
Abstract
In this paper, we propose a Geo-SceneEncoder framework to handle point cloud scene semantic segmentation, including a SceneEncoder to learn a scene prior, an advanced geometric kernel to learn geometry information from the point cloud, and a region similarity loss to refine segmentation results. In semantic segmentation, global information plays a pivotal role, while most recent works ignore the importance and usually fail to fully use it. Specifically, they do not explicitly extract meaningful global information and simply use global features in the concatenation. In this paper, we propose a SceneEncoder module to give scene-aware guidance to final segmentation results. This module learns to predict a scene descriptor that represents the categories existing in the scene and uses it to filter out categories not belonging to this scene directly. Additionally, to better use geometry information in the point cloud, we propose an advanced version of kernel correlation to extract geometric features at various scales. Then, we design a region similarity loss to alleviate segmentation noise in the local region. This loss propagates distinguishing features to their neighbors with the same label, enhancing the distinguishing ability of point-wise features. We integrate our methods into several prevailing networks and conduct comprehensive experiments on benchmark datasets ScanNet, S3DIS, and ShapeNet. Results show that our methods greatly improve the performance of baselines and outperform many state-of-the-art competitors. The source code is available at https://github.com/azuki-miho/GeoSceneEncoder.








Similar content being viewed by others
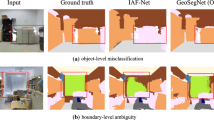
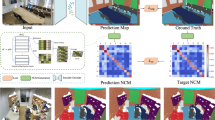

References
Ertugrul, E., Zhang, H., Zhu, F., Lu, P., Li, P., Sheng, B., Wu, E.: Embedding 3d models in offline physical environments. Comput. Anim. Virtual Worlds 31(4–5), e1959 (2020)
Sheng, B., Liu, B., Li, P., Fu, H., Ma, L., Wu, E.: Accelerated robust boolean operations based on hybrid representations. Comput. Aided Geom. Des. 62, 133–153 (2018)
Sheng, B., Li, P., Zhang, Y., Mao, L., Chen, C.P.: Greensea: visual soccer analysis using broad learning system. IEEE Trans. Cybern. 51(3), 1463–1477 (2020)
Sheng, B., Li, P., Fu, H., Ma, L., Wu, E.: Efficient non-incremental constructive solid geometry evaluation for triangular meshes. Graph. Models 97, 1–16 (2018)
Gong, J., Xu, J., Tan, X., Song, H., Qu, Y., **e, Y., Ma, L.: Omni-supervised point cloud segmentation via gradual receptive field component reasoning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11 673–11 682 (2021)
Tan, X., Ma, Q., Gong, J., Xu, J., Zhang, Z., Song, H., Qu, Y., **e, Y., Ma, L.: Positive-negative receptive field reasoning for omni-supervised 3d segmentation. IEEE Trans. Pattern Analy. Mach. Intell. (2023). https://doi.org/10.1109/TPAMI.2023.3319470
Jiang, J., Lu, X., Ouyang, W., Wang, M.: Unsupervised contrastive learning with simple transformation for 3d point cloud data. Visual Comput. (2023). https://doi.org/10.1007/s00371-023-02921-y
Kirillov, A., Wu, Y., He, K., Girshick, R.: Pointrend: Image segmentation as rendering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 9799–9808 (2020)
Tan, X., Xu, K., Cao, Y., Zhang, Y., Ma, L., Lau, R.W.: Night-time scene parsing with a large real dataset. IEEE Trans. Image Process. 30, 9085–9098 (2021)
Qi, F., Tan, X., Zhang, Z., Chen, M., **e, Y., Ma, L.: Glass makes blurs: learning the visual blurriness for glass surface detection. IEEE Trans. Ind. Inf. (2024). https://doi.org/10.1109/TII.2024.3352232
Jiang, J., Lu, X., Zhao, L., Dazaley, R., Wang, M.: Masked autoencoders in 3d point cloud representation learning. IEEE Trans. Multimedia (2023). https://doi.org/10.1109/TMM.2023.3314973
Su, H., Maji, S., Kalogerakis, E., Learned-Miller, E.: Multi-view convolutional neural networks for 3d shape recognition. In: The IEEE International Conference on Computer Vision (ICCV), pp. 945–953 (2015)
Graham, B., Engelcke, M., van der Maaten, L.: 3d semantic segmentation with submanifold sparse convolutional networks. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 9224–9232 (2018)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: The IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp. 652–660 (2017)
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: deep hierarchical feature learning on point sets in a metric space. In: Advances in neural information processing systems(NIPS), pp. 5099–5108 (2017)
Wu, W., Qi, Z., Fuxin, L.: Pointconv: Deep convolutional networks on 3d point clouds. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 9621–9630 (2019)
Gong, J., Ye, Z., Ma, L.: Neighborhood co-occurrence modeling in 3d point cloud segmentation. Comput. Vis. Media 8, 303–315 (2022)
Xu, Y., Fan, T., Xu, M., Zeng, L., Qiao, Y.: Spidercnn: Deep learning on point sets with parameterized convolutional filters. In: Proceedings of the European conference on computer vision (ECCV), pp. 87–102 (2018)
Gupta, S., Arbelaez, P., Malik, J.: Perceptual organization and recognition of indoor scenes from rgb-d images. In: The IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp. 564–571 (2013)
Deng, H., Birdal, T., Ilic, S.: Ppf-foldnet: Unsupervised learning of rotation invariant 3d local descriptors. In: Proceedings of the European conference on computer vision (ECCV), pp. 602–618 (2018)
Han, Z., Liu, Z., Han, J., Vong, C.-M., Bu, S., Chen, C.P.: Unsupervised learning of 3-d local features from raw voxels based on a novel permutation voxelization strategy. IEEE Trans. Cybern. 49(2), 481–494 (2017)
Zeng, A., Song, S., Nießner, M., Fisher, M., **ao, J., Funkhouser, T.: 3dmatch: learning local geometric descriptors from rgb-d reconstructions. In: The IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp. 1802–1811 (2017)
Shen, Y., Feng, C., Yang, Y., Tian, D.: Mining point cloud local structures by kernel correlation and graph pooling. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 4548–4557 (2018)
Tsin, Y., Kanade, T.: A correlation-based approach to robust point set registration. In: Proceedings of the European conference on computer vision (ECCV). Springer, pp. 558–569 (2004)
Zhao, H., Jiang, L., Fu, C.-W., Jia, J.: Pointweb: enhancing local neighborhood features for point cloud processing. In: The IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp. 5565–5573 (2019)
Xu, J., Gong, J., Zhou, J., Tan, X., **e, Y., Ma, L.: Sceneencoder: scene-aware semantic segmentation of point clouds with a learnable scene descriptor. In: Proceedings of the 29th international joint conference on artificial intelligence (IJCAI) (2020)
Jiang, L., Zhao, H., Liu, S., Shen, X., Fu, C.-W., Jia, J.: Hierarchical point-edge interaction network for point cloud semantic segmentation. In: The IEEE international conference on computer vision (ICCV), pp. 10 433–10 441 (2019)
Schult, J., Engelmann, F., Kontogianni, T., Leibe, B.: Dualconvmesh-net: joint geodesic and euclidean convolutions on 3d meshes. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), (2020)
Le, T., Duan, Y.: Pointgrid: a deep network for 3d shape understanding. In: The IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp. 9204–9214 (2018)
Qin, Y., Chi, X., Sheng, B., Lau, R.W.: Guiderender: large-scale scene navigation based on multi-modal view frustum movement prediction. Vis. Comput. 39, 3597 (2023)
Maturana, D., Scherer, S.: Voxnet: a 3d convolutional neural network for real-time object recognition. In: 2015 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp. 922–928 (2015)
Zhou, Y., Tuzel, O.: Voxelnet: end-to-end learning for point cloud based 3d object detection. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 4490–4499 (2018)
Lin, Y., Yan, Z., Huang, H., Du, D., Liu, L., Cui, S., Han, X.: Fpconv: learning local flattening for point convolution. In: The IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp. 4293–4302 (2020)
Thomas, H., Qi, C.R., Deschaud, J.-E., Marcotegui, B., Goulette, F., Guibas, L.J.: Kpconv: flexible and deformable convolution for point clouds. In: The IEEE international conference on computer vision (ICCV), pp. 6411–6420 (2019)
Jiang, J., Zhao, L., Lu, X., Hu, W., Razzak, I., Wang, M.: Dhgcn: dynamic hop graph convolution network for self-supervised point cloud learning. ar**v preprint ar**v:2401.02610 (2024)
Liu, J., Ni, B., Li, C., Yang, J., Tian, Q.: Dynamic points agglomeration for hierarchical point sets learning. In: The IEEE International conference on computer vision (ICCV), (2019)
Yan, X., Zheng, C., Li, Z., Wang, S., Cui, S.: Pointasnl: robust point clouds processing using nonlocal neural networks with adaptive sampling. In: The IEEE/CVF Conference on computer vision and pattern recognition (cvpr) (2020)
Hu, Q., Yang, B., **e, L., Rosa, S., Guo, Y., Wang, Z., Trigoni, N., Markham, A.: Randla-net: efficient semantic segmentation of large-scale point clouds. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), (2020)
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: richly-annotated 3d reconstructions of indoor scenes. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 5828–5839 (2017)
Armeni, I., Sener, Zamir, A.R., Jiang, H., Brilakis, I., Fischer, M., Savarese, S.: 3d semantic parsing of large-scale indoor spaces. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 1534–1543 (2016)
Chang, A.X., Funkhouser, T., Guibas, L., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., et al.: Shapenet: an information-rich 3d model repository. ar**v preprint ar**v:1512.03012 (2015)
Johnson, A.E., Hebert, M.: Using spin images for efficient object recognition in cluttered 3d scenes. IEEE Trans. Pattern Anal. Mach. Intell. 21(5), 433–449 (1999)
Chen, H., Bhanu, B.: 3d free-form object recognition in range images using local surface patches. Pattern Recogn. Lett. 28(10), 1252–1262 (2007)
Zhou, H., Chen, H., Feng, Y., Wang, Q., Qin, J., **e, H., Wang, F.L., Wei, M., Wang, J.: Geometry and learning co-supported normal estimation for unstructured point cloud. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 13 238–13 247 (2020)
Choy, C., Park, J., Koltun, V.: Fully convolutional geometric features. In: The IEEE international conference on computer vision (ICCV), pp. 8958–8966 (2019)
Zhao, L., Tao, W.: Jsnet: joint instance and semantic segmentation of 3d point clouds. In: AAAI, pp. 12 951–12 958 (2020)
Gong, J., Xu, J., Tan, X., Zhou, J., Qu, Y., **e, Y., Ma, L.: Boundary-aware geometric encoding for semantic segmentation of point clouds. Proc. AAAI Conf. Artif. Intell. 35(2), 1424–1432 (2021)
Li, Y., Bu, R., Sun, M., Wu, W., Di, X., Chen, B.: Pointcnn: Convolution on x-transformed points. In: Advances in neural information processing systems (NIPS), pp. 820–830 (2018)
Huang, J., Zhang, H., Yi, L., Funkhouser, T., Nießner, M., Guibas, L.J.: Texturenet: consistent local parametrizations for learning from high-resolution signals on meshes. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 4440–4449 (2019)
Lei, H., Akhtar, N., Mian, A.: Seggcn: efficient 3d point cloud segmentation with fuzzy spherical kernel. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 11 611–11 620 (2020)
Lei, H., Akhtar, N., Mian, A.: Spherical kernel for efficient graph convolution on 3d point clouds. IEEE Trans. Pattern Anal. Mach. Intell. 43, 3664 (2020)
Zhang, J., Zhu, C., Zheng, L., Xu, K.: Fusion-aware point convolution for online semantic 3d scene segmentation. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 4534–4543 (2020)
Li, H., Chen, Y., Tao, D., Yu, Z., Qi, G.: Attribute-aligned domain-invariant feature learning for unsupervised domain adaptation person re-identification. IEEE Trans. Inf. For. Secur. 16, 1480–1494 (2021)
Shi, W., Xu, J., Zhu, D., Zhang, G., Wang, X., Li, J., Zhang, X.: Rgb-d semantic segmentation and label-oriented voxelgrid fusion for accurate 3d semantic map**. IEEE Trans. Circuits Syst. Video Technol. 32(1), 183–197 (2022)
Du, Z., Ye, H., Cao, F.: A novel local-global graph convolutional method for point cloud semantic segmentation. IEEE Trans. Neural Netw. Learn. Syst. (2022). https://doi.org/10.1109/TNNLS.2022.3155282
Huang, Q., Wang, W., Neumann, U.: Recurrent slice networks for 3d segmentation of point clouds. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 2626–2635 (2018)
Yang, J., Zhang, Q., Ni, B., Li, L., Liu, J., Zhou, M., Tian, Q.: Modeling point clouds with self-attention and gumbel subset sampling. In: The IEEE/CVF Conference on computer vision and pattern recognition (CVPR), pp. 3323–3332 (2019)
Wang, X., He, J., Ma, L.: Exploiting local and global structure for point cloud semantic segmentation with contextual point representations. Adv. Neural Inf. Process. Syst. 32, 4571–4581 (2019)
Xu, Q., Sun, X., Wu, C.-Y., Wang, P., Neumann, U.: Grid-gcn for fast and scalable point cloud learning. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 5661–5670 (2020)
Li, J., Chen, B.M., Hee Lee, G.: So-net: self-organizing network for point cloud analysis. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 9397–9406 (2018)
Atzmon, M., Maron, H., Lipman, Y.: Point convolutional neural networks by extension operators. ACM Trans. Graph. 37(4), 71 (2018)
Rao, Y., Lu, J., Zhou, J.: Spherical fractal convolutional neural networks for point cloud recognition. In: The IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 452–460 (2019)
Zhang, Z., Hua, B.-S., Yeung, S.-K.: Shellnet: efficient point cloud convolutional neural networks using concentric shells statistics. In: The IEEE international conference on computer vision (ICCV), pp. 1607–1616 (2019)
Song, Z., Zhao, L., Zhou, J.: Learning hybrid semantic affinity for point cloud segmentation. IEEE Trans. Circuits Syst. Video Technol. 32, 4599 (2021)
Acknowledgements
This work is partially supported by National Natural Science Foundation of China (Nos. 61972157, 72192821, 62106268), Shanghai Municipal Science and Technology Major Project (2021SHZDZX0102).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This is the extended version of the previous IJCAI paper.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chai, Y., Gong, J., Tan, X. et al. Learnable scene prior for point cloud semantic segmentation. Vis Comput (2024). https://doi.org/10.1007/s00371-024-03344-z
Accepted:
Published:
DOI: https://doi.org/10.1007/s00371-024-03344-z