
Abstract
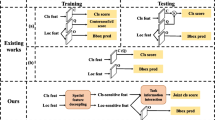
Existing one-stage detectors usually use two decoupled branches to optimize two subtasks, i.e., object localization and classification. However, this design paradigm will lead to misalignment of spatial features due to inconsistency in localization and classification. To mitigate this problem, we propose a plug-in and simple AF-Head (Aligned Features) that can generate aligned features for each task. Our proposed AF-Head contains Focus-Guided Feature Enhancement Module (FGM) and Auxiliary Positioning Module (APM). Specifically, in our FGM, we propose a focus branch representing the joint representation of localization confidence and classification scores. Then, we combine the focus and classification branches to alleviate the gap between training and inference. In addition, APM generates more accurate offsets for the localization branch to align with the classification branch. Moreover, we propose AF-Net based on the AF-Head. Extensive experiments on the MS-COCO demonstrate that our AF-Head can boost 0.7\(\sim \)1.7 AP on different state-of-the-art one-stage detectors. Notably, AF-Net with a standard ResNeXt-101-32x4d-DCN backbone achieves 49.2 AP on the COCO test-dev.







Similar content being viewed by others


Availability of data and materials
The datasets generated or analyzed during this study are available in the MS-COCO2017 repository, https://cocodataset.org/download.
References
Zou, Z., Shi, Z., Guo, Y., Ye, J.: Object detection in 20 years: a survey (2019). ar**v:1905.05055
Chen, K., Lin, W., Li, J., See, J., Wang, J., Zou, J.: Ap-loss for accurate one-stage object detection. IEEE Trans. Pattern Anal. Mach. Intell. 43(11), 3782–3798 (2020)
Chen, Z.M., **, X., Zhao, B.R., Zhang, X., Guo, Y.: HCE: hierarchical context embedding for region-based object detection. IEEE Trans. Image Process. 30, 6917–6929 (2021)
Ren, S., He, K., Girshick, R.B., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2015)
Zhu, X., Hu, H., Lin, S., Dai, J.: Deformable convnets v2: more deformable, better results. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9300–9308 (2019)
Fan, B., Shao, M., Li, Y., Li, C.: Global contextual attention for pure regression object detection. Int. J. Mach. Learn. Cybern. 13, 2189–2197 (2022)
Li, Y., Shao, M., Fan, B., Zhang, W.: Multi-scale global context feature pyramid network for object detector. Signal Image Video Process 16, 705–713 (2022)
He, K., Gkioxari, G., Dollár, P., Girshick, R.B.: Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 42, 386–397 (2020)
Lin, T.Y., Goyal, P., Girshick, R.B., He, K., Dollár, P.: Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42, 318–327 (2020)
Kong, T., Sun, F., Liu, H., Jiang, Y., Li, L., Shi, J.: Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 29, 7389–7398 (2020)
Yang, Y., Pan, Z., Hu, Y., Ding, C.: CPS-Det: an anchor-free based rotation detector for ship detection. Remote Sens. 13(11), 2208 (2021)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European Conference on Computer Vision, pp. 213–229. Springer (2020)
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J: Deformable detr: deformable transformers for end-to-end object detection (2021). ar**v:2010.04159
Chi, C., Zhang, S., **ng, J., Lei, Z., Li, S.Z., Zou, X.: Selective refinement network for high performance face detection. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 8231–8238 (2019)
Wang, J., Chen, K., Yang, S., Loy, C.C., Lin, D.: Region proposal by guided anchoring. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2960–2969 (2019)
Zhang, S., Wen, L., Bian, X., Lei, Z., Li, S.: Single-shot refinement neural network for object detection. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4203–4212 (2018)
Zhang, H., Wang, Y., Dayoub, F., Sunderhauf, N.: Varifocalnet: an iou-aware dense object detector. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8510–8519 (2021)
Yang, Z., Liu, S., Hu, H., Wang, L., Lin, S.: Reppoints: point set representation for object detection. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9656–9665 (2019)
Yang, Y., Li, M., Meng, B., Ren, J., Sun, D., Huang, Z.: Rethinking the aligned and misaligned features in one-stage object detection (2021). ar**v:2108.12176
Wu, S., Li, X., Wang, X.: Iou-aware single-stage object detector for accurate localization. Image Vis. Comput. 97, 103911 (2020)
Jiang, B., Luo, R., Mao, J., **ao, T., Jiang, Y.: Acquisition of localization confidence for accurate object detection. In: Proceedings of the European conference on computer vision (ECCV), pp. 784–799 (2018)
Kim, K., Lee, H.S.: Probabilistic anchor assignment with iou prediction for object detection. In: ECCV (2020)
Li, Y., Wang, S.: Har-net: joint learning of hybrid attention for single-stage object detection. IEEE Trans. Image Process. 29, 3092–3103 (2020)
Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection. Adv. Neural. Inf. Process. Syst. 33, 21002–21012 (2020)
Feng, C., Zhong, Y., Gao, Y., Scott, M.R., Huang, W.: Tood: task-aligned one-stage object detection. In: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 3490–3499. IEEE Computer Society (2021)
Li, X., Wang, W., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss v2: learning reliable localization quality estimation for dense object detection. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11627–11636 (2021)
Tian, Z., Shen, C., Chen, H., He, T.: Fcos: a simple and strong anchor-free object detector. IEEE Transactions on Pattern Analysis and Machine Intelligence (2020)
Zhang, S., Chi, C., Yao, Y., Lei, Z., Li, S.Z.: Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9756–9765 (2020)
Rezatofighi, S.H., Tsoi, N., Gwak, J., Sadeghian, A., Reid, I.D., Savarese, S.: Generalized intersection over union: A metric and a loss for bounding box regression. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 658–666 (2019)
Lin, T.Y., Maire, M., Belongie, S.J., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: common objects in context. In: ECCV (2014)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016)
**e, S., Girshick, RB., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5987–5995 (2017)
Deng, J., Dong, W., Socher, R., Li, LJ., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: CVPR (2009)
Chen, K., Wang, J., Pang, J., Cao, Y., **ong, Y., Li, X., Sun, S., Feng, W., Liu, Z., Xu, J., et al.: Mmdetection: open mmlab detection toolbox and benchmark (2019). ar**v:1906.07155
Goyal, P., Dollár, P., Girshick, R.B., Noordhuis, P., Wesolowski, L., Kyrola, A., Tulloch, A., Jia, Y., He, K.: Accurate, large minibatch SGD: training imagenet in 1 hour (2017). ar**v:1706.02677
Li, H., Wu, Z., Zhu, C., **ong, C., Socher, R., Davis, L.S.: Learning from noisy anchors for one-stage object detection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10585–10594 (2020)
Zhang, X., Wan, F., Liu, C., Ji, R., Ye, Q.: Freeanchor: learning to match anchors for visual object detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (2019)
Zhu, C., Chen, F., Shen, Z., Savvides, M.: Soft anchor-point object detection. In: European Conference on Computer Vision, pp. 91–107. Springer (2020)
Ke, W., Zhang, T., Huang, Z., Ye, Q., Liu, J., Huang, D.: Multiple anchor learning for visual object detection. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10203–10212 (2020)
Zhu, B., Wang, J., Jiang, Z., Zong, F., Liu, S., Li, Z., Sun, J.: Autoassign: differentiable label assignment for dense object detection (2020). ar**v:2007.03496
Acknowledgements
The authors are very indebted to the reviewers for their critical comments and suggestions for the improvement in this paper.
Funding
This work was supported by National Key Research and Development Program of China (2021YFA1000102) and in part by the Grants from the National Natural Science Foundation of China (Nos. 61673396, 61976245).
Author information
Authors and Affiliations
Contributions
All authors read and approved the final manuscript. All authors’ individual contributions are as follows: ZL: investigation, writing—original draft. MS: conceptualization , supervision, validation. YS: methodology, data Curation. ZP: formal analysis, writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, Z., Shao, M., Sun, Y. et al. Multi-task feature-aligned head in one-stage object detection. SIViP 17, 1345–1353 (2023). https://doi.org/10.1007/s11760-022-02342-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-022-02342-9