
Abstract
The optimization of geometrical pore control in high-capacity Ni-based cathode materials is required to enhance the cyclic performance of lithium-ion batteries. Enhanced porosity improves lithium-ion mobility by increasing the electrode–electrolyte contact area and reducing the number of ion diffusion pathways. However, excessive porosity can diminish capacity, thus necessitating optimizing pore distribution to compromise the trade-off relation. Accordingly, a statistically meaningful porosity estimation of electrode materials is required to engineer the local pore distribution inside the electrode particles. Conventional scanning electron microscopy (SEM) image-based porosity measurement can be used for this purpose. However, it is labor-intensive and subjected to human bias for low-contrast pore images, thereby potentially lowering measurement accuracy. To mitigate these difficulties, we propose an automated image segmentation method for the reliable porosity measurement of cathode materials using deep convolutional neural networks specifically trained for the analysis of porous cathode materials. Combined with the preprocessed SEM image datasets, the model trained for 100 epochs exhibits an accuracy of > 97% for feature segmentation with regard to pore detection on the input datasets. This automated method considerably reduces manual effort and human bias related to the digitization of pore features in serial section SEM image datasets used in 3D electron tomography.
Graphical abstract

Similar content being viewed by others


Introduction
Extensive research efforts have been made in recent decades to develop high-performance durable Li-ion batteries with large capacity. Among promising candidates, high-capacity Ni-based cathode materials, e.g., LiNi0.8Co0.1Mn0.1O2, have been considered owing to their outstanding properties related to energy density, cycling stability, and manufacturing cost (Shim et al. 2019). The optimization of geometrical parameters, i.e., the porosity of the secondary particles of the cathode materials, was suggested as an effective strategy to further improve performance (Chen et al. 2016). X-ray computed tomography (XCT) is used to characterize the porosity of electrode materials. However, this technique is dedicated to the microscale characterization of porous electrode structures at the cell level (Pietsch and Wood 2017). Cross-sectional image analysis or tomography interpretation using scanning electron microscopy (SEM) combined with a focused ion beam (FIB)-based serial milling was suggested for precise porosity quantification owing to its nanoscale resolution down to a level of 10 nm (Cantoni et al. 2014; Hong et al. 2022). However, statistical interpretation using 3D tomographic reconstruction or 2D-image-based pore segmentation requires a large number of image datasets and heavy human input for digital processing. In general, a subjective decision can be made regarding the weak image contrast of pores in SEM images, which can reduce the measurement veracity. Therefore, a reliable machine-perspective automated segmentation analysis of pores in the SEM images of porous cathodes is required. Digital segmentation methods were typically used to estimate the pore content in a material based on SEM imaging (Andrä et al. 2013). These digital methods first detect the edge of an image by applying a random threshold to each pixel and then, extend the detection condition to the surrounding pixels using a marker-based watershed. Furthermore, the traditional Otsu method (Zhang and Hu 2008) and Canny edge detection technique (Chen et al. 2015) were used for edge detection. Alternatively, the expectation–maximization/maximization of posterior marginals (Comer and Delp 2000) can be considered for edge detection. However, multiple parameters for this digital processing must be optimized. Digital segmentation using the aforementioned approaches is generally time-consuming and requires human intervention for each digital processing step, thus complicating measurements with statistical significance (Galbany et al. 2005; Gesho et al. 2020; Roldán et al. 2021). To address the limitations of conventional digital approaches, convolutional neural networks (CNNs) combined with relevant filters can be used to devise a promising solution because CNNs are highly efficient in training images, extracting features, performing semantic segmentation, and interpreting feature characteristics (Krizhevsky et al. 2012; Long et al. 2015; Nanfack et al. 2018; Garcia-Garcia et al. 2017). Recently, machine learning/deep learning algorithms such as random forest classifiers and CNNs for feature segmentation were actively adapted to reduce contrast artifacts in traditional SEM images and to improve efficiency and reliability in FIB-SEM tomography for pore structure characterizations (Zang et al. 2023; Osenberg et al. 2023). Considering the advantages of the CNN-based approach, the geometrical characterization of high-capacity Ni-based cathode materials can be rapidly and reliably performed, which facilitates the understanding of the electrode structures and advances the design strategy for high-performance electrodes (Finegan et al. 2022; Yang et al. 2022).
This study introduces a CNN-based model for the accurate feature segmentation and statistical interpretation of geometrical factors, e.g., the pore content distributed in high-capacity Ni-based cathode materials. To this end, a convolutional encoder–decoder model was used to construct a deep learning model for the pore segmentation of the SEM images of cathode materials, and the performance of the model was evaluated by comparing it with the ground truth data based on human inputs. The established model can automatedly expedite the segmentation process for a large dataset of SEM images and effectively learn pore features from SEM images, reliably determining porosity with an accuracy of > 97%. To optimize the performance of the proposed model for the semantic detection and extraction of geometrical pores from raw SEM images, the effects of preprocessing of raw image data, i.e., hysteresis thresholding (Wang et al. 2008) or histogram stretching and equalization (Luo et al. 2021; Abdullah-Al-Wadud et al. 2007), were examined. The preprocessing was generally used to improve feature segmentation performance in conventional FIB-SEM tomography. However, whether those digital filters are effective has barely been tested in the CNN-driven automated feature segmentation. Interestingly, the measured porosity of the material with this CNN-assisted 2D segmentation process was revealed to be well consistent with the result measured from the 3D electron tomography after the CNN-based workflow optimization. This result shows that the labor-intensive effort required for pore structure analysis of the cathode materials can be substantially reduced, while the human bias in the segmentation task is avoided, warranting the measurement veracity corresponding to the learning reliability of the used CNN model.
Materials and methods
Sample preparation and data acquisition
The secondary particles of high-capacity Ni-based oxide cathodes (LiNi0.8Co0.1Mn0.1O2, hereafter referred to as NCM) were prepared as model samples using the established method (Song et al. 2018). The serial section imaging of the porous structures was conducted using the Helios5 HX DualBeam™ system installed in the Thermo Fisher Scientific laboratory. For SEM imaging, the NCM particles were fixed to an Al stub (Agar Scientific) using a conductive colloidal silver paste (Ted Pella) (Fig. 1a). To reduce the surface contamination of the NCM particles, the sample was baked for 2.5 h at 300 °C in an oven and further cleaned with Ar plasma for 2 h in the FIB-SEM chamber. Thereafter, the NCM particles were moved to the beam coincident point of the SEM and FIB, where each beam was scanned simultaneously during SEM imaging and FIB milling. A cross-sectional image is shown in Fig. 1b. This acquisition process can be generally automated in modern FIB-SEM instruments by serial functions of automated FIB slicing and consecutive SEM imaging. With this function, serial section SEM images were automatically taken at the thickness interval of 15 nm in this experiment (Hong et al. 2022; Cantoni and Holzer. 2014). To reduce the artificial-charging-induced edge contrast around the pores, a highly magnified cross-sectional image of the sample was acquired in the backscatter electron (BSE) imaging mode at a low accelerating voltage of 2 kV and low beam current of 50 pA (Fig. 1c). For FIB milling, the accelerating voltage and ion beam current were 30 kV and 2.4 nA, respectively, which helped mitigate the curtaining effect caused by the uneven vertical milling of the sample (Schwarz et al. 2003; Konvalina et al. 2019).

Microstructure of high-capacity Ni-based oxide cathodes (LiNi0.8Co0.1Mn0.1O2, NCM). a SEM surface image of a secondary particle of NCM. b SEM–FIB serial section structure of a secondary particle of NCM. c High-magnification backscatter electron (BSE) image obtained from the FIB cross-sectioning workflow. Note that statistical noise background and vertical stripe contrast artifacts in all the acquired BSE images were removed using Gaussian and FFT filters before constructing the image stack. d Experimental BSE image stack with a cropped size of 256 × 256 pixels and e human-based binarized pore image stack prepared as ground truth datasets after applying hysteresis thresholding. f Concept of the gradient magnitude of pixel intensity to determine the hysteresis thresholding condition
In the FIB slicing by the depth interval of 15 nm, 400 BSE images were experimentally acquired from front to back side surfaces for the whole size of the NCM secondary particle (Fig. 1b). Due to the geometrical constraint of the spherical particle, 100 square images practically usable for pore structure analysis (with an imaging dimension of 2.3 μm2) per learning session were prepared for training and test sessions, which were obtained separately from different NCM particles (i.e., 200 images in total) for our model. The sizes of the grayscale input and output images were set to 256 × 256 pixels (Fig. 1d). Since these images were acquired during the cross-sectioning of the NCM particles in the FIB system (Burnett et al. 2016), the uneven vertical milling of the sample during continuous FIB sectioning must be mitigated. This phenomenon is known as the curtaining effect, which results in surface roughness and adversely affects the results of the segmentation process because it generates stripe contrast artifacts in SEM images along the vertical direction (Hong et al. 2022). To remove the vertical texture pattern generated by the curtaining effect, a filtering process based on the fast Fourier transform (FFT) was employed for the entire SEM image stack. In Fourier space, the frequency component pertaining to the stripe artifacts appears highly directional so that it can be filtered out by applying a wedge-type filter (Burnett et al. 2016; Schwartz et al. 2019). This filtering routine was performed on a commercial 3D visualization software AVIZO (Thermo Fisher Scientific Inc.) in this study. Then, a filtered SEM image stack with the same 16-bit single-channel grayscale (Gupta et al. 2015) was prepared by applying the inverse FFT operation, which was used as the ground truth dataset. As secondary electron (SE) imaging in SEM exhibits high contrast on pore edges owing to the high yield of secondary electron emission, SE imaging is not suitable for reliable pore recognition and segmentation. Thus, the use of the BSE imaging mode is highly recommended because the signal contrast in the BSE mode is not affected by the surface geometry of a sample and does not exhibit topographic contrast differences (Hong et al. 2022). Therefore, we obtained a series of cross-sectional SEM images of the NCM cathode particles in the BSE imaging mode. Owing to the low yield of the BSE signal, the resulting image exhibited a poor signal-to-noise ratio (SNR). To reduce statistical noise in the BSE image, Gaussian filtering was applied; it is efficient in removing high-frequency background noise with a probability distribution (Young and Vliet 1995; Ramadan 2019). It is noted that the processing of the raw SEM images by FFT and Gaussian filters is routinely required to prepare the image stack for conventional tomography analysis (Additional file 1: Fig. S1).
Hysteresis thresholding for boundary definition
To prepare training and test datasets, digital image processing, such as contrast dichotomization (or digital binarization), which is a two-class classification problem that separates black and white and classifies objects into one of the two values (Stathis et al. 2008; Ntogas and Veintzas 2008), is required to improve the learning efficiency for image segmentation between primary particles and pores (i.e., empty space) (Fig. 1e). In general, the boundaries between particles and pores are difficult to be determined when pixel values are similar across the boundaries. To perform binarization effectively, an appropriate criterion that considers pixel values across boundaries is required to reduce errors in the boundary definition (Condurache and Aach 2005). To this end, we used the hysteresis thresholding technique, which effectively detects the boundaries between objects when the pixel values are not sharp (Wang et al. 2008; Condurache et al. 2005).
The hysteresis thresholding technique is defined as follows (Fig. 1f): First, the two thresholds of grains and pores across the boundary with gradient magnitude are defined as high and low thresholds, respectively. Values above these thresholds are classified as edge pixels. Second, when a pixel is located between the high and low thresholds and connected to edge pixels, it is assigned as an edge pixel. Finally, the remaining pixels (either below the low threshold or at intermediate values but not connected to edge pixels) are classified as non-edge pixels (Fig. 1f). When the hysteresis threshold can be reliably determined, binarization processing is effectively performed. However, when the thresholding judgment is uncertain because the measured values fall into the transition region (C and D in Fig. 1f), a decision should be made according to the surrounding environment (Wang et al. 2008). The ground truth SEM image dataset (200 square images with 256 × 256 pixels) containing the distributed pores was prepared after optimized hysteresis thresholding. Among them, 100 images were assigned as training data, and the remaining images were used as test data. To improve the learning efficiency of our model, cross-validation with the same configuration as that of the training (50%) and validation datasets (50%) was performed (Azimi et al. 2018; Badrinarayanan et al. 2017; Chatfield et al. 2014). The cross-validation is usually used as a statistical method to evaluate the generalizability of a model and to suppress overfitting. With two-fold cross-validation, which divides the image dataset into two subsets, our model was trained on one subset, and the remaining subset was used for validating the model’s performance. This process was repeated two times, with each subset used exactly once as validation data, and the average performance metric was used to evaluate the model’s performance.
Preprocessing of input images
The usefulness of CNN models lies in their ability to identify the hidden characteristics of various datasets (Garcia-Garcia et al. 2017; He et al. 2015; Kim et al. 2022). To enhance this capability, data preprocessing is recommended for preparing high-quality input datasets (Luo et al. 2021). Preprocessing involves reducing unnecessary data dimensions with meaningless features that are irrelevant to the semantic classification of the input dataset. To preprocess the image dataset, we independently used histogram stretching and histogram equalization to create a high-contrast image dataset exhibiting a clear pore structure in the secondary cathode particles (Fig. 2) (Oliver. 1998).

Input image dataset prepared for deep learning. a Example image array of original image dataset (256 × 256 pixels) obtained at different depths in the NCM secondary particle through SEM–FIB serial sectioning and postprocessing. The depth interval between each slice number is 15 nm. b, c Image datasets generated after histogram stretching and histogram equalization, respectively
Histogram stretching is a linear transformation technique that changes the histogram of an image to be evenly distributed over the grayscale (Im et al. 2011). The histogram stretching formula can be expressed as \(g\left( {x,y} \right) = \frac{{f\left( {x,y} \right) - f\min }}{f\max - f\min }*2^{{{\text{bpp}}}}\), where \(f\left( {x,y} \right)\) denotes the pixel value, \(f\max\) denotes the maximum value, \(f\min\) denotes the minimum value, and \({\text{bpp}}\) denotes the bit per pixel. After measuring the \(f\max\) and \(f\min\) values of the pixels in the initial image, the brightness and contrast of the image can be improved by adjusting each pixel value using the histogram stretching equation (Fig. 2a and b) (Luo et al. 2021).
Subsequent treatment based on histogram equalization can further improve the image contrast, which effectively reduces the difference in magnitude among all pixels in the pore region with dark contrast (Abdullah-Al-Wadud et al. 2007). The histogram equalization is described as \(h\left( v \right) = {\text{round}}\left( {\frac{{{\text{cdf}}\left( v \right) - {\text{cdf}}_{\min } }}{{\left( {M*N} \right) - {\text{cdf}}_{\min } }}*\left( {L - 1} \right)} \right)\), where \({\text{cdf}}_{\min }\) denotes the minimum cumulative function, \(M\) and \(N\) denote the numbers of rows and columns of pixels, respectively, and \(L\) denotes the number of gray levels. The contrast of the image dataset is substantially improved using the histogram equalization process (Fig. 2c).
CNN for feature segmentation
The SegNet model has been widely used as a CNN for binary feature segmentation (Badrinarayanan et al. 2017). Figure 3 illustrates the model structure. When input images of the training set are fed into the CNN model for learning, the model returns the predicted value, compares the output with the ground truth data to evaluate loss (or accuracy), and tunes the weight and bias of fitting to reduce the loss. Subsequently, using the images of the test session, the learned model returns the predicted values, and its performance is evaluated by comparing the values with the ground truth data. SegNet is a convolutional encoder–decoder model that is useful for segmentation. The architecture of the model is divided into an encoder and decoder, which is a type of feedforward neural network, in which the input and output convolution layers are symmetric (Fig. 4). The encoder extracts key elements by reducing the dimensions of the input data, and the decoder generates high-dimensional data based on the compressed information (Garcia-Garcia et al. 2017). The encoder performs downsampling, which includes convolution layers that generate a feature map and 2D max pooling layers (Fig. 4). A 3 × 3 filter was applied to the convolution layer, whereas a 2 × 2 filter was applied to the 2D max pooling layers to form a feature map (Badrinarayanan et al. 2017). The decoder enables the convolution and upsampling of the 2D layers to reconstruct a higher-dimensional output from the previous feature map at each step. The final layer after decoding defines a softmax layer for classification, and the output image is normalized between zero and one (Simonyan and Zisserman 2014).

Deep learning workflow structure of the convolutional neural network (CNN)-based image segmentation of pore features in the SEM image of the NCM particle

Detailed architecture of the CNN model used for the automated segmentation of pore features in SEM images
In the encoding part of the SegNet architecture, the low-dimensional feature extraction of the input images was performed using two 2D convolution and 2D max pooling layers. This downsampling process is repeated twice to reduce the dimensions of the input images. Subsequently, a dense layer was added to arrange the low-dimensional features (Fig. 4). To decode the feature information and reconstruct the output image, 2D upsampling and 2D convolution layers were designed symmetrically (Fig. 4). In the last layer of the classification model, a softmax layer was added to categorize the output features into two labels (Badrinarayanan et al. 2017), which represent pores and grains. Adam was used to optimize the learning efficiency of the model (Kingma and Adam 2014), and binary cross-entropy was used to estimate learning loss. The callback function of ReduceLROnPlateau was used to dynamically reduce the learning rate when a metric has stopped improving. As parameters used in the callback, the function of ‘monitor’ was set to ‘val_loss’ with a factor of 0.2, and the values of patience and verbose were set to 10 and 1, respectively, in ‘auto’ mode with the minimum learning rate (min_lr) of 1 × 10–5. The model was trained for 100 epochs with a batch size of 32. The total number of parameters used in this process was 331,137. The model’s performance was evaluated by comparing the predicted data with the ground truth results. The language used for writing code in this study was Python, and the deep learning workflow was constructed using Keras.
Results and discussion
Figure 5 shows the performance of the model based on the training and test datasets as a function of the epochs. Accuracy, F1 score, and mean squared error (MSE) are the indicators considered for evaluating the classification performance of a CNN model. The model trained for 100 epochs exhibits an accuracy of > 97% for feature segmentation regarding pore detection on the input datasets with suppressed overfitting (Additional file 1; Fig. S2). The results shown in Fig. 5 confirm that the learning efficiency of the model improves when histogram equalization data are used for training and testing. The learning accuracy of the model with the equalization data is saturated at a bit earlier epoch than the case with the unprocessed dataset. However, the model with the histogram stretching dataset requires 20 more epochs at least for learning stabilization showing the same performance (> 97% in accuracy and F1 score) as the model with the histogram equalization dataset (Fig. 5). Therefore, histogram equalization for preparing the input image dataset is an advisable strategy for the reliable learning of the CNN model for segmentation tasks.

Training and test scores of the CNN-based pore segmentation model in terms of (a, b) accuracy, (c, d) F1 score, and (e, f) mean squared error as a function of learning epoch
Factors for assessing model performance can be monitored based on the relationship between the predicted output and ground truth data. As listed in Table 1, these relationships can be classified into four types. When the model’s prediction corresponds to the actual result, this case is defined as a true positive (TP). Meanwhile, when the model indicates that the predicted answer is true despite the actual value being false, this case is categorized as a false positive (FP). Similarly, the opposite two cases are categorized as false negative (FN) and true negative (TN) (Table 1). Given that the TP and TN cases exist, the accuracy of the model’s prediction can be intuitively measured using the following expression: \(\left( {{\text{Accuracy}}} \right) = \frac{{{\text{TP}} + {\text{TN}}}}{{{\text{TP}} + {\text{FN}} + {\text{FP}} + {\text{TN}}}}\). We measured the F1 score to estimate the model’s performance. The F1 score is defined as the harmonic average of the precision and recall values, i.e., \(\left( {{\text{F}}1\;{\text{score}}} \right) = 2{*}\left( {\frac{1}{{\frac{1}{{{\text{Precision}}}} + \frac{1}{{{\text{Recall}}}}}}} \right) = 2{*}\left( {\frac{{{\text{Precision}}*{\text{Recall}}}}{{{\text{Precision}} + {\text{Recall}}}}} \right)\). By comparing the pixel values of the actual image with those of the predicted image, the MSE value was obtained as the average of the square of the errors, i.e., \({\text{MSE}} = \frac{1}{n}\mathop \sum \limits_{i = 1}^{n} \left( {\widehat{{Y_{i} }} - Y_{i} } \right)^{2}\), where \(Y_{i}\) and \(\widehat{{Y_{i} }}\) are the predicted value and the actual value, respectively.
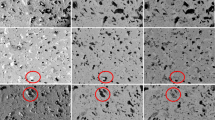
The estimated classification accuracy, F1 score, and MSE values obtained using the proposed model are listed in Table 2. The results indicate that the established CNN model can reliably predict the output image at an accuracy of > 97% after it is sufficiently trained for up to 100 epochs. Figure 6 shows the model performance regarding the segmentation of pores in NCM secondary particles. Figure 6a shows the input images (top) and ground-truth images of the pores (bottom) prepared based on human inputs. The predicted results obtained using the CNN model have better agreed with the ground truth results (Fig. 6b) compared to the process with the commonly used digital threshold (Fig. 6c), demonstrating that the model is successfully trained for pore segmentation based on the SEM image dataset of the NCM secondary particle. Owing to the effect of preprocessing the input image data for learning accuracy, the model performs slightly better when the input image is processed based on stretching and equalization before being fed to the model for training and testing (Table 2 and Fig. 6b). We note that the predicted result by the CNN model with unprocessed image dataset shows poor performance for pore segmentation (Additional file 1: Fig. S3).

Arrays of a the original BSE images and corresponding ground truth input images prepared for the training and performance test of the CNN-based segmentation model. b The corresponding output image arrays generated by the CNN-based segmentation model combined with the histogram stretching and histogram equalization processes. c The corresponding output image arrays generated using the digital threshold process implemented in Avizo software, which has been used for tomographic volume reconstruction
To assess the geometric parameters of the NCM secondary particles with respect to the different 2D segmentation approaches (ground truth measurement, digital threshold process, and CNN-assisted process combined with histogram stretching or equalization), we reconstructed the 3D pore volumes using the 2D segmentation image datasets prepared by each method. Figure 7a shows the reconstructed pore volumes obtained from this perspective. By analyzing the 3D pore volumes, the total porosity (Pt), total pore volume (Vt), and total pore surface area (St) were obtained for each process, as shown in Fig. 7b. From the results, we can see that the CNN-assisted pore segmentation after the preprocessing of histogram equalization shows the best fit to the ground truth data. However, the results based on the digital threshold process and CNN-assisted process combined with histogram stretching show that the estimation of geometrical parameters can be exaggerated by several percentages. This comparison suggests that the CNN-based automated segmentation process combined with the histogram equalization treatment of the SEM images allows a reliable estimation of the geometrical pore characteristics of NCM cathode particles close to the ground truth result. Considering the high accuracy of the CNN model (> 97%) for binary segmentation, we expect that the algorithm established in this study can be used as an effective analytical tool to address the segmentation problems arising from other polycrystalline materials with internal pores. The source code (written by Python) of the trained model for pore structures in NCM secondary particles is available in the public domain of GitHub (Lee 2023).

Tomographic volume reconstruction. a Perspective views of the 3D reconstructed volumes of pore distribution inside the NCM secondary particle. The tomographic volumes were reconstructed with different 2D pore segmentation images obtained using the ground truth measurement, digital threshold process, and CNN-assisted process combined with histogram stretching or equalization. The reconstructed dimensions were set to 2.3 (x) µm × 2.3 (y) µm × 1.5 (z) µm. b Total porosity (Pt), total pore volume (Pv), and total surface area (St) of the NCM secondary particle, which were measured from the reconstructed tomographic volumes
Conclusions
We demonstrated that the proposed CNN model reliably performs binary segmentation for porous materials, e.g., NCM electrode materials, without human intervention. The model automatically expedited the segmentation process for a large dataset of SEM images to evaluate the porosity of materials and exhibited high accuracy (> 97%) by systematically comparing performance evaluation factors as a function of the training epoch. High performance was assured when the input images were preprocessed using hysteresis thresholding and histogram equalization, thereby indicating the importance of the optimized preprocessing of the input dataset for reliable functioning of the established CNN model. The measured porosity of the material using the CNN model was well consistent with the ground truth 3D electron tomography result. This implies that the labor-intensive effort required for pore structure analysis can be substantially reduced to obtain equivalent information on the porosity of polycrystalline porous materials.
Availability of data and materials
Upon reasonable request, the datasets of this study can be available from the corresponding author.
References
Abdullah-Al-Wadud M, Kabir MH, Dewan MAA, Chae O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans Consum Electron. 2007;53(2):593–600.
Andrä H, Combaret N, Dvorkin J, Glatt E, Han J, Kabel M, Keehm Y, Krzikalla F, Lee M, Madonna C, Marsh M, Mukerji T, Saenger EH, Sain R, Saxena N, Ricker S, Wiegmann A, Zhan X. Digital rock physics benchmarks—part I: imaging and segmentation. Comput Geosci. 2013;50:25–32.
Azimi SM, Britz D, Engstler M, Fritz M, Mücklich F. Advanced steel microstructural classification by deep learning methods. Sci Rep. 2018;8(1):1–14.
Badrinarayanan V, Kendall A, Cipolla R. Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans Pattern Anal Mach Intell. 2017;39(12):2481–95.
Burnett T, Kelley R, Winiarski B, Contreras L, Daly M, Gholinia A, Burke M, Withers P. Large volume serial section tomography by Xe Plasma FIB dual beam microscopy. Ultramicroscopy. 2016;161:119–29.
Cantoni M, Holzer L. Advances in 3D focused ion beam tomography. MRS Bull. 2014;39(4):354–60.
Chatfield K, Simonyan K, Vedaldi A, Zisserman A. Return of the devil in the details: delving deep into convolutional nets. (2014). Available from: https://arxiv.org/abs/14053531.
Chen Y, Deng C, Chen X. An improved canny edge detection algorithm. IJHIT. 2015;8(10):359–70.
Chen Z, Wang J, Chao D, Baikie T, Bai L, Chen S, Zhao Y, Sum TC, Lin J, Shen Z. Hierarchical porous LiNi1/3Co1/3Mn1/3O2 nano-/micro spherical cathode material: minimized cation mixing and improved Li(+) mobility for enhanced electrochemical performance. Sci Rep. 2016;6:25771.
Comer ML, Delp EJ. The EM/MPM algorithm for segmentation of textured images: analysis and further experimental results. IEEE Trans Image Process. 2000;9(10):1731–44.
Condurache A-P, Aach T. Vessel segmentation in angiograms using hysteresis thresholding. MVA 2005. Tsukuba Science City, Japan, Citeseer (2005).
Finegan D, Squires I, Dahari A, Kench S, Jungjohann K, Cooper S. Machine-learning-driven advanced characterization of battery electrodes. ACS Energy Lett. 2022;7(12):4368–78.
Galbany J, Martínez L, López-Amor H, Espurz V, Hiraldo O, Romero A, de Juan J, Pérez-Pérez A. Error rates in buccal-dental microwear quantification using scanning electron microscopy. Scanning. 2005;27(1):23–9.
Garcia-Garcia A, Orts-Escolano S, Oprea S, Villena-Martinez V, Garcia-Rodriguez J. A review on deep learning techniques applied to semantic segmentation. (2017). Available from: https://arxiv.org/abs/170406857.
Gesho M, Chaisoontornyotin W, Elkhatib O, Goual L. Auto-segmentation technique for SEM images using machine learning: asphaltene deposition case study. Ultramicroscopy. 2020;217:113074.
Gupta S, Agrawal A, Gopalakrishnan K, Narayanan P. Deep learning with limited numerical precision. ICML. PMLR; (2015). pp 1737–46.
He K, Zhang X, Ren S, Sun J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. ICCV. 2015; pp 1026–34.
Hong JA, Jung M-H, Cho SY, Park E-B, Yang D, Kim Y-H, Yang S-H, Jang W-S, Jang JH, Lee HJ. Segmented tomographic evaluation of structural degradation of carbon support in proton exchange membrane fuel cells. J Energy Chem. 2022;74:359–67.
Im J, Jeon J, Hayes MH, Paik J. Single image-based ghost-free high dynamic range imaging using local histogram stretching and spatially-adaptive denoising. IEEE Trans Consum Electron. 2011;57(4):1478–84.
Kim Y-H, Yang S-H, Jeong M, Jung M-H, Yang D, Lee H, Moon T, Heo J, Jeong HY, Lee E, Kim Y-M. Hybrid deep learning crystallographic map** of polymorphic phases in polycrystalline Hf0.5Zr0.5O2 thin films. Small. 2022;18(18):2107620.
Kingma D P, Ba J. Adam, A method for stochastic optimization. 2014. Available from: https://arxiv.org/abs/1412.6980
Konvalina I, Mika F, Krátký S, Materna Mikmeková E, Müllerová I. In-lens band-pass filter for secondary electrons in ultrahigh resolution SEM. Materials. 2019;12(14):2307.
Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst. 2012;25.
Lee H-B. SKKU-STEM/Pore-segnet, 2023. https://github.com/SKKU-STEM/Pore-segnet. Accessed 20 Aug 2023.
Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. CVPR. 2015; pp 3431–40.
Luo W, Duan S, Zheng J. Underwater image restoration and enhancement based on a fusion algorithm with color balance, contrast optimization, and histogram stretching. IEEE Access. 2021;9:31792–804.
Nanfack G, Elhassouny A, Thami ROH. Squeeze-SegNet: a new fast deep convolutional neural network for semantic segmentation. ICMV 2017. SPIE; 2018. Pp. 703–10.
Ntogas N, Veintzas D. A binarization algorithm for historical manuscripts, WSEAS Math Comput Sci Eng. World Scientific and Engineering Academy and Society; 2008. Pp. 41–51.
Oliver WR. Histogram stretching or histogram equalization in image processing. Micros Today. 1998;6(3):20–4.
Osenberg M, Hilger A, Neumann M, Wagner A, Bohn N, Binder J, Schmidt V, Banhart J, Manke I. Classification of FIB/SEM-tomography images for highly porous multiphase materials using random forest classifiers. J Power Sources. 2023;570:233030.
Pietsch P, Wood V. X-ray tomography for lithium ion battery research: a practical guide. Annu Rev Mater Res. 2017;47:451–79.
Ramadan ZM. Effect of kernel size on Wiener and Gaussian image filtering. Telecommun Comput Electron Control. 2019;17(3):1455–60.
Roldán D, Redenbach C, Schladitz K, Klingele M, Godehardt M. Reconstructing porous structures from FIB-SEM image data: Optimizing sampling scheme and image processing. Ultramicroscopy. 2021;226:113291.
Schwarz SM, Kempshall BW, Giannuzzi LA, McCartney MR. Avoiding the curtaining effect: backside milling by FIB INLO. Microsc Microanal. 2003;9(S02):116–7.
Schwartz J, Jiang Y, Wang Y, Aiello A, Bhattacharya P, Yuan H, Mi Z, Bassim N, Hovden R. Removing stripes, scratches, and curtaining with nonrecoverable compressed sensing. Microsc Microanal. 2019;25(3):705–10.
Shim JH, Kim YH, Yoon HS, Kim HA, Kim JS, Kim J, Cho NH, Kim YM, Lee S. Hierarchically structured core-shell design of a lithium transition-metal oxide cathode material for excellent electrochemical performance. ACS Appl Mater Interfaces. 2019;11(4):4017–27.
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. 2014. Available from: https://arxiv.org/abs/14091556.
Song J-H, Bae J, Lee K-W, Lee I, Hwang K, Cho W, Hahn SJ, Yoon S. Enhancement of high temperature cycling stability in high-nickel cathode materials with titanium do**. J Ind Eng Chem. 2018;68:124–8.
Stathis P, Kavallieratou E, Papamarkos N. An evaluation technique for binarization algorithms. J Univ Comput Sci. 2008;14(18):3011–30.
Wang L, You S, Neumann U. Supporting range and segment-based hysteresis thresholding in edge detection. ICIP 2008. IEEE; 2008; pp. 609–12.
Yang Y, Li N, Wang B, Li N, Gao K, Liang Y, Wei Y, Yang L, Song W, Chen H. Microstructure evolution of lithium-ion battery electrodes at different states of charge: deep learning-based segmentation. Electrochem Commun. 2022;136:107224.
Young IT, Van Vliet LJ. Recursive implementation of the Gaussian filter. Sig Process. 1995;44(2):139–51.
Zang J, Liu J, He J, Zhang X. Characteristics of the pore structure in Chinese anthracite coal using FIB-SEM tomography and deep learning-based segmentation. Energy. 2023;282:128686.
Zhang J, Hu J. Image segmentation based on 2D Otsu method with histogram analysis. CSSE. 2008;2008:105–8.
Acknowledgements
Not applicable.
Funding
This paper was supported by the Sungkyun Research Fund, Sungkyunkwan University, 2017.
Author information
Authors and Affiliations
Contributions
H-BL contributed to conceptualization, methodology, software, validation, investigation, data curation, writing—original draft, and visualization. M-HJ contributed to methodology, validation, investigation, data curation, writing—original draft, and visualization. Y-HK contributed to data curation, and investigation. E-BP contributed to data curation, and investigation. W-SJ contributed to investigation, and visualization. S-JK contributed to investigation, and visualization. KC contributed to visualization, and investigation. JP contributed to investigation. KH contributed to investigation. J-HS contributed to investigation. SY contributed to supervision, investigation, writing—review & editing. Y-MK contributed to conceptualization, methodology, data curation, supervision, writing—review & editing, project administration, and funding acquisition. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
No potential conflicts of interest relevant to this article exist.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Fig. S1.
Effect of FFT and Gaussian filters for preparing input images. a Cross-sectional backscatter electron (BSE) SEM image of an NCM secondary particle as acquired without filtering. The vertical stripe-type contrast artifacts are formed due to the curtaining effect. b FFT filtered BSE SEM image to remove vertical stripe artifacts. c Prepared input image after removing statistical noise background by Gaussian filter for the FFT filtered image. Fig. S2. Application of the trained model to a different NCA secondary particle for detection and segmentation performance for irregular shape pores. This extra data supports that the accuracy of >97% for feature segmentation is well maintained, thus suggesting the model’s generalizability. Fig. S3. Comparison of pore segmentation performance between human-driven process with preprocessed image dataset and CNN-assisted process with unprocessed image dataset. Without preprocessing, false-positive detection in feature segmentation was notably increased for using the CNN-assisted process. This result indicates the importance of preprocessing of input images for deep learning-assisted pore segmentation.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lee, HB., Jung, MH., Kim, YH. et al. Deep learning image segmentation for the reliable porosity measurement of high-capacity Ni-based oxide cathode secondary particles. J Anal Sci Technol 14, 47 (2023). https://doi.org/10.1186/s40543-023-00407-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40543-023-00407-z