
Abstract
Mass spectrometry based non-target analysis is increasingly adopted in environmental sciences to screen and identify numerous chemicals simultaneously in highly complex samples. However, current data processing software either lack functionality for environmental sciences, solve only part of the workflow, are not openly available and/or are restricted in input data formats. In this paper we present patRoon, a new R based open-source software platform, which provides comprehensive, fully tailored and straightforward non-target analysis workflows. This platform makes the use, evaluation and mixing of well-tested algorithms seamless by harmonizing various common (primarily open) software tools under a consistent interface. In addition, patRoon offers various functionality and strategies to simplify and perform automated processing of complex (environmental) data effectively. patRoon implements several effective optimization strategies to significantly reduce computational times. The ability of patRoon to perform time-efficient and automated non-target data annotation of environmental samples is demonstrated with a simple and reproducible workflow using open-access data of spiked samples from a drinking water treatment plant study. In addition, the ability to easily use, combine and evaluate different algorithms was demonstrated for three commonly used feature finding algorithms. This article, combined with already published works, demonstrate that patRoon helps make comprehensive (environmental) non-target analysis readily accessible to a wider community of researchers.
Similar content being viewed by others
Introduction
Chemical analysis is widely applied in environmental sciences such as earth sciences, biology, ecology and environmental chemistry, to study, e.g. geomorphic processes (chemical) interaction between species or the occurrence, fate and effect of chemicals of emerging concern in the environment. The environmental compartments investigated include air, water, soil, sediment and biota, and exhibit a highly diverse chemical composition and complexity. The number and quantities of chemicals encountered within samples may span several orders of magnitude relative to each other. Therefore, chemical analysis must discern compounds at ultra-trace levels, a requirement that can be largely met with modern analytical instrumentation such as liquid or gas chromatography coupled with mass spectrometry (LC-MS and GC–MS). The high sensitivity and selectivity of these techniques enable accurate identification and quantification of chemicals in complex sample materials.
Traditionally, a ‘target analysis’ approach is performed, where identification and quantitation occur by comparing experimental data with reference standards. The need to pre-select compounds of interest constrains the chemical scope of target analysis, and hampers the analysis of chemicals with (partially) unknown identities such as transformation products and contaminants of emerging concern (CECs). In addition, the need to acquire or synthesize a large number of analytical standards may not be feasible for compounds with a merely suspected presence. Recent technological advancements in chromatography and high resolution MS (HRMS) allows detection and tentative identification of compounds without the prior need of standards [1]. This ‘non-target’ analysis (NTA) approach is increasingly adopted to perform simultaneous screening of up to thousands of chemicals in the environment, such as finding new CECs [1,2,3,4,5,6], identifying chemical transformation (by)products [7,8,9,10,11,12] and identification of toxicants in the environment [13,14,15,16].
Studies employing environmental NTA typically allow the detection of hundreds to thousands of different chemicals [17, 18]. Effectively processing such data requires workflows to automatically extract and prioritize NTA data, perform chemical identification and assist in interpreting the complex resulting datasets. Currently available tools often originate from other research domains such as life sciences and may lack functionality or require extensive optimization before being suitable for environmental analysis. Examples include handling chemicals with low sample-to-sample abundance, recognition of halogenated compounds, usage of data sources with environmentally relevant substances, or temporal and spatial trends [1, 2, 5, 6, 9, 19].
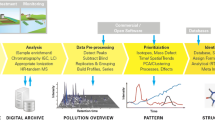
An NTA workflow can be generalized as a four step process (Fig. 1) [1]. Firstly, data from LC or GC-HRMS is either acquired or retrieved retrospectively, and pre-treated for subsequent analysis (Fig. 1a). This pre-treatment may involve conversion to open data formats (e.g. mzML [20] or mzXML [21]) to increase operability with open-source software, re-calibration of mass spectra to improve accuracy and centroiding [22] or other raw data reduction steps to conserve space such as trimming chromatographs or filtering mass scans (e.g. with the functionality from the ProteoWizard suite [23]). Secondly (Fig. 1b), features with unique chromatographic and mass spectral properties (e.g. retention time, accurate mass, signal intensity) are automatically extracted and features considered equivalent across sample analyses are grouped to allow qualitative and (semi-) quantitative comparison further down the workflow. Thirdly (Fig. 1c), the feature dataset quality is refined, for instance, via rule-based filters (e.g. minimum intensity and absence in sample blanks) and grou** of features based on a defined relationship such as adducts or homologous series (e.g. “componentization”). Further prioritization during this step of the workflow is often required for efficient data analysis, for instance, based on chemical properties (e.g. mass defect and isotopic pattern), suspected presence (i.e. “suspect screening”) or intensity trends in time and/or space (e.g. reviewed in [1]). Finally (Fig. 1d), prioritized features are annotated, for instance by assigning chemical formulae or compounds from a chemical database (e.g. PubChem [24] or CompTox [25]) based on the exact mass of the feature. The resulting candidates are ranked by conformity with MS data, such as match with theoretical isotopic pattern and in silico or library MS fragmentation spectra, and study-specific metadata, such as number of scientific references and toxicity data [1, 19].

Generic workflow for environmental non-target analysis
Various open and closed software tools are already available to implement (parts of) the NTA workflow. Commercial software tools such as MetaboScape [26], UNIFI [27], Compound Discoverer [28] and ProGenesis QI [29] provide a familiar and easy to use graphical user interface, may contain instrument specific functionality and optimizations and typically come with support for their installation and usage. However, they are generally not open-source or open-access and are often restricted to proprietary and specific vendor data formats. This leads to difficulties in data sharing, as exact algorithm implementations and parameter choices are hidden, while maintenance, auditing or code extension by other parties is often not possible. Many open-source or open-access tools are available to process mass spectrometry data, such as CFM-ID [30, 31], enviMass [32], enviPick [33], nontarget [34], GenForm [35], MetFrag [36], FOR-IDENT [37], MS-DIAL [38], MS-FINDER [39], MZmine [40], OpenMS [41], ProteoWizard [23], RAMClustR [42], SIRIUS and CSI:FingerID [43,44,45,46,47], XCMS [48], CAMERA [49] and XCMS online [50] (Table 1, further reviewed in [51, 52]). Various open tools are easily interfaced with the R statistical environment [53] (Table 1). Leveraging this open scripting environment inherently allows defining highly flexible and reproducible workflows and increases the accessibility of such workflows to a wider audience as a result of the widespread usage of R in data sciences. While many tools were originally developed to process metabolomics and proteomics data, approaches such as XCMS and MZmine have also been applied to environmental NTA studies [6, 54]. However, as stated above, these tools can lack the specific functionality and optimizations required for effective environmental NTA data processing. While a complete environmental NTA workflow requires several steps from data pre-processing through to automated annotation (see Fig. 1), existing software approaches designed for processing environmental data (e.g. enviMass and nontarget) and most others only implement part of the required functionality, as indicated in Table 1. Furthermore, only few workflow solutions support automated compound annotation. Moreover, available tools often overlap in functionality (Table 1), and are implemented with differing algorithms or employing different data sources. Consequently, tools may generate different results, as has been shown when generating feature data [55,Implementation The implementation section starts with an overview of the patRoon workflows. Subsequent sections provide details on novel functionality implemented by patRoon, which relate to data processing, annotation, visualization and reporting. Finally, a detailed description is given of the software architecture. patRoon is then demonstrated in the Results and discussion section. The software tools and databases used for the implementation of patRoon are summarized in Additional file 1. patRoon encompasses a comprehensive workflow for HRMS based NTA (Fig. 2). All steps within the workflow are optional and the order of execution is largely customizable. Some steps depend on data from previous steps (blue arrows) or may alter or amend data from each other (red arrows). The workflow commonly starts with pre-treatment of raw HRMS data. Next, feature data is generated, which consists of finding features in each sample, an optional retention time alignment step, and then grou** into “feature groups”. Finding and grou** of features may be preceded by automatic parameter optimization, or followed by suspect screening. The feature data may then finally be used for componentization and/or annotation steps, which involves generation of MS peak lists, as well as formula and compound annotations. At any moment during the workflow, the generated data may be inspected, visualized and treated by, e.g. rule based filtering. These operations are discussed in the next section. Overview of the NTA patRoon workflow. All steps are optional. Steps that are connected by blue and straight arrows represent a one-way data dependency, whereas steps connected with red curved and dashed arrows represent steps with two-way data interaction Several commonly used open software tools, such as ProteoWizard [23], OpenMS [41], XCMS [48], MetFrag [36] and SIRIUS [43,44,45,46,47], and closed software tools, such as Bruker DataAnalysis [61] (chosen due to institutional needs), are interfaced to provide a choice between multiple algorithms for each workflow step (Additional file 3: Table S1). Customization of the NTA workflow may be achieved by freely selecting and mixing algorithms from different software tools. For instance, a workflow that uses XCMS to group features allows that these features originate from other algorithms such as OpenMS, a situation that would require tedious data transformation when XCMS is used alone. Furthermore, the interface with tools such as ProteoWizard and DataAnalysis provides support to handle raw input data from all major MS instrument vendors. To ease parameter selection over the various feature finding and grou** algorithms, an automated feature optimization approach was adopted from the isotopologue parameter optimization (IPO) R package [62], which employs design of experiments to optimize LC–MS data processing parameters [63]. IPO was integrated in patRoon, and its code base was extended to (a) support additional feature finding and grou** algorithms from OpenMS, enviPick and usage of the new XCMS 3 interface, (b) support isotope detection with OpenMS, (c) perform optimization of qualitative parameters and (d) provide a consistent output format for easy inspection and visualization of optimization results. In patRoon, componentization refers to consolidating different (grouped) features with a prescribed relationship, which is currently either based on (a) highly similar elution profiles (i.e. retention time and peak shape), which are hypothesized to originate from the same chemical compound (based on [42, 49]), (b) participation in the same homologous series (based on [64]) or (c) the intensity profiles across samples (based on [4, 5, 65]). Components obtained by approach (a) typically comprise adducts, isotopologues and in-source fragments, and these are recognized and annotated with algorithms from CAMERA [49] or RAMClustR [42]. Approach (b) uses the nontarget R package [34] to calculate series from aggregated feature data from replicates. The interpretation of homologous series between replicates is assisted by merging series with overlap** features in cases where this will not yield ambiguities to other series. If merging would cause ambiguities, instead links are created that can then be explored interactively and visualized by a network graph generated using the igraph [66] and visNetwork [67] R packages (see Additional file 2: Figure S1). During the annotation step, molecular formulae and/or chemical compounds are automatically assigned and ranked for all features or feature groups. The required MS peak list input data are extracted from all MS analysis data files and subsequently pre-processed, for instance, by averaging multiple spectra within the elution profile of the feature and by removing mass peaks below user-defined thresholds. All compound databases and ranking mechanisms supported by the underlying algorithms are supported by patRoon and can be fully configured. Afterwards, formula and structural annotation data may be combined to improve candidate ranking and manual interpretation of annotated spectra. More details are outlined in the section “MS peak list retrieval, annotation and candidate ranking”. Various rule-based filters are available for data-cleanup or study specific prioritization of all data obtained through the workflow (see Table 2), and can be inverted to inspect the data that would be removed (i.e. negation). To process feature data, multiple filters are often applied, however, the order may influence the final result. For instance, when features were first removed from blanks by an intensity filter, a subsequent blank filter will not properly remove these features in actual samples. Similarly, a filter may need a re-run after another to ensure complete data clean-up. To reduce the influence of order upon results, filters for feature data are executed by default as follows: An intensity pre-filter, to ensure good quality feature data for subsequent filters; Filters not affected by other filters, such as retention time and m/z range; Minimum replicate abundance, blank presence and ‘regular’ minimum intensity; Repetition of the replicate abundance filter (only if previous filters affected results); Other filters that are possibly influenced by prior steps, such as minimum abundance in feature groups or sample analyses. Note that the above scheme only applies to those filters requested by the user, and the user can apply another order if desired. Further data subsetting allows the user to freely select data of interest, for instance, following a (statistical) prioritization approach performed by other tools. Similarly, features that are unique or overlap** in different sample analyses may be isolated, which is a straightforward but common prioritization technique for NTA studies that involve the comparison of different types of samples. Data from feature groups, components or annotations that are generated with different algorithms (or parameters thereof) can be compared to generate a consensus by only retaining data with (a) minimum overlap, (b) uniqueness or (c) by combining all results (only (c) is supported for data from components). Consensus data are useful to remove outliers, for inspection of algorithmic differences or for obtaining the maximum amount of data generated during the workflow. The consensus for formula and compound annotation data are generated by comparison of Hill-sorted formulae and the skeleton layer (first block) of the InChIKey chemical identifiers [72], respectively. For feature groups, where different algorithms may output deviating retention and/or mass properties, such a direct comparison is impossible. Instead, the dimensionality of feature groups is first reduced by averaging all feature data (i.e. retention times, m/z values and intensities) for each group. The collapsed groups have a similar data format as ‘regular’ features, where the compared objects represent the ‘sample analyses’. Subjection of this data to a feature grou** algorithm supported by patRoon (i.e. from XCMS or OpenMS) then allows straightforward and reliable comparison of feature data from different algorithms, which is finally used to generate the consensus. Hierarchical clustering is utilized for componentization of features with similar intensity profiles or to group chemically similar candidate structures of an annotated feature. The latter “compound clustering” assists the interpretation of features with large numbers of candidate structures (e.g. hundreds to thousands). This method utilizes chemical fingerprinting and chemical similarity methods from the rcdk package [73] to cluster similar structures, and subsequent visual inspection of the maximum common substructure then allows assessment of common structural properties among candidates (methodology based on [74]). Cluster assignment for both componentization and compound annotation approaches is performed automatically using the dynamicTreeCut R package [75]. However, clusters may be re-assigned manually by the desired amount or tree height. Several data conversion methods were implemented to allow interoperability with other software tools. All workflow data types are easily converted to commonly used R data types (e.g. data.frame or list), which allows further processing with other R packages. Furthermore, feature data may be converted to and from native XCMS objects (i.e. xcmsSet and XCMSnExp) or exported to comma-separated values (CSV) formats compatible with Bruker ProfileAnalysis or TASQ, or MZmine. Data for MS and MS/MS peak lists for a feature are collected from spectra recorded within the chromatographic peak and averaged to improve mass accuracies and signal to noise ratios. Next, peak lists for each feature group are assigned by averaging the mass and intensity values from peak lists of the features in the group. Mass spectral averaging can be customized via several data clean-up filters and a choice between different mass clustering approaches, which allow a trade-off between computational speed and clustering accuracy. By default, peak lists for MS/MS data are obtained from spectra that originate from precursor masses within a certain tolerance of the feature mass. This tolerance in mass search range is configurable to accommodate the precursor isolation window applied during data acquisition. In addition, the precursor mass filter can be completely disabled to accommodate data processing from data-independent MS/MS experiments, where all precursor ions are fragmented simultaneously. The formula annotation process is configurable to allow a tradeoff between accuracy and calculation speeds. Candidates are assigned to each feature group, either directly by using group averaged MS peak list data, or by a consensus from formula assignments to each individual feature in the group. While the latter inherently consumes more time, it allows removal of outlier candidates (e.g. false positives due to features with poor spectra). Candidate ranking is improved by inclusion of MS/MS data in formula calculation (optional for GenForm [35] and DataAnalysis). Formula calculation with GenForm ranks formula candidates on isotopic match (amongst others), where any other mass peaks will penalize scores. Since MS data of “real-world” samples typically includes many other mass peaks (e.g. adducts, co-eluting features, background ions), patRoon improves the scoring accuracy by automatic isolation of the feature isotopic clusters prior to GenForm execution. A generic isolation algorithm was developed, which makes no assumptions on elemental formula compositions and ion charges, by applying various rules to isolate mass peaks that are likely part of the feature isotopic cluster (see Additional file 2: Figure S2). These rules are configured to accommodate various data and study types by default. Optimization is possible, for instance, to (a) improve studies of natural or anthropogenic compounds by lowering or increasing mass defect tolerances, respectively, (b) constrain cluster size and intensity ranges for low molecular weight compounds or (c) adjust to expected instrumental performance such as mass accuracy. Note that precursor isolation can be performed independently of formula calculation, which may be useful for manual inspection of MS data. Compound annotation is usually the most time and resource intensive process during the non-target workflow. As such, instead of annotating individual features, compound assignment occurs for the complete feature group. All compound databases supported by the underlying algorithms, such as PubChem [24], ChemSpider [76] or CompTox [25] and other local CSV files, as well as the scoring terms present in these databases, such as in silico and spectral library MS/MS match, references in literature and presence in suspect lists, can be utilized with patRoon. Default scorings supported by the selected algorithm/database or sets thereof are easily selectable to simplify effective compound ranking. Furthermore, formula annotation data may be incorporated in compound ranking, where a ‘formula score’ is calculated for each candidate formula, which is proportional to its ranking in the formula annotation data. Execution of unattended sessions is assisted by automatic restarts after occurrence of timeouts or errors (e.g. due to network connectivity) and automatic logging facilities. In patRoon, visualization functionality is provided for feature and annotation data (e.g. extracted ion chromatograms (EICs) and annotated spectra), to compare workflow data (i.e. by means of Venn, chord and UpSet [77] diagrams, using the VennDiagram [78], circlize [79] and UpSetR [80] R packages, respectively) and others such as plotting results from automatic feature optimization experiments and hierarchical clustering data. Reports can be generated in a common CSV text format or in a graphical format via export to a portable document file (PDF) or hypertext markup language (HTML) format. The latter are generated with the R Markdown [5c). Since execution times of each step may vary significantly, the inclusion of different combinations of steps may significantly influence overall execution times. The use of multiprocessing for all tools (except SIRIUS), the implemented batch mode strategies for GenForm and the use of the native batch mode supported by SIRIUS were set as default in patRoon with the determined optimal parameters from the benchmarks results. However, the user can still freely configure all these options to potentially apply further optimizations or otherwise (partially) disable parallelization to conserve system resources acquired by patRoon. As a final note, it is important to realize that a comparison of these benchmarks with standalone execution of investigated tools is difficult, since reported execution times here are also influenced by (a) preparing input and processing output and (b) other overhead such as process creation from R. However, (b) is probably of small importance, as was revealed by the highly scalable results of msConvert where the need to perform (a) is effectively absent. Furthermore, the overhead from (a) is largely unavoidable, and it is expected that handling of input and output data is still commonly performed from a data analysis environment such as R. Nonetheless, the various optimization strategies employed by patRoon minimize such overhead, and it was shown that the parallelization functionality often provide a clear advantage in efficiency when using typical CLI tools in an R based NTA workflow, especially considering the now widespread availability of computing systems with increasing numbers of cores. The previous section investigated several parallelization strategies implemented in patRoon for efficient data processing. A common method in environmental NTA studies to increase data processing efficiency and reducing the data complexity is by merely screening for chemicals of interest. This section demonstrates such a suspect screening workflow with patRoon, consisting of (a) raw data pre-treatment, (b) extracting, grou** and suspect screening of feature data, and finally (c) annotating features to confirm their identity. During the workflow several rule-based filters are applied to improve data quality. The ‘suspects’ in this demonstration are, in fact, a set of compounds spiked to influent samples (Table 5), therefore, this brief NTA primarily serves for demonstration purposes. After completion of the suspect screening workflow, several methods are demonstrated to inspect the resulting data. The code described here can easily be generated with the newProject() function, which automatically generates a ready-to-use R script based on user input (section “Visualization, reporting and graphical interface”). First, the patRoon R package is loaded and a data.frame is generated with the file information of the sample analyses and their replicate and blank assignments. Next, this information is used to centroid and convert the raw analyses files to the open mzML file format, a necessary step for further processing. The next step involves finding features and grou** them across samples. This example uses the OpenMS algorithms and sets several algorithm specific parameters that were manually optimized for the employed analytical instrumentation to optimize the workflow output. Other algorithms (e.g. enviPick, XCMS) are easily selected by changing the algorithm function parameter. Several rule-based filters are then applied for general data clean-up, followed by the removal of sample blanks from the feature dataset. Next, features are screened with a given suspect list, which is a CSV file read into a data.frame containing the name, SMILES and (optionally) retention time for each suspect (see Additional file 5). While the list in this demonstration is rather small (18 compounds, see Table 5), larger lists containing several thousands of compounds such as those available on the NORMAN network Suspect List Exchange [118] can also be used. The screening results are returned in a data.frame, where each row is a hit (a suspect may occur multiple times) containing the linked feature group identifier and other information such as detected m/z and retention time (deviations). Finally, this table is used to transform the original feature groups object (fGroups) by removing any unassigned features and tagging remainders by their suspect name. In the final step of this workflow annotation is performed, which consists of (a) generation of MS peak list data, (b) general clean-up to only retain significant MS/MS mass peaks, automatic annotation of (c) formulae and (d) chemical compounds, and (e) combining both annotation data to improve ranking of candidate compounds. As with previous workflow steps, the desired algorithms (mzR, GenForm and MetFrag in this example) are set using the algorithm function parameter. Similarly, the compound database used by MetFrag (here CompTox via a local CSV file obtained from [119]) can easily be changed to other databases such as PubChem, ChemSpider or another local file. All data generated during the workflow (e.g. features, peak lists, annotations) can be inspected by overloads of common R methods. Furthermore, all workflow data can easily be subset with, e.g. the R subset operator (“[“), for instance, to perform a (hypothetical) prioritization of features that are most intense in the effluent samples. Visualization of data generated during the workflow, such as an overview of features, chromatograms, annotated MS spectra and uniqueness and overlap of features, can be performed by various plotting functions (see Fig. 6). Common visualization functionality of patRoon applied to the demonstrated workflow. From left to right: an m/z vs retention time plot of all feature groups uniquely present in the samples, an EIC for the tramadol suspect, a compound annotated spectrum for the benzotriazole suspect and comparison of feature presence between sample groups using UpSet [77], Venn (influent/effluent A) and chord diagrams The final step in a patRoon NTA workflow involves automatic generation of comprehensive reports of various formats which allow (interactive) exploration of all data (see Additional file 2: Figure S8).Workflow in patRoon

Data reduction, comparison and conversion
MS peak list retrieval, annotation and candidate ranking
Visualization, reporting and graphical interface
Demonstration: suspect screening
Suspect screening: workflow





Suspect screening: data inspection





Suspect screening: results
A summary of data generated during the NTA workflow demonstrated here is shown in Tables 5 and 6. The complete workflow finished in approximately 8 min (employing a laptop with an Intel® Core™ I7-8550U CPU, 16 gigabyte RAM, NVME SSD and the Windows 10 Pro operating system). While nearly 60,000 features were grouped into nearly 20,000 feature groups, the majority (97%, 678 remaining) were filtered out during the various pre-treatment filter steps. Regardless, most suspects were found (17/18 attributed to 19/20 individual chromatographic peaks, Table 5), and the missing suspect (aniline) could be detected when lowering the intensity threshold of the filter() function used to post-filter feature groups in the workflow. The majority of suspects (17) were annotated with the correct chemical compound as first candidate (Table 6), the two n-methylbenzotriazole isomer suspects were ranked as second or fourth. Results for formulae assignments were similar, with the exception of dimethomorph, where the formula was ranked in only the top 25 (the candidate chemical compound was ranked first, however).
While this demonstration conveys a relative simple NTA with ‘known suspects’, the results show that patRoon is (a) time-efficient on conventional computer hardware, (b) allows a straightforward approach to perform a complete and tailored NTA workflow, (c) provides powerful general data clean-up functionality to prioritize data and (d) performs effective automated annotation of detected features.
Demonstration: algorithm consensus
This section briefly demonstrates how the consensus functionality of patRoon can be used to compare and combine output from the supported algorithms from OpenMS, XCMS and enviPick. The MS data from the suspect screening demonstration above was also used here. The full processing script can be found as Additional file 6.
To obtain the feature data the findFeatures(), groupFeatures() and filter() functions were used as was demonstrated previously (see Additional file 6). The first step is to create a comparison from this data, which is then used to create a consensus (discussed in section “Data reduction, comparison and conversion”). The consensus can be formed from combining all data or from overlap** or unique data, which can then be inspected with the aforementioned data inspection functionality.

A summary of the results is shown in Table 7 and Additional file 2: Figure S9. While the number of features prior to grou** and filtering varied significantly between algorithms (~ 10 000 to ~ 60 000), they were roughly equal after pre-treatment: 678 (OpenMS), 801 (XCMS) and 836 (enviPick). Combining these resulted in 1243 grouped features, of which 541 (44%) were unique to one algorithm, 332 (27%) were shared amongst two algorithms and 370 (30%) fully overlapped. Application of the suspect screening workflow from the previous section revealed that the same 17 out of 18 suspects were present in all the algorithm specific, combined and overlap** feature datasets. Still, the results from this demonstration indicates that each algorithm generates unique results. Dedicated efforts such as ENTACT [120,121,
Conclusions
This paper presents patRoon, a fully open source platform that provides a comprehensive MS based NTA data processing workflow developed in the R environment. Major workflow functionality is implemented through the usage of existing and well-tested software tools, connecting primarily open and a few closed approaches. The workflows are easily setup for common use cases, while full customization and mixing of algorithms allows for execution of completely tailored workflows. In addition, extensive functionality related to data processing, annotation, visualization, reporting and others was implemented in patRoon to provide an important toolbox for effectively handling complex NTA studies. The easy and predictable interface of patRoon lowers the computational expertise required of users, making it available for a broad audience. It was shown that the optimization strategies implemented reduced the computational times. Furthermore, it was demonstrated how patRoon can be used to perform a straightforward and effective suspect screening workflow and how it can easily generate, compare and combine results from different NTA workflow algorithms.
patRoon has been under development for several years and has already been applied in a variety of studies, such as the characterization of organic matter [71], elucidation of transformation products of biocides [7, 12], assessment of removal of polar organics by reversed-osmosis drinking water treatment [14] and the investigation of endocrine disrupting chemicals in human breast milk [110]. patRoon will be maintained to stay compatible with its various dependencies and further development is planned. This includes extension of integrated workflow algorithms for new and less commonly used ones and the implementation of additional componentization strategies to help prioritizing data. Addition of new workflow functionality is foreseen, such as usage of ion-mobility spectrometry data to assist annotation, automated screening of transformation products (e.g. utilizing tools such as BioTransformer [123]), prediction of feature quantities for prioritization purposes (recently reviewed in [124]) and automated chemical classification (e.g. through ClassyFire [125]). Finally, interfacing with other R based mass spectrometry software such as those provided by the “R for Mass Spectrometry” initiative [126] is planned to further improve the interoperability of patRoon. The use in real-world studies, feedback from users and developments within the non-target analysis community, are all critical in determining future directions and improvements of patRoon. We envisage that the open availability, straightforward usage, vendor independence and comprehensive functionality will be useful to the community and result in a broad adoption of patRoon.
Availability and requirements
Project name: patRoon.
Project home page: https://github.com/rickhelmus/patRoon.
Operating system(s): Platform independent (tested on Microsoft Windows and Linux).
Programming language(s): R, C ++, JavaScript.
Other requirements: Depending on utilized algorithms (see installation instructions in [85, 88]).
License: GNU GPL version 3.
Any restrictions to use by non-academics: none.
Definitions
Features: data points assigned with unique chromatographic and mass spectral information (e.g. retention time, peak area and accurate m/z), which potentially described a compound in a sample analysis.
Feature group: A group of features considered equivalent across sample analyses.
MS peak list: tabular data (m/z and intensity) for MS or MS/MS peaks attributed to a feature and used as input data for annotation purposes.
Formula/Compound: a chemical formula or compound candidate revealed during feature annotation.
Component: A collection of feature groups that are somehow linked, such as MS adducts, homologous series or highly similar intensity trends.
