
Abstract
Polyadenylation of pre-messenger RNA (pre-mRNA) specific sites and termination of their downstream transcriptions are signaled by unique sequence motif structures such as AAUAAA and its auxiliary elements. Alternative polyadenylation (APA) is an important post-transcriptional regulatory mechanism that processes RNA products depending on its 3′-untranslated region (3′-UTR) specific sequence signal. APA processing can generate several mRNA isoforms from a single gene, which may have different biological functions on their target gene. As a result, cellular genomic stability, proliferation capability, and transformation feasibility could all be affected. Furthermore, APA modulation regulates disease initiation and progression. APA status could potentially act as a biomarker for disease diagnosis, severity stratification, and prognosis forecast. While the advance of modern throughout technologies, such as next generation-sequencing (NGS) and single-cell sequencing techniques, have enriched our knowledge about APA, much of APA biological process is unknown and pending for further investigation. Herein, we review the current knowledge on APA and how its regulatory complex factors (CFI/IIm, CPSF, CSTF, and RBPs) work together to determine RNA splicing location, cell cycle velocity, microRNA processing, and oncogenesis regulation. We also discuss various APA experiment strategies and the future direction of APA research.
Similar content being viewed by others
Introduction
Splicing, cap**, and polyadenylation are three major steps in processing pre-messenger RNA (pre-mRNA) to mRNA [1, 2]. Polyadenylation (poly(A)) involves in endonucleolytic cleavage of pre-mRNA and addition of the poly(A) tail at the cleavage site [1]. Individual pre-mRNA usually harbors a few cleavage/polyadenylation (C/P) sites (polyA sites or pA) [2]. Alternative polyadenylation (APA) can eventually produce several mRNA polyadenylation isoforms [5, 6]. The 3′-UTRof mRNA harbors key RNA regulatory elements that determine when, where, and how much mRNA transcript will be translated [1]. APA is a crucial 3′-UTR post-transcriptional regulation mechanism. The 3′-UTR APA isoforms play various roles in determining mRNA stability, localization, half-life, and functions. Furthermore, previous studies demonstrated that APA is involved in disease progression and drug sensitivity, especially for drugs targeting chromatin modifiers [2, 7,8,9]. Though APA research is still in its early stage, its unique post-transcriptional regulatory effect makes it potentially both a biomarker for cancer prognosis and diagnosis, and a target for novel target therapy development [10, 11].
How APA modulates pre-mRNA
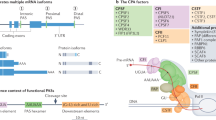
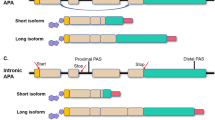
Based on the locations of pAs, APA can be classified into two major categories: UTR-APA (Fig. 1a) and coding region-APA (CR-APA) (Fig. 1b-d). For CR-APA, alternative pAs are located in exons or introns. Therefore, CR-APA affects coding regions via alternative splicing (AS), leading to generation of protein isoforms with distinct C-termini [12, 13]. For UTR-APA, alternative pAs are located in the 3′-UTR, leading to the transcription products containing the same coding frame but variable 3′-UTRs. Previous studies suggested that global UTR-APA events are tissue-specific, with3′-UTR shortening positively correlates to cell proliferation and negatively to cellular differentiation [14,15,16].

Comparison of APA and AS. a-c The patterns of APA can be classified into two main types: UTR-APA and CR-APA. For UTR-APA, alternative PAS resides in the 3′-UTR. Therefore, UTR-APA can generate transcripts with varying UTR lengths without changing the coding sequences. There are major types of CR-APA that may yield transcripts with truncated coding sequence. d Yellow is used to label the extended exon. For AS, e-constitutive splicing; f exon skip**/ inclusion;g alternative 5′-splice sites;h alternative 3′-splice sites; i intron retention; j mutually exclusive exons
The pre-mRNA 3′-processing complex is formed by several elements, including the canonical poly(A) signal sequence AAUAAA or its close variants (e.g. AAAUAA, AUAAAA, AUUAAA, AUAAAU, AUAAAG, CAAUAA, UAAUAA, AUAAAC, AAAAUA, AAAAAA, AAAAAG), which are utilized with varying frequencies throughout the genome, usually within 15–50 nts from the pA site [6, 8, 17,18,19,20]. UGUA elements are often located upstream of the pA site, U-rich elements are located near the pA site, and U/GU-rich elements are located within ~ 100 nts downstream of the pA site [7, 21, 22]. However, ~ 20% of human poly(A) signals are not surrounded by U−/GU-rich regions [23].
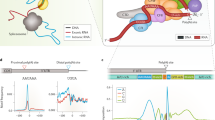
Out of 80 core factors in mammalian cells, about 20 of them are involved in the C/P machinery [24,25,26]. Generally, these core factors can be divided into four elements as followings (Fig. 2) [27, 28]:

The APA complex and its machinery. CFIm complex binds to the conserved upstream UGUA region to mediate the cleavage reaction and recruit other proteins, including CPSF and CSTF. After combining with PAP, this complex translocates through the pre-mRNA in a 5′ to 3′ fashion. Upon arrival at the AAUAAA region, the adenosine acidification signal CPSF recognizes the polyadenylation signal AAUAAA and CPSF73 cleaves the mRNA. CSTF then binds to the GU- or U-rich sequence. The U-rich region bound to the FIP1L1 subunit of the CPSF is located between the polyadenylation signal AAUAAA and the cleavage site. Symplekin functions as a scaffold protein and PAPs catalyze the addition of untemplated adenosines. Generally, the usage of the proximal pAs generates short isoforms and the translation can be suppressed, often resulting in less protein
CPSF (cleavage and polyadenylation specificity factor) is composed of CPSF1–CPSF4 (also known as CPSF160, CPSF100, CPSF73 and CPSF30), WDR33 and FIP1L1 (also known as Fip1) [22, 29]. The current understanding is that WDR33 and CPSF4 directly interact with pAs, and CPSF3 carries out the endonucleolytic cleavage [30, 31]. Working as a complex, CPSF recognizes the polyadenylation signal sequence AAUAAA and cleaves the pre-mRNA. This provides sequence specificity that may play an important role in regulating pA site selection, gene expression, cancer cell migration, metastasis, and eventually disease outcome [32]. As a part of CPSF complex, CPSF73 is an endonuclease that cleaves the pre-mRNA at the pA site [33]. However, under oxidative stress, CPSF73 translocates from the nucleus to the cytosol and causes significant inhibition of polyadenylation activity in prostate cancers [34]. Furthermore, Fip1, a member of the CPSF complex, potentially serves as a regulator of cellular self-renewal. Indeed, Fip1 depletion in mouse embryonic stem cells (ESCs) results in loss of cellular undifferentiated states and self-renewal capabilities due to the usage of preferred distal poly(A) site (dpA), ultimately leading to 3′-UTR lengthening of selected genes that determine the cell fate [35].
CSTF (cleavage stimulation factor) is composed of CSTF1, CSTF2, and CSTF3 (50 kDa, 64 kDa, and 77 kDa, respectively), and plays a key role in the cleavage reaction [36, 37]. CSTF complex can bind to the U- or GU-rich field downstream of the cleavage site to boost cleavage. For example, CSTF2, also known as CSTF64, directly interacts with the U/GU-rich region to modulate the 3′-terminal processing efficiency [38, 39]. Some studies reported that CSTF not only promote the usage of pAs, but also affect cell proliferation and potentially act as a biomarker of cancer invasion and prognosis [40, 41]. CSTF64 acts as an essential polyadenylation factor and a master regulator of 3′-UTR shortening across multiple tumor types. The expression of CSTF64 was found to be associated with poor lung cancer prognosis and overexpression of CSTF64 promoted lung cancer cell proliferation and invasion [25].
CFI and CFII (cleavage factors I and II) are consisted of CFIm25 (also known as NUDT21/nudix hydrolase 21/CPSF5), CFIm59 and CFIm68, all of which bind upstream of the conserved UGUA motif to mediate the cleavage reaction [28, 42]. CFIm binding can function as a primary determinant of pA sites by loo** out an entire pA region and thereby inducing the selection of an APA site [43]. Other proteins, including symplekin, poly(A) polymerase (PAP), and poly(A) binding protein (PAB), can regulate APA site selection as well. PABs (PABII, RBBP6, PABPN1) bind to the growing poly(A) tail, preventing the interaction between CPSF and the poly(A) polymerase. Those activities primarily occur when the tail is ~ 250 nts and the purpose of which is to control poly(A) tail length while APA in progression [44, 45].
The factors involved in the C/P machinery usually participate in APA regulation. Among them, CFIm25 has been identified as the major global regulator of APA, whose knockdown not only induce a global switch to the use of proximal poly(A) signal, but also enhance target gene stability and expression [41, 59].
Additionally, APA can be regulated at the transcription level. The transcription machinery, such as transcription initiation, progression, and splicing, is likely to affect the efficiency and specificity of polyadenylation [60]. Therefore, investigating the association between the specific sequence elements at the promoter region and the poly(A) site selection will greatly aid us in uncovering the mechanism behind this interesting phenomenon, which may potentially help in develo** a novel cancer therapy strategy [61].
How APA is methodologically analyzed
Since the effects of pAs in IgM and dihydrofolate reductase (DHFR) gene encoding were observed in 1980, a series of stringent research methods and strategies have been developed to identify and study APA, such as the Poly(A)-ClickSeq next-generation sequencing (NGS) technology [62,18, 70]. Though it has reading length limitation, a range of RNA-seq algorithms have been developed to quantify relative changes in 3′-UTR length, therefore to predict APA events. Several pA detection and APA analytical methods and algorithms also have been developed in the last several years, such as Dynamic Analyses of Alternative PolyA Adenylation (DaPars), 3USS, MISO, Roar, QAPA, and Change Points [74]. The limitation of QAPA is that it requires pre-defined pAs. However, this problem can be mitigated by the generation of an expanded resource of annotated pAs that incorporate data from 3′-UTR RNA-seq and other resources [74]. Because of reading coverage biases at the 3′-terminus of transcripts, poor yields of non-templated poly(A) tail-containing reads, and ambiguity of read map** in overlap** transcript isoforms, the methods based on canonical RNA-seq data are limited while attempting to precisely map the pAs [18, 76]. However, with the advance of molecular technology, the methods to study APA have been continuously growing. Wang et al. used CRISPR/Cas9 methodology to study the biological function of APA via editing the weak poly(A) signal to a canonical poly (A) signal and directing the signals to target specific poly(A) sites [77].
In brief, each of current available APA analytic methods has its advantages and limitations. The analytical strategies based on canonical RNA-seq data are utilized most within the APA research community.
Single-cell level study The advantage of single-cell approach is that it can significantly reduce the background noise from bulk cells that contain a mixture of RNA material extracted from cells originating from various tissues or differentiations.
With the development of single-cell analysis technology, APA variations among the cells has been recently investigated [78]. Though single-cell APA research has rarely been conducted on a large scale, this technique works on high-depth and full-length of single-cell RNA-seq (scRNA-seq), which makes it a possible tool to accurately analyze APA. **gle Bells and scRNA-SeqDB (https://bioinfo.uth.edu/scrnaseqdb/) utilized scRNA-seq datasets to investigate a variety of cancer types [79]. Ye et al. reported the use of scRNA-seq data to investigate dynamic APA usage variations in different bone marrow mononuclear cell types from a large sample collections containing both healthy controls and AML patients. They found that, in comparing to healthy individuals, AML patients appear to have lower APA diversity among eight different cell types. They further revealed extensive involvement of APA regulation in erythropoiesis during leukemia progression at the single-cell level [50]. By analyzing 515 scRNA-seq datasets extracted from 11 breast cancer patients, Kim et al. reported that cell-type-specific APA can be identified in single cell level based on 3′-UTR length variation in combination with gene expression level and APA patterns. Moreover, they demonstrated that immune-specific APA signatures in breast cancer can potentially be utilized as a prognostic marker for early stage breast cancers [31].
APA and alternative splicing: Though there are significant differences between APA and alternative splicing (AS), both APA and AS can generate various isoforms, even interacting with each other during pre-mRNA process. Additionally, while APA has four typical isoforms, AS has six (Fig. 2). Several in-depth analyses of transcriptomic data from various human tissues and cell lines revealed a strong correlation between APA and AS [6, 55, 80]. If the pA is within the terminal exon, the APA can act like a special type of AS, named CR-APA, which cannot possess an in-frame stop codon or 3′-UTR and is likely to be degraded rapidly through the non-stop code mediated mRNA decay process (Fig. 1b) [11, 12, 81]. Shen et al. reported that APA and splicing factor SRSF3 worked together to modulate the cell-aging process [82]. While APA may play a role in some splicing factor-mediated AS, splicing factors may also work with APA elements to assist in this process. For example, U2AF2 and RBPs are capable of interacting and recruiting CFI to facilitate 3′-terminus formation near the polypyrimidine tracts [79, 83]. Furthermore, CPSF complex can interact with splicing factor TFIID (transcription factor II D) in regulating RNA polymerase II [84, 85]. It is also observed that U1 snRNP (small nuclear ribonucleoprotein) can work within introns by suppressing premature cleavage and polyadenylation. U1 depletion also leads to the activation of intron poly(A) signals and causes genome-wide APA [86, 87].
AS and APA also compete each other while in CR-APA. For example, the ablation of the splicing factor 3B subunit1 (a component of U2 snRNP, also named SF3b1) can activate the intron PAS. U1 snRNP can also independently influence APA splicing activities [88]. Since U1 snRNP can bind to the 5′-terminal region of the transcript and block potential cleavage factor recognition, U1 snRNP knockdown increases the utilization of the pA sites within introns close to that transcript area [89, 90]. However, Movassat et al. demonstrated that the association between APA and AS is limited to terminal introns [91]. They also demonstrated that CstF64 knockdown can indirectly influence the AS of hnRNP A2/B1, but not APA, in HeLa cells [92].
How APA regulate cell cycle
There are many genes, including TP53, CDC6 (cell division cycle 6), CyclinD1 (CCND1), and CDK (cyclin-dependent kinase), are associated with cell cycle checkpoints and regulate cell cycle progression. As pre-mRNA usually has more than one pA sites, the cell cycle relevant gene products are modulated by the APA mechanism and generate various isomers. 3′-UTR shortening of CDC6, a major regulator of DNA replication, is linked to higher CDC6 protein levels and increased S-phase entry in breast cancer cells [93]. Cyclin D1, which plays a critical role in promoting G1–S phase transition in many cell types, is subject to APA regulation via both UTR-APA and CR-APA mechanisms [77, 94]. In addition, **ang et al. examined the top 10% of all 20,532 genes associated with APA events and observed that most of these genes participate in chromatin structure-related activities, suggesting a relationship between APA processing and chromatin structure modification [53]. Mitra et al. found that APA acts as a linkage between cell cycle and tissue migration through analyzing mice dermal excisional wounds [17]. They demonstrated that proliferating cells adjacent to wounds express higher levels of APA factors than quiescent fibroblasts in unwounded skin. PIGN, which regulates cell cycle through interacting with the spindle assembly checkpoint proteins, is found to harbrt 6 pA sites in its 3′-UTR (Fig. 3) [95].

Track of PIGN by Grch37/hg19. PIGN location in chromosome18(q21.33) has three transcripts. There are 6 pAs in the polyA database
How APA interacts with miRNA in post-transcriptional modulation
More than 50% of conserved microRNAs (miRNAs) target sites residing downstream of proximal pAs in mammalian genes. As a result, the UTR-APA plays a key role in regulating the interaction between transcripts and miRNAs [96]. APA is recently identified as a widespread mechanism controlling gene stability and expression. The miRNA targeting sites are mostly located in 3′-UTR [ APA Impacts at molecular, cellular, and clinical levels. a APA can affect cell functions through various molecular mechanisms;b&c APA has relationship with many type diseases and the diagnosis, prognosis and treatment of diseases
Conclusion
APA is a crucial post-transcriptional regulatory mechanism that could generate various mRNA isoforms from a single gene. Each mRNA isoform eventually translates into a protein product with unique biological functions. APA could regulate almost every major step of molecular cell biological process, such as cellular genomic stability, proliferation capability, and transformation feasibility. Our journal of understanding APA is just beginning. However, the emerging evidences indicate that APA, at least, could be potentially a biomarker for disease diagnosis, severity stratification, and prognostic forecast; and possibly a novel therapy target.
