
Abstract
The map** and characterisation of building footprints is a challenging task due to inaccessibility and incompleteness of the required data, thus hindering the estimation of loss caused by natural and anthropogenic hazards. Major advancements have been made in the collaborative map** of buildings with platforms like OpenStreetMap, however, many parts of the world still lack this information or the information is outdated. We created a semi-automated workflow for the development of elements-at-risk (EaR) databases of buildings by detecting building footprints using deep learning and characterising the footprints with building occupancy information using building morphological metrics and open-source auxiliary data. The deep learning model was used to detect building EaR footprints in a city in Kerala (India) with an F1 score of over 76%. The footprints were classified into 13 building occupancy types along with information such as average number of floors, total floor space area, building density, and percentage of built-up area. We analysed the transferability of the approach to a different city in Kerala and obtained an almost similar F1 score of 74%. We also examined the exposure of the buildings and the associated occupancies to floods using the 2018 flood susceptibility map of the respective cities. We notice certain shortcomings in our research particularly, the need for a local expert and good quality auxiliary data to obtain reasonable building occupancy information, however, our research contributes to develo** a rapid method for generating a building EaR database in data-scarce regions with attributes of occupancy types, thus supporting regional risk assessment, disaster risk mitigation, risk reduction initiatives, and policy developments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
1.1 Background
Natural hazards may result in negative consequences, including loss of life, property damage, and economic disruption, all of which must be considered in order to develop successful risk mitigation strategies (Eshrati et al. 2015). Exposure, vulnerability, and risk analysis require inventories of elements-at-risk (EaR), also called assets, to determine who and what is at risk, as a basis for selecting risk reduction options (Gill and Malamud 2014). Many types of EaR can be considered (e.g. buildings, population, transportation infrastructure, agriculture), depending on the aim of the risk assessment and the sector considered. Detection of existing EaR footprints and their characterisation or classification are important requirements for risk assessment (Eshrati et al. 2015). Buildings are the most frequently used EaR in risk assessments, as they are key for estimating economic losses and population losses. Important building characteristics for loss estimation are the occupancy types, structural types, number of storeys, the value of the structure and its content, and the number of people in different time periods (Papathoma-Köhle et al. 2007). This information, however, is difficult to obtain as it requires field surveys or access to census data, which is often restricted or outdated. Recent advances in volunteered geographical information (VGI) with platforms such as OpenStreetMap (OSM) and Mapillary, highlight the continuing emergence of citizen science (Goodchild 2007). Collaborative initiatives have aided in many applications, such as land use map** (Ribeiro and Fonte 2015), post-disaster damage map** (Panek 2015), and community development (Panek and Netek 2019) in countries like South Africa (Panek 2015), Spain (Ariza-López et al. 2014), India (Papnoi et al. 2017; Raskar-phule and Choudhury 2015) and Malaysia (Husen et al. 2018). Barrington-Leigh and Millard-Ball (2017) estimated that over 80 per cent of the world is mapped on OSM. Raskar et al. (2015) generated flood vulnerability maps by employing VGI data like OSM of Mumbai city for critical infrastructure and transportation systems. Papnoi et al. (2017) also looked at the hazard, risk, and severity of the floods in Navi-Mumbai in a gridded system while recommending that urban areas can be easily and effectively mapped using OSM data, which are generally quite accurate. Geiß et al. (2017) estimated building and population EaR from land use/cover data on very high-resolution remote sensing while also commenting on the applicability of OSM data in exposure assessment. A promising area of application is the use of OSMs for data analysis processes and the substitution of conventional data sources. The quality of OSM properties and metadata has also been researched for suitability in different fields including the natural hazard risk science and suggests much pertinence (Fan et al. 2014ab; Poser and Dransch 2010; Schnebele and Cervone 2013). Furthermore, OSM data can also be used to train supervised algorithms to extract information relevant to field of application.
However, the usage of OSM building information for risk assessment has several problems. OSM buildings are often not updated on a regular basis and buildings that have been destroyed by a disaster, for example, are often still present in OSM even if they no longer exist physically (Foody et al. 2015). Accurate attribute collection of building data from OSM is also significant difficult since building characteristics cannot be seen by volunteer mappers on vertical satellite images, and often left blank (Zhang and Pfoser 2019). In the assessment of the vulnerability, loss, and risk, building typological variables such as occupancy class (e.g., single-family home), construction type (e.g., reinforced concrete), and the number of storeys is required. Current online products and tools such as Google Street View, Google Maps, OSM maps, land use data, and other auxiliary datasets can assist in providing additional context mostly of the occupancy type. However, the integration of such data with collaborative map** can be difficult due to the different nature of these data.
1.2 Building map**
Building footprint map** through visual interpretation and manual digitisation from remote sensing images has become the standard approach. However, this is time-consuming and depends on the skill and dedication of the mapper, and may result in omission and misclassification (Mobasheri et al. 2018; Wu et al. 2019), resulting in the detection of hidden features, based on common characteristics like colour, shape, and size, and deep features such as spatial relationship. Specific capabilities of CNNs are that they maintain spatial configuration of input images, their sparse connections enable the use of lightweight models, and their representation learning procedure helps to automatically learn features from the training data. These capabilities have resulted in high accuracies in image classification (**. Remote Sens. https://doi.org/10.3390/rs12142274 " href="/article/10.1007/s11069-022-05612-4#ref-CR65" id="ref-link-section-d248350792e616">2020; ** of image pixels to specified class labels, such as buildings and non-buildings. For semantic segmentation, FCN is one of the most essential networks in DL (Zhu et al. 2020). Therefore, the ResU-Net model was chosen for building detection following.
1.3 Building characterisation
It is mostly not possible to describe important building characteristics based only on the visual interpretation or automatic classification of vertical remote sensing images. Properties such as building occupancy types, construction types or the number of floors can sometimes be obtained from vertical satellite images (Sarabandi and Kiremidjian 2008), from aspects such as the shadow from buildings, the characteristics of rooftops, and the spatial relationships with other buildings. However, there are many building features that cannot be deduced from vertical images alone, and other data sources are required such as census data, official building databases, cadastral databases, field surveys or volunteered geographic information (VGI) (Graff et al. 2019) to provide relevant building information. Therefore, an approach to obtaining such relevant building information that describes the characteristics of the buildings via the use of open source data must be established. The first step in characterising a building is to examine its physical morphology and how it relates to neighbouring buildings and the environment. These morphological measures or metrics can provide useful information about the sort of buildings that may exist in a given location, as well as possible building functions such as occupancy types. The urban morphology Python library Momepy (Fleischmann 2019) is created for the quantitative analysis of urban form and morphometrics. Building diversity, adjacency, area coverage, and other structural factors can all be calculated using the library, which is useful for grou** buildings into physical similarities. As a result, the tool can serve as a link between detecting and characterising buildings as elements at risk. Momepy is used for semantically classifying buildings based on building attributes such as size, form, proximity to other buildings, and building compactness. The second step in characterising would be to combine the obtained morphometric information with added auxiliary knowledge, which can be, for example, building tags from VGI such as OSM and land use data. Fan et al. (2014ab) studied urban morphometrics to characterise buildings in five German cities using a complete OSM dataset with accurate building data and over 2027 buildings with occupancy type labels. The use of OSM for determining building attributes was also investigated by several other authors (Fan et al. 2014ab; Sun et al. 2017). However, the process of using building tags using just the OSM is not feasible in regions where very few buildings are mapped in OSM. In addition to OSM data, additional data sources can prove useful in approximating building characteristics, which could be oblique images such as Google street view or Mapillary, building labels such as from Google Maps, built-up area classification from the Global Urban Footprint (GUF) (Esch et al. 2013; Gei, Wurm, and Taubenböck, 2017; Geis et al. 2019) and land use/land cover maps (ISRO 2020). Gei et al. (2017, 2019) developed a method to combine the GUF data with height information from TanDEM-X data. Cerri et al. (2021) used OSM building data together with various proxies or auxiliary data to enhance building characterisation for flood vulnerability assessment. Stewart et al. (2016) created a technique for estimating the building occupancy type from population density data using Bayesian machine learning. Hasan et al. (2018) used LiDAR data to automatically extract building footprints and heights, and manual interpretation of building occupancy types for landslide exposure. Our study expands on these earlier studies by develo** a building characterisation approach using open-source data such as OSM, Google Maps, and other publicly available data, focusing on the generation of homogeneous urban units manifested by the physical morphologies of the buildings and the estimation of their pre-dominant building occupancy type. We do this at an aggregated level in homogeneous units to avoid the lack of information for each individual building.
Therefore, the crux of the research was to detect building footprints using deep learning and to recognise the building occupancy of the detected footprints via building characterisation modules including the use of building morphological metrics and open-source auxiliary data. We employ a semi-automated workflow for the generation of Elements-at-Risk (EaR) databases of buildings.
2 Study area and datasets
2.1 Study area
The approach was tested in two areas in the state of Kerala, India (Fig. 1-A,B,C). Although Kerala is one of the most developed states of India, with a good disaster management framework, it suffered from a lack of organised EaR data, as a basis for risk assessment and disaster preparedness. The state witnessed severe flooding and landsliding in 2018, displacing 85,000 people and destroying numerous buildings (Dwyer 2018). The Kerala State Disaster Management Authority (KSDMA) is the main organisation at the state level, supporting district-level organisations in this state with a high level of self-government. KSDMA supported disaster risk management in Kerala through collaborative map** projects with organisations such as the International Centre for Free and Open-Source Software (ICFOSS) to establish an elements-at-risk database through the Mapathon Kerala project (Kerala State Spatial Data Infrastructure 2021). However, owing to the time necessary to compile appropriate open data across the entire state of Kerala, the results were not available online at the time of this study. In contrast to this project, which requires a considerable effort in time and human resources, our research aims to address the rapid map** of buildings EaR (including both detection and characterisation) in data-scarce locations that may be utilised for emergency reasons such as relief efforts.

Study area of Palakkad (b) and Kollam (c) in south western India (a). D and E are examples of the existing building data in OpenStreetMap. b and c also depicts the flood exposure derived from a flood susceptibility map by the KSDMA
Palakkad is town with a population of 130,000 people located in the district of Palakkad (Census of India 1981). It is bordered by tributaries of the Bharathapuzha River and is frequently subjected to high levels of monsoonal rainfall with an average annual of 1216 mm. In the latest disaster of 2018, due to widespread heavy rain-induced floods and landslides in the mountainous hills surrounding Palakkad, many people had to be relocated while landslides claimed the lives of 9 people destroying 3 houses (Bennett 2018). To examine the practicality and transferability of the proposed framework, part of the city of Kollam was chosen as a second test site. The former is a landlocked city, surrounded by two river channels and a dam towards the north whereas the latter is a coastal city which is surround by the Arabian Sea towards the west and the big Ashtamudi Lake in the north. As Kollam is surrounded by these two water bodies, it becomes extremely vulnerable to coastal and lake flooding during the monsoon seasons. Likewise, Kollam was severely flooded causing major property damage and loss in 2018.
2.2 Datasets
Road and building data were downloaded from OSM. As can be seen from Fig. 1d, e, even though there are many buildings (indicated by circles) mapped with their respective footprints, these are mostly limited to specific types of buildings (e.g. public, commercial, educational buildings), while the majority of the city is only marked as built-up area (with instances of tags such as “Yes”). The majority of the footprints lack attribute information.
Building tags were derived from OSM and Google Maps. The point and polygon data from OSM, which included the building tags, were used to extract information on the use of the buildings (e.g., stores, restaurants, offices, houses, residential apartments, commercial, recreational spaces, schools, and hotels). Data on urban land use were collected from the national geospatial data portal Bhuvan (ISRO 2020). The land use map was made at 1:10,000 scale by the Ministry of Urban Development, India (MoUD) as part of the National Urban Information System (NUIS). The land use map was obtained using a Web Map Service, resampled and used as a backdrop image for manually digitising the land use polygons.
The Overpass API, which delivers custom-chosen sections of the OSM data, was used to extract existing building footprints from OSM (1000 buildings approximately). Satellite RGB orthoimages of 80 cm resolution were obtained for both study areas from Google Earth™ dated 20th November 2019.
In order to train DL models correctly and attain greater accuracy, additional 6000 building polygons were manually digitised in order to increase the number of training examples in the Palakkad data set and another 2000 were manually digitized to test the model accuracy.
A total of 15 tiles, each 8000 × 8000 pixels in size, were generated around the city of Palakkad to divide the building polygon data in each tile for training (12 tiles) and testing (3 tiles) purposes.
3 Methods
The overall approach for this research (Fig. 2) and consists of three main components: map** of building footprints, their characterisation, and their use in flood exposure assessment. The map** of the building footprints is based on the ground truth data from OSM and the satellite imagery. This was followed by data sampling for training, validation, and testing purposes. The training data is used to train an initial model with buildings, while the validation data is a portion of the training data used to describe the evaluation of the model trained when tuning the hyper-parameters to overcome issues like overfitting. This results in various results with different combinations of hyper-parameters. The testing data is used to evaluate the performance of a final tuned model based on the predictions of the model over the “unseen” data in the test set.

Conceptualisation of the research methodology. The steps include the preparation of data, sampling of the data for model training and evaluation, calculation of characteristic parameters combining these parameters into typological attributes of the buildings at an aggregated scale, and exposure assessment of the aggregated buildings using the derived typological attributes
The characterisation of the detected building footprints is the next step. We hypothesise that the characteristics of buildings are homogeneous in a neighbourhood such that the homogeneity is manifested by the morphology of the buildings. Therefore, following the detection of the building footprints, the buildings are grouped into aggregated homogeneous areas based on parameters obtained from structural data (morphological) and proxy data (open-source data such as OSM, land use data, and Google Maps). Typological (occupancy type) properties of the buildings were assigned to the homogeneous units which were then validated by local experts from the KSDMA and ICFOSS. Additional information such as average number of floors, total floor space area, building density, and percentage of built-up area are also compiled from this approach. Flood exposure assessment was done combining the 2018 flood extend maps and the generated output from the building characteristics at a homogeneous unit level.
3.1 Deep learning model set-up
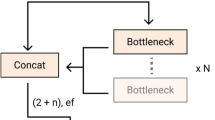
Building footprint detection in the study areas was carried out using the ResU-Net model (Diakogiannis et al. 2020) that specialises in recognising objects with limited training samples. The ResU-Net model is a semantic segmentation model inspired by the deep residual learning network (He et al. 2016) and U-Net (Ronneberger et al. 2015) which combines the benefits of both residual network and U-Net models in order to achieve higher accuracies. The ResU-Net structure (Fig. 3) contains a very deep encoding network, followed by a bridge and decoding network. The deep encoding network enables more discriminative and hierarchical feature extraction.

Schematic diagram of the ResU-Net model based on Diakogiannis et al. (2020)
which consists of three encoder blocks including a convolutional layer (Conv) (Zhang et al. 1988), a batch normalisation layer (BN) (Ioffe and Szegedy 2015), and a rectified linear unit (ReLU) (Agarap 2018) activation function, which helps learn abstract representations of the input images. The output of the three encoder blocks is connected to the corresponding decoder block through skip connections (He et al. 2016) (blue dotted arrows in Fig. 3), which help skip layers in the network and feeds the outputs to the next layers. The bridge is a residual block that consists of similar BN, Conv, and ReLU layers which connects the encoder network and decoder network.
The decoder network takes information from the bridge and the encoder network through the skip connections to produce segmentation results. The decoder network consists of decoder blocks with upsampling layers that help retain size similar to that of the features in the corresponding encoder blocks, thereby finally resulting in segmentation results of output size similar to that of the input image.
After training, the result is a binary classified image that distinguishes between building and nonbuilding pixels. On Google Colab, the whole process of training the model with the ResU-Net network was conducted on an NVIDIA P100 GPU (16 GiB VRAM) with 25 GB of RAM. Hyper-parameter tuning is a very crucial part of DL training as it controls the overall behaviour of the model. The following hyper-parameters were utilised during training: Number of epochs (the number of complete training passes over a training dataset), Batch Size (the amount of training samples utilized before updating the model), Optimisers (algorithms that update parameters like weights to minimize loss), Learning Rate (a hyper-parameter that regulates how the model changes in response to an estimated inaccuracy). The Adam optimiser was used instead of the traditional Stochastic Gradient Descent optimiser in the tests, as proposed by Bottou (2010) and Pan et al. (2020). Because of its adaptive learning potential, the former is much quicker and converges faster to decrease the loss, thus enhancing overall accuracy. To optimize training speed and avoid overfitting the network model, learning rate and weight decay settings were employed. Heat maps of probability values belonging to the classes "buildings" and "non-buildings" were generated as a result of this stage. Weighted loss functions like the Tversky Loss function can force the model to focus on learning the target building pixels, even when the target pixels constitute a relatively small part of the whole image (Lin et al. 2020). Therefore, this loss function was investigated to improve the Precision and Recall by using the beta weights (alpha and beta) that control the overall False Positives and False Negatives, respectively.
The building detection results are evaluated by measuring the number of pixels assigned as True Positives (TP), False Positives (FP), and False Negatives (FN). The thematic accuracy assessments were computed with Precision, Recall, and F1-score using metrics. The proportion of buildings accurately recognized by the suggested method is shown by Precision (Eq. 1). Recall (Eq. 2) is the fraction of the buildings in the labelled data that were successfully spotted by the technique. The F1-score (Eq. 3) is used to balance the Precision and Recall parameters. The Accuracy (Eq. 4) indicates all of the True Positive and True Negative predictions that the model correctly predicted.
3.2 Building morphological clustering
To comprehend the physical morphology of the building structures, the next step was to use spatial urban morphological metrics through the Momepy Python package, which is a library for morphometrics and quantitative analysis of urban structures (Fleischmann 2019). Twenty-two morphological measures were chosen from the library's numerous metrics (Table 1) to determine the spatial connections and morphologies of the buildings to themselves and their surroundings. The spatial morphological analysis is based on the hypothesis that buildings that are comparable in shape and size and that are close to similar ones are also likely to have the same occupancy type (Fan et al. 2014a).
After calculating the metrics of each building, the buildings were clustered, with each cluster including information on the physical shape of the buildings. The clustering is based upon the hypothesis made earlier where the attributes/characteristics are manifested by the physical morphology of the respective buildings. Clustering was accomplished via unsupervised K-Means classification, which divides the morphological metrics of the buildings into k clusters, with each observation belonging to the cluster with the closest mean (or cluster centroid). The appropriate number of clusters in the data set was determined based on the Silhouette score in combination with the input from local stakeholders as a guide. The Silhouette score approach is a metric that calculates the goodness of the clustering, where the value ranges between from -1 to 1 (Marutho et al. 2018). It effectively measures how similar an observation/object is to its cluster compared to the other clusters. A high score would indicate appropriate clustering configuration and the vice-versa would indicate too many or few clusters.
3.3 Built-up area homogenisation
After grou** the buildings into homogeneous clusters based on their physical morphologies, they still lacked the data on the likely occupancy types. If, for example, considering that 4 was the optimal number of clusters based on the Silhouette score in Palakkad, the conclusion would be that only four distinct types of buildings exist however, numerous spatially and morphologically distinct characteristics would also be assigned to these four types, which would be incorrect. Therefore, the next step was to improve the clustering with smaller homogeneous units (coupled with local expert validation, see Sect. 3.4). To address this, linear features such as road networks, river lines, and railway lines were used to subdivide the city of Palakkad into 62 homogeneous urban units (Fig. 4). These homogeneous units also follow the earlier hypothesis whereby buildings within the units/neighbourhoods manifest the built-up morphology. Using linear features as blocks to homogenize land parcels has been done earlier (Zeng et al. 2019; Kuffer et al. 2020) and thus, allow generating a sort of administrative units.

Linear features for designing homogeneous built-up areas in Palakkad
A metric (Eq. 5) was used to analyse the homogeneity of the cluster values within each homogeneous urban unit (Fan et al. 2014ab). It is not likely, for instance, that within an urban homogenous unit, there are building clusters with morphologies of agricultural buildings. The homogeneity score indicates the similarity of the building morphologies in each unit. A lower percentage score might aid in determining what additional sorts of buildings may be present in that particular unit, and further subdivide the unit into smaller homogenous ones.
3.4 Characterisation of occupancy types
The homogeneous urban units were subsequently characterised by the prevalent occupancy type using auxiliary open-source data such as building tags (from OSM and Google Maps) and land use in combination with the morphological information from the building clusters.
We first combined all the auxiliary data at the building footprint level into one shapefile. The next step is to determine the proper classification of the homogeneous urban units in terms of the occupancy types based on the amalgamated data. A majority condition rule was utilised to assert the majority characteristics to classify each individual homogeneous urban unit. These majority calculations were done in the Python environment. The classification system designed for this can be seen in Fig. 5 and the steps to perform it are as follows:
-
1.
Sort the data according to the homogeneity score.
-
2.
Based on the scoring and the majority cluster value, the associated building morphology is interpreted with the building tags.
-
(i)
If information from the building tags is not available, then skip step 2 and move to step 3 to use the land use information.
-
(ii)
If information from the building tags is available, then use it and then move to step 3.
-
(i)
-
3.
Next, the majority land use information is used for further interpretation.
-
(i)
If information from the land use map is not available, then use the building tags from step 2 as the class label instead.
-
(ii)
If information from the land use map is available, then use the information and move to step 4.
-
(i)
-
4.
Classify the built-up area units into occupancy types using the inferred/interpreted building type from steps 2 to 3.
-
5.
Sort the classified classes from mixed-built-up and then re-classify based on the distance from the central business district (CBD) or the city centre.

Classification system for building classification based on the typology of the occupancy type
One rationale for reclassifying the mixed-built-up class into residential or commercial classes (in step 5) is to help break down the former into useful information that can be combined with vulnerability curves to estimate flood vulnerability (Huizinga et al. 2017) (refer to Fig. 12b in the appendix section). The next step was to compare the obtained results with the actual situation in the city. Hence, local experts of KSDMA and ICFOSS, Kerala, collaborated to validate the cluster interpretations and overall representation of the occupancy types of the buildings. Furthermore, the experts were asked to comment on the building classification and building occupancy types. Local validation was documented at two stages: a) K-means cluster interpretation, and b) the final (re-) classification of the homogenous urban units later on.
3.5 Flood exposure assessment
Flood susceptibility maps (indicating only presence/absence) were acquired from the KSDMA (KSDMA 2020) (Fig. 1b, c). Although KSDMA has undertaken a crowdsourcing campaign to obtain flood heights during this 2018 flood event, these were not accessible at a sufficient level of detail, and therefore flood vulnerability assessment could not be conducted.
“Flood exposure", which is the quantification of EaR in flood-prone locations (De Moel et al. 2011; Koks et al. 2015), was computed by overlaying the flood susceptibility map with the homogeneous urban units and individual building maps. The proportion of the area exposed by the flood extent is determined as well as the number of buildings exposed. Another method of determining the exposure for individual building footprints was done and the results were aggregated at the homogeneous unit level.
4 Results
4.1 Building detection for the Palakkad study site
The ResU-Net model was trained over 12 tiles and the accuracy was tested on the 3 test tiles using the metrics (Eqs. 1, 2, and 3). First, the Tversky Loss was investigated with varying beta weights and other hyper-parameters like batch size and learning rate. Our experiments demonstrated that beta = 0.7 with a batch size 12 and learning rate of 1e-3 (Table 2) was the best hyper-parameter combination which gave the highest F1 score with the lowest loss. Batch sizes and learning rates affect the convergence of the loss to reach the minimal point (Kinghorn 2018), and here, batch size = 12 and learning rate = 1e-3, gave the lowest loss of 0.231. While for learning rates 1e-4 and 1e-5, we see loss of over 0.5. Table 3 shows the outputs for different batch sizes and learning rates. Therefore, for the final training in Palakkad, batch size = 12 and learning rate = 1e-3 were chosen. The generated weights were then utilised to recognise buildings in the entire region of Palakkad using the TensorFlow API. To minimise the influence of boundary artefacts on the predictions, a sliding window approach with a stride (pixel steps that a filter move by during prediction) of 24 was used to produce overlap** images over each 512 × 512 sized patches and the prediction of these were averaged to get the final segmentation results. Post-processing was performed to remove multi-polygons (instances of building polygons coinciding with another building polygon) and false-positive predictions. Figure 6a, b depicts the detected buildings against the manually mapped buildings.

a Detected buildings using the ResU-Net model. b: Manually mapped buildings against the detected buildings. c: Existing building tags from the OSM data (inside the yellow box), and d: shows the overall cluster values of each building after performing K-Means clusterisation over the morphological data of each building (see Table 4 for explanation of the classes
4.2 Amalgamation of building morphological with open-source data and local expert validation
After post-processing the detected building footprints, we calculated 22 spatial urban morphology metrics (Table 1) of the buildings using the Momepy Python library. These were used to cluster the buildings based on the K-Means unsupervised algorithm where each cluster value represents a morphological metric associated to the buildings. Figure 6c shows the types of building tags available in the OSM data. Figure 6d and Table 4 show the classification in eight clusters (chosen based on the results and suggestion of the local experts), describing the building morphology.
The cluster data in combination with auxiliary data (see Table 5) such as building tags, and land use information were used to determine the majority of urban land use type per homogeneous urban unit.
The cluster interpretation and final classification were modified to the actual setting of Palakkad based on the opinions and suggestions of the local experts who advised to employ a distance-based classification from the CBD while re-classifying the homogeneous urban units to address the Mixed-Built-Up classes. With increasing distance from the CBD, the classification of units would shift from commercial, residential urban, public, industrial, and residential rural (Appendix section, Fig. 12b).
4.3 Final classification of buildings after the classification system
Table 6: First 5 examples of the final classification based on the majority information of the auxiliary data.
The final product indicates the predominant occupancy type per homogeneous urban unit in Palakkad as seen in Fig. 7. This is done by incorporating the majority rule-based classification system as shown in Fig. 5. Overall, there are 13 occupancy types recognised by this method with additional information (Table 6) such as the number of buildings, building density, percentage of built-up area per homogeneous unit, number of floors (estimated using Google Street View and Mapillary images), and total floor space area (using the estimated number of floors with the building floor space per homogeneous unit). Such information can very well used be in the context of exposure to flooding, for example, and leverage such data to support risk assessment and risk reduction initiatives.

Occupancy types of the homogeneous urban units in Palakkad with the respective unit numbers
5 Transferability of the method in a different test area
Similar to Palakkad, 8 tiles each 8000 × 8000 in size were generated for Kollam for training (5 tiles) and testing (3 tiles) purposes. With the ability of learning feature representations (building features in this case) from previously trained models, transfer learning can become very effective when there is scarce training data by transferring the learnt weights from previous models to different locations with new data (Ravishankar et al. 2016). The weights obtained from a previous model can be applied to the class of buildings in a new area of interest, whereby it can learn on top of the pre-trained model and retrain an output layer through the target building data set. This method can shorten the training time of the model and improve model efficiency in the new area (Bai et al. 2012).
Therefore, to detect buildings in Kollam, transfer learning was used to address fewer training data. The OSM data for Kollam contains about 1100 building polygons in the training tiles but a few more building footprints were manually digitised within the five training tiles to compensate for the missing labels and to also correct some erroneous footprints within the OSM data. Using transfer learning makes more sense than simply training from scratch with label data from Kollam alone as rooftop configurations (such as colour and shape) are similar to that of Palakkad’s, thus allowing us to avoid longer training runtime (Xu et al. 2013). Transfer learning help accomplish faster and seamless detection of buildings in new study areas with just a few training samples, allowing for effective transferability of the model in other relatively similar regions. Such ability to detect buildings over a new and completely un-seen environment makes the use of such deep networks very advantageous. Using transfer learning from the weights learnt in Palakkad, the model trained over Kollam achieved over 74.6% F1-score accuracy. The predictions of buildings over Kollam can be seen in Fig. 8-A (red coloured polygons).

Results of the building detection in Kollam. a: Detected buildings data. b: The existing tags from OSM. c: The overall cluster values after K-means clusterisation
The morphological metrics from Momepy were used to cluster individual buildings in eight clusters (see Table 4 and Fig. 8c). The available building tags from OSM and Google Earth were linked to the individual building footprints, shown in Fig. 8b.
Similar to Palakkad, linear features were used to improve the homogenisation of the existing clusters. These linear features can be seen as edge boundaries in each homogeneous urban unit in Fig. 9. From the DL detection point of view, Kollam buildings were predicted with the learnt weights from Palakkad as well as trained with new building training samples, which has affected the predictions to be far better than that of Palakkad.

Occupancy types of the homogeneous urban units in Kollam with the respective unit numbers
Figure 9 shows the final classification of the occupancy types of Kollam. This result was obtained by employing the majority classification system similar to Palakkad. Also, validation by local experts was performed for Kollam to investigate, improve, and refine the occupancy type classification. The procedure to derive the homogenous units in Kollam was also timed to analyse how fast such an analysis can be done. The steps of downloading the auxiliary data, generating building footprints using DL, application of Momepy metrics and classification of clusters, amalgamating auxiliary data and interpretation through the classification system, took around one day. Despite differences in the availability of auxiliary data, the final results were comparable in the two study areas. Moreover, with additional input from the local experts and stakeholders through online interviews, it was possible to refine the classification further (refer to Fig. 12a).
6 Exposure assessment
The resulting urban classification maps of this study are intended as key input for the exposure, vulnerability and risk assessment for hazardous events such as flooding. The exposure analysis aims to calculate the number of exposed buildings, their spatial distribution, and typological attributes based on the occupancy type. This information can be used in combination with hazard intensity maps (like flood depth) and physical vulnerability curves that are linked to the occupancy types. Exposure was calculated in different ways: percentage of the homogeneous unit, percentage of the buildings in the unit, the number of buildings in the unit, the floorspace in the unit. Figure 10 gives an example of the flood exposure maps for the two locations, indicating the percentage of the homogenous units exposed and the percentage of the buildings exposed 21 homogeneous units are exposed to flooding in Palakkad and 18 in Kollam.

Flood exposure maps. a and b Percentage of homogeneous units in Palakkad (a) and Kollam (c); b and d Percentage of buildings per homogeneous units exposed in Palakkad and (b) and Kollam (d)
The differences between the percentage exposure at homogeneous unit level and the percentage of exposed buildings per unit show some interesting differences (See Fig. 10). The main reason for such differences is the non-uniform spatial distribution of the building footprints within the homogeneous units, indicative of the fact that for some units, the level of homogeneity might be too big and possibly require further subdivision. A good example of this phenomenon is given in Fig. 11. Due to the uneven distribution of buildings within the unit, 19% of the buildings aggregated are exposed, whereas 37% of the entire homogeneous unit is exposed to flooding. As a result, the final exposure assessment results will be the aggregated footprint level values recorded at the homogeneous unit level.

Flood exposure to homogeneous units against the building footprints in Palakkad
7 Discussion
As discussed in 4.1, the best result was given by beta = 0.7 as the accuracy peaked in terms of highest F1 score and lowest loss by targeting the pixels of buildings with FNs. The reason for this is that greater beta weights prevent the model from learning the training data adequately, and as a result, the loss value plateaus during training, thereby decreasing the total accuracy. Even if the Recall increases, adding greater weights does not guarantee that the class imbalance will be handled linearly, as lower Precision decreases the F1 score, resulting in a lower F1 score across all batch sizes. Therefore, a combination of the hyper-parameters that gave the best balance between Precision and Recall was considered for the final training. Furthermore, the poor performance of loss values with lower learning rates of 1e-4 and 1e-5 demonstrates that such lower learning rates are ineffective in updating learned weights and are unable to appropriately optimize training with the existing data. Lower learning rates can deteriorate updating of the weights as training progresses slowly due to tiny updates to the weights in the neural network this procedure reduces the model's overall capacity to train optimally and obstructs its potential performance in achieving better accuracy.
There were quite a few FP predictions due to the similar spectral characteristics of building roofs and roads in Palakkad. This is also explained by the low Precision scores as seen in Table 2. However, with appropriate post-classification removal of these FPs, such non-building artefact issues could be easily eliminated.
As the cluster values of each homogeneous unit depict the morphological characteristics of buildings, some units showed low homogeneity scores (e.g., units 2, 3, and 4 for example in Table 6). A reason for this is that some predictions made by the DL model result in irregular polygonal building features, which affect the building morphological metric calculation. Fan (2014a) and Qi and Li (2008) also state that homogeneity scoring is suitable for representing similar buildings but is dependent on the detail of the polygonal geometry of the buildings.
The use of an urban land use map, which was available for the study areas, is not a requirement for the methodology. Although a very useful input, the use of auxiliary information from OSM and Google Maps tags, building morphological information based on the spatial characteristics, and the homogeneity scores of the morphological clusters, are decisive in determining the classification of the buildings within each homogeneous unit. The approach is also applicable in areas where an urban land use map is not available. Also, the knowledge from local experts, although extremely useful, is not essential in the methodology. Their suggestions helped to improve the classification of the built-up area into building occupancy types. There were challenges that were met such as subjective classification of the buildings. The involvement of local experts in the interpretation of the automated procedure is a useful alternative for the time-consuming ground survey using VGI. As this method is aiming to provide fast results, it therefore seems as an important add-on to the automated procedure.
The detail of characterisation of the buildings is another point for discussion. Whereas it is possible to map buildings at an individual level, their characterisation using the approach outlined in this research does not allow the characterisation of each individual building. Therefore, the approach was carried out at a homogeneous level to counteract this drawback, but this also brought forth another issue where the rather coarse homogenous units that have still quite variation in building density implying that they are not so homogenous after all, and perhaps could be subdivided more.
For each of the homogeneous units, important characteristics for the evaluation of exposure, vulnerability, and risk to natural and anthropogenic disaster was obtained: occupancy types, number of buildings, average number of floors, total floorspace area, and percentage of built-up area. These can be used to estimate population data per homogeneous unit (Lwin and Murayama 2009), thus also forming the basis for population exposure and risk assessment.
In the use of OSM data, some well-known problems were encountered concerning positional accuracy, data quality, and lack of attribute information. The tags of residential buildings are mostly not available, resulting in a strong bias towards non-residential buildings, with an emphasis on commercial buildings. Even when there are building tags available for other uses, for example, schools or religious buildings, the application of the majority rule per homogeneous unit often makes that these are outnumbered by other land uses. Due to the small number of individual tags present within a homogeneous unit, sometimes using the majority tags might not be the best way to represent the actual building occupancy, also in addition to the fact that certain units may be rather large in comparison to the relatively small number of buildings.
Another limitation witnessed is the interpretation of the classification system, which can change in different types of settlements and countries, and hence would require local validation every time. Because of this reason, the methodology cannot be fully automated as there will always be a point where local knowledge validation would be necessary to authenticate the results. A possible solution to overcome this problem is streamlining the rules for different types of settlements and countries through organisational efforts at a meta-level. Nevertheless, this is beyond the scope of this study as it would require a large sample of case study cities. However, the agreement of the local stakeholders' on the various occupancy types in Palakkad ruled out favour of the methodology's overall applicability in data-scarce regions, thus encouraging to test the reproducibility of the approach in Kollam.
One of the crucial questions which this methodology also attempts to answer is to link the building characteristics of occupancy types to the physical vulnerability of buildings. One of the main requirements for calculating the vulnerability is to link these occupancy types to physical vulnerability curves such as the global flood-depth damage curves reported by Huizinga et al. (2017). The method proposed in this study can be applied for rapid initial elements-at-risk characterisation at a regional to city-scale, and the results of the exposure and vulnerability assessment can be subsequently used in loss estimation, risk assessment, and planning of measures and policies to reduce, mitigate, and avoid risk of hazards.
8 Conclusion
The research attempted to provide a fast and preliminary approach for elements-at-risk map** by develo** a semi-automated detection and characterisation method. The research objectives were achieved by first detecting buildings in Palakkad with an F1 score of 76%, followed by homogenising the buildings into units with linear features such as road networks as boundaries. The building morphological characteristics were then assessed using the Momepy approach, and the results were used to develop a number of clusters with similar building characteristics. These were combined with auxiliary information such as building tags from OSM and Google Maps, and a classification system was applied to determine the main occupancy type of the homogeneous units. Moreover, we also tested the reproducibility of the methodology in a different city, where we achieved an F1 score of 74% in building detection and building occupancy type as the characterisation output. The building maps were then used to quantify flood exposure.
This study is one of the first attempts at showing the possibility to obtain EaR information/data as building occupancy type using remote sensing image data in combination with freely available data on geotags and OSM, by means of the state-of-the-art DL models, open-source remote sensing products, and validation with local expert/stakeholder. Such data can be extremely relevant in flooding exposure with information such as building density, the average number of floors, total floor space area, and can be used to support risk assessment and risk reduction measures.
However, certain challenges still remain such as the availability and accessibility to quality open-source data in other countries, the need for local experts to address and refine the building occupancy type classifications, and the inclusion of AI in fully automatising the classification system. Nevertheless, the research does enable the development of databases for buildings as EaR in data-scarce regions, which is the first step for estimating hazard vulnerability, risk assessment, rescue missions, and rehabilitation.
This methodology also has implications for dasymetric map** in develo** nations or regions that lack building typological information. With our approach, it became evident that OSM labels for building tags are critical, but that such information was lacking in some areas of the cities of Palakkad and Kollam, emphasizing the need to update building tag information and make it publicly available for further research. Another significant aspect of the study was to remark on the rapid or timely map** of buildings using open-source data in real-world crises to swiftly develop an EaR database for effective risk reduction and disaster relief efforts. In the future, we would be experimenting with better-curated data (for example the WSF-3D) and more complex characterisation algorithms to fully automatise this approach. We would also be looking towards classifying more attributes apart from the occupancy types for better use in vulnerability assessment like building materials. Furthermore, efforts will also be spent on scaling this approach for more number of hazards including landslides for multi-hazard exposure and vulnerability assessment.
References
Agarap AF (2018) Deep learning using rectified linear units (ReLU). https://arxiv.org/abs/1803.08375v2
Alidoost F, Arefi H (2018) A CNN-based approach for automatic building detection and recognition of roof types using a single aerial image. PFG - J Photogramm Remote Sens Geoinf Sci 86(5–6):235–248. https://doi.org/10.1007/s41064-018-0060-5
Ariza-López FJ, García-Balboa JL, Alba-Fernández V, Rodríguez-Avi J, Ureña-Cámara M (2014) Quality assessment of the OSM data from the map** party of Baeza (Spain). In: Accuracy 2014—Proceedings of the 11th international symposium on spatial accuracy assessment in natural resources and environmental sciences. International Spatial Accuracy Research Association (ISARA)
Badrinarayanan V, Kendall A, Cipolla R (2017) SegNet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell 39(12):2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615
Bai S, Wang J, Zhang Z, Cheng C (2012) Combined landslide susceptibility map** after Wenchuan earthquake at the Zhouqu segment in the Bailongjiang Basin, China. CATENA 99:18–25. https://doi.org/10.1016/J.CATENA.2012.06.012
Barrington-Leigh C, Millard-Ball A (2017) The world’s user-generated road map is more than 80% complete. PLoS ONE 12(8):e0180698. https://doi.org/10.1371/journal.pone.0180698
Bennett, C. and C. L. (2018). Landslide kills nine in Palakkad | Kochi News - Times of India. https://timesofindia.indiatimes.com/city/kochi/landslide-kills-nine-in-palakkad/articleshow/65433001.cms
Blaschke T (2010) Object based image analysis for remote sensing. ISPRS J Photogramm Remote Sens 65:2–16. https://doi.org/10.1016/j.isprsjprs.2009.06.004
Bottou L (2010) Large-scale machine learning with stochastic gradient descent. In: Proceedings of COMPSTAT 2010—19th international conference on computational statistics, keynote, invited and contributed papers (pp 177–186). Physica-Verlag HD. https://doi.org/10.1007/978-3-7908-2604-3_16
Cerri M, Steinhausen M, Kreibich H, Schröter K (2021) Are OpenStreetMap building data useful for flood vulnerability modelling? Nat Hazard 21(2):643–662. https://doi.org/10.5194/nhess-21-643-2021
Cohen JP, Ding W, Kuhlman C, Chen A, Di L (2016) Rapid building detection using machine learning. Appl Intell 45(2):443–457. https://doi.org/10.1007/s10489-016-0762-6
COI (1981) Census of India. District census handbook, Coimbatore, Tamilnadu, Series-34(Part XII-B), 232. https://censusindia.gov.in/2011census/dchb/KerlaA.html
De Moel H, Aerts JCJH, Koomen E (2011) Development of flood exposure in the Netherlands during the 20th and 21st century. Glob Environ Chang 21(2):620–627. https://doi.org/10.1016/j.gloenvcha.2010.12.005
Diakogiannis FI, Waldner F, Caccetta P, Wu C (2020) ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data. ISPRS J Photogramm Remote Sens 162:94–114. https://doi.org/10.1016/j.isprsjprs.2020.01.013
Dwyer, C. (2018). Monsoon Hammers India With “unprecedented flood havoc,” killing scores of people : NPR. https://www.npr.org/2018/08/16/639224478/monsoon-hammers-india-with-unprecedented-flood-havoc-killing-scores-of-people?t=1623498005548
Esch T, Marconcini M, Felbier A, Roth A, Heldens W, Huber M et al (2013) Urban footprint processor-Fully automated processing chain generating settlement masks from global data of the TanDEM-X mission. IEEE Geosci Remote Sens Lett 10(6):1617–1621. https://doi.org/10.1109/LGRS.2013.2272953
Eshrati L, Mahmoudzadeh A, Taghvaei M (2015) Multi hazards risk assessment, a new methodology. Int J Health Syst Disaster Manage 3(2):79. https://doi.org/10.4103/2347-9019.151315
Fan H, Zipf A, Fu Q (2014a) Estimation of building types on openstreetmap based on urban morphology analysis. Lecture notes in geoinformation and cartography, pp 19–35. Kluwer Academic Publishers. https://doi.org/10.1007/978-3-319-03611-3_2
Fan H, Zipf A, Fu Q, Neis P (2014b) Quality assessment for building footprints data on OpenStreetMap. Int J Geogr Inf Sci 28(4):700–719. https://doi.org/10.1080/13658816.2013.867495
Fleischmann, M. (2019). momepy: Urban morphology measuring toolkit. J of Open Source Softw, 4(43), 1807. https://doi.org/10.21105/joss.01807
Foody GM, See L, Fritz S, Van Der Velde M, Perger C, Schill C et al (2015) Accurate attribute map** from volunteered geographic information: issues of volunteer quantity and quality. Cartogr J 52(4):336–344. https://doi.org/10.1080/00087041.2015.1108658
Fu Y, Ye Z, Deng J, Zheng X, Huang Y, Yang W et al (2019) Finer resolution map** of marine aquaculture areas using world view-2 imagery and a hierarchical cascade convolutional neural network. Remote Sens 11(14):1678. https://doi.org/10.3390/rs11141678
Gei, C., Wurm, M., & Taubenböck, H. (2017). Towards large-area morphologic characterization of urban environments using the TanDEM-X mission and Sentinel-2. 2017 Joint urban remote sensing event, JURSE 2017. Institute of Electrical and Electronics Engineers Inc. https://doi.org/10.1109/JURSE.2017.7924543
Geis C, Leichtle T, Wurm M, Pelizari PA, Standfus I, Zhu XX et al (2019) Large-area characterization of urban morphology - map** of built-up height and density using TanDEM-X and sentinel-2 Data. IEEE J Sel Top Appl Earth Obs Remote Sens 12(8):2912–2927. https://doi.org/10.1109/JSTARS.2019.2917755
Geiß C, Schauß A, Riedlinger T, Dech S, Zelaya C, Guzmán N et al (2017) Joint use of remote sensing data and volunteered geographic information for exposure estimation: evidence from Valparaíso Chile. Nat Hazards 86(1):81–105. https://doi.org/10.1007/s11069-016-2663-8
Ghorbanzadeh O, Blaschke T, Gholamnia K, Meena SR, Tiede D, Aryal J (2019) Evaluation of different machine learning methods and deep-learning convolutional neural networks for landslide detection. Remote Sens 11(2):196. https://doi.org/10.3390/rs11020196
Ghorbanzadeh O, Tiede D, Wendt L, Sudmanns M, Lang S (2021) Transferable instance segmentation of dwellings in a refugee camp - integrating CNN and OBIA. Eur J Remote Sens 54(sup1):127–140. https://doi.org/10.1080/22797254.2020.1759456
Gill JC, Malamud BD (2014) Reviewing and visualizing the interactions of natural hazards. Rev Geophys 52:680–722. https://doi.org/10.1002/2013RG000445
Goodchild MF (2007) Citizens as sensors: the world of volunteered geography. GeoJournal 69:211–221. https://doi.org/10.1007/s10708-007-9111-y
Graff K, Lissak C, Thiery Y, Maquaire O, Costa S, Medjkane M, Laignel B (2019) Characterization of elements at risk in the multirisk coastal context and at different spatial scales: Multi-database integration (normandy, France). Appl Geogr. https://doi.org/10.1016/j.apgeog.2019.102076
Guirado E, Tabik S, Alcaraz-Segura D, Cabello J, Herrera F (2017) Deep-learning convolutional neural networks for scattered shrub detection with Google Earth imagery. http://arxiv.org/abs/1706.00917
Hasan, R. C., A’Zad Rosle, Q., Asmadi, M. A., & Kamal, N. A. M. (2018). Extraction of element at risk for landslides using remote sensing method. International archives of the photogrammetry, remote sensing and spatial information sciences - ISPRS archives, 42(4/W9), 181–188. International Society for Photogrammetry and Remote Sensing. https://doi.org/10.5194/isprs-archives-XLII-4-W9-181-2018
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE computer society conference on computer vision and pattern recognition, 2016-Decem, 770–778. IEEE Computer Society. https://doi.org/10.1109/CVPR.2016.90
Huizinga J, de Moel H, Szewczyk W (2017) Global flood depth-damage functions: methodology and the database with guidelines. Jt Res Centre. https://doi.org/10.2760/16510
Husen SNRM, Idris NH, Ishak MHI (2018) The quality of OpenStreetMap in Malaysia: A preliminary assessment. International archives of the photogrammetry, remote sensing and spatial information sciences - ISPRS archives, 42(4/W9), 291–298. International Society for Photogrammetry and Remote Sensing. https://doi.org/10.5194/isprs-archives-XLII-4-W9-291-2018
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. In: 32nd international conference on machine learning, ICML 2015, 1, 448–456. International Machine Learning Society (IMLS). https://arxiv.org/abs/1502.03167v3
ISRO. (2020). Bhuvan. Indian Geo Platform of ISRO. Retrieved from https://bhuvan.nrsc.gov.in/home/index.php
Karpatne A, Jiang Z, Vatsavai RR, Shekhar S, Kumar V (2016) Monitoring land-cover changes: a machine-learning perspective. IEEE Geosci Remote Sens Mag 4(2):8–21. https://doi.org/10.1109/MGRS.2016.2528038
Kerala State Spatial Data Infrastructure. (2021). Mapathon Keralam. Retrieved January 30, 2022, from 2021 website: https://mapathonkeralam.in/%E0%B4%AE%E0%B4%BE%E0%B4%AA%E0%B5%8D%E0%B4%AA%E0%B4%A4%E0%B5%8D%E0%B4%A4%E0%B5%8B%E0%B5%BA
Kinghorn, D. (2018). GPU Memory Size and Deep Learning Performance (batch size) 12GB vs 32GB -- 1080Ti vs Titan V vs GV100. Retrieved January 23, 2022, from Puget Systems website: https://www.pugetsystems.com/labs/hpc/GPU-Memory-Size-and-Deep-Learning-Performance-batch-size-12GB-vs-32GB----1080Ti-vs-Titan-V-vs-GV100-1146/
Koks EE, Jongman B, Husby TG, Botzen WJW (2015) Combining hazard, exposure and social vulnerability to provide lessons for flood risk management. Environ Sci Policy 47:42–52. https://doi.org/10.1016/j.envsci.2014.10.013
KSDMA. (2020). Kerala State Disaster Management Authority. 1–27. Retrieved from https://sdma.kerala.gov.in/maps/
Kuffer M, Thomson DR, Boo G, Mahabir R, Grippa T, Vanhuysse S et al (2020) The role of earth observation in an integrated deprived area map** “system” for low-to-middle income countries. Remote Sens 12:982. https://doi.org/10.3390/rs12060982
Lin TY, Goyal P, Girshick R, He K, Dollar P (2020) Focal loss for dense object detection. IEEE Trans Pattern Anal Mach Intell 42(2):318–327. https://doi.org/10.1109/TPAMI.2018.2858826
Lwin, K., & Murayama, Y. (2009). A GIS approach to estimation of building population for micro‐spatial analysis. Transactions in GIS, 13(4), 401–414. Retrieved from https://cdema.org/virtuallibrary/images/AGISApproachtoEstimationofBuilding.pdf
Marutho D, Hendra Handaka S, Wijaya E, Muljono (2018) The determination of cluster number at k-mean using elbow method and purity evaluation on headline news. In: Proceedings - 2018 international seminar on application for technology of information and communication: creative technology for human life, ISemantic 2018, 533–538. https://doi.org/10.1109/ISEMANTIC.2018.8549751
Mobasheri A, Zipf A, Francis L (2018) OpenStreetMap data quality enrichment through awareness raising and collective action tools—experiences from a European project. Geo-Spat Inf Sci 21(3):234–246. https://doi.org/10.1080/10095020.2018.1493817
Pan Z, Xu J, Guo Y, Hu Y, Wang G (2020) Deep learning segmentation and classification for urban village using a worldview satellite image based on U-net. Remote Sens 12(10):1574. https://doi.org/10.3390/rs12101574
Panek J (2015) How participatory map** can drive community empowerment - a case study of Koffiekraal South Africa. South Afr Geogr J 97(1):18–30. https://doi.org/10.1080/03736245.2014.924866
Panek J, Netek R (2019) Collaborative map** and digital participation: a tool for local empowerment in develo** countries. Information (switzerland). https://doi.org/10.3390/info10080255
Papathoma-Köhle M, Neuhäuser B, Ratzinger K, Wenzel H, Dominey-Howes D (2007) Elements at risk as a framework for assessing the vulnerability of communities to landslides. Nat Hazards Earth Syst Sci 7(6):765–779. https://doi.org/10.5194/nhess-7-765-2007
Papnoi A, Surve A, Silgiri P, Wankhede A, Raskar R (2017) Vulnerability and risk assessment of transport infrastructure of navi Mumbai for disaster risk management and planning. 1–6.
Parker, O. P. (2013). Object‐based segmentation and machine learning classification for landslide detection from multi‐temporal worldview‐2 imagery
Pesaresi M, Gerhardinger A, Kayitakire F (2008) A robust built-up area presence index by anisotropic rotation-invariant textural measure. IEEE J Sel Top Appl Earth Obs Remote Sens 1(3):180–192. https://doi.org/10.1109/JSTARS.2008.2002869
Poser K, Dransch D (2010) Volunteered geographic information for disaster management with application to rapid flood damage estimation. Geomatica 64(1):89–98
Qi HB, Li ZL (2008) An approach to building grou** based on hierarchical constraints. ISPRS Arch 37(B2):449–454
Qi W, Wei M, Yang W, Xu C, Ma C (2020) Automatic map** of landslides by the ResU-Net. Remote Sens. https://doi.org/10.3390/RS12152487
Raskar-phule R, Choudhury D (2015) Vulnerability map** for disaster assessment using ArcGIS tools and techniques for Mumbai City , India. 15th Esri India user conference, 1–9. Retrieved from https://www.esri.in/~/media/esri-india/files/pdfs/events/uc2015/proceedings/papers/UCP062.pdf
Ravishankar H, Sudhakar P, Venkataramani R, Thiruvenkadam S, Annangi P, Babu N, Vaidya V (2016). Understanding the mechanisms of deep transfer learning for medical images. Lecture notes in computer science (Including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), 10008 LNCS, 188–196. Springer. https://doi.org/10.1007/978-3-319-46976-8_20
Ribeiro A, Fonte CC (2015) A methodology for assessing openstreetmap degree of coverage for purposes of land cover map**. ISPRS Ann Photogramm, Remote Sens Spatial Inf Sci 2(3W5):297–303. https://doi.org/10.5194/isprsannals-II-3-W5-297-2015
Ronneberger O, Fischer P, Brox T (2015) U-net: convolutional networks for biomedical image segmentation. Lecture notes in computer science (Including subseries lecture notes in artificial intelligence and lecture notes in bioinformatics), 9351, 234–241. https://doi.org/10.1007/978-3-319-24574-4_28
Sameen MI, Pradhan B (2019) Landslide detection using residual networks and the fusion of spectral and topographic information. IEEE Access 7:114363–114373. https://doi.org/10.1109/ACCESS.2019.2935761
Sarabandi P, Kiremidjian A S (2008) Building inventory information extraction from remote sensing data and statistical models. In: 14th world conference on earthquake engineering, Bei**g, China, 1–8
Schnebele E, Cervone G (2013) Improving remote sensing flood assessment using volunteered geographical data. Nat Hazards Earth Syst Sci 13(3):669–677. https://doi.org/10.5194/nhess-13-669-2013
Stewart C, Lazzarini M, Luna A, Albani S (2020) Deep learning with open data for desert road map**. Remote Sens. https://doi.org/10.3390/rs12142274
Stewart R, Urban M, Duchscherer S, Kaufman J, Morton A, Thakur G et al (2016) A Bayesian machine learning model for estimating building occupancy from open source data. Nat Hazards 81(3):1929–1956. https://doi.org/10.1007/s11069-016-2164-9
Sun Y, Shahzad M, Zhu XX (2017) Building height estimation in single SAR image using OSM building footprints. In: 2017 Joint Urban Remote Sensing Event. https://doi.org/10.1109/JURSE.2017.7924549
Sur U, Singh P, Meena SR (2020). Landslide susceptibility assessment in a lesser Himalayan road corridor (India) applying fuzzy AHP technique and earth-observation data. https://www.tandfonline.com/Action/JournalInformation?Show=aimsScope&journalCode=tgnh20#.VsXodSCLRhE, 11(1), 2176–2209. https://doi.org/10.1080/19475705.2020.1836038
Sur U, Singh P, Meena SR, Singh TN (2022) Predicting landslides susceptible zones in the lesser himalayas by ensemble of per pixel and object-based models. Remote Sens 14(8):1953. https://doi.org/10.3390/RS14081953
Wu G, Shao X, Guo Z, Chen Q, Yuan W, Shi X, Shibasaki R (2018) Automatic building segmentation of aerial imagery usingmulti-constraint fully convolutional networks. Remote Sens. https://doi.org/10.3390/rs10030407
Wu T, Luo J, Zhou Y, Wang C, ** J, Fang J (2020) Geo-Object-based land cover map update for high-spatial-resolution remote sensing images via change detection and label transfer. Remote Sens 12(1):174. https://doi.org/10.3390/rs12010174
**e Y, Cai J, Bhojwani R, Shekhar S, Knight J (2020) A locally-constrained YOLO framework for detecting small and densely-distributed building footprints. Int J Geogr Inf Sci 34(4):777–801. https://doi.org/10.1080/13658816.2019.1624761
Xu C, Xu X, Dai F, Wu Z, He H, Shi F et al (2013) Application of an incomplete landslide inventory, logistic regression model and its validation for landslide susceptibility map** related to the May 12, 2008 Wenchuan earthquake of China. Nat Hazards 68(2):883–900. https://doi.org/10.1007/S11069-013-0661-7/FIGURES/7
Yi Y, Zhang Z, Zhang W, Zhang C, Li W, Zhao T (2019) Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens 11(15):1774. https://doi.org/10.3390/rs11151774
Zeng J, Qian Y, Ren Z, Xu D, Wei X (2019) Road landscape morphology of valley city blocks under the concept of “open block”-taking lanzhou city as an example. Sustainability (switzerland). https://doi.org/10.3390/su11226258
Zhang L, Pfoser D (2019) Using openstreetmap point-of-interest data to model urban change—a feasibility study. PLoS ONE 14(2):e0212606. https://doi.org/10.1371/journal.pone.0212606
Zhang, W., Tanida, J., Itoh, K., & Ichioka, Y. (1988). Shift-invariant pattern recognition neural network and its optical architecture. In: Proceedings of annual conference of the Japan Society of Applied Physics, 2147–2151. Montreal, CA.
Zhou K, Chen Y, Smal I, Lindenbergh R (2019) Building segmentation from airborne vhr images using mask r-cnn. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences - ISPRS Archives, 42(2/W13), 155–161. International Society for Photogrammetry and Remote Sensing. https://doi.org/10.5194/isprs-archives-XLII-2-W13-155-2019
Zhou X (2018) Understanding the convolutional neural networks with gradient descent and backpropagation. J Phys: Conf Ser 1004(1):12028. https://doi.org/10.1088/1742-6596/1004/1/012028
Zhu XX, Tuia D, Mou L, **a GS, Zhang L, Xu F, Fraundorfer F (2017) Deep learning in remote sensing: a comprehensive review and list of resources. IEEE Geosci Remote Sens Mag 5:8–36. https://doi.org/10.1109/MGRS.2017.2762307
Funding
Open access funding provided by Università degli Studi di Padova within the CRUI-CARE Agreement. This work was supported by the ITC Excellence Scholarship. Author K.B. received research support from the Faculty of Geo-Information Science and Earth Observation (ITC), University of Twente, the Netherlands.
Author information
Authors and Affiliations
Contributions
KB, CW, and JW contributed to the study conception and design. Material preparation, data collection and analysis were performed by KB and JW. The first draft of the manuscript was written by KB, CW, and JW, and SRM assisted in the reviewing of the previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A1: Schematic diagram for local expert questioning and distance from CBD classification
Appendix A1: Schematic diagram for local expert questioning and distance from CBD classification
See Fig. 12.

a Diagram of the local expert questioning procedure and b distance from the CBD-based classification
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bhuyan, K., Van Westen, C., Wang, J. et al. Map** and characterising buildings for flood exposure analysis using open-source data and artificial intelligence. Nat Hazards 119, 805–835 (2023). https://doi.org/10.1007/s11069-022-05612-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11069-022-05612-4