
Abstract
An integrated method is proposed to solve the problem of frequent conflicts between autonomous vehicles and pedestrians in the street crossing scene. The method involves pedestrian detection, tracking, and intention recognition. First, an enhanced YOLOv8 is introduced by combining the C2f_CA module to achieve accurate pedestrian detection, tracking and pose estimation. Second, a variety of intention recognition features are proposed to characterize the position and pose of pedestrians in spatial and time domains. Finally, by taking the feature data as input for the base learners, the intention classification model is proposed based on the Stacking model with SVM, KNN and random forest as the base learners and XGBoost as the meta learner. The experimental results show that the enhanced YOLOv8 improves the detection accuracy by 5.4% compared with the original model, and the intention recognition based on the Stacking model can achieve 94.0% accuracy on the JAAD dataset, which is improved by more than 3.4% compared with the existing intention recognition models. Furthermore, when different parts of a pedestrian are occluded, the accuracy of the Stacking model still reaches 65.8%–73.3%, which verifies the robustness of the proposed model. The proposed model provides reliable inputs for decision planning of autonomous vehicles, which is conducive to improving the safety of self-driving.
摘 要
针对过街场景下智能车与行人冲突多发的情况,提出了一套针对行人检测、跟踪和意图识 别的集成方法。首先提出基于C2f_CA 模块改进YOLOv8 模型完成对行人的准确检测、跟踪和姿态 估计;然后提出多种意图识别特征在空间和时域关系下表征行人的位置与姿态;最后以特征数据为 输入,基于以SVM、 KNN 和随机森林三者为基模型的Stacking 异质集成方法完成行人的意图识别 建模。对上述模型进行实验验证,结果表明,改进后的YOLOv8 模型相较于原模型检测精度提高了 5.4%,基于Stacking 异质集成模型的行为意图识别在JAAD 数据集上可以达到94.0%的准确率,相 比于现有的意图识别模型提升了3.4%以上;在行人不同部位被遮挡的情况下,模型的准确率依旧达 到65.8%∼73.3%,验证了该方法的鲁棒性。该方法为自动驾驶汽车的决策规划提供了可靠的输入, 有利于提高自动驾驶的安全性。
Similar content being viewed by others


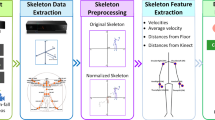
References
HU Y C, LI M K. Challenges and responses of self-driving vehicles to road traffic safety law [J]. Journal of Shanghai Jiao Tong University (Philosophy and Social Sciences), 2019, 27(1): 44–53 (in Chinese).
ZHOU M C. Criminal liability of traffic accident caused by self-driving vehicles [J]. Journal of Shanghai Jiao Tong University (Philosophy and Social Sciences), 2019, 27(1): 36–43 (in Chinese).
YANG B, FAN F C, YANG J C, et al. Recognition of pedestrians’ street-crossing intentions based on action prediction and environment context [J]. Automotive Engineering, 2021, 43(7): 1066–1076 (in Chinese).
WANG R P, CUI Y, SONG X A, et al. Multi-information-based convolutional neural network with attention mechanism for pedestrian trajectory prediction [J]. Image and Vision Computing, 2021, 107: 104110.
ABUGHALIEH K M, ALAWNEH S G. Predicting pedestrian intention to cross the road [J]. IEEE Access, 2020, 8: 72558–72569.
FANG H S, LI J F, TANG H Y, et al. AlphaPose: Whole-body regional multi-person pose estimation and tracking in real-time [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 7157–7173.
OSOKIN D. Real-time 2D multi-person pose estimation on CPU: Lightweight OpenPose [DB/OL]. (2018-11-29) [2023-08-17]. https://arxiv.org/abs/1811.12004
GHORI O, MACKOWIAK R, BAUTISTA M, et al. Learning to forecast pedestrian intention from pose dynamics [C]//2018 IEEE Intelligent Vehicles Symposium. Changshu: IEEE, 2018: 1277–1284.
HU Y Z, JIANG T, LIU X, et al. Pedestrian-crossing intention-recognition based on dual-stream adaptive graph-convolutional neural-network [J]. Journal of Automotive Safety and Energy, 2022, 13(2): 325–332 (in Chinese).
LÜ C, CUI G G, MENG X H, et al. Graph representation method for pedestrian intention recognition of intelligent vehicle [J]. Transactions of Bei**g Institute of Technology, 2022, 42(7): 688–695 (in Chinese).
ZHANG Y F, SUN P Z, JIANG Y, et al. Byte-Track: multi-object tracking by associating every detection box [M]//Computer vision—ECCV 2022. Cham: Springer, 2022: 1–21.
HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design [C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 13708–13717.
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132–7141.
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [M]//Computer vision—ECCV 2018. Cham: Springer, 2018: 3–19.
LI C X, LU S B, ZHANG B H, et al. Human-vehicle steering collision avoidance path planning based on pedestrian location prediction [J]. Automotive Engineering, 2021, 43(6): 877–884 (in Chinese).
NAVEED H, KHAN G, KHAN A U, et al. Human activity recognition using mixture of heterogeneous features and sequential minimal optimization [J]. International Journal of Machine Learning and Cybernetics, 2019, 10(9): 2329–2340.
WANG J, LIU Z C, WU Y, et al. Mining actionlet ensemble for action recognition with depth cameras [C]//2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence: IEEE, 2012: 1290–1297.
SUN J H, GE H Y, ZHANG Z H. AS-YOLO: An improved YOLOv4 based on attention mechanism and SqueezeNet for person detection [C]//2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference. Chongqing: IEEE, 2021: 1451–1456.
LI D P, REN X M, YAN N N. Real-time detection of insulator drop string based on UAV aerial photography [J]. Journal of Shanghai Jiao Tong University, 2022, 56(8): 994–1003 (in Chinese).
GIRSHICK R. Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 1440–1448.
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [M]//Computer vision—ECCV 2016. Cham: Springer, 2016: 21–37.
XING Z W, KAN B, LIU Z S, et al. Airport pavement snow and ice state perception based on improved YOLOX-S [J]. Journal of Shanghai Jiao Tong University, 2023, 57(10): 1292–1304 (in Chinese).
ZHANG S L, ABDEL-ATY M, WU Y N, et al. Pedestrian crossing intention prediction at red-light using pose estimation [J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(3): 2331–2339.
YAN S J, XIONG Y J, LIN D H. Spatial temporal graph convolutional networks for skeleton-based action recognition [J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 7444–7452.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest The authors declare that they have no conflict of interest.
Additional information
Foundation item: the National Natural Science Foundation of China (No. 52302501), and the Natural Science Foundation of Shanghai (No. 21ZR1444500)
Rights and permissions
About this article

Cite this article
Lu, J., Chen, H., Bai, Y. et al. Recognition of Pedestrians’ Street-Crossing Intentions Based on Skeleton Features. J. Shanghai Jiaotong Univ. (Sci.) (2024). https://doi.org/10.1007/s12204-024-2700-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12204-024-2700-9