
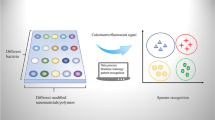
Abstract
The rapid discrimination of bacteria is currently an emerging trend in the fields of food safety, medical detection, and environmental observation. Traditional methods often require lengthy culturing processes, specialized analytical equipment, and bacterial recognition receptors. In response to this need, we have developed a paper-based fluorescence sensor array platform for identifying different bacteria. The sensor array is based on three unique carbon quantum dots (CQDs) as sensing units, each modified with a different antibiotic (polymyxin B, ampicillin, and gentamicin). These antibiotic-modified CQDs can aggregate on the bacterial surface, triggering aggregation-induced fluorescence quenching. The sensor array exhibits varying fluorescent responses to different bacterial species. To achieve low-cost and portable detection, CQDs were formulated into fluorescent ink and used with an inkjet printer to manufacture paper-based sensor arrays. A smartphone was used to collect the responses generated by the bacteria and platform. Diverse machine learning algorithms were utilized to discriminate bacterial types. Our findings showcase the platform's remarkable capability to differentiate among five bacterial strains, within a detection range spanning from 1.0 × 103 CFU/mL to 1.0 × 107 CFU/mL. Its practicality is further validated through the accurate identification of blind bacterial samples. With its cost-effectiveness, ease of fabrication, and high degree of integration, this platform holds significant promise for on-site detection of diverse bacteria.
Graphical abstract

Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The rapid and accurate identification of various bacterial strains is of paramount importance for effective disease control, treatment, and prevention, and for ensuring the safety and quality of food products and the environment [1]. While traditional bacterial recognition methods, including germiculture [2], microscopic observation of bacterial samples [3], flow cytometry [4], and enzyme-linked immunosorbent assays (ELISA) [5], have been established as reliable, these methods are encumbered by limitations such as prolonged culture periods, the need for advanced analytical equipment, the demand for specialized technical expertise, and location-specific restrictions, which impede their broad application.
Fluorescence analysis technology, known for its high sensitivity, specificity, and accuracy, is employed extensively in sensor development [6]. Current research in bacterial detection via fluorescence sensors focuses primarily on the unique interactions between the sensor and bacteria, leading to fluorescence quenching [7]. The recognition elements include antimicrobial peptides [8, 9], antibodies [1, the addition amounts of Triton X-100 and ethylene glycol were set at 5% and 10%, respectively.
Identification of bacteria by sensor-array platform
To evaluate the capability of the fluorescence sensing array in identifying multiple bacterial strains, a diverse set of five bacteria was selected based on variations in size and morphology. These bacteria included Pseudomonas aeruginosa, Escherichia coli, Staphylococcus aureus, Salmonella typhimurium, and Listeria monocytogenes. Each bacterial strain, with a concentration ranging from 1.0 × 103 CFU/mL to 1.0 × 107 CFU/mL, was exposed to interaction with each of the three sensing units and subsequently assessed using the developed platform.
Figure 3A illustrates the range of relative signal intensity variations (ΔRGB) observed in the three types of CQDs following their interaction with the five types of bacteria at a concentration of 1.0 × 103 CFU/mL. Notably, the values of ΔRGB corresponding to the interactions between the different bacterial strains and the CQDs are distinctly unique. This can be attributed to the diverse binding abilities of the bacteria to the CQDs, which are determined by variations in size, morphology, and surface chemical components of the bacteria. Subsequently, the ΔRGB values were subjected to analysis using pattern recognition methods, including various machine learning algorithms.

(A) Relative signal intensity variety (ΔRGB) of the three types of CQDs reacted with five types of bacteria in a concentration of 1.0 × 103 CFU/mL. All values are the means of five replicates. (B) Identification efficiency of unknown individual samples. (C) Parallel coordinates figures of the three canonical factors (Factor 1, Factor 2, Factor 3) of unknown individual samples. (D) Confusion matrix plot of the results of the three classification algorithms for identification of individual unknown samples
During the training phase, we employed a random selection procedure to allocate 70% of the available data as the training set, while the remaining 30% was designated as the testing set. For each dataset, one or more ML algorithms were considered, depending on which algorithm demonstrated the best performance. We utilized all the available classification algorithms built into MATLAB for bacterial discrimination, without assuming that one algorithm was superior to the others. These algorithms included k-nearest neighbors (KNN), the naive Bayes method, decision trees, linear discriminant analysis (LDA), and support vector machines (SVM).
The test dataset consisted of a total of 122 samples, encompassing 50 individual bacterial samples, 24 binary mixtures, and 48 ternary mixtures derived from five distinct bacterial strains. This dataset was trained with several algorithms. Across the three subsets, the performance of the algorithms remained fairly consistent, with minor variations. The accuracy percentages of all these algorithms are illustrated in Figs. 3B and S10. Among these algorithms, three achieved a remarkable 100% accuracy rate on the entire dataset: (i) decision tree, (ii) linear discriminant analysis, (iii) naïve Bayes.
Three canonical factors, designated as Factor 1, Factor 2, and Factor 3, were generated for comprehensive discrimination. To gain a deeper understanding of the relationships among these three canonical factors derived from the ML algorithms, we employed a parallel coordinates figure (Figs. 3C and S11). A parallel coordinates figure offers a means of visualizing multivariate data and is particularly suitable for displaying trends in multivariate data. Additionally, the confusion matrix plot, displayed in Figs. 3D and S12, demonstrates that the three above-listed ML algorithms achieved 100% accuracy.
To further validate the discriminatory capabilities of the sensor array assisted by ML algorithms, we created a 3D feature space plot using the three canonical factors generated from a subset of individual bacterial samples (Fig. 4A). In this plot, each point represents the relative signal intensity variation of the three CQDs when reacted with a specific bacterial strain. The five bacterial strains were distinctly clustered, with a 100% identification accuracy rate for each type. We also selected the first two most significant discrimination factors to confirm the discrimination of the samples (Fig. 4B). Individual bacterial samples were identified without any failures, underscoring the high precision of the ML algorithms-assisted sensor array in bacterial discrimination. Furthermore, binary and ternary mixtures were accurately identified (Fig. S13). We calculated the Euclidean distances among the five types of bacteria to classify them.

(A) Feature space plot of five types of bacteria using machine learning algorithms. (B) Canonical score plot for the identification of individual bacterial samples. The bacteria concentration was 1.0 × 103 CFU/mL. (C) Canonical score plot for the distinction of E. coli at different concentrations. (D) Score plot of Factor 1 versus the concentration of E. coli. Error bars represent the standard deviation from three parallel tests. (E) Canonical score plot for the identification of unknown individual bacterial samples. (F) Canonical score plot for the identification of individual unknown bacterial samples in tap water. In each case, the bacteria concentration was 1.0 × 103 CFU/mL
To determine the limit of detection (LOD) of the sensor array, we conducted a quantitative analysis of five types of bacteria. The fluorescence response of the sensor array to varying concentrations of bacteria was transformed into canonical score plots. As shown in Fig. 4C, the sensor array effectively distinguishes between various concentrations of E. coli, correlating Factor 1 with bacterial concentration. Figure 4D demonstrates a strong linear relationship between the fluorescence intensity of the sensor array and the concentration of E. coli. The sensor array demonstrated consistent performance in distinguishing between the various concentrations of the remaining four bacteria (Fig. S14). Table S1 summarizes the LOD of the sensor array for the five types of bacteria. These results demonstrate that the sensor array can be utilized for simultaneous identification and quantification of bacteria.
Identification of blind and real samples
The practicality of the platform was assessed by employing individual bacteria, binary mixtures, and ternary mixtures of the five bacterial strains, all with a total concentration of 1.0 × 103 CFU/mL, as blind samples. As depicted in Figs. 4E and S15, a total of 45 blind samples were accurately identified (the results are listed in Table S2). The device's applicability to real samples was further explored using 12 unknown bacterial samples mixed in tap water, with each sample having a concentration of 1.0 × 103 CFU/mL. All of the bacterial samples were successfully distinguished within the tap water medium (Fig. 4F, the results are listed in Table S3). These results confirm the platform's suitability for identifying the five types of bacteria in real samples.
Conclusion
In this study, we developed a paper-based fluorescence sensor-array platform designed for the identification of various bacterial strains. Three antibiotic-modified CQDs, each with distinct bacterial binding affinities, were utilized as the sensing units. These CQDs were formulated into fluorescent inks with carefully adjusted surface tension and viscosity. The paper-based sensor array was then created by printing an array pattern directly onto filter paper using an inkjet printer.
The differential binding abilities of bacteria to the CQDs resulted in differences in the fluorescence quenching efficiency of the CQDs. Leveraging this principle, we established unique identification fingerprints for each bacterial strain on the proposed sensor-array platform. This platform enables rapid on-site discrimination of bacteria by utilizing smartphones and integrating multiple machine learning algorithms.
Furthermore, we validated the platform's applicability by successfully differentiating between bacterial strains in real samples and accurately identifying blind samples. This platform shows great promise as a tool for on-site testing, with significant potential applications in various fields such as food safety assessment, disease diagnosis, and environmental pollution detection.
Data availability
The data that support the findings of this study are available from the corresponding author on request.
References
Carey JR, Suslick KS, Hulkower KI, Imlay JA, Imlay KRC, Ingison CK, Ponder JB, Sen A, Wittrig AE. Rapid identification of bacteria with a disposable colorimetric sensing array. J Am Chem Soc. 2011;133(19):7571–6.
Ferone M, Gowen A, Fanning S, Scannell AGM. Microbial detection and identification methods: bench top assays to omics approaches. Compr Rev Food Sci Food Saf. 2020;19(6):3106–29.
Bhavya ML, Shewale SR, Rajoriya D, Hebbar HU. Impact of blue led illumination and natural photosensitizer on bacterial pathogens, enzyme activity and quality attributes of fresh-cut pineapple slices. Food Bioprocess Tech. 2021;14(2):362–72.
Ambriz-Aviña V, Contreras-Garduño JA, Pedraza-Reyes M. Applications of flow cytometry to characterize bacterial physiological responses. BioMed Res Int. 2014;2014:461941.
Umrao PD, Kumar V, Kaistha SD. Enzyme-Linked Immunosorbent assay detection of bacterial wilt–causing Ralstonia solanacearum. In: Gupta N, Gupta V (eds) Experimental protocols in biotechnology. Springer US, New York, NY, 2020;1–18.
Wu D, Sedgwick AC, Gunnlaugsson T, Akkaya EU, Yoon J, James TD. Fluorescent chemosensors: the past, present and future. Chem Soc Rev. 2017;46(23):7105–23.
Zhang J, Zhou M, Li X, Fan Y, Li J, Lu K, Wen H, Ren J. Recent advances of fluorescent sensors for bacteria detection-A review. Talanta. 2023;254:124133.
Mannoor MS, Zhang S, Link AJ, McAlpine MC. Electrical detection of pathogenic bacteria via immobilized antimicrobial peptides. Proc Nat Acad Sci. 2010;107(45):19207–12.
Hoyos-Nogués M, Brosel-Oliu S, Abramova N, Muñoz F-X, Bratov A, Mas-Moruno C, Gil F-J. Impedimetric antimicrobial peptide-based sensor for the early detection of periodontopathogenic bacteria. Biosens Bioelectron. 2016;86:377–85.
Wang C, Shen W, Rong Z, Liu X, Gu B, **ao R, Wang S. Layer-by-layer assembly of magnetic-core dual quantum dot-shell nanocomposites for fluorescence lateral flow detection of bacteria. Nanoscale. 2020;12(2):795–807.
Richter Ł, Janczuk-Richter M, Niedziółka-Jönsson J, Paczesny J, Hołyst R. Recent advances in bacteriophage-based methods for bacteria detection. Drug Discov Today. 2018;23(2):448–55.
Hussain W, Ullah MW, Farooq U, Aziz A, Wang S. Bacteriophage-based advanced bacterial detection: concept, mechanisms, and applications. Biosens Bioelectron. 2021;177:112973.
Majdinasab M, Hayat A, Marty JL. Aptamer-based assays and aptasensors for detection of pathogenic bacteria in food samples. TrAC Trends Anal Chem. 2018;107:60–77.
Zhang T, Zhou W, Lin X, Khan MR, Deng S, Zhou M, He G, Wu C, Deng R, He Q. Light-up RNA aptamer signaling-CRISPR-Cas13a-based mix-and-read assays for profiling viable pathogenic bacteria. Biosens Bioelectron. 2021;176:112906.
Wu J, Liu W, Ge J, Zhang H, Wang P. New sensing mechanisms for design of fluorescent chemosensors emerging in recent years. Chem Soc Rev. 2011;40(7):3483–95.
Wang Z, Hu T, Liang R, Wei M. Application of zero-dimensional nanomaterials in biosensing. Front Chem. 2020;8:320.
Yan C, Wang C, Hou T, Guan P, Qiao Y, Guo L, Teng Y, Hu X, Wu H. Lasting tracking and rapid discrimination of live gram-positive bacteria by peptidoglycan-targeting carbon quantum dots. ACS Appl Mater Interfaces. 2021;13(1):1277–87.
Albert KJ, Lewis NS, Schauer CL, Sotzing GA, Stitzel SE, Vaid TP, Walt DR. Cross-reactive chemical sensor arrays. Chem Rev. 2000;100(7):2595–626.
Morsy MK, Zór K, Kostesha N, Alstrøm TS, Heiskanen A, El-Tanahi H, Sharoba A, Papkovsky D, Larsen J, Khalaf H, Jakobsen MH, Emnéus J. Development and validation of a colorimetric sensor array for fish spoilage monitoring. Food Control. 2016;60:346–52.
Lin H, Jang M, Suslick KS. Preoxidation for colorimetric sensor array detection of VOCs. J Am Chem Soc. 2011;133(42):16786–9.
Boutry CM, Nguyen A, Lawal QO, Chortos A, Rondeau-Gagné S, Bao Z. A sensitive and biodegradable pressure sensor array for cardiovascular monitoring. Adv Mater. 2015;27(43):6954–61.
Han J, Cheng H, Wang B, Braun MS, Fan X, Bender M, Huang W, Domhan C, Mier W, Lindner T, Seehafer K, Wink M, Bunz UHF. A polymer/peptide complex-based sensor array that discriminates bacteria in urine. Angew Chem Int Edit. 2017;56(48):15246–51.
Luo Y, **ao X, Chen J, Li Q, Fu H. Machine-learning-assisted recognition on bioinspired soft sensor arrays. ACS Nano. 2022;16(4):6734–43.
Haugen JE, Rudi K, Langsrud S, Bredholt S. Application of gas-sensor array technology for detection and monitoring of growth of spoilage bacteria in milk: A model study. Anal Chim Acta. 2006;565(1):10–6.
Bordbar MM, Tashkhourian J, Tavassoli A, Bahramali E, Hemmateenejad B. Ultrafast detection of infectious bacteria using optoelectronic nose based on metallic nanoparticles. Sens Actuators B. 2020;319:128262.
Han X, Che L, Zhao Y, Chen Y, Zhou S, Wang J, Yin M, Wang S, Deng Q. Fluorescence sensor array of a multiplexing probe with three/four excitations/emissions for rapid and highly sensitive discrimination of foodborne pathogenic bacteria. Sens Actuators B. 2023;388:133847.
Lu Y, Liang Y, Zhao Y, **a M, Liu X, Shen T, Feng L, Yuan N, Chen Q. Fluorescent test paper via the in situ growth of cofs for rapid and convenient detection of Pd(II) ions. ACS Appl Mater Interfaces. 2021;13(1):1644–50.
Cate DM, Adkins JA, Mettakoonpitak J, Henry CS. Recent developments in paper-based microfluidic devices. Anal Chem. 2015;87(1):19–41.
Sun R, Huo X, Lu H, Feng S, Wang D, Liu H. Recyclable fluorescent paper sensor for visual detection of nitroaromatic explosives. Sens Actuators B. 2018;265:476–87.
Chen X, Yu S, Yang L, Wang J, Jiang C. Fluorescence and visual detection of fluoride ions using a photoluminescent graphene oxide paper sensor. Nanoscale. 2016;8(28):13669–77.
Wong PT, Tang S, Tang K, Coulter A, Mukherjee J, Gam K, Baker JR, Choi SK. A lipopolysaccharide binding heteromultivalent dendrimer nanoplatform for Gram negative cell targeting. J Mater Chem B. 2015;3(6):1149–56.
Bell CS, Mejías R, Miller SE, Greer JM, McClain MS, Cover TL, Giorgio TD. Magnetic extraction of Acinetobacter baumannii using colistin-functionalized γ-Fe2O3/Au core/shell composite nanoclusters. ACS Appl Mater Interfaces. 2017;9(32):26719–30.
Bryan LE, Kwan S. Roles of ribosomal binding, membrane potential, and electron transport in bacterial uptake of streptomycin and gentamicin. Antimicrob Agents Ch. 1983;23(6):835–45.
Rafailidis PI, Ioannidou EN, Falagas ME. Ampicillin/sulbactam. Drugs. 2007;67(13):1829–49.
Chandra S, Mahto TK, Chowdhuri AR, Das B, Sahu SK. One step synthesis of functionalized carbon dots for the ultrasensitive detection of Escherichia coli and iron (III). Sens Actuators B. 2017;245:835–44.
Koivunen R, Jutila E, Bollström R, Gane P. Hydrophobic patterning of functional porous pigment coatings by inkjet printing. Microfluid Nanofluid. 2016;20(6):83.
Wang L, Zhang X, Yang K, Wang L, Lee C-S. Oxygen/nitrogen-related surface states controlled carbon nanodots with tunable full-color luminescence: mechanism and bio-imaging. Carbon. 2020;160:298–306.
Campos BB, Contreras-Cáceres R, Bandosz TJ, Jiménez-Jiménez J, Rodríguez-Castellón E, Esteves da Silva JCG, Algarra M. Carbon dots as fluorescent sensor for detection of explosive nitrocompounds. Carbon. 2016;106:171–8.
Li H, Han S, Lyu B, Hong T, Zhi S, Xu L, Xue F, Sai L, Yang J, Wang X, He B. Tunable light emission from carbon dots by controlling surface defects. Chin Chem Lett. 2021;32(9):2887–92.
Funding
Open access funding provided by The Hong Kong Polytechnic University. This work was supported by the National Natural Science Foundation of China (Grant No. 11804072) and the Fundamental Research Funds for the Central Universities (Grant No. JZ2023HGTB0232).
Author information
Authors and Affiliations
Contributions
Fangbin Wang: Conceptualization, Methodology, Formal analysis, Writing—original draft. Minghui **ao: Data collection and Formal analysis. **g Qi: Project administration, Data curation, Validation. Liang Zhu: Conceptualization, Resources, Writing—review and editing, Supervision.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, F., **ao, M., Qi, J. et al. Paper-based fluorescence sensor array with functionalized carbon quantum dots for bacterial discrimination using a machine learning algorithm. Anal Bioanal Chem 416, 3139–3148 (2024). https://doi.org/10.1007/s00216-024-05262-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00216-024-05262-4