
Abstract
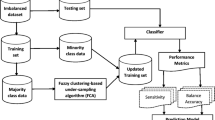
The era of big data has arrived, making it impossible for traditional machine learning algorithms to perform training in a stand-alone computing environment. In this paper, we propose a method for imbalanced binary classification of large-scale datasets based on undersampling and ensemble. More specifically, our method first adaptively partitions the majority class big data into k clusters, followed by undersampling to create k balanced datasets. Subsequently, k base classifiers are trained on each balanced dataset and are combined to perform the final prediction. Existing undersampling methods randomly select a subset of the majority class; thus, important instances may be lost during the process. In contrast, our proposed fuzzy data reduction scheme selects informative instances from each cluster, preventing information loss. Traditional ensemble methods have negative correlations between the base classifiers, whereas our proposed classifier fusion scheme fuses the base classifiers using fuzzy integral to facilitate modeling the relations between the base classifiers. The proposed algorithm is evaluated on six imbalanced large data sets and compared with state-of-the-art undersampling and ensemble methods, including the synthetic minority oversampling technique bagging (SMOTE-Bagging), SMOTE-Boost, and Binary Ensemble Classification for Imbalanced big data based on MapReduce and Upper sampling (BECIMU). Quantitative evaluations and theoretical analysis demonstrate that the proposed method outperforms the three state-of-the-art methods by 1.47%, 2.00% and 2.03%, and by 3.15%, 2.15% and 2.52%, in terms of the average G-mean and AUC-area, respectively.



Similar content being viewed by others


Notes
k is automatically determined by the clustering algorithm.
References
Abdallah ACB, Frigui H, Gader P (2012) Adaptive local fusion with fuzzy integrals. IEEE Trans Fuzzy Syst 20(5):849–864
Abdi L, Hashemi S (2015) To combat multi-class imbalanced problems by means of over-sampling and boosting techniques. Soft Comput 19:3369–3385
Bach M, Werner A, Palt M et al (2019) The proposal of undersampling method for learning from imbalanced datasets. Proc Comput Sci 159:125–134
Batista G, Prati R, Monard M (2004) A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor Newslett 6(1):20–29
Chawla NV, Lazarevic A, Hall LO et al (2003a) SMOTEBoost: Improving prediction of the minority class in boosting. Eur Conf Knowl Discov Databases 107–119
Chawla NV, Lazarevic A, Hall LO et al (2003b) SMOTEBoost: improving prediction of the minority class in boosting. Berlin, Heidelberg, European conference on principles of data mining and knowledge discovery. Springer, pp 107–119
Chen Z, Lin T, **a X et al (2018) A synthetic neighborhood generation based ensemble learning for the imbalanced data classification. Appl Intell 48:2441–2457
Chen D, Wang XJ, Zhou CJ et al (2019) The distance-based balancing ensemble method for data with a high imbalance ratio. IEEE Access 7:68940–68956
Cover T, Hart P (1967) Nearest neighbor pattern classification. IEEE Trans Inform Theory 13(1):21–27
Ding SF, Zhang N, Zhang J et al (2017) Unsupervised extreme learning machine with representational features. Int J Mach Learn Cybern 8(2):587–595
Dua D, Graff C (2019) UCI machine learning repository. University of California, School of Information and Computer Science, Irvine, CA. http://archive.ics.uci.edu/ml
Fan Q, Wang Z, Gao DQ (2016) One-sided dynamic undersampling no-propagation neural networks for imbalance problem. Eng Appl Artif Intell 53:62–73
Galar M, Fernández A, Barrenechea E et al (2012) A review on ensembles for the class imbalance problem: bagging-, boosting-, and hybrid-based approaches. IEEE Trans Syst Man Cybern Part C Appl Rev 42(4):463–484
Galar M, Fernández A, Barrenechea E et al (2013) EUSBoost: enhancing ensembles for highly imbalanced data-sets by evolutionary undersampling. Patt Recogn 46:3460–3471
García S, Herrera F (2009) Evolutionary under-sampling for classification with imbalanced data sets: proposals and taxonomy. Evol Comput 17(3):275–306
Guo HP, Zhou J, Wu CA (2020) Ensemble learning via constraint projection and undersampling technique for class-imbalance problem. Soft Comput 24:4711–4727
Huang GB, Zhu QY, Siew CK (2006) Extreme learning machine: theory and applications. Neurocomputing 70:489–501
Huang Y, ** Y, Li Y et al (2020) Towards imbalanced image classification: a generative adversarial network ensemble learning method. IEEE Access 8:88399–88409
Japkowicz N (2000) The class imbalance problem: significance and strategies. In: Proceedings of the 2000 international conference on artificial intelligence, pp 111–117
Japkowicz N, Stephen S (2002) The class imbalance problem: a systematic study. Intell Data Anal 6(5):429–449
Kang Q, Chen XS, Li SS et al (2017) A noise-filtered under-sampling scheme for imbalanced classification. IEEE Trans Cybern 47(12):4263–4274
Keller JR, Gray MR, Givens JA (2009) A fuzzy k-nearest neighbor algorithm. IEEE Trans Knowl Data Eng 21(9):1263–1284
Koziarski M (2020) Radial-based undersampling for imbalanced data classification. Patt Recogn 102:107262. https://doi.org/10.1016/j.patcog.2020.107262
Li Q, Li G, Niu W et al (2017) Boosting imbalanced data learning with Wiener process oversampling. Front Comput Sci 11:836–851
Liang T, Xu J, Zou B et al (2021) LDAMSS: Fast and efficient undersampling method for imbalanced learning. Appl Intell. https://doi.org/10.1007/s10489-021-02780-x
Lim P, Goh CK, Tan KC (2017) Evolutionary cluster-based synthetic oversampling ensemble (ECO-Ensemble) for imbalance learning. IEEE Trans Cybern 47(9):2850–2861
Lin WC, Tsai CF, Hu YH et al (2017) Clustering-based undersampling in class-imbalanced data. Inform Sci 409–410:17–26
Liu XY, Wu JX, Zhou ZH (2009) Exploratory undersampling for class-imbalance learning. IEEE Trans Syst Man Cybern Part B Cybern 39(2):539–550
Lu W, Li Z, Chu JH (2017) Adaptive ensemble undersampling-boost: a novel learning framework for imbalanced data. J Syst Softw 132:272–282
Murtaza G, Shuib L, Wahab AWA et al (2020) Deep learning-based breast cancer classification through medical imaging modalities: state of the art and research challenges. Artif Intell Rev 53:1655–1720
Ni P, Zhao SY, Wang XZ et al (2019) PARA: A positive-region based attribute reduction accelerator. Inform Sci 503:533–550
Ni P, Zhao SY, Wang XZ et al (2020) Incremental feature selection based on fuzzy rough sets. Inform Sci 536:185–204
Ofek N, Rokach L, Stern R et al (2017) Fast-CBUS: A fast clustering-based undersampling method for addressing the class imbalance problem. Neurocomputing 243:88–102
Pelleg D, Moore A (2000) X-means: extending K-means with efficient estimation of the number of clusters. In: Proceedings of the seventeenth international conference on machine learning (ICML 2000), pp 1–8
Raghuwanshi BS, Shukla S (2019) Class imbalance learning using underbagging based kernelized extreme learning machine. Neurocomputing 329:172–187
Ren FL, Cao P, Li W et al (2017) Ensemble based adaptive over-sampling method for imbalanced data learning in computer aided detection of microaneurysm. Comput Med Imag Graph 55:54–67
Seiffert C, Khoshgoftaar TM, Hulse JV et al (2010) RUSBoost: a hybrid approach to alleviating class imbalance. IEEE Trans Syst Man Cybern Part A Syst Humans 40(1):185–197
Sun Z, Song Q, Zhu X et al (2015) A novel ensemble method for classifying imbalanced data. Patt Recogn 48(5):1623–1637
Sun B, Chen H, Wang JD et al (2018) Evolutionary under-sampling based bagging ensemble method for imbalanced data classification. Front Comput Sci 12:331–350
Sun L, Zhang XY, Qian YH et al (2019a) Feature selection using neighborhood entropy-based uncertainty measures for gene expression data classification. Inform Sci 502:18–41
Sun L, Zhang XY, Qian YH et al (2019b) Joint neighborhood entropy-based gene selection method with fisher score for tumor classification. Appl Intell 49(4):1245–1259
Tomek I (1976) Two modifications of CNN. IEEE Trans Syst Man Commun SMC 6:769–772
Triguero I, Galar M, Vluymans S et al (2015) Evolutionary undersampling for imbalanced big data classification. In: IEEE congress on evolutionary computation (CEC), 25–28 May 2015. Sendai, Japan, pp 715–722
Triguero I, Galar M, Merino D et al (2016) Evolutionary undersampling for extremely imbalanced big data classification under Apache Spark. In: IEEE congress on evolutionary computation (CEC), 24–29 July 2016. Vancouver, BC, Canada, pp 640–647
Triguero I, Galar M, Bustince H et al (2017) A first attempt on global evolutionary undersampling for imbalanced big data. In: IEEE congress on evolutionary computation (CEC), 5–8 June 2017. San Sebastian, Spain, pp 2054–2061
Vuttipittayamongkol P, Elyan E (2020) Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inform Sci 509:47–70
Wang DW, Ding W (2015) A hierarchical pattern learning framework for forecasting extreme weather events. In: 2015 IEEE international conference on data mining, 14–17 Nov, Atlantic City, NJ, USA, pp 1021–1025
Wang S, Yao X (2009) Diversity analysis on imbalanced data sets by using ensemble models. In: IEEE symposium on computational intelligence and data mining. Nashville, TN, USA, pp 324–331
Wang CZ, Huang Y, Shao MW et al (2019) Fuzzy rough set-based attribute reduction using distance measures. Knowl Based Syst 164:205–212
Wang CZ, Wang Y, Shao MW et al (2020a) Fuzzy rough attribute reduction for categorical data. IEEE Trans Fuzzy Syst 28(5):818–830
Wang CZ, Huang Y, Shao MW et al (2020b) Feature selection based on neighborhood self-information. IEEE Trans Cybern 50(9):4031–4042
Wang Z, Cao C, Zhu Y (2020c) Entropy and confidence-based undersampling boosting random forests for imbalanced problems. IEEE Trans Neural Netw Learn Syst. https://doi.org/10.1109/TNNLS.2020.2964585
Yan YT, Wu ZB, Du XQ et al (2019) A three-way decision ensemble method for imbalanced data oversampling. Int J Approx Reason 107:1–16
Zhai JH, Wang XZ, Pang XH (2016) Voting-based instance selection from large data sets with MapReduce and random weight networks. Inform Sci 367:1066–1077
Zhai JH, Zhang MY, Chen CX et al (2018a) Binary ensemble classification for imbalanced big data based on MapReduce and upper sampling. J Data Acquis Process 33(3):416–425 (in Chinese)
Zhai JH, Zhang SF, Zhang MY et al (2018b) Fuzzy integral-based ELM ensemble for imbalanced big data classification. Soft Comput 22(11):3519–3531
Zhai M, Chen L, Tung F et al (2019) Lifelong GAN: Continual learning for conditional image generation. IEEE/CVF Int Conf Comput Vis (ICCV) 2019:2759–2768. https://doi.org/10.1109/ICCV.2019.00285
Yang K, Yu Z, Wen X et al (2020) Hybrid classifier ensemble for imbalanced data. IEEE Trans Neural Netw Learn Syst 31(4):1387–1400
Zhai M. Y., Chen L, Mori G (2021) Hyper-LifelongGAN: scalable lifelong learning for image conditioned generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR2021), pp 2246–2255
Zhang M, Li T, Zhu R et al (2020) Conditional Wasserstein generative adversarial network-gradient penalty-based approach to alleviating imbalanced data classification. Inform Sci 512:1009–1023
Zheng M, Li T, Zheng X et al (2021) UFFDFR: Undersampling framework with denoising, fuzzy c-means clustering, and representative sample selection for imbalanced data classification. Inform Sci 576:658–680
Zhong GQ, Wang LN, Ling X et al (2016) An overview on data representation learning: from traditional feature learning to recent deep learning. J Finance Data Sci 2(4):265–278
Acknowledgements
This study was supported by the key R&D program of science and technology foundation of Hebei Province (19210310D), and by the natural science foundation of Hebei Province (F2021201020).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhai, J., Wang, M. & Zhang, S. Binary imbalanced big data classification based on fuzzy data reduction and classifier fusion. Soft Comput 26, 2781–2792 (2022). https://doi.org/10.1007/s00500-021-06654-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-06654-9