
Abstract
The support vector machine (SVM) is a powerful classifier used for binary classification to improve the prediction accuracy. However, the nondifferentiability of the SVM hinge loss function can lead to computational difficulties in high-dimensional settings. To overcome this problem, we rely on the Bernstein polynomial and propose a new smoothed version of the SVM hinge loss called the Bernstein support vector machine (BernSVC). This extension is suitable for the high dimension regime. As the BernSVC objective loss function is twice differentiable everywhere, we propose two efficient algorithms for computing the solution of the penalized BernSVC. The first algorithm is based on coordinate descent with the maximization-majorization principle and the second algorithm is the iterative reweighted least squares-type algorithm. Under standard assumptions, we derive a cone condition and a restricted strong convexity to establish an upper bound for the weighted lasso BernSVC estimator. By using a local linear approximation, we extend the latter result to the penalized BernSVC with nonconvex penalties SCAD and MCP. Our bound holds with high probability and achieves the so-called fast rate under mild conditions on the design matrix. Simulation studies are considered to illustrate the prediction accuracy of BernSVC relative to its competitors and also to compare the performance of the two algorithms in terms of computational timing and error estimation. The use of the proposed method is illustrated through analysis of three large-scale real data examples.





Similar content being viewed by others
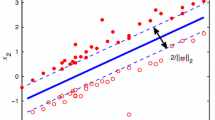
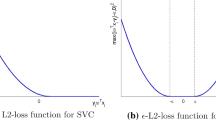

References
Alam J, Alam S, Hossan A (2018) Multi-stage lung cancer detection and prediction using multi-class svm classifie. In: 2018 International conference on computer, communication, chemical, material and electronic engineering (IC4ME2). IEEE, pp 1–4
Becker N, Toedt G, Lichter P, Benner A (2011) Elastic scad as a novel penalization method for svm classification tasks in high-dimensional data. BMC bioinformatics 12(1), 1–13
Bradley PS, Mangasarian OL (1998) Feature selection via concave minimization and support vector machines. In: ICML, vol 98, pp 82–90
Chang HH, Chen SW (2008) The impact of online store environment cues on purchase intention: Trust and perceived risk as a mediator. Online information review
Christidis A-A, Van Aelst S, Zamar R (2021) Data-driven diverse logistic regression ensembles. ar**v:2102.08591
Christmann, A., Hable, R.: Consistency of support vector machines using additive kernels for additive models. Computational Statistics and Data Analysis 56(4), 854–873 (2012) 10.1016/j.csda.2011.04.006
Cortes C, Vapnik V (1995) Support-vector networks. Machine learning 20(3), 273–297
Dedieu A (2019) Error bounds for sparse classifiers in high-dimensions. In: The 22nd international conference on artificial intelligence and statistics, pp 48–56
Fan J, Li R, Zhang C-H, Zou H (2020) Statistical Foundations of Data Science. CRC Press, New York
Fernández-Delgado M, Cernadas,E, Barro S, Amorim D Do we need hundreds of classifiers to solve real world classification problems? The journal of machine learning research 15(1), 3133–3181 (2014)
Friedman, J, Hastie T, Tibshirani R (2010) Regularization paths for generalized linear models via coordinate descent. J Stat Softw 33(1), 1
Golub TR, Slonim DK, Tamayo P, Huard C, Gaasenbeek M, Mesirov JP, Coller H, Loh ML, Downing JR, Caligiuri MA, et al. (1999) Molecular classification of cancer: class discovery and class prediction by gene expression monitoring. Science 286(5439), 531–537
Guan L, Sun T, Qiao L-b, Yang Z-h, Li D-s, Ge K-s, Lu X-c (2020) An efficient parallel and distributed solution to nonconvex penalized linear svms. Front Inf Technol Electron Eng 21, 587–603
Huang J, Zhang C-H (2012) Estimation and selection via absolute penalized convex minimization and its multistage adaptive applications. J Mach Learn Res 13(1), 1839–1864
Huang, S., Cai, N., Pacheco, P.P., Narrandes, S., Wang, Y., Xu, W.W.: Applications of support vector machine (svm) learning in cancer genomics. Cancer genomics & proteomics 15 1, 41–51 (2018)
Kharoubi R, Oualkacha K, Mkhadri A (2019) The cluster correlation-network support vector machine for high-dimensional binary classification. J Stat Comput Simul 89(6), 1020–1043
Kim S, Jhong J-H, Lee J, Koo J-Y Meta-analytic support vector machine for integrating multiple omics data. BioData mining 10, 1–14 (2017)
Koo J-Y, Lee Y, Kim Y, Park C (2008) A bahadur representation of the linear support vector machine. J Mach Learn Res 9, 1343–1368
Kumar S, Singh S, Kumar J (2018) Multiple face detection using hybrid features with svm classifier. Data Commun Netw
Lee Y-J, Mangasarian OL (2001) Rsvm: reduced support vector machines. In: Proceedings of the 2001 SIAM international conference on data mining. SIAM, pp 1–17
Marron J (2015) Distance-weighted discrimination. Wiley Interdiscip Rev Comput Stat 7(2), 109–114
J. S Marron MJT, Ahn J (2007) Distance-weighted discrimination. Journal of the American Statistical Association 102(480), 1267–1271
Negahban S, Yu B, Wainwright MJ, Ravikumar P (2009) A unified framework for high-dimensional analysis of \( m \)-estimators with decomposable regularizers. Adv Neural Inf Processing Syst 22
Park M, Kim H, Shin SJ \(l_1\)-penalized fraud detection support vector machines. Journal of the Korean Statistical Society 52(2):234 (2023) https://doi.org/10.1007/s42952-023-00207-6
Peng B, Wang L, Wu Y (2016) An error bound for l1-norm support vector machine coefficients in ultra-high dimension. J Mach Learn Res 17(1), 8279–8304
Raskutti G, Wainwright MJ, Yu B (2010) Restricted eigenvalue properties for correlated gaussian designs. J Mach Learn Res 11, 2241–2259
Reichert C, Klemm L, Mushunuri RV, Kalyani A, Schreiber S, Kuehn E, Azañón E Discriminating free hand movements using support vector machine and recurrent neural network algorithms. Sensors 22(16):234 (2022) https://doi.org/10.3390/s22166101
Rudelson M, Zhou S (2012) Reconstruction from anisotropic random measurements. In: Conference on learning theory. JMLR Workshop and conference proceedings, pp 10–1
Schölkopf B, Smola AJ (2018) Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. https://doi.org/10.7551/mitpress/4175.001.0001
Singh D, Febbo PG, Ross K, Jackson DG, Manola J, Ladd C, Tamayo P, Renshaw AA, D’Amico, AV, Richie JP, et al. (2002) Gene expression correlates of clinical prostate cancer behavior. Cancer Cell 1(2), 203–209
Storey JD, Tibshirani R (2003) Statistical significance for genomewide studies. Proceedings of the National Academy of Sciences 100(16), 9440–9445
Wang, B., Zou, H.: Another Look at Distance-Weighted Discrimination. Journal of the Royal Statistical Society Series B: Statistical Methodology 80(1), 177–198 (2017) 10.1111/rssb.12244
Wang L, Zhu J, Zou H (2006) The doubly regularized support vector machine. Stat Sin 589–615
Yang, Y., Zou, H.: An efficient algorithm for computing the hhsvm and its generalizations. Journal of Computational and Graphical Statistics 22(2), 396–415 (2013)
Ye G-B, Chen Y, **e X (2011) Efficient variable selection in support vector machines via the alternating direction method of multipliers. In: Proceedings of the fourteenth international conference on artificial intelligence and statistics, pp 832–840
Yi C, Huang J (2017) Semismooth newton coordinate descent algorithm for elastic-net penalized huber loss regression and quantile regression. J Comput Graph Stat 26(3), 547–557
Zhang X, Wu Y, Wang L, Li R (2016) Variable selection for support vector machines in moderately high dimensions. Journal of the Royal Statistical Society Series B (Statistical Methodology) 78(1), 53–76
Zhang X, Wu Y, Wang L, Li R (2016) Variable selection for support vector machines in moderately high dimensions. J Roy Stat Soc Ser B (Statist Methodol) 78(1), 53–76
Zhu J, Rosset S, Tibshirani R, Hastie (2003) T1-norm support vector machines. Adva Neural Inf Process Syst 16
Zou H, Li R (2008) One-step sparse estimates in nonconcave penalized likelihood models. The Annals of statistics 36(4), 1509–1533
Acknowledgements
The authors want to thank the reviewers for their helpful comments and constructive suggestions. This work was supported by the Fonds de Recherche Québec-Santé [267074 to K.O.]; and the Natural Sciences and Engineering Research Council of Canada [RGPIN-2019-06727 to K.O.].
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kharoubi, R., Mkhadri, A. & Oualkacha, K. High-dimensional penalized Bernstein support vector classifier. Comput Stat 39, 1909–1936 (2024). https://doi.org/10.1007/s00180-023-01448-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-023-01448-z