
Abstract
Failure mode and effects analysis (FMEA) is an important risk analysis tool that has been widely used in diverse areas to manage risk factors. However, how to manage the uncertainty in FMEA assessments is still an open issue. In this paper, a novel FMEA model based on the improved pignistic probability transformation function in Dempster–Shafer evidence theory (DST) and grey relational projection method (GRPM) is proposed to improve the accuracy and reliability in risk analysis with FMEA. The basic probability assignment (BPA) function in DST is used to model the assessments of experts with respect to each risk factor. Dempster’s rule of combination is adopted for fusion of assessment information from different experts. The improved pignistic probability function is proposed and used to transform the fusion result of BPA into probability function for getting more accurate decision-making result in risk analysis with FMEA. GRPM is adopted to determine the risk priority order of all the failure modes to overcome the shortcoming in traditional risk priority number in FMEA. Applications in aircraft turbine rotor blades and steel production process are presented to show the rationality and generality of the proposed method.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
As an important risk analysis tool in reliability engineering, failure mode and effects analysis (FMEA) is used for defining and identifying potential failures or problems in design, processes, or services before they reach the end users [1,2,3,4]. FMEA ranks the potential risk item based on the risk priority number (RPN) model, which is defined by multiplying three risk factors named the Occurrence (O), Severity (S), Detectability (D), where O means the probability of the occurrence of a FMEA item, S means the severity degree if a failure happens with respect to the corresponding FMEA item, and D is the probability of a potential FMEA item being detected. Briefly, the basic process of applying FMEA is as follows: (1) analyze the target system and obtain the failure modes, (2) obtain the evaluation data of the failure modes regarding the RPN model, (3) rank the failure modes according to the evaluation data based on RPN values, and (4) improve the actual system according to the ranking result. FMEA has been widely applied in practical applications such as industry systems [5, 6], equipment maintenance [7], medical domain [8] and new product development [9]. The hazards in maritime autonomous surface ships during development and operation process are identified with FMEA method in [10]. The failure of Taper–Lock bush used in aggregate batcher plant for construction application is analyzed with FEMA model in [11]. An integrated decision-making algorithm is proposed to overcome some shortcomings in FMEA model and applied in clean energy barriers evaluation in [12]. Sustainable medical waste management systems designing process is analyzed with FMEA model in [13].
Uncertain information modeling and processing is commonly studied in practical applications such as fault diagnosis [14, 15], advanced control in complex systems [16, 17], control of repetitive tasks [18] and classification [55, 56].
Definition 1
Suppose that \(\Omega = \{\theta _1,\theta _2,\ldots ,\theta _N\}\) is a nonempty set with N mutually exclusive and exhaustive events, and \(\Omega \) is called the frame of discernment. The power set of \(\Omega \) consists of \(2^N\) elements denoted as follows:
Definition 2
A mass function m is a map** from the power set \(2^{\Omega }\) to the interval \(\left[ 0,\ 1\right] \). m satisfies:
A mass function is also known as basic probability assignment (BPA) or basic belief assignment (BBA). If \(m(A)>0\), then A is called focal element. The m(A) represents the degree that an evidence supports A.
Definition 3
In DST, two independent mass functions \(m_1\) and \(m_2\) can be fused with Dempster’s rule of combination defined as follows:
where k is a normalization factor defined as:
When two pieces of evidence have high conflict with each other, the classic Dempster’s rule of combination is not efficient. To overcome this limitation, some discounting methods have been proposed based on Dempster’s rule of combination, and this work adopts the one used in [57]:
where \(\alpha \) is the discounting coefficient.
The pignistic probability transformation function \(BetP_m\)
Definition 4
Let m be a BPA on \(\Omega \). Its associated pignistic probability transformation function \(BetP_m\) is defined as follows [58]:
where |A| means the cardinality of the set A. The aim of \(BetP_m\) is to transform a BPA into a probability function for final decision-making in DST framework.
Some key notations in this work are summarized in Table 1.
An improved pignistic probability transformation function
In this section, an improved pignistic probability transformation function based on the classical \(BetP_m\) is proposed. The new method combines the information both in the propositions of singleton and multiple subsets, which can optimize the strategy of assigning the belief value averagely in the pignistic probability transformation function \(BetP_m\).
Limitation in the pignistic probability transformation function
The traditional pignistic probability transformation function assigns the belief of multiple subsets averagely into the singleton. Consequently, as for the singleton A, the \(BetP_m(A)\) can also be expressed as follows:
where n means the number of multiple subsets that include the singleton A. \(A_i\) represents the specific multiple subsets.
Figure 1 shows the visualized effect of \(BetP_m\). The abscissa represents the value of m(A), and the ordinate represents the proportion of belief (\(p_1\)) assigned to A from \(A_n\). Obviously, the line stays parallel with the abscissa. The figure shows the essence of pignistic probability transformation function that the proportion of the belief assigned to the singleton from the multiple subsets is independent of the mass value in the singleton proposition. The averagely assigning method makes the belief being equally utilized by each singleton in spite of the mass value of singleton element. Therefore, it has a good compatibility. However, the complete independence between the singleton mass function value and belief assignment of multiple subsets actually neglects the information given by the original singleton BPA. This strategy excessively narrows the differences in each singleton BPA, which causes inaccuracy and information loss in decision-making section to a certain extent.

An illustration of functional relationship between m(A) and \(p_1\) based on the pignistic probability transformation function \(BetP_m\)
Considering the original BPA in information fusion result during belief assignment of multiple subsets, define a linear pignistic probability transformation function \(\textrm{Lin}_m\) as follows:
where C means the singleton included in the multiple subsets proposition B.
Figure 2 shows the visualized effect of \(\textrm{Lin}_m\). The abscissa represents the value of m(A), and the ordinate represents the proportion of belief (\(p_2\)) assigned to A from B.

An illustration of functional relationship between m(A) and \(p_2\) based on the linear pignistic probability transformation function \(\textrm{Lin}_m\)
Based on the linear pignistic probability transformation function \(\textrm{Lin}_m\), the \(p_2\) is directly proportional to m(A). The figure shows that the proportion of the belief assigned to one singleton from the multiple subsets proposition has complete positive correlation with the singleton mass function value. This assignment method substantially utilizes the information from the original singleton BPA in information fusion result. However, correspondingly, the information from the multiple subsets is neglected. This strategy excessively holds the gap among each singleton BPA, which may also cause inaccuracy in final decision-making section.
The improved pignistic probability transformation function
To address the disadvantage of aforementioned functions \(BetP_m\) and \(\textrm{Lin}_m\), the information in both the original BPA of singleton element of fusion result and the multiple subsets should be utilized. Based on the above analysis, define the improved pignistic probability transformation function \(\textrm{Exp}_m\) as follows:
where C means the singleton included by multiple subsets proposition B, \(\gamma \) is the discounting coefficient.
The following example is proposed to illustrate the calculation procedure of the improved pignistic probability transformation function \(\textrm{Exp}_m\).
Example 1
Define that a frame of discernment is \(\Omega =\{a,b\}\), the following BPAs of information fusion result are constructed:
where t represents the value of m(a), \(t \in \left[ {0,0.9} \right] \). Based on the improved pignistic probability transformation function, the belief assignment result for this example is calculated as follows:
Define that:
Figure 3 shows the visualized effect of the above example (Here, set \(\gamma \)=3 as a numerical example). The abscissa represents the value of t, and the ordinate represents the proportion of belief (\(p_3\)) assigned to \(\{a\}\) from \(\{a,b\}\).

An illustration of functional relationship between t and \(p_3\) based on the improved pignistic probability transformation function \(\textrm{Exp}_m\)
Based on the improved pignistic probability transformation function, the \(p_3\) is directly proportional to t. The proportion of the belief assigned to one singleton from the multiple subsets proposition is a non-liner and exponential-like function of the singleton mass function value. The ascending rate is controlled by the discounting coefficient \(\gamma \), which can be modified to adapt the requirement of different data set. Consequently, the designed strategy combines the information from both the multiple subsets and the original singleton BPA in information fusion result. It also has a good compatibility with the traditional \(BetP_m\) because the improved pignistic probability transformation function \(\textrm{Exp}_m\) will be degenerated to \(BetP_m\) if \(\gamma \) = 0. The effectiveness and practicality of the improved pignistic probability transformation function will be verified in Sect. “A novel FMEA model utilizing the improved pignistic probability transformation function and GRPM”.
A novel FMEA model utilizing the improved pignistic probability transformation function and GRPM
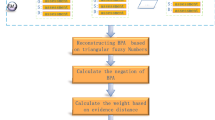
To improve the efficiency of traditional FMEA, a novel FMEA model utilizing the improved pignistic probability transformation function and grey relational projection method (GRPM) is proposed, as shown in Fig. 4.

The flowchart for the novel FMEA model using the improved pignistic probability function in the evidence theory and grey relational projection method
Step 1. Define the failure modes and the level of risk assessment regarding risk factors
Suppose there are k experts involved in the FMEA team (\(E_1,E_2,\ldots ,E_i,\ldots ,E_k\)) for assessing of m failure modes (\(FM_1,FM_2,\ldots ,FM_i,\ldots ,FM_m\)) with respect to three risk factors \(F_R\) denoted as Occurrence (\(F_1\)), Severity (\(F_2\)) and Detectability (\( F_3\)). Considering the flexibility and accuracy of the judgements, each risk factor will be ranked from the lowest level 1 to the highest level 10 [1,2,3, 59], as expressed in Tables 2, 3 and 4 respectively. Each expert will utilize a rating number to assess each risk factor with their belief degree on the assessment. According to the belief structure data of the evaluations, the basic probability assignment can be constructed to represent the belief degree of the assessment coming from the expert.
Step 2. Construct the frame of discernment
Based on DST, the frame of discernment for the three risk factors can be defined as follows:
where \(R=1\), \(R=2\) and \(R=3\) correspond to the risk factor O, S and D respectively, j means the jth FMEA item.
Step 3. Combine the judgement results of experts in FMEA team
Define \(m_{iR}^{j}\) (\(i=1,2,\ldots ,m,R=1,2,3,j=1,2,\ldots ,k\)) as the BPA collected from \(E_j\) on the assessment of \(FM_i\) regarding the risk factor \(F_R\). Then the \(m_{iR}^{'j}\) can be calculated using Eq. (5). Combine BPAs from all the experts by using Eq. (3) and Eq. (4), shown as follows:
Step 4. Calculate \(x_{ij}\) by utilizing the improved pignistic probability transformation function \(\textrm{Exp}_m\)
After combining the judgement results in Step 3, the integrated representation \(x_{ij}\) (\(i=1,2,\ldots ,m,j=1,2,3\)) of the aggregated assessment \(m_{iR}\) can be constructed through discounting combination rule. The value of \(x_{ij}\) is calculated as follows by utilizing the improved pignistic probability transformation function \(\textrm{Exp}_m\):
Step 5. Construct comparative sequence X
In comparative sequence X, \(x_{ij}\) represents the jth factor of \(X_i\). The matrix format of X is defined as follows:
Step 6. Construct reference sequence \(X^+\) and \(X^-\)
The positive sequence means that the evaluation of failure mode on each risk factor is on the lowest risk level.Correspondingly, the negative sequence means that the evaluation of failure mode on each risk factor is on the highest risk level. The double-facet reference sequences improve the reliability of FMEA. \(X^+\) and \(X^-\) are defined as follows:
Step 7. Construct the grey relational matrices \(Y^+\) and \(Y^-\)
First, calculate the grey relation coefficient \(Y_{ij}^{+}\) and \(Y_{ij}^{-}\):
where \(i=1,2,\ldots ,m,j=1,2,3\). \(Y_{ij}^{+}\) is the grey relation coefficient of \(x_{ij}\) with respect to the positive ideal risk factor \(x_{0j}^{+}\). \(Y_{ij}^{-}\) is the grey relation coefficient of \(x_{ij}\) with respect to the negative ideal risk factor \(x_{0j}^{-}\). \(\xi \) is the distinguishing coefficient and \(\xi \in \left[ 0,1\right] \). In this method, the medium value \(\xi \) = 0.5 is applied.
Then, based on the coefficients \(Y_{ij}^{+}\) and \(Y_{ij}^{-}\), the grey relational matrices \(Y^+\) and \(Y^-\) can be denoted as follows:
Step 8. Calculate the grey relation projection \(P^+\) and \(P^-\)
The grey relation projections of \(FM_i\) on the reference sequence \(X^+\) and \(X^-\) respectively are calculated as follows:
Step 9. Calculate the relative projection \(RP_i\) and rank failure modes
The relative projection of each failure mode to the positive reference sequence is defined as follows:
In FMEA, the relative projection value denotes the relative size of each failure mode. The higher the relative projection value, the smaller the impact of the failure mode and correspondingly the lower the ranking priority.
Application
Experiment 1: Application in aircraft turbine rotor blades
In this section, the proposed method is applied to a FMEA case study of rotor blades for an aircraft turbine adopted from [60,61,62,63,64]. Rotor blades are the most damageable component in aircraft turbines due to the complex working environments. The FMEA method is introduced to improve the reliability and safety of the rotor blades’ design.
Experiment process
Step 1. Define the failure modes and the level of risk assessment regarding risk factors. According to previous studies [60,61,62,63,64], eight failure modes (\(FM_i,i=1,2,\ldots ,8\)) are considered with the improved FMEA model and will be ranked for efficient management of risk level. Three experts (\(E_1,E_2,E_3\)) provide the assessment of \(FM_i\) by utilizing 10 levels in terms of the three risk factors denoted as \(F_R\) Occurrence (\(F_1\)), Severity (\(F_2\)) and Detectivity (\(F_3\)).
Step 2. Construct the frame of discernment. According to Eq. (10), the frame of discernment can be defined as follows:
Step 3. Combine the judgement results of experts in FMEA team. The original BPA of the risk factors derived from experts’ assessment is shown in Table 5. The combination result of original BPA using Eqs. (3), (4) and (5) is shown in Table 6.
Step 4. Calculate \(x_{ij}\) by utilizing the improved pignistic probability transformation function \(\textrm{Exp}_m\). First, transform the combining result of BPA into probability function by utilizing the improved pignistic probability transformation function \(\textrm{Exp}_m\) which is denoted in Eq. (9). Then, the value of \(x_{ij}\) can be calculated by using Eq. (12).
To select the ideal discounting coefficient \(\gamma \), we set \(\gamma \) as different values (0, 3, 6, and 9) and calculate the results respectively. In the following steps, we only show the detail of calculating process under the parameter of \(\gamma =3\).
Step 5. Construct comparative sequence X. The comparative sequence X is shown as follows based on the calculating result of \(x_{ij}\):
Step 6. Construct reference sequence \(X^+\) and \(X^-\). The reference sequences \(X^+\) and \(X^-\) can be constructed by using Eqs. (13) and (14).
Step 7. Construct the grey relational matrices \(Y^+\) and \(Y^-\). According to Eqs. (15) and (16), the grey relation matrices \(Y^+\) and \(Y^-\) are calculated, shown as follows:
Step 8. Calculate the grey relation projection \(P^+\) and \(P^-\). \(P^+\) is the grey relation projection of \(FM_i\) on the positive reference sequence and \(P^-\) is the grey relation projection of \(FM_i\) on the negative reference sequence. \(P^+\) and \(P^-\) are calculated by using Eqs. (17) and (18). The calculation result is shown in Table 7.
Step 9. Calculate the relative projection \(RP_i\) and rank failure modes. The relative projection of each failure mode to positive reference sequence \(RP_i\) can be calculated by using Eq. (19). The \(RP_i\) values and the risk priority ranking of all the 8 failure modes in aircraft turbine rotor blades are also shown in Table 7.
Experiment result
Figure 5 shows the ranking results of the 8 failure modes under the condition that \(\gamma \) is assigned with different coefficient values: 0, 3, 6, and 9. If \(\gamma =0\), the experimental result is mathematically equivalent to the result with the pignistic probability transformation function \(BetP_m\). Among the coefficients of \(\gamma =3\), \(\gamma =6\) and \(\gamma =9\), the result under the condition of \(\gamma =3\) has a proximal ranking trend with \(\gamma =0\) according to Fig. 5. In this work, we choose the result under the condition of \(\gamma =3\) for the following experiment and analysis.

The ranking of failure modes under the conditions of \(\gamma =0,3,6,9\)

The ranking of failure modes based on the proposed method in comparison with other methods in Experiment 1
The ranking result for \(FM_i\) under the condition of \(\gamma =3\) is \(FM_3 \succ FM_2 \succ FM_6 \succ FM_1 \succ FM_7 \succ FM_6 \succ FM_8 \succ FM_5\), where \( \succ \) means prior to. The ranking result of the 8 failure modes is compared with the result of some previous studies in [60,61,62,63,64], as shown in Fig. 6. Most of the methods rank \(FM_3\) as the most important failure mode that is supposed to be addressed with the highest priority and \(FM_5\) as the least important failure mode that is supposed to be addressed with the lowest priority. From this perspective, the result of the proposed method is consistent with the previous works. Meanwhile, in general, the proposed method has a similar ranking trend on all the failure modes in comparison with the results of previous studies, which shows the rationality and effectiveness of the proposed method. There is no duplicated ranking level for all the 8 FMEA items with the proposed method.

The ranking of failure modes based on the proposed method in comparison with other methods in Experiment 2
Experiment 2: application in steel production process
To better verify the generalization ability of the proposed FMEA method, we adopt another risk analysis example in [57] as the Experiment 2. In this case study [57], 10 failure modes of sheet steel production process in a steel factory are evaluated by the proposed method with respect to the three risk factors.
The original data of risk analysis in the sheet steel production process is adopted from [57]. The calculation steps based on the proposed method are similar to the application of aircraft turbine rotor blades in Experiment 1. For this reason, the detailed calculation process is omitted here. Table 8 shows the calculation and ranking results with the proposed method. The ranking result of all the 10 failure modes is \(FM_4 \succ FM_7 \succ FM_3 \succ FM_8 \succ FM_5 \succ FM_1 \succ FM_6 \succ FM_{10} \succ FM_9 \succ FM_2\), where \( \succ \) represents prior to.
The comparison of the ranking result with other methods in previous studies of [22, 57, 64, 65] is shown in Fig. 7. The figure indicates that the ranking result obtained by the proposed method has the same trend obtained by the other methods, especially for Wu et al. method [22] and Liu et al. method [64]. The failure mode \(FM_4\) is ranked as the first FMEA item in the proposed method, which is consistent with the results of other three methods. In practical application, a higher priority should be given to the failure mode \(FM_4\) because it has the highest risk level according to the result in the proposed method as well as some other different methods in comparison. It should be noted that there is no duplicated ranking level for all the 10 FMEA items with the proposed method, which shows a good distinguish ability of the proposed method on different FMEA items.
Discussion
Sensitivity and robustness analysis
In general, the proposed novel FMEA model makes good use of the information given by the original singleton BPA of fusion result in principle through the improved pignistic probability transformation function and further ensures the accuracy of the results by GRPM. The reliability and rationality of the proposed method are verified by two experiments in different applications. There are two variable parameters included in the proposed method including the \(\gamma \) in the improved pignistic probability transformation function and \(\xi \) in GRPM process which will be adopted for sensitivity and robustness analysis.
For testing the sensitivity and robustness of the parameter \(\xi \) in Eqs. (15) and (16) of GRPM method, the application in Experiment 1 is taken as the example where another experiment is designed and implemented to observe the ranking results of the distinguishing coefficient \(\xi \) varying from 0.1 to 1 with a step length of 0.1. With the change of \(\xi \) from 0.1 to 1 with the step length of 0.1, the corresponding values of \(RP_i\) and the ranking results of 8 failure modes in Experiment 1 are shown in Table 9. It shows that the \(RP_i\) values are different in each experiment but the ranking results of all the FMEA items stay the same, which shows the robustness of the proposed method.
For the discounting coefficient \(\gamma \) in the improved pignistic probability transformation function, in Experiment 1, we test different values of \(\gamma \) as 0, 3, 6, and 9, the corresponding ranking results with different values of \(\gamma \) in the improved FMEA model are shown in Fig. 5. The discounting coefficient \(\gamma \) has a significant effect on ranking results. Thus, we can improve the accuracy of ranking results through different strategies of the selection of \(\gamma \), which can be an open issue in the improved pignistic probability transformation function.
According to all the ranking results listed in Tables 7, 8, 9, Figs. 6, and 7, there is no duplicated ranking level for both Experiment 1 and Experiment 2 with the proposed method, which shows a good distinguish ability of the proposed method on different FMEA items. The high distinguish ability on similar failure modes can be a significant feature and superiority of the proposed method.
Complexity of the proposed method
The time complexity in the proposed method is mainly based on the scale of the risk analysis problem in practical application. Suppose that there are m failure modes, n risk factors and k team members in a risk analysis problem with FMEA model. In the process with DST theory, there are mnk pieces of BPAs, so the combination of BPAs can be finished in time O(mnk). In the process with GRPM theory, establishing comparative sequence needs O(m), determining the grey relation matrices can be done with time of O(2mn), the grey relation projections can be finished with time of O(2mn), computing the relative projection and ranking failure modes need the time of \(O(m\log _{2}m)\). In conclusion, the time complexity in the proposed FMEA model is \(O(mnk+4mn+m+m\log _{2}m)\) which is more complex than traditional FMEA theory with RPN model. Theoretically, the time complexity is cubic (mnk). It can be understand that more accurate on modeling and computing of uncertain information means more cost. It should be noted that, in FMEA, there are three risk factors and n equals to 3.
Limitation and open issue
There are limitations and open issues in the work. First, the strategy of choosing the coefficient \(\gamma \) in the improved pignistic probability transformation function is mainly based on intuition or experience. Some intelligent methods may be adopted for addressing this issue in some complex problems. Second, the time complexity of the proposed method is cubic which is higher than the classical method, which may be a potential issue while it is used in some very complex system. It may be solved with more computing resources. Third, there are many modified evidence combination rules in DST. It can be a problem while choosing a proper combination rule in different practical applications.
Conclusion
In this work, an improved pignistic probability transformation function in Dempster–Shafer evidence theory is proposed to improve the probability transformation accuracy of basic probability assignment in decision-making in the evidence theory. Based on the improved pignistic probability transformation function, an improved FMEA model using the grey relational projection method is proposed. The experts in FMEA team firstly use basic probability assignment to evaluate failure modes regarding different risk factors, then Dempster’s rule of combination is used to fuse the evaluation coming from each expert. Meanwhile, the improved pignistic probability transformation function is used to transform the fusion results of BPA into probability function for more accurate decision-making result. Finally, the grey relational projection method is adopted to calculate the risk priorities of all the failure modes. The rationality and generality of the proposed method is verified through comparative studies of FMEA in applications of aircraft turbine rotor blades and steel factory process.
Some possible further research directions can be as follows. First, a widely accepted BPA transformation strategy other than the pignistic probability transformation function is still an open issue [45, 66]. The improved pignistic probability transformation function can complete the principles of setting the discounting coefficient. The assignment of different mass function value in the frame of discernment is expected to be concretely combined with choosing the discounting coefficient to adapt complex environment efficiently. Second, uncertainty measures such as belief entropy [67,68,69] and correlation coefficient [70] can be adopted to quantify and manage the uncertainty in the process of risk analysis such as the relative importance among difference experts and risk factors. Third, the interdependencies among the FMEA items as well as the FMEA experts should be taken into consideration and can be properly modeled with the dependent evidence fusion method [71]. Fourth, approximate calculation method may be adopted to address the computation complexity of the proposed method.
Data availability
All data generated or analysed during this study are included in the article.
References
Huang J, You J-X, Liu H-C, Song M-S (2020) Failure mode and effect analysis improvement: a systematic literature review and future research agenda. Reliab Eng Syst Saf 199:106885
Liu Z, Mou X, Liu H-C, Zhang L (2021) Failure mode and effect analysis based on probabilistic linguistic preference relations and gained and lost dominance score method. IEEE Trans Cybern
Shi H, Liu Z, Liu H-C (2022) A new linguistic preference relation-based approach for failure mode and effect analysis with dynamic consensus reaching process. Inform Sci 610:977–993
Zhu J-H, Chen Z-S, Shuai B, Pedrycz W, Chin K-S, Martinez Luis (2021) Failure mode and effect analysis: a three-way decision approach. Eng Appl Artif Intell 106:104505
Rouabhia-Essalhi R, Boukrouh EH, Ghemari Y (2022) Application of failure mode effect and criticality analysis to industrial handling equipment. Int J Adv Manufact Technol 120(7–8):5269–5280
Emovon I, Norman R (2020) Risk analysis of engineering systems for sustainable industrial development using the taguchi approach. J Qual Mainten Eng 26(4):611–624
Relkar AS (2021) Risk analysis of equipment failure through failure mode and effect analysis and fault tree analysis. J Fail Anal Prevent 21(3):793–805
Kobo-Greenhut A, Sharlin O, Adler Y, Peer N, Eisenberg VH, Barbi Merav, Levy Talia, Shlomo Izhar Ben, Eyal Zimlichman (2021) Algorithmic prediction of failure modes in healthcare. Int J Qual Health Care 33(1):mzaa151
Moreira AC, Ferreira LMDF, Silva P (2021) A case study on fmea-based improvement for managing new product development risk. Int J Qual Reliab Manag 38(5):1130–1148
Chang C-H, Kontovas C, Qing Y, Yang Z (2021) Risk assessment of the operations of maritime autonomous surface ships. Reliab Eng Syst Saf 207:107324
Deulgaonkar VR, Karambelkar A, Kulkarni A, Kashid C (2021) Failure analysis of taper-lock bush used in aggregate batcher plant for construction applications. Eng Fail Anal 130:105753
Ghoushchi SJ, Garg H, Bonab SR, Rahimi A (2023) An integrated swara-codas decision-making algorithm with spherical fuzzy information for clean energy barriers evaluation. Expert Syst Appl:119884
Ghoushchi SJ, Ghiaci AM, Bonab SR, Ranjbarzadeh R (2022) Barriers to circular economy implementation in designing of sustainable medical waste management systems using a new extended decision-making and fmea models. Environ Sci Pollut Res 29(53,SI):79735–79753
Tao H, Qiu J, Chen Y, Stojanovic V, Cheng L (2023) Unsupervised cross-domain rolling bearing fault diagnosis based on time-frequency information fusion. J Franklin Inst 360(2):1454–1477
Zou F, Jiang M, Li X, Sang S, Chen W, Kang Zhijie, Zhang Haifeng (2023) Research on mechanical fault diagnosis based on mads evidence fusion theory. Measure Sci Technol 34(8):085901
Zhuang Z, Tao H, Chen Y, Stojanovic V, Paszke W (2023) An optimal iterative learning control approach for linear systems with nonuniform trial lengths under input constraints. IEEE Trans Syst Man Cybern Syst 53(6):3461–3473
Guan S, Zhuang Z, Tao H, Chen Y, Stojanovic V, Paszke W (2023) Feedback-aided pd-type iterative learning control for time-varying systems with non-uniform trial lengths. Trans Inst Measur Control 45(11):2015–2026
Zhuang Z, Tao H, Chen Y, Stojanovic V, Paszke W (2022) Iterative learning control for repetitive tasks with randomly varying trial lengths using successive projection. Int J Adapt Control Signal Process 36(5):1196–1215
**aojian X, **aobin X, Shi P, Zifa Ye Y, Bai SZ, Dustdar S, Wang G (2022) Data classification based on attribute vectorization and evidence fusion. Appl Soft Comput 121:108712
Geramian A, Shahin A, Minaei B, Antony J (2020) Enhanced fmea: an integrative approach of fuzzy logic-based fmea and collective process capability analysis. J Oper Res Soc 71(5):800–812
Huang G, **ao L, Zhang G (2021) Risk evaluation model for failure mode and effect analysis using intuitionistic fuzzy rough number approach. Soft Comput 25(6):4875–4897
Dongdong W, Tang Y (2020) An improved failure mode and effects analysis method based on uncertainty measure in the evidence theory. Qual Reliab Eng Int 36(5):1786–1807
Liu H-C, Chen X-Q, Duan C-Y, Wang Y-M (2019) Failure mode and effect analysis using multi-criteria decision making methods: a systematic literature review. Comput Ind Eng 135:881–897
Liu Z, Bi Y, Liu P (2022) An evidence theory-based large group fmea framework incorporating bounded confidence and its application in supercritical water gasification system. Appl Soft Comput 129:109580
Ghoushchi SJ, Yousefi S, Khazaeili M (2019) An extended fmea approach based on the z-moora and fuzzy bwm for prioritization of failures. Appl Soft Comput 81:105505
Gul M, Fatih Ak M (2021) A modified failure modes and effects analysis using interval-valued spherical fuzzy extension of topsis method: case study in a marble manufacturing facility. Soft Comput 25(8):6157–6178
Ilbahar E, Kahraman C, Cebi S (2022) Risk assessment of renewable energy investments: a modified failure mode and effect analysis based on prospect theory and intuitionistic fuzzy AHP. Energy 239:121907
Huang G, **ao L (2021) Failure mode and effect analysis: an interval-valued intuitionistic fuzzy cloud theory-based method. Appl Soft Comput 98:106834
Yushan H, Gou L, Deng X, Jiang W (2021) Failure mode and effect analysis using multi-linguistic terms and dempster-shafer evidence theory. Qual Reliab Eng Int 37(3):920–934
Garg A, Das S, Maiti J, Pal SK (2020) Granulized z-vikor model for failure mode and effect analysis. IEEE Trans Fuzzy Syst 30(2):297–309
Yousefi S, Valipour M, Gul M (2021) Systems failure analysis using z-number theory-based combined compromise solution and full consistency method. Appl Soft Comput 113:107902
Yucesan M, Gul M, Celik E (2021) A holistic fmea approach by fuzzy-based bayesian network and best-worst method. Complex Intell Syst 7:1547–1564
Akram M, Luqman A, Alcantud JCR (2021) Risk evaluation in failure modes and effects analysis: hybrid topsis and electre i solutions with pythagorean fuzzy information. Neural Comput Appl 33:5675–5703
Zhongyi W, Liu W, Nie W (2021) Literature review and prospect of the development and application of fmea in manufacturing industry. Int J Adv Manufact Technol 112:1409–1436
Gupta G, Ghasemian H, Janvekar AA (2021) A novel failure mode effect and criticality analysis (fmeca) using fuzzy rule-based method: a case study of industrial centrifugal pump. Eng Fail Anal 123:105305
Mohammed A, Ghaithan A, Al-Yami F (2023) An integrated fuzzy-fmea risk assessment approach for reinforced concrete structures in oil and gas industry. J Intell Fuzzy Syst 44(1):1129–1151
Liu Z, Bi Y, Liu P (2023) A conflict elimination-based model for failure mode and effect analysis: a case application in medical waste management system. Comput Ind Eng 178:109145
Tang Y, Tan S, Zhou D (2023) An improved failure mode and effects analysis method using belief Jensen–Shannon divergence and entropy measure in the evidence theory. Arab J Sci Eng 48:7163–7176
Yushan H, Gou L, Deng X, Jiang W (2021) Failure mode and effect analysis using multi-linguistic terms and dempster-shafer evidence theory. Qual Reliab Eng Int 37(3):920–934
Cao Y, Zhou ZJ, Hua CH, Tang SW, Wang J (2021) A new approximate belief rule base expert system for complex system modelling. Decis Sup Syst 150:113558
Song Y, Wang X, Zhu J, Lei L (2018) Sensor dynamic reliability evaluation based on evidence theory and intuitionistic fuzzy sets. Appl Intell 48(11):3950–3962
Smets P, Kennes R (1994) The transferable belief model. Artif Intell 66(2):191–234
Smets P (2005) Decision making in the tbm: the necessity of the pignistic transformation. Int J Approx Reason 38(2):133–147
Shijun X, Hou Y, Deng X, Chen P, Ouyang K, Zhang Ye (2021) A novel divergence measure in dempster-shafer evidence theory based on pignistic probability transform and its application in multi-sensor data fusion. Int J Distrib Sens Netw 17(7):15501477211031472
Zhu J, Wang X, Song Y (2018) A new distance between bpas based on the power-set-distribution pignistic probability function. Appl Intell 48:1506–1518
Li R, Chen Z, Li H, Tang Y (2022) A new distance-based total uncertainty measure in dempster-shafer evidence theory. Appl Intell 52(2):1209–1237
Abellan J, Bosse E (2018) Drawbacks of uncertainty measures based on the pignistic transformation. IEEE Trans Syst Man Cybern Syst 48(3):382–388
Zhang J, Ma X, Song T, Wang A, Lin Y (2023) An enhanced pignistic transformation-based fusion scheme with applications in image segmentation. IEEE Access 11:19892–19913
Zhou Q, Huang Y, Deng Y (2022) Belief evolution network-based probability transformation and fusion. Comput Ind Eng 174:108750
Huang C, Mi X, Kang B (2021) Basic probability assignment to probability distribution function based on the shapley value approach. Int J Intell Syst 36(8):4210–4236
Zhao K, Chen Z, Li L, Li J, Sun R, Yuan Gang (2023) Dpt: an importance-based decision probability transformation method for uncertain belief in evidence theory. Expert Syst Appl 213:119197
Liu X, Dawei J (2020) A novel multiple attribute decision making method based on grey relational projection and its application for e-commerce risk assessment. Int J Serv Technol Manag 26(4):305–322
Li H (2020) Application of image recognition based on grey relational analysis. Autom Control Comput Sci 54(4):371–377
Yi-Chung H, Jiang P, Chiu Y-J, Ken Y-W (2021) Incorporating grey relational analysis into grey prediction models to forecast the demand for magnesium materials. Cybern Syst 52(6):522–532
Dempster AP (1967) Upper and lower probabilities induced by a multi-valued map**. Ann Math Stat 38(2):325–339
Shafer G (1976) A mathematical theory of evidence. Princeton University Press, Princeton
Li Z, Chen L (2019) A novel evidential fmea method by integrating fuzzy belief structure and grey relational projection method. Eng Appl Artif Intell 77:136–147
Liu W (2006) Analyzing the degree of conflict among belief functions. Artif Intell 170(11):909–924
Liu H-C, Zhang L-J, ** Y-J, Wang L (2020) Failure mode and effects analysis for proactive healthcare risk evaluation: a systematic literature review. J Evaluat Clin Pract 26(4):1320–1337
Chen L, Deng Y (2018) A new failure mode and effects analysis model using dempster-shafer evidence theory and grey relational projection method. Eng Appl Artif Intell 76:13–20
Liu H-C, You J-X, Fan X-J, Lin Q-L (2014) Failure mode and effects analysis using d numbers and grey relational projection method. Expert Syst Appl 41(10):4670–4679
Yang J, Huang H-Z, He L-P, Zhu S-P, Wen D (2011) Risk evaluation in failure mode and effects analysis of aircraft turbine rotor blades using dempster-shafer evidence theory under uncertainty. Eng Fail Anal 18(8):2084–2092
Yuan Y, Tang Y (2022) Fusion of expert uncertain assessment in fmea based on the negation of basic probability assignment and evidence distance. Sci Rep 12(1):8424
Liu Y, Tang Y (2022) Managing uncertainty of expert’s assessment in fmea with the belief divergence measure. Sci Rep 12(1):6812
Tang Y, Zhou D, Chan FTS (2018) Amwrpn: ambiguity measure weighted risk priority number model for failure mode and effects analysis. IEEE Access 6:27103–27110
Chen L, Deng Y, Cheong KH (2021) Probability transformation of mass function: a weighted network method based on the ordered visibility graph. Eng Appl Artif Intell 105:104438
**ao F (2020) On the maximum entropy negation of a complex-valued distribution. IEEE Trans Fuzzy Syst 29(11):3259–3269
Tang Y, Chen Y, Zhou D (2022) Measuring uncertainty in the negation evidence for multi-source information fusion. Entropy 24(11):1596
Zhou Q, Deng Y (2022) Fractal-based belief entropy. Informat Sci 587:265–282
Tang Y, Dai G, Zhou Y, Huang Y, Zhou D (2023) Conflicting evidence fusion using a correlation coefficient-based approach in complex network. Chaos Solit Fract 176:114087
**aoyan S, Li L, Qian H, Mahadevan S, Deng Y (2019) A new rule to combine dependent bodies of evidence. Soft Comput 23(20):9793–9799
Funding
The funding has been received from National Natural Science Foundation of China with Grant no. 62301439; Natural Science Foundation of Chongqing, China with Grant no. CSTB2023NSCQ-MSX0513; NWPU Research Fund for Young Scholars with Grant no. G2022WD01010.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no potential conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tang, Y., Sun, Z., Zhou, D. et al. Failure mode and effects analysis using an improved pignistic probability transformation function and grey relational projection method. Complex Intell. Syst. 10, 2233–2247 (2024). https://doi.org/10.1007/s40747-023-01268-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01268-0