. The comparison between multi-head attention mechanism of the standard Transformer and the window self-attention mechanism of the Swin-Transformer is as follows:

The architecture of Swin module
The windowed self-attention mechanism presents a substantial reduction in computational complexity when compared to the traditional self-attention mechanism. However, windowed self-attention restricts attention to individual windows, with no inter-window connection and limited information interaction. To enhance global feature extraction, the Shift-Swin module incorporates a window self-attention mechanism that includes shifted window operation. Whenever the window slide operates, it moves half the size of the window, aiming to enhance the information interaction of adjacent windows. The specific principle of the shifted window operation is illustrated in Fig. 7. Following the shifted window operation at the edge of the feature map, the resulting feature map will contain an empty area. By copying the feature information from adjacent windows to fill the vacant part and then masking the filled part, the issue of feature vacancy can be effectively resolved. At the same time, a residual connection is added to each Swin module. This not only prevents gradient disappearance but also enhances the ability to extract local features.

Shifted window operation
2.2.3 Windowed Attention Optimization
The attention mechanism refers to the allocation of focus on significant regions of features in computer vision, prioritizing essential aspects while disregarding non-essential information. This process facilitates the allocation of more resources to essential features. To enhance the feature expression capability of networks, in addition to methodologies that focus on network depth, width, and dimensions, optimizing attention mechanisms also serves as a means to improve feature expression capabilities.
We focus on optimizing the attention window size within the Swin module. To process speech signals characterized by temporal patterns, a matrix-shaped attention window is used. This window is embedded within the self-attention computation of each layer, resulting in the creation of a novel windowed self-attention computation module. Simultaneously, to extract feature information from each frame of the input speech signal while ensuring temporal contextual relevance, a frame-level windowed self-attention mechanism is utilized. This mechanism adaptively adjusts the frequency-domain scale of the window based on the input signal and shifts along the temporal dimension. Both of the aforementioned optimization processes are depicted in Fig. 8.

Attention window optimization strategy
In Fig. 8a, we present the MFCC feature map of an input speech signal. The application of windowed attention mechanisms to such sequential signals adeptly captures local feature information. Introducing a shifted window mechanism resolves the weak interaction between windows. However, the original square-shaped attention window proves unsuitable for processing speech signals, as illustrated in Fig. 8b. Unlike image features, the MFCC feature map has a rectangular-like shape. Utilizing a square attention window to extract features from speech signals may lead to subsequent feature processing errors. Hence, it is more practical to employ a rectangular-shaped attention window specifically designed to align with speech signals. As illustrated in Fig. 8c, we propose an optimized attention window by substituting the original square-shaped attention window with a rectangular-shaped one. In comparison to the original approach, the rectangular-shaped self-attention window, featuring a temporal length greater than its frequency-domain counterpart, more effectively captures temporal sequential features in speech signals. This design enables a more comprehensive extraction of information from MFCC features and effectively prevents an overemphasis on frequency-domain features at the expense of temporal characteristics.
Furthermore, since each frame of the input speech signal contains highly correlated information, both square and rectangular attention windows struggle to effectively extract the global features of each frame. Therefore, we utilize a frame-level attention window mechanism, as illustrated in Fig. 8d. This mechanism calculates self-attention using information from each frame of the input MFCC feature. Compared to the previous two methods, it comprehensively extracts frame-level feature information from the speech signal. Through the shifted window mechanism, this approach ensures temporal contextual relevance, thereby enhancing the model's ability to extract global features.
To analyze the complexity of these three windowed self-attention mechanisms, we can precisely define them using the following formula:
where H, W, and C are defined consistently with formula (4), \(P_{T}\) and \(P_{F}\), respectively, represent the temporal and frequency-domain scale sizes of the attention window. From formula (7), we can find \(P_{T} \times P_{F}\) remains constant when the attention window sizes are equal. Therefore, without changing the window sizes, the computational complexity of windowed self-attention does not increase. The adopted windowed attention optimization strategy does not result in an increased computational burden on the device.
2.3 Loss Function
In this work, the cross-entropy loss function is used to optimize the model parameters. The calculation formula is as follows:
where \({y}_{i}\) represents the true value of \({x}_{i}\), and \(pre\left({x}_{i}\right)\) represents the corresponding predicted value of \({x}_{i}\) obtained through the model.
A dynamic learning rate is utilized in the training process with an initial learning rate of 0.001. The update strategy of the learning rate is as follows: During the evaluation process if the loss is not reduced after three consecutive epochs, the learning rate will be halved.
3 Experiments
3.1 Dataset
The Speech Command V1 dataset is employed for training and evaluating. It contains 30 keywords, and the sampling frequency is 16 kHz. Each speech lasts about 4 s, including 1 instance of the keyword. To address class imbalance [21], 10 keywords are selected based on their frequency, and the remaining 20 keywords are considered as irrelevant.
3.2 Hyper-Parameter Tuning Strategy
To gain deeper insights into the Swin-Transformer, it is essential to analyze its performance across different model depths and attention heads using the Speech Command V1 dataset. Each processing stage employs an attention window size of 8 × 8. In the Swin-Transformer model, there are 2 Swin modules in the first, second, and fourth processing stages, while the third stage incorporates 6 or 18 Swin modules. Through the manipulation of the number of attention heads, we aim to analyze their impact on the effect. Table 1 presents the experimental results of the model on the Speech Command V1 dataset. The results indicate that the recognition accuracy of the Swin- transformer tends to improve as the number of Swin modules increases. However, increasing the attention heads does not produce a similar substantial enhancement. Notably, the model achieved a peak accuracy of 98.01% when configured with 18 layers and attention heads set to (3, 6, 12, 24). In keyword recognition tasks, increasing the depth of the model leads to higher attention head counts, which can potentially accumulate errors and thus reduces recognition accuracy.
Table 2 illustrates a performance analysis across different attention window sizes. The experimental results show that the model achieves the best performance when the attention window of each level is uniformly configured to 8. Maintaining a consistent window size facilitates the map** of features between each layer. Different window sizes will lead to variations in the attention calculation within each window, leading to a partial loss of information.
3.3 Comparison with Other Models
We compare our method with other mainstream deep learning based-KWS methods, including LSTM [22], Transformer [23], DS-CNN [22], and DS-CNN-TCN. Each model is trained 10 times for 100 epochs to obtain 10 different model parameters., and the ultimate validation model is obtained through result averaging. LSTM, Transformer, and DS-CNN all follow the default configurations detailed in the corresponding papers. KWT-8 and KWT-16 denote Transformer variants with 8 and 16 attention heads, respectively. TCN-DS-CNN is an extension of DS-CNN with feature extraction accomplished using the TCN.
For the Swin-Transformer model, we compare two cases: (1) Swin-Transformer, using MFCC directly as the input feature; (2) TCN + Swin-Transformer, which uses TCN-processed MFCC features as the input of Swin-Transformer. Table 3 shows the accuracy of various KWS models on the Speech Command V1 dataset.
Table 3 demonstrates that TCN + Swin-Transformer has outperformed other models. As the number of attention heads increases, the recognition accuracy of the Transformer-based model gradually improves. Transformer-16 achieves 81.17% accuracy with 19,185.7 K parameters, while Swin-Transformer attains 87.49% accuracy with only 3068.1 K parameters. This demonstrates that the Swin-Transformer outperforms the traditional Transformer in KWS tasks. The Swin-Transformer not only greatly reduces the parameters through windowed attention computation, but also significantly improves the recognition performance. However, both Swin-Transformer and Transformer rely on extensive datasets. Compared to traditional deep learning methods such as LSTM and DS-CNN, they struggle to fully harness their advantages. Additionally, they require substantial computational resources during training. Achieving an accuracy of 87.49% in situations with limited device resources is already considered quite remarkable. Compared to Swin-Transformer, TCN + Swin-Transformer achieves superior results, with a recognition rate of 98.01%. Experimental results highlight that using TCN for MFCC feature extraction enables better capture of historical information in the speech signal, effectively enhancing the recognition accuracy.
A comparison of the loss curves of the different models is given in Fig. 9. We can observe that the Transformer converges slowly. While Swin-Transformer converges faster than Transformer because it restricts the attention to a local window. TCN + Swin-Transformer enhances the consideration of historical information using TCN, thereby speeding up the convergence of Swin-Transformer. The loss of TCN + Swin-Transformer converges to a lower level at the 40th epoch compared to the other models. TCN-DS-CNN converges quickly as well but with higher initial loss values. It nearly overlaps the curve of TCN + Swin-Transformer only after training for 80 epochs.

Comparison of training loss function curves of different methods
4 Conclusions
We present a novel KWS method leveraging the Swin-Transformer architecture. This marks the pioneering application of the Swin-Transformer in KWS tasks. The successful amalgamation of the Swin-Transformer with TCN underscores the robust potential of the windowed attention mechanism within KWS fields. Importantly, Swin-Transformer shows the potential of serving as a universal backbone for future recognition models. Next, we will explore the application of Swin-Transformer in individual-specific KWS tasks, researching Swin-Transformer models based on speaker information and integrating more priori speech knowledge. Our research aims to propel the development of Swin-Transformer within KWS fields.
Data availability
Datasets used during the current study. These datasets were derived from the following public domain resources “http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz” and “http://download.tensorflow.org/data/speech_commands_test_set_v0.01.tar.gz”.
Abbreviations
- KWS:
-
Keyword spotting
- TCN:
-
Temporal Convolutional Network
- ASR:
-
Automatic Speech Recognition
- HMM:
-
Hidden Markov Model
- DNN:
-
Deep Neural Networks
- RNN:
-
Recurrent Neural Network
- CNN:
-
Convolutional neural network
- CTC:
-
Connectionist temporal classification
- MFCC:
-
Mel-Frequency Cepstral Coefficient
References
Chengli Sun. Research on speech keyword recognition technology [D]. (2008)
Dridi, H., Ouni, K.: Hybrid context dependent CD-DNN-HMM keywords spotting on continuous speech[C]. 2017 International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), 1–7 (2017)
Wang, D., Li, T., Deng, P., et al.: A generalized deep learning algorithm based on NMF for multi-view clustering[J]. IEEE Trans. Big Data 9(1), 328–340 (2023)
Wang, D., Li, T., Deng, P., et al.: A generalized deep learning clustering algorithm based on non-negative matrix factorization[J]. ACM Trans. Knowl. Discover. Data 17, 1–20 (2023)
Liu, Z., Li, T., Zhang, P.: RNN-T Based open-vocabulary keyword spotting in mandarin with multi-level detection[C]. ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5649–5653 (2021)
H D, K O. pplying hybrid “CD-CNN-HMM” model for keywords spotting in continuous speech[C]. 2018 International Conference on Electrical Sciences and Technologies in Maghreb (CISTEM), 1–7 (2018)
Rostami, A.M., Karimi, A., Akhaee, M.A.: Keyword spotting in continuous speech using convolutional neural network[J]. Speech Commun.Commun. 142, 15–21 (2022)
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need[C]. Proceedings of the 31st International Conference on Neural Information Processing Systems, 6000–6010 (2017)
Yang, R.Y., Cheng, G.F., Miao, H.R., et al.: Keyword search using attention-based end-to-end ASR and frame-synchronous phoneme alignments[J]. IEEE-Acm Trans. Audio Speech Language Process. 29, 3202–3215 (2021)
Ding, K., Zong, M., Li, J., et al.: LETR: a lightweight and efficient transformer for keyword spotting[C]. ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7987–7991 (2022)
Martinc, M., Skrlj, B., Pollak, S.: TNT-KID: transformer-based neural tagger for keyword identification[J]. Nat. Language Eng. 28(4), 409–448 (2022)
Higuchil, T., Gupta, A., Dhir, C.: Multi-Task Learning with Cross Attention for Keyword Spotting[C]. 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 571–578 (2021)
**e, X., Chen, Ge., Sun, J., et al.: End-to-end speech recognition of TCN-transformer-CTC[J]. Comput. Appl. Res. 39(03), 699–703 (2022)
Zhang, Q., Lu, H., Sak, H., et al.: Transformer transducer: a streamable speech recognition model with transformer encoders and RNN-T loss[C]. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7829–7833 (2020)
Park, H., Kim, C., Son, H., et al.: Hybrid CTC-Attention Network-based end-to-end speech recognition system for korean language[J]. J. Web Eng. 21(2), 265–284 (2022)
Liu, Z., Lin, Y., Cao, Y., et al.: Swin transformer: hierarchical vision transformer using shifted windows[C]. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9992–10002 (2021)
Chen, K., Du, X., Zhu, B., et al.: HTS-AT: a hierarchical token-semantic audio transformer for sound classification and detection[C]. ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 646–650 (2022)
Pete, W.: Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition[J].ar**v - CS - Human-Computer Interaction (2018)
Deok**, S., Heung-Seon, O., Yuchul, J.: Wav2KWS: Transfer learning from speech representations for keyword spotting[J]. IEEE Access 9, 80682–80691 (2021)
Shaojie, B., Kolter, J. Z., Vladlen, K.: An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[J]. ar**v - CS - Computation and Language (2018)
Lopez-Espejo, I., et al.: Deep spoken keyword spotting: an overview[J]. IEEE Access 10, 4169–4199 (2022)
Yundong, Z., Naveen, S., Liangzhen, L., et al.: Hello Edge: keyword spotting on microcontrollers[J]. ar**v - CS - Neural and Evolutionary Computing (2017)
Axel, B., Mark, O. C., Miguel Tairum, C.: Keyword transformer: a self-attention model for keyword spotting[J]. ar**v - CS - Sound (2021)
Acknowledgements
We would like to thank the Government of China, Jiangxi Province, Shandong Province and Nanchang Hangkong University for providing us the necessary facilities and funding. We would also like to thank the editors and reviewers for their valuable comments.
Funding
Natural Science Foundation of China (Nos. 61861033), Talent Support Program of Jiangxi (No. 20232BCJ22050) Natural Science Foundation of Shandong Province (Nos. ZR2020MF020) and Innovation Foundation of Graduate Students of Nanchang Hangkong University (Nos. YC2022-050).
Author information
Authors and Affiliations
Contributions
CS: conceptualization, methodology, writing–review and editing. BC: experiments, writing-original draft, software, visualization. FC: data curation, validation. YL: validation. QG: resources, data collection.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no competing interests.
Ethics Approval and Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sun, C., Chen, B., Chen, F. et al. Speech Keyword Spotting Method Based on Swin-Transformer Model. Int J Comput Intell Syst 17, 61 (2024). https://doi.org/10.1007/s44196-024-00448-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-024-00448-1