
Abstract
Most existing visual simultaneous localization and map** (SLAM) algorithms rely heavily on the static world assumption. Combined with deep learning, semantic SLAM has become a popular solution for dynamic scenes. However, most semantic SLAM methods show poor real-time performance when dealing with dynamic scenes. To handle this problem, a real-time semantic SLAM method is proposed in this paper, combining knowledge distillation and dynamic probability propagation strategy. First, to improve the execution speed, a multi-level knowledge distillation method is adopted to obtain a lightweight segmentation model, which is more suitable for continuous frames to create an independent semantic segmentation thread. This segmentation thread only accepts keyframes as input so that the system can avoid time delay caused by processing each frame. Second, a static semantic keyframe selection strategy is proposed based on the segmentation results. In this way, those keyframes containing more static information will be selected to reduce the participation of dynamic objects. By combining segmentation results and data matching algorithm, our system can realize the update and propagation of dynamic probability, reducing the influence of dynamic points in the pose optimization process. Validation results based on the KITTI and TUM datasets show that our method can effectively deal with dynamic feature points and improve running speed simultaneously.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
As a key technology for mobile robots to acquire perceptual information, SLAM is widely used in various realistic scenarios [1]. Visual SLAM uses images as input and has become a mainstream solution [2]. Since most current visual SLAM methods have a static assumption of the environment, these methods cannot effectively deal with dynamic scenarios [3]. However, the actual scene inevitably contains moving objects or objects with moving properties. With the development of deep learning (DL), semantic SLAM for dynamic scenes has been widely studied in the literature [4,5,6,7], which mainly uses DL methods to detect moving objects in highly dynamic environments. However, most existing semantic SLAM methods for dynamic scenes still suffer from real-time performance issues. The reasons can be listed as follows:
Firstly, most semantic SLAM methods use object detection or semantic segmentation models to generate semantic information. However, most DL models used in the existing semantic SLAM methods require high memory consumption and computational cost. For example, the Mask R-CNN model [8] used in DynaSLAM [4] and OFM-SLAM [5], the Deeplab-V2 model [9] used in USS-SLAM [6], and the PSPNet-50 model [10] used in PSPNet-SLAM [7]. Some semantic SLAM methods [11,12,13] choose lightweight DL models, such as the SegNet model [14]. However, the accuracy of semantic segmentation cannot be guaranteed in such lightweight models. To solve this problem, we propose to use a novel multi-level knowledge distillation method to train a lightweight semantic segmentation model, which can greatly improve inference speed while ensuring the segmentation accuracy.
Second, the segmentation strategy of existing semantic SLAM methods is also a major factor hindering the real-time performance of the whole system. When dealing with dynamic scenes, conventional semantic SLAM methods distinguish feature points according to the inference results of the segmentation model, and then static feature points are utilized for pose estimation. If each image is segmented, feature points in all input images will be more accurately distinguished, eventually reducing the localization error. Most classical semantic SLAM methods, such as DynaSLAM [4], DS-SLAM [11], and DM-SLAM [15], produce the semantic result for each frame individually. However, such segmentation strategy has the problem of redundant operation. The inputs of visual SLAM are continuous frames. Considering that continuous images have a certain spatio-temporal consistency, these segmentation results have many similarities, so it is unnecessary to segment each frame. Since the running time of the feature extraction is much less than that of semantic segmentation, producing segmentation results for each frame will inevitably make the tracking thread be blocked to wait for the results of the semantic segmentation model. To address this problem, only the keyframes are segmented in this paper. Since the keyframes have a certain spatio-temporal consistency with their adjacent frames, the segmentation results of keyframes are transferred to their adjacent frames, which can significantly avoid the time delay caused by segmenting each frame.
Third, the predicted segmentation results on blurred and rotated images can hardly be guaranteed to be accurate enough. To solve this problem, the multi-view geometry [16] and optical flow [17, 18] methods are often introduced to jointly distinguish dynamic outliers. Multi-view geometry finds outliers by calculating projection errors of feature points on different frames. Optical flow calculates pixel motion relation of adjacent images and determines outlier feature points by motion consistency. However, these methods usually require expensive computing costs, which affect the running speed of the visual SLAM system and are not conducive to the deployment of mobile devices. To effectively distinguish dynamic points and avoid expensive time consumption, we only use the semantic segmentation model to assign initial dynamic probabilities to the feature points. The dynamic probabilities of feature points in non-keyframes are updated using the data matching algorithm [19]. With the help of dynamic probabilities, multiple segmentation results can be combined to avoid probably wrong segmentation results produced on a single frame to a certain extent.
Fourthly, general semantic SLAM methods only focus on how to screen out dynamic feature points effectively and do not improve the pose optimization process. Most semantic SLAM methods treat all feature points equally important in the pose optimization process, ignoring the motion information of these features. In this paper, the dynamic probability is introduced in pose optimization to reduce the influence of feature points with high-dynamic probability on optimization results.
Aiming at the problems mentioned above, we propose a real-time semantic SLAM approach based on knowledge distillation and dynamic probabilistic propagation. The main contributions of this paper are as follows:
-
(1)
A lightweight segmentation model trained based on multi-level knowledge distillation is deployed in our SLAM system to improve image segmentation speed while ensuring segmentation accuracy.
-
(2)
Dynamic probability is utilized to distinguish the attributes of feature points. The update and propagation of dynamic probability are realized using semantic segmentation results of keyframes and the data matching algorithm.
-
(3)
We propose a static semantic key frame selection method, which aims to reduce the proportion of dynamic map points and can increase the static information.
-
(4)
Dynamic probability is introduced into the pose optimization process to reduce the influence of map points with high-dynamic probability.
The rest of this paper is structured as follows: Sect. “Related work” describes the related work in knowledge distillation for semantic segmentation and semantic SLAM for dynamic scenes Sect. “Method” discusses the proposed method in detail Sect. “Experimental results” evaluates the effectiveness of the proposed method Sect. “Conclusion” concludes this paper and presents the future research directions.
Related work
Knowledge distillation for semantic segmentation
As the pioneering work in the field of knowledge distillation, the method proposed by Hinton et al. [25] employed the optical flow method to fuse the segmentation results of adjacent frames to improve the segmentation accuracy. Zhu et al. [26] used the motion estimation network to transfer semantic labels of pixels to other frames. It was regarded as a data enhancement to improve the accuracy of the segmentation model on continuous frames. These methods use optical flow or motion estimation to establish the connection between adjacent frames, which require vast computing resources, so they are obviously not suitable for practical application. In addition, existing methods do not take the dependency between continuous images into account when designing the distillation scheme. In this paper, based on the prediction results of continuous frames, we encode the dependency among adjacent frames by calculating their similarity. By distilling this dependency, we can transfer the implicit knowledge in continuous images to the student model.
Considering the diversity of knowledge in the teacher model, we propose a multi-level knowledge distillation method. In this method, knowledge from the teacher is divided into high, middle, and low levels for distillation, so that the student model can learn more comprehensive and abundant knowledge in continuous images.
Semantic SLAM for dynamic scenes
With the rapid development of DL, some scholars combine the related methods of deep learning with visual SLAM to deal with dynamic scenes. Based on ORB-SLAM2 [27], Bescos et al. [4] proposed DynaSLAM, which can recognize dynamic objects and repair static backgrounds. For pose estimation in dynamic scenes, DynaSLAM firstly utilized Mask R-CNN [8] to segment prior dynamic objects, and then used multi-view geometry to filter out the remaining outlier dynamic feature points. Like DynaSLAM, DM-SLAM [15] also used Mask R-CNN [8] to obtain semantic information in dynamic scenarios. In addition, when detecting dynamic feature points, DM-SLAM also combines geometric methods such as pole line constraint and feature point reprojection to further detect dynamic points. Although such detection strategies can effectively distinguish dynamic and static feature points, they fail to consider the real-time performance of the SLAM system, so they are not suitable for practical application. Ai et al. [28] proposed DDL-SLAM, a dynamic semantic SLAM suitable for RGB-D mode, which can deal with localization and background repair in dynamic scenes. DDL-SLAM uses the semantic segmentation model, DUNet [29], and multi-view geometry to jointly distinguish dynamic objects. Compared with the original ORB-SLAM2, the final localization accuracy is improved. However, DUNet is a segmentation model designed for medical images, which is not applicable to the real environment. In addition, DDL-SLAM and DynaSLAM use multi-view geometry to further eliminate dynamic features, significantly hindering real-time performance. Yu et al. [11] proposed a real-time semantic SLAM method DS-SLAM, which combines the SegNet model [14] with a motion consistency algorithm to reduce the influence of dynamic objects. Different from DynaSLAM, DS-SLAM treats feature points on the stationary person as static and involves those matching points in camera pose estimation. It is noted that DS-SLAM works better in high-dynamic scenes and runs faster than DynaSLAM. Motivated by DS-SLAM, FD-SLAM [13] combines multi-thread processing with a lightweight segmentation model to effectively handle dynamic objects and improve overall speed simultaneously. In order to effectively eliminate dynamic feature points, FD-SLAM uses depth images and semantic images to generate segmentation masks according to the depth of feature points. Although FD-SLAM has improved the real-time performance, the frame-by-frame segmentation strategy still limits the overall speed. To improve the running speed, Chen et al. proposed RDS-SLAM [30], which only uses the lightweight SSD object detection model [31] to choose dynamic points without any geometric method. Utilizing the conversion between 2D coordinate and 3D coordinate in the ORB-SLAM2 system, RDS-SLAM can predict dynamic points on each frame. Different from those methods that eliminate all feature points in the region of dynamic objects, Zhong et al. [32] proposed Detect-SLAM, which divides all feature points into four states according to motion probability, i.e., high confidence static, low confidence static, high confidence dynamic and low confidence dynamic. As the processing time of the detection model is more than that of feature point extraction, and considering that continuous frames have certain spatio-temporal consistency, Detect-SLAM only applies object detection model SSD to keyframes. The states of feature points in the local map are updated by probability propagation, and the selected static points are then used for pose estimation.
Semantic SLAM methods for dynamic scenes can eliminate the influence of moving objects to a certain extent, but they still suffer from the real-time issues. To alleviate this problem, a real-time semantic SLAM method is proposed in this paper, combining knowledge distillation and dynamic probability propagation strategy.
Methods
General framework
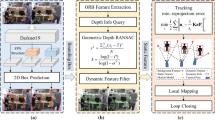
Figure 1 presents the overall framework of the proposed method, where ORB-SLAM3 [19] is adopted as the backbone. We modify the original tracking thread and local map** thread in ORB-SLAM3. In addition, we create a separate semantic segmentation thread. This framework is summarized next.

General framework of the method
Atlas
Atlas [33] is a multiple-map system. The Atlas manages two different types of maps: active maps and non-active maps. The tracking thread is responsible for localizing the incoming images in the active map. The active map is also continuously optimized and expanded with new keyframes by the local map** thread. The active map is transformed into a non-active map when the tracking failure occurs and relocalization is not successful for a few images. Then, a new active map will be initialized.
Tracking thread
Tracking thread processes incoming images and estimates the pose of the current frame in real time, minimizing the reprojection error of the matched feature points. In this paper, we exclude dynamic feature points from tracking using the computed dynamic probability by the semantic segmentation thread. The tracking thread is also responsible for determining whether the current frame becomes a keyframe.
Keyframe
Keyframes are selected to reduce unnecessary redundancy in tracking and optimization. In this paper, each keyframe stores (1) estimated camera pose that transforms points from the world to the camera coordinate system; (2) extracted ORB feature points; (3) the dynamic probability of each feature point.
Semantic segmentation thread
The keyframes will be exported to the semantic segmentation thread to further determine whether they are static semantic keyframes according to their segmentation results. The selected static semantic keyframes contain more static information, which can provide more static map points for the SLAM system and reduce the proportion of dynamic points. In order to improve the running speed of the whole system, we take a lightweight semantic segmentation model. In addition, we use the segmentation result of the last keyframe and the data matching algorithm of ORB-SLAM3 to transmit corresponding dynamic probabilities to the current frame, and then complete the screening of dynamic feature points.
Local map** thread
Local map** thread adds keyframes and map points to the active map. The camera pose is optimized by the local bundle adjustment (BA), which is performed in a local window of keyframes close to the current frame.
Loop closing and full BA
Loop closing detects common regions between the active map and the whole Atlas. If the common area belongs to the active map, it performs loop correction. Loop correction launches an independent thread to perform full BA to optimize the camera poses and the corresponding map points jointly.
Lightweight semantic segmentation model
In this subsection, we introduce the multi-level knowledge distillation to train a lightweight semantic segmentation model to shorten the processing time of the semantic segmentation model in semantic SLAM. Knowledge distillation is a widely used model compression method to improve the generalization performance of lightweight models. Recently, Liu et al. [34] proposed temporal consistency knowledge distillation for the semantic video segmentation task. The purpose of temporal consistency distillation is to pass the dependencies between successive frames from the teacher model to the student model. Inspired by this work, we propose a multi-level knowledge distillation scheme and semantic consistency loss for semantic segmentation of continuous images, aiming at enabling the student model to learn more comprehensive representation knowledge from the teacher model. As shown in Fig. 2a, in the training process, two adjacent frames \(I_{t}\) and \(I_{t + 1}\) are used as input. We introduce three levels of knowledge distillation: feature distillation, spatial structure distillation, and dependency distillation, which correspond to activations in intermediate feature layers, multi-scale fusion feature maps, and model predictions, respectively. All the proposed methods are only used during training. As shown in Fig. 2b, we can improve the segmentation accuracy of our student network without any extra parameters or post-processing during inference. We can realize per-frame inference in the testing process.

a Overall proposed training scheme with multi-level knowledge distillation. b The inference process
In this paper, we use the proposed multi-level knowledge distillation method to a compact semantic segmentation model with per-frame inference. The widely used segmentation architecture PSPNet [10] with a ResNet101, namely PSPNet101, is used as the teacher network. We adopt the lightweight ResNet18 with the architecture of PSPNet, namely PSPNet18, as the student network. The network architecture of PSPNet18 is shown in Fig. 3. PSPNet18 is an end-to-end lightweight network, which takes an image as the input and outputs its final prediction result. Given an input image, we first use ResNet18 to get the feature map of the last convolutional layer. Then, a pyramid pooling module [10] is used to capture global context information with different pyramid scales, followed by a concatenation operation to obtain the final feature representation. Finally, a convolution layer is used to get the final prediction result from the feature representation.

The network architecture of PSPNet18
Then, we will describe each distillation loss of the proposed multi-level knowledge distillation method and the semantic consistency loss in detail as follows.
Intermediate feature distillation
In order to improve the feature extraction ability of the student model, we treat the intermediate feature of the teacher model as low-level knowledge and distill them to the student model. Since the activation function, ReLU [35] only retains positive neurons and all negative neurons are assigned a value of 0. Therefore, vast information is lost in intermediate feature layers. During intermediate feature distillation, we select batch normalized activations before ReLU function as the target of distillation, and add a 1 × 1 convolution layer to transform the dimensions of intermediate features of student model for distillation. Figure 4 shows the process of intermediate feature distillation.

The process of intermediate feature distillation
For feature maps \(F_{t}^{i}\) and \(F_{s}^{i}\), which are extracted from the ith convolution layer in the teacher model and the student model, respectively, we retain all positive activations in channels. For negative activations in each channel, we first calculate their average value \(\alpha\), then all activations less than average value in the channel are assigned as \(\alpha\). The calculation of intermediate feature distillation loss is defined as Eq. (1), where \(T_{i}\) and \(S_{i}\) are, respectively, defined as feature maps of the teacher model and the student model at the ith convolution layer after dimension transformation, and K is the number of intermediate feature layers:
Structural knowledge distillation
Semantic segmentation model not only needs to learn how to assign the correct label to each pixel, but also needs to consider the spatial structure of the input image from the perspective of global information. Generally speaking, the final feature map of deep neural network can represent the general features of training data. In the multi-level knowledge distillation method, we regard multi-scale feature map fused by pyramidal pooling modules as middle-level knowledge. On this basis, the structure information of input image is encoded into affinity graph. Then, structural knowledge distillation can be achieved by aligning the affinity graphs generated by the teacher model and the student model, respectively. The distillation process is shown in Fig. 5.

The process of structural knowledge distillation
\(F_{T}\) and \(F_{S}\) are used to represent the final feature maps of the teacher model and the student model, respectively. After average pooling, their feature maps were denoted as \(F_{T}^{\prime }\) and \(F_{S}^{\prime }\). In this method, cosine similarity is used to measure the similarity relationship between two pixels in feature map. The structural knowledge of input image can be represented by calculating the similarity relationship between all pixels. Taking the ith and jth pixel points \(f_{i}\) and \(f_{j}\) for example, cosine similarity calculation is shown in Eq. (2), where \(m_{ij}\) represents a pixel point in the generated affinity graph \(M\):
After calculation, \(M^{t}\) and \(M^{s}\) are defined as the affinity graphs generated by the teacher model and the student model, respectively, and the pixels in corresponding affinity graphs are marked as \(m_{ij}^{t}\) and \(m_{ij}^{s}\). The calculation of structural knowledge distillation loss is shown in Eq. (3), where N represents the dimension of flattened feature map:
Dependency distillation
In practice, the input of the segmentation model can be regarded as continuous image sequences. There are dependencies between adjacent frames in sequence, so we hope that the student model can learn this implicit relationship. Inspired by temporal consistency knowledge distillation, we regard the prediction of the teacher model as high-level knowledge. On this basis, we encode the dependencies of adjacent frames as similarity graphs. Then the knowledge transfer can be accomplished by making student model imitate the similarity graph generated by teacher model. We continue to use cosine similarity to measure the relationship between adjacent frames. For adjacent frames \(I_{t}\) and \(I_{t + 1}\), the segmentation results of the teacher model and the student model are represented as \(T_{t}\), \(T_{t + 1}\), \(S_{t}\), \(S_{t + 1}\), respectively. According to Eq. (4), we can calculate dependency distillation loss, where function \(sim( \cdot , \cdot )\) is used to represent the similarity of adjacent frames and Q is the number of images in sequence:
Semantic consistency loss
When the semantic segmentation model trained by single-frame images is used to test continuous images, the pixels in the same position between adjacent frames may have inconsistent prediction labels. Except for those pixels whose semantic labels change inevitably due to inter-frame motion, inconsistent semantic labels on other pixels are caused by incorrect prediction results. Therefore, we propose semantic consistency loss to ensure the invariance of semantic labels of pixels on adjacent frames.
We regard the segmentation results of the teacher model as pseudo-labels. For image sequence with length L, the prediction results of the student model at a certain pixel position in frame t and frame t + 1 are defined as \(P_{ij}^{t}\) and \(P_{ij}^{t + 1}\), and the corresponding prediction results of the teacher model are \(T_{ij}^{t}\) and \(T_{ij}^{t + 1}\). According to the prediction of the teacher model, the number of pixels satisfying semantic consistency between adjacent frames can be expressed as follows:
where the function \(\varphi ( \cdot , \cdot )\) is expressed as follows:
Based on Eq. (5), the number of pixels meeting inconsistent semantic labels in the results of student model is expressed as Eq. (7):
where the function \(\delta ( \cdot , \cdot )\) is expressed as follows:
Finally, semantic consistency loss is defined as follows:
Based on the above distillation loss and semantic consistency loss, we can finally train a lightweight semantic segmentation model. In addition to ensuring the segmentation accuracy, the inference speed of the student model is greatly improved. Consequently, it will improve the real-time performance of semantic SLAM.
Semantic segmentation thread
In order to alleviate the time delay caused by waiting for the semantic segmentation results during tracking, we create a separate semantic segmentation thread. It runs in parallel with the tracking thread and the local map** thread, and only accepts keyframes as input. This design avoids the segmentation of each image, which shortens the running time of the whole system.
From the perspective of efficiency, to reduce the time spent on image segmentation, we deploy the lightweight model PSPNet18 in our SLAM system, which is trained based on the multi-level knowledge distillation method. PSPNet18 will be employed to segment prior dynamic objects, such as people and vehicles. Then, according to the segmentation result of the current keyframe, we propose a static semantic keyframe selection algorithm, which is used to insert keyframes containing more static information. If the current frame is judged as a static semantic keyframe, we will further generate a binary mask according to its segmentation result. Combining binary mask and ORB feature point extraction results, we can further realize the dynamic probability update and propagation of feature points. In the following subsections, we will introduce the components of the semantic segmentation thread in detail.
Static semantic keyframe selection
Considering the information redundancy between adjacent images, the keyframe mechanism is adopted to avoid using all frames, which can greatly reduce the consumption of computing resources. When dealing with dynamic scenes, to generate more static map points, we propose a static semantic keyframe selection algorithm according to the segmentation result of keyframe. This will reduce the impact of dynamic map points and improve the accuracy of pose optimization.
Assuming that \(I_{t}\) is the keyframe selected by ORB-SLAM3 at time t, and \(I_{i,j}\) is the pixel of position \((i,j)\) in keyframe \(I_{t}\). \(S_{static}\) and \(S_{dynamic}\) are defined to represent the static and dynamic semantic scores. When keyframe \(I_{t}\) is generated, it will be conveyed to the semantic segmentation thread and then its segmentation result will be obtained. Each pixel is assigned static and dynamic semantic score according to the semantic segmentation results. If the semantic label of \(I_{i,j}\) belongs to objects such as people and vehicles, the corresponding dynamic semantic score \(S_{dynamic} \left( {i,j} \right)\) will be set to 1, or it will be set to 0, because these objects are in moving states. If the semantic label of \(I_{i,j}\) belongs to some movable objects such as vegetation, cup and chair, the corresponding static semantic score \(S_{static} \left( {i,j} \right)\) will be set to 0.8. If the semantic label of \(I_{i,j}\) belongs to some objects such as building, traffic sign, table, and monitor, the corresponding static semantic score \(S_{static} \left( {i,j} \right)\) will be set to 1, because these objects are unlikely to be moved during the SLAM process.
Then according to the accumulated static semantic score and dynamic semantic score, the score of the current keyframe can be calculated by Eq. (10). If the score is greater than threshold \(\sigma\), the current keyframe is determined to be a static semantic keyframe. Then, it will be inserted into keyframe sequence of the SLAM system to serve the subsequent workflow:
Mask generation
Considering that the semantic segmentation model is usually sensitive to object boundary, sometimes the segmentation of target boundary is not accurate enough. Consequently, when we judge the properties of feature points, these dynamic feature points on the object boundary may be omitted if we directly use binary masks generated by segmentation model. Therefore, we dilate the boundary of binary masks appropriately. Figure 6 shows the original segmentation masks of the PSPNet18 model and the dilated results. As we can see from Fig. 6, the lightweight model PSPNet18 can accurately segment target objects, such as cars on the street and people sitting in the indoor scene. Moreover, the dilation of segmentation masks can expand the region of prior dynamic objects and provide more accurate discrimination for subsequent work.

Original masks and dilated masks generated by PSPNet18
Dynamic probability initialization
In complex environments, the segmentation results cannot always be accurate. If we directly distinguish dynamic feature points according to the segmentation masks, the feature points that originally belong to dynamic objects may be misclassified as static points. This will reduce the accuracy of the pose estimation.
To deal with the above problems, we assign initial dynamic probability 0.5 to the extracted feature points and their corresponding map points. Then, the dynamic probabilities of map points are updated by segmentation results of different keyframes. When the dynamic probability of feature point or map point is closer to 1, it indicates that the point has more dynamic property. We set some dynamic probability thresholds and divide the states of map points and feature points into four types: high confidence dynamic, low confidence dynamic, high confidence static and low confidence static, which is shown in Fig. 7.

Definition of dynamic properties
Dynamic probability update
Considering the limitation of the semantic segmentation model in complex environments, we do not distinguish dynamic and static points directly according to the segmentation result of current frame. Instead, the dynamic probabilities of map points will be constantly updated by integrating static semantic keyframes from multiple perspectives. The dynamic probability update process of map points is shown in Fig. 8.

The process of dynamic probability update
Assume that the static semantic keyframe selected at current moment is \(I_{t}\), and the last reference static semantic keyframe is marked \(I_{t - 1}\). \(M_{i}\) is the 3D map point in Atlas that meets matching relationship with \(I_{t}\) and \(I_{t - 1}\). The dynamic probability of \(M_{i}\) updated at time t-1 is expressed as \(P_{t - 1} (M_{i} )\). According to the segmentation mask of \(I_{t}\) at time t, the dynamic probability of \(M_{i}\) can be expressed as \(X_{t} (M_{i} )\). If 2D projection point of \(M_{i}\) on \(I_{t}\) falls within the mask region, \(M_{i}\) will be preliminarily judged as dynamic, and then \(X_{t} (M_{i} )\) is assigned to 1, otherwise 0. After updating at time t, the dynamic probability of \(M_{i}\) can be expressed as \(P_{t} (M_{i} )\). The dynamic probability update method can be expressed as follows:
The parameter \(\lambda\) is used to balance the dynamic probability of the previous moment and the observed value of the current moment. When \(\lambda\) becomes larger, it indicates that updated dynamic probability is more dependent on the observed value. On the contrary, if \(\lambda\) gets smaller, the state at previous moment has a greater influence on the dynamic probability at current moment. In this paper, we set \(\lambda\) to be 0.4.
Modified tracking thread
In the front-end tracking thread, we rely on dynamic probabilities of feature points to distinguish dynamic points from static points. The tracking thread is used to estimate the initial camera pose by matching the feature points between the previous frame and the current frame. To reduce the influence of dynamic objects, only static feature points are used in the initial camera pose estimation stage in the tracking thread. We use the data matching algorithm of ORB-SLAM3 to transmit the dynamic probabilities of feature points in the last frame and map points stored in Atlas to the current frame. The propagation of dynamic probability is realized in two ways, which is shown in Fig. 9.

Propagation of dynamic probability
First, taking advantage of the 2D-2D data association of ORB-SLAM3, we can obtain feature points matched on different frames. Therefore, the dynamic probabilities of feature points on the previous frame can be propagated to the current frame. In the second place, the ORB-SLAM3 system can project some feature points into 3D space and save them as map points in Atlas during tracking, so there is also a matching relationship between 2D feature points and 3D map points. Through 3D-2D data association, the dynamic probabilities of updated map points can be transferred to feature points of the current frame to prepare for further static point screening. As the current frame completes the update and propagation of dynamic probabilities, the dynamic probabilities of feature points and their matching map points in the current frame have been determined. Then, according to the dynamic probability threshold, static feature points could be selected and used for pose estimation in the next step. Algorithm 1 shows the screening process of static points.

We take some images as examples to visually display the transmission of dynamic probabilities of feature points during tracking, as shown in Fig. 10. Among them, green points represent the feature point with initial dynamic probability, blue point represent the static points with dynamic probability less than \(\beta\), and red point represents the dynamic feature points with dynamic probability over \(\alpha\).

Propagation of dynamic probabilities during tracking
Local map** thread
In tracking thread, our SLAM system completes initial estimation of camera pose according to the selected static feature points. Meanwhile, the local map** thread can create map points based on the static semantic keyframes. Afterwards, the local BA will utilize 3D map points to optimize estimated camera pose. As a nonlinear optimization method, BA optimization minimizes reprojection error to obtain optimal camera pose. The schematic diagram of reprojection error is shown in Fig. 11. In Fig. 11, pi is the ith feature point in Frame1; qi is the corresponding estimated feature point in Frame2; \(q_{i}^{\prime }\) represents the projection point of the map point \(M_{i}\) in Frame2.

Schematic diagram of reprojection error
To reduce the influence of points with high-dynamic probabilities on pose optimization, we combine the dynamic probabilities of map points with BA optimization. For map points whose probability exceeds the dynamic threshold, we will prevent them from participating in the BA optimization. While for map points whose probability is lower than the static threshold, we will use the BA optimization method for pose optimization. Finally, for the remaining map points, we use their dynamic probabilities to calculate the weighted reprojection errors. The weight of reprojection error can be calculated by Eq. (12), where \(P(M_{i} )\) is the dynamic probability of map point \(M_{i}\):
Assuming that the coordinate of a 3D map point is expressed as \(M_{i} = \left[ {X_{i} ,Y_{i} ,Z_{i} } \right]^{T}\), and its projection point in Frame2 is marked as \(q_{i}^{\prime } = \left[ {u_{i} ,v_{i} } \right]^{T}\). According to camera internal parameter K and camera pose \(\xi\), the weighted reprojection error can be constructed using Eq. (13), where \(\eta\) is the weight coefficient corresponding to the 3D map point \(M_{i}\):
Experimental results
System setup
To evaluate the tracking accuracy and running speed of our SLAM system in dynamic scenes, a series of experiments are performed on several sequences of the public datasets: TUM [36] and KITTI [37]. Table 1 lists each image sequence with a thorough explanation. Regarding the KITTI dataset, the images are obtained via a camera mounted on a moving car. All sequences of the KITTI dataset are captured from the rural, urban, highway and street scenes, containing many dynamic vehicles and pedestrians. Based on each sequence of the KITTI dataset, we will evaluate the tracking accuracy of our SLAM system in monocular and stereo modes. The TUM dataset is collected by Kinect in different indoor scenes. It contains 39 sequences, which are suitable for a variety of visual tasks such as hand-held SLAM, robotic SLAM, dynamic environment, and 3D reconstruction. Among them, 5 sequences are used for the experiments in this paper to evaluate our SLAM system in RGB-D mode. The resolution of each image is 640 × 480 and the frame rate is 30 Hz. The validations on the public datasets are carried out on a device equipped with Intel Core I9-10900X CPU and GeForce RTX 3090 GPU.
Parameter setting
The main parameters of our SLAM system are listed in Table 2.
We conduct experiments to determine the best parameters. We change only one parameter while the other values are fixed as listed in Table 2 in each experiment. For the threshold \(\sigma\), we vary its values in the interval [2, 4] with step of 1. Then, the RMSE of the Absolute Pose Error (APE) and the number of keyframes with different \(\sigma\) on three sequences of the KITTI dataset are shown in Table 3. It can be observed that the localization accuracy can be slightly improved as the threshold \(\sigma\) increases in scenes dominated by static objects and a small number of moving objects, such as Seq. 02 and 03. However, in highly dynamic scenes, a higher threshold \(\sigma\) will lead to a decrease in the number of keyframes, which will reduce the localization accuracy to some extent. Therefore, a reasonable value of threshold \(\sigma\) is 3.
In the case of dynamic probability threshold \(\alpha\) and static probability threshold \(\beta\), Table 4 presents their impacts on the localization accuracy. When the dynamic probability threshold \(\alpha\) becomes larger, more dynamic feature points participate in the BA optimization process, which will lead to a decrease in the localization accuracy. When the static probability threshold \(\beta\) is too large, more low confidence points are regarded as static points, which also reduce the localization accuracy. As a result, we set the dynamic probability threshold \(\alpha\) and the static probability threshold \(\beta\) to be 0.75 and 0.25, respectively.
Evaluation of lightweight semantic segmentation model
In this section, we compared our lightweight semantic segmentation model with some mainstream lightweight models, such as DSRL [38], ShuffleNetV2-ASC [39], CGNet-M3N21 [40], ICNet [41], ESPNet [42], and Mobilenetv2-(CSC + ACE) [24], on the Cityscapes dataset [43] in terms of the model parameters (#Param) and mean Intersection over Union (mIoU) for semantic segmentation. The results can be shown in Table 5, where ‘–’ means the value can not be found in the corresponding paper. Compared with other methods, ESPNet has obvious advantages in terms of the model parameters. However, the accuracy of ESPNet is relatively worse. Table 5 shows the proposed lightweight semantic segmentation model can achieve a better balance between the accuracy and the model parameters.
Moreover, to verify the effectiveness of the proposed multi-level knowledge distillation training method, we have compared it with different knowledge distillation methods, such as IFVD [44], SKDD [45], and CWD [46]. It can be shown in Table 6 that the improvement of the semantic segmentation accuracy of the student model is the most obvious using the proposed multi-level knowledge distillation method. We use the student network to perform per-frame inference, which does not increase any parameters or extra computational costs. All the distillation losses can be seen as extra constraints, which can better help the training process. Such constraints contribute to learning extra knowledge from the pre-trained teacher net.
Evaluation of localization accuracy
When dealing with dynamic scenes, our SLAM system is not limited to a particular camera mode, so this proposed method is general. In order to demonstrate the effectiveness of the proposed system, we will analyze and verify the tracking accuracy of the SLAM system in monocular, RGB-D, and stereo modes.
Monocular
In monocular mode, APE and Relative Pose Error (RPE) of keyframe trajectory were used to compare the tracking accuracy of different methods. RPE contains relative translation error and relative rotation error. To make a fair comparison, we use RMSE, Mean, and Std as evaluation indicators. We select ten sequences (00,02-10) from the KITTI dataset for testing. Each sequence is tested five times. Then, on the basis of APE, we compare our method with ORB-SLAM3 and the recent semantic SLAM methods Dyn-ORB-SLAM [47] and Dynamic-SLAM [48]. As shown in Table 7, our system achieves higher tracking accuracy on some sequences. Due to the few images in KITTI 04 sequence, the final number of selected keyframes in 04 sequence is also small. However, our system mainly relies on the segmentation results of keyframes to transmit dynamic probability. Therefore, the update times of dynamic probability in 04 sequence are not enough, resulting in a less obvious improvement of APE in this sequence. In sequences 03, 08, 09 and 10, vehicles on both sides of roads are mostly static. When PSPNet18 segment objects such as people and cars in images, the feature points on these objects would be updated as dynamic by our SLAM system. Since these vehicles are stationary during tracking, feature points in these areas are indeed beneficial to pose estimation. However, after the dynamic probabilities of feature points are updated, our SLAM system does not allow these feature points to participate in pose estimation, which indirectly reduces the number of static points. Therefore, it influences the pose estimation between frames and leads to relatively large errors in these KITTI sequences.
Figures 12, 13, 14, 15, 16, 17, 18, 19, 20, and 21 present the APE comparison results of our method and Dyn-ORB-SLAM. The left side of each subgraph from Figs. 12, 13, 14, 15, 16, 17, 18, 19, 20, and 21 represents the APE results of our method, and the right side represents the results of Dyn-ORB-SLAM. From these figures, the variation of APE at different times can be seen intuitively. In general, except for sequences 03, 08, 09, and 10, we can find that the APE of our method is significantly smaller than Dyn-ORB-SLAM.

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 00

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 02

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 03

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 04

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 05

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 06

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 07

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 08

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 09

The comparison of APE w.r.t translation part (m) between our method (left) and Dyn-ORB-SLAM (right) on sequence 10
In addition, in order to compare RPE with Dyn-ORB-SLAM and ORB-SLAM3, we also conduct evaluations based on KITTI sequences. Tables 8 and 9 display the comparison results, which correspond to the translational and rotational parts of RPE, respectively. RPE is used to compare the increment of pose, which can reflect local accuracy and is suitable for estimating the drift of the SLAM system. In this experiment, we mainly consider each frame’s translation amount and rotation angle.
It can be seen from Table 8 that the translation errors of our method are significantly smaller than that of Dyn-ORB-SLAM in sequences 02, 06, and 08, but slightly less than that of Dyn-ORB-SLAM in sequences 09 and 10. Table 9 reflects the RPE for rotation part. It can be seen that although our method only has advantages in some sequences, the results in rest sequences are not much different from Dyn-ORB-SLAM.
Figure 22 shows the trajectories and APE projections of ORB-SLAM3, Dyn-ORB-SLAM, and our method on four representative sequences of the KITTI dataset. It shows that our SLAM system can roughly predict trajectories that are much closer to the real global trajectories. Our method pays more attention to static feature points, thereby making the pose estimation closer to the true value.

The comparison of trajectories and APE projections between ORB-SLAM3, Dyn-ORB-SLAM, and our method. In each figure, solid lines are the estimated global trajectories, and the dotted lines represent real trajectories of KITTI sequences. From left to right: results of ORB-SLAM3, Dyn-ORB-SLAM, and our method. From top to bottom: results on sequences 02, 05, 07, and 08 of the KITTI dataset
Furthermore, in order to verify the effectiveness of static semantic keyframe selection, we compare APE results before and after using static semantic keyframes based on KITTI sequences. Results are shown in Table 10. It can be seen that with the selected static semantic keyframes, the localization accuracy of our SLAM system has been further improved on most sequences. The final mean error indicates that the APE of the SLAM system using static semantic keyframe is the lowest, which proves that static semantic keyframes can reduce the influence of dynamic objects on localization accuracy.
RGB-D
We also validate our method based on the TUM dataset in RGB-D mode. In this case, Absolute Trajectory Error (ATE) is used as the measurement indicator. Table 11 shows the ATE comparison results with ORB-SLAM3, DS-SLAM, Dyn-ORB-SLAM, DynaSLAM, Zhang et al. [49], and DOS-SLAM [50]. Overall, our method has satisfying performance on all sequences of the TUM dataset. The reason why DynaSLAM is slightly more accurate is that it specifically applies extra geometric constraints to further detect more dynamic objects in RGB-D mode. Albeit our results are marginally worse than DynaSLAM, it succeeds in bootstrap** the runtime of SLAM system with lightweight semantic segmentation model. In DynaSLAM, Mask-R-CNN [51] has been applied to detect dynamic objects. However, Mask-R-CNN cannot be in real time.
As shown in Table 11, compared with ORB-SLAM3, the localization accuracy of our method in dynamic scenarios has significantly improved by 38.3–90.9%. DynaSLAM relies on Mask R-CNN and multi-view geometry constraints to effectively eliminate dynamic feature points, which achieves high accuracy in dynamic scenarios. Although our method is less accurate than DynaSLAM, the results are not significantly different on some sequences. Compared with the real-time semantic SLAM method Dyn-ORB-SLAM, our system has lower ATE in high-dynamic sequences such as walk-rpy, walk-halfsphere, and walk-xyz. After classifying feature points with the object detection model, Dyn-ORB-SLAM eliminates dynamic points by combining data matching between the current frame and reference frame. However, our method not only uses dynamic probabilities to screen feature points, but also combines the probabilities of map points in BA optimization, which makes the pose estimation result more accurate.
Stereo
In order to verify the performance of our SLAM system in stereo mode based on KITTI sequences, ORB-SLAM3 and Dyn-ORB-SLAM have been reconstructed to establish comparison experiments. Moreover, we directly report the results of DM-SLAM according to the corresponding paper. As before, we still use APE to measure the error of camera pose. Table 12 presents the comparison results. Different from monocular mode, stereo camera relies on the left and right view to estimate the scene depth, so it has better performance in camera pose estimation. According to Table 12, our method performs the best on almost all sequences. When compared with the original ORB-SLAM3, the APE of our method decreased on all sequences from 4.38 to 24.25%. It can be seen that our method is superior to DM-SLAM except that it is slightly inferior to DM-SLAM in sequence 10. Our method does not use static feature points on static vehicles in tracking, which may drag down the system performance. Therefore, except for sequences 00, 04, and 10, the performance of our SLAM system is better than other methods. These results also prove the effectiveness of our method when dealing with dynamic scenes in stereo mode.
Evaluation of processing speed
In order to verify the improvement of real-time performance by our method, we calculate the running time of different semantic SLAM systems based on the w_rpy sequence. Table 13 lists the statistical results.
In the w_rpy sequence, the resolution of each input image is 640 × 480. We measure the average running time of each part by setting the FPS of camera at 30 and compare it to Dyn-ORB-SLAM and DynaSLAM. All measurements are based on the same computing platform. Deep learning models used by these semantic SLAM methods and their corresponding inference times are listed in Table 13. It can be seen that after applying the lightweight semantic segmentation model trained by the multi-level knowledge distillation, the inference time is significantly reduced compared with other methods. Especially, the inference time of our method is only 12.8% of that of DynaSLAM. Moreover, adding multi-view geometry and background inpainting is a further slowdown, which is another reason why DynaSLAM cannot be performed for real-time operation. Therefore, compared with DynaSLAM, our method is able to establish a better balance between the accuracy and processing speed, which is more suitable for practical applications. Compared with Dyn-ORB-SLAM, our method has a shorter average tracking time and a faster running speed. Static semantic keyframe selection and dynamic probability update of our method do not consume much time.
Conclusion
Aiming at the problem that existing semantic SLAM methods for dynamic scenes are not fast enough, we propose a real-time semantic SLAM system based on dynamic probabilistic optimization and knowledge distillation in this paper. Taking ORB-SLAM3 as backbone, we improve the overall execution speed of SLAM system from the perspectives of model lightweight, keyframe segmentation strategy, and multithreading parallelism. In terms of dynamic processing, we rely on probability to distinguish the attributes of extracted feature points. By combining the segmentation results of keyframes and data matching algorithm, we can realize the update and propagation of dynamic probability. Moreover, we also combine dynamic probability with local BA to optimize the camera pose. Experimental results based on open datasets show that our method can effectively deal with dynamic scenes and improve the execution speed of semantic SLAM system at the same time.
However, our method still has some limitations. In this paper, static feature points are utilized for pose estimation and play a more important role in the BA optimization process. However, the selection of static feature points is dependent on artificial priors. For example, we subjectively consider some movable objects, like vehicles, to be dynamic and some objects, like tables, to be static. However, some movable objects may be static, such as the parking cars. Assigning high-dynamic probabilities to feature points on these objects may drag down the SLAM system’s performance. Moreover, some objects without a priori dynamic property could be moving, e.g., the chairs being dragged by a person. Track feature points on these objects may corrupt the robustness of the pose estimation. Therefore, methods to quickly detect the above two kinds of feature points should be proposed to solve this problem in the future.
Availability of data and materials
Not applicable.
Code availability
Not applicable.
References
Taketomi T, Uchiyama H, Ikeda S (2017) Visual SLAM algorithms: a survey from 2010 to 2016. IPSJ Trans Comput Vis Appl. https://doi.org/10.1186/s41074-017-0027-2
Dong X, Cheng L, Peng H, Li T (2021) FSD-SLAM: a fast semi-direct SLAM algorithm. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00323-y
Cadena C, Carlone L, Carrillo H et al (2016) Past, present, and future of simultaneous localization and map**: toward the robust-perception age. IEEE T Robot 32:1309–1332. https://doi.org/10.1109/TRO.2016.2624754
Bescos B, Fácil JM, Civera J et al (2018) DynaSLAM: tracking, map**, and inpainting in dynamic scenes. IEEE Robot Autom Lett 3:4076–4083. https://doi.org/10.1109/LRA.2018.2860039
Zhao X, Zuo T, Hu X (2021) OFM-SLAM: a visual semantic SLAM for dynamic indoor environments. Math Porbl Eng. https://doi.org/10.1155/2021/5538840
** S, Chen L, Sun R et al (2020) A novel vSLAM framework with unsupervised semantic segmentation based on adversarial transfer learning. Appl Soft Comput 90:106153. https://doi.org/10.1016/j.asoc.2020.106153
Long X, Zhang W, Zhao B (2020) PSPNet-SLAM: a semantic SLAM detect dynamic object by pyramid scene parsing network. IEEE Access 8:214685–214695. https://doi.org/10.1109/ACCESS.2020.3041038
He K, Gkioxari G, Dollár P et al (2017) Mask r-cnn. In: IEEE international conference on computer vision (ICCV). IEEE, pp 2961–2969. https://doi.org/10.1109/ICCV.2017.322
Chen LC, Papandreou G, Kokkinos I et al (2018) Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell 40:834–848. https://doi.org/10.1109/TPAMI.2017.2699184
Zhao H, Shi J, Qi X et al (2017) Pyramid scene parsing network. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 2881–2890. https://doi.org/10.1109/CVPR.2017.660
Yu C, Liu Z, Liu X J et al (2018) DS-SLAM: A semantic visual SLAM towards dynamic environments. In: IEEE/RSJ International conference on intelligent robots and systems (IROS). IEEE, pp 1168–1174. https://doi.org/10.1109/IROS.2018.8593691
Cui L, Ma C (2019) SOF-SLAM: a semantic visual SLAM for dynamic environments. IEEE Access 7:166528–166539. https://doi.org/10.1109/ACCESS.2019.2952161
Xu H, Yang C, Feng Y (2019) FD-SLAM: real-time tracking and map** in dynamic environments. In: IEEE international conference on unmanned systems and artificial intelligence (ICUSAI). IEEE, pp 166–171. https://doi.org/10.1109/ICUSAI47366.2019.9124850
Badrinarayanan V, Kendall A, Cipolla R (2017) Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell 39:2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615
Cheng J, Wang Z, Zhou H et al (2020) DM-SLAM: a feature-based SLAM system for rigid dynamic scenes. ISPRS Int J Geo Inf 9:202. https://doi.org/10.3390/ijgi9040202
Hartley R, Zisserman A (2004) Multiple view geometry in computer vision. Cambridge, New York
Liu PR, Meng MQH, Liu PX et al (2006) Optical flow and active contour for moving object segmentation and detection in monocular robot. In: IEEE International conference on robotics and automation (ICRA). IEEE, pp 4075–4080. https://doi.org/10.1109/ROBOT.2006.1642328
Zinbi Y, Chahir Y, Elmoataz A (2008) Moving object segmentation using optical flow with active contour model. In: International conference on information and communication technologies: from theory to applications (ICTTA). IEEE, pp 1–5. https://doi.org/10.1109/ICTTA.2008.4530112
Campos C, Elvira R, Rodríguez JJG et al (2021) ORB-SLAM3: an accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans Robot 37:1874–1890. https://doi.org/10.1109/TRO.2021.3075644
Hinton G, Vinyals O, Dean J (2015) Distilling the knowledge in a neural network. Preprint at ar**v:1503.02531
**e J, Shuai B, Hu JF et al (2018) Improving fast segmentation with teacher-student learning. Preprint at ar**v:1810.08476.
Hou Y, Ma Z, Liu C et al (2020) Inter-region affinity distillation for road marking segmentation. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 12486–12495. https://doi.org/10.1109/CVPR42600.2020.01250
He T, Shen C, Tian Z et al (2019) Knowledge adaptation for efficient semantic segmentation. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 578–587. https://doi.org/10.1109/CVPR42600.2020.01250
Park S, Heo YS (2020) Knowledge distillation for semantic segmentation using channel and spatial correlations and adaptive cross entropy. Sensors 20:4616. https://doi.org/10.3390/s20164616
Gadde R, Jampani V, Gehler PV (2017) Semantic video cnns through representation war**. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 4453–4462. https://doi.org/10.1109/ICCV.2017.477
Zhu Yi, Sapra K, Reda FA et al (2019) Improving semantic segmentation via video propagation and label relaxation. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 8856–8865. https://doi.org/10.1109/CVPR.2019.00906
Mur-Artal R, Tardós JD (2017) ORB-SLAM2: an open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans Robot 33:1255–1262. https://doi.org/10.1109/TRO.2017.2705103
Ai Y, Rui T, Lu M et al (2020) DDL-SLAM: a robust RGB-D SLAM in dynamic environments combined with deep learning. IEEE Access 8:162335–162342. https://doi.org/10.1109/ACCESS.2020.2991441
** Q, Meng Z, Pham TD et al (2019) DUNet: a deformable network for retinal vessel segmentation. Knowl Based Syst 178:149–162. https://doi.org/10.1016/j.knosys.2019.04.025
Chen X, Xue J, Fang J et al (2020) Using detection, tracking and prediction in visual SLAM to achieve real-time semantic map** of dynamic scenarios. In: IEEE intelligent vehicles symposium. IEEE, pp 666–671. https://doi.org/10.1109/IV47402.2020.9304693
Liu W, Anguelov D, Erhan D et al (2016) SSD: single shot multibox detector. In: European conference on computer vision. Springer, pp 21–37
Zhong F, Wang S, Zhang Z et al (2018) Detect-SLAM: making object detection and SLAM mutually beneficial. In: IEEE winter conference on applications of computer vision (WACV). IEEE, pp 1001–1010. https://doi.org/10.1109/WACV.2018.00115
Elvira R, Tardos JD, Montiel JMM (2019) ORBSLAM-Atlas: A robust and accurate multi-map system. In: IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 6253–6259. https://doi.org/10.1109/IROS40897.2019.8967572
Liu Y, Shen C, Yu C et al (2020) Efficient semantic video segmentation with per-frame inference. In: European conference on computer vision. Springer, pp 352–368
Nair V, Hinton GE (2010) Rectified linear units improve restricted boltzmann machines. In: International conference on international conference on machine learning (ICML). ACM, pp 807–814
Sturm J, Engelhard N, Endres F et al (2012) A benchmark for the evaluation of RGB-D SLAM systems. In: IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 573–580. https://doi.org/10.1109/IROS.2012.6385773
Geiger A, Lenz P, Urtasun R (2012) Are we ready for autonomous driving? The KITTI vision benchmark suite. In: IEEE conference on computer vision and pattern recognition. IEEE, pp 3354–3361. https://doi.org/10.1109/CVPR.2012.6248074
Wang L, Li D, Zhu Y et al (2020) Dual super-resolution learning for semantic segmentation. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR). IEEE, pp 3773–3782. https://doi.org/10.1109/CVPR42600.2020.00383
Türkmen S, Heikkilä J (2019) An efficient solution for semantic segmentation: Shufflenet v2 with atrous separable convolutions. In: Scandinavian conference on image analysis. Springer, pp 41–53. https://doi.org/10.1007/978-3-030-20205-7_4
Wu T, Tang S, Zhang R et al (2020) Cgnet: a light-weight context guided network for semantic segmentation. IEEE Trans Image Process 30:1169–1179. https://doi.org/10.1109/TIP.2020.3042065
Zhao H, Qi X, Shen X et al (2018) Icnet for real-time semantic segmentation on high-resolution images. In: European conference on computer vision (ECCV). Springer pp, 418–434. https://doi.org/10.1007/978-3-030-01219-9_25
Mehta S, Rastegari M, Caspi A et al (2018) Espnet: efficient spatial pyramid of dilated convolutions for semantic segmentation. In: European conference on computer vision (ECCV). Springer, pp 561–580. https://doi.org/10.1007/978-3-030-01249-6_34
Cordts M, Omran M, Ramos S et al (2016) The cityscapes dataset for semantic urban scene understanding. In: IEEE conference on computer vision and pattern recognition (CVPR). IEEE, pp 3213–3223. https://doi.org/10.1109/CVPR.2016.350
Wang Y, Zhou W, Jiang T et al (2020) Intra-class feature variation distillation for semantic segmentation. In: European conference on computer vision (ECCV). Springer, pp 346–362. https://doi.org/10.1007/978-3-030-58571-6_21
Liu Y, Shu C, Wang J et al (2020) Structured knowledge distillation for dense prediction. IEEE Trans Pattern Anal. https://doi.org/10.1109/TPAMI.2020.3001940
Shu C, Liu Y, Gao J et al. Channel-wise distillation for semantic segmentation. In: IEEE/CVF international conference on computer vision (ICCV). IEEE, pp 5291–5300. https://doi.org/10.1109/ICCV48922.2021.00526
Jiao J, Wang C, Li N et al (2021) An adaptive visual dynamic-SLAM method based on fusing the semantic information. IEEE Sens J. https://doi.org/10.1109/JSEN.2021.3051691
** based on deep learning in dynamic environment. Robot Auton Syst 117:1–16. https://doi.org/10.1016/j.robot.2019.03.012
Zhang Z, Zhang J, Tang Q (2019) Mask R-CNN based semantic RGB-D SLAM for dynamic scenes. In: IEEE/ASME international conference on advanced intelligent mechatronics (AIM). IEEE, pp 1151–1156. https://doi.org/10.1109/AIM.2019.8868400
Xu H, Zhang S, Liu P (2019) DOS-SLAM: A real-time dynamic object segmentation visual SLAM system. In: The 2019 2nd international conference on algorithms, computing and artificial intelligence. ACM, pp 85–90. https://doi.org/10.1145/3377713.3377731
He K, Gkioxari G, Dollar P, Girshick R (2017) Mask R-CNN. In: IEEE international conference on computer vision (ICCV). IEEE, pp 2980–2988. https://doi.org/10.1109/ICCV.2017.322
Acknowledgements
This work is financially supported by the National Innovation and Development Project of Industrial Internet (No. TC190H3WR), in part by 2021 Open Project of Jiangsu Provincial Key Laboratory of Advanced Robotics (No. KJS2160).
Funding
This work is financially supported by the National Innovation and Development Project of Industrial Internet (No.TC190H3WR), in part by 2021 Open Project of Jiangsu Provincial Key Laboratory of Advanced Robotics (No. KJS2160).
Author information
Authors and Affiliations
Contributions
Conceptualization: YG and RS; software: SJ and ZL; validation: LC and RS; writing—original draft preparation: ZL and YG; writing—review and editing: LC and SJ; project administration: LC. All the authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, L., Ling, Z., Gao, Y. et al. A real-time semantic visual SLAM for dynamic environment based on deep learning and dynamic probabilistic propagation. Complex Intell. Syst. 9, 5653–5677 (2023). https://doi.org/10.1007/s40747-023-01031-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01031-5