
Abstract
Despite the importance of preventing chronic kidney disease (CKD), predicting high-risk patients who require active intervention is challenging, especially in people with preserved kidney function. In this study, a predictive risk score for CKD (Reti-CKD score) was derived from a deep learning algorithm using retinal photographs. The performance of the Reti-CKD score was verified using two longitudinal cohorts of the UK Biobank and Korean Diabetic Cohort. Validation was done in people with preserved kidney function, excluding individuals with eGFR <90 mL/min/1.73 m2 or proteinuria at baseline. In the UK Biobank, 720/30,477 (2.4%) participants had CKD events during the 10.8-year follow-up period. In the Korean Diabetic Cohort, 206/5014 (4.1%) had CKD events during the 6.1-year follow-up period. When the validation cohorts were divided into quartiles of Reti-CKD score, the hazard ratios for CKD development were 3.68 (95% Confidence Interval [CI], 2.88–4.41) in the UK Biobank and 9.36 (5.26–16.67) in the Korean Diabetic Cohort in the highest quartile compared to the lowest. The Reti-CKD score, compared to eGFR based methods, showed a superior concordance index for predicting CKD incidence, with a delta of 0.020 (95% CI, 0.011–0.029) in the UK Biobank and 0.024 (95% CI, 0.002–0.046) in the Korean Diabetic Cohort. In people with preserved kidney function, the Reti-CKD score effectively stratifies future CKD risk with greater performance than conventional eGFR-based methods.
Similar content being viewed by others


Introduction
Chronic kidney disease (CKD) is a leading cause of cardiovascular disease and non-communicable disease mortality1,2,3. CKD prevalence is growing rapidly due to an aging global population and increased prevalence of hypertension and diabetes, two major causes of CKD4,28,29,30. In addition, even in cases of localized kidney diseases, early-stage nephron loss may induce changes in the systemic milieu which could lead to retinal vascular pathology. Investigations showing that macrophage activation is promoted, even in early kidney disease stages, which induces systemic cholesterol accumulation through cholesterol efflux alteration support this possibility31.
Fourth, to the best of our knowledge, there are two prior studies related to the current topic. Sabanayagam et al. developed a retina-based deep-learning algorithm from a cross-sectional study that could diagnose CKD, but the prediction of future CKD events was not evaluated17. Further, Zhang et al. also proposed a deep-learning algorithm to predict CKD32. However, the total number of CKD cases was low in their validations, with a maximum of 6 years of follow-up (80 cases in the internal and 66 cases in the external test set). Moreover, risk stratification, in that study, was less apparent. Notably, in our exploratory analysis, the predictive power of the Reti-CKD score was >99% for both the UK Biobank and Korean Diabetic Cohort, a significant improvement over previous investigations32.
Interestingly, in the subgroup analyses, the impact of Reti-CKD predicting CKD was relatively greater among patients without diabetes than diabetic patients. Several explanations for this finding would be possible. First, more patients would be presenting CKD related retinal photograph findings among diabetic patients due to diabetic retinopathy, while retinal changes would be a comparably less common feature in non-diabetic patients33. This disproportion of retinal abnormality among groups may have resulted in a greater CKD prediction power for Reti-CKD in people without diabetes. Abnormal retinal changes in a group in which most people present normal retinal features may indicate a higher likelihood of concomitant kidney disease than those without retinal pathology. Second, in diabetes patients, other risk factors than retinal abnormalities may serve as powerful surrogates for kidney function status, such as blood glucose level or diabetes duration34,35. The presence of these other factors could have resulted in a relatively lower predictive capability of the Reti-CKD score. Nonetheless, although the predictive impact of Reti-CKD may slightly differ regarding the presence of diabetes, it should be noted that, in both patient populations, the effectiveness of Reti-CKD as a predictive marker was significant.
The major strength of this study is the development of a deep-learning algorithm using separate datasets from a Korean health screening center and validation of a new CKD risk score using two different cohorts (internal validation in the UK Biobank and external validation in the Korean Diabetic Cohort) with a sufficient number of CKD incidence. However, this study had several limitations. First, the primary outcome in the UK Biobank was defined according to claim codes from inpatient and general practice claim records. Due to human error and subjectivity, chances of CKD development being misdiagnosed in the claims data should be considered. Nonetheless, differences in CKD incidence across the four Reti-CKD score groups were significant lowering this possibility. This is because misdiagnosed cases would have been randomly distributed across the four risk groups. Additionally, sensitivity analyses also supported the association between the Reti-CKD score and CKD incidence, further reducing the likelihood that bias played a major role. Second, external validation had only been performed on the Korean Diabetic Cohort. There remains a need for further validating Reti-CKD scores in various disease populations and across different ethnicities.
In conclusion, we derived and validated a non-invasive CKD risk stratification tool, Reti-CKD score. For people with preserved kidney function, Reti-CKD score was more effective in the prediction of CKD incidence than conventional blood test-based method. Since access to retinal photography is increasing at community and primary care levels, Reti-CKD score has the potential to be adopted as a practical screening tool for primary CKD prevention.
Methods
Ethics statement
This study was conducted in accordance with the Declaration of Helsinki and approved by the institutional review board of Severance Hospital, Yonsei University Health System (4-2021-1174). Owing to the retrospective nature and use of de-identified data, the requirement for informed consent was waived for the Korean datasets. Written informed consent was obtained from the UK Biobank participants. UK Biobank resources were used under the application number 68428.
Study population
In phase 1, a health screening center data were used for the development of deep-learning algorithm (Fig. 3). A development set including 158,216 retinal photographs was used to train the deep-learning algorithm. These retinal photographs were from 79,108 adults who had participated in health screening programs at a health screening center affiliated with Severance Hospital, South Korea.

In phase 1, health-screening center data was used for the development of deep-learning algorithm. In phase 2, data from longitudinal cohorts were utilized for derivation and validation of Reti-CKD score. Reti-CKD score was derived based on a Cox model using the UK Biobank cohort. The performance of Reti-CKD score was subsequently validated using the UK Biobank and Korean Diabetic Cohort.
In phase 2, data from longitudinal cohorts were used to derive and validate the Reti-CKD score. Reti-CKD score was derived using the UK Biobank cohort (n = 30,477). The performance of Reti-CKD score was subsequently validated using the UK Biobank and Korean Diabetic Cohort (n = 5014). The UK Biobank is a community-based prospective longitudinal study. The Korean Diabetic Cohort contains clinical data from a cohort of patients with type 2 diabetes who were treated at Severance Hospital or Gangnam Severance Hospital from April 2011 to August 2018.
Participants were eligible for this validation if clinical information for calculating eGFR and retinal photographs were available. Accordingly, participants with prevalent CKD, with eGFR <90 mL/min/1.73 m2, or with albuminuria (defined as urine albumin to creatinine ratio >30 mg/Cr in the UK Biobank and albumin ≥trace level on dip-stick urinalysis in the Korean Diabetic Cohort) were excluded. A detailed flowchart of the study population is shown in Supplementary Fig. 2.
Retinal photography
In phase 1, retinal photographs were taken using three different retinal cameras in the development set: the AFP-210 nonmydriatic auto retinal camera (NIDEK Corporation, Aichi, Japan), TRC-NW8 nonmydriatic retinal camera (Topcon Corporation, Tokyo, Japan), and Nonmyd A-D (Kowa Co. Ltd., Shizuoka, Japan). In the development set, retinal photographs of all participants were taken, and blood tests were performed on the same day.
In phase 2, retinal photographs were taken at baseline using TRC-NW8 (Topcon Corporation, Tokyo, Japan) and KOWA VX-20 (Kowa, Chofu Factory, Japan) in the Korean Diabetic Cohort and Topcon 3D OCT-1000 Mark II (Topcon Corporation, Tokyo, Japan) in the UK Biobank.
Development of deep-learning algorithm using retinal photographs: phase 1
In phase 1, contemplating that retinal microvascular signature associated with CKD could determine future risk of CKD, a deep-learning algorithm was trained (Fig. 3). The model inputs were retinal photographs. Ground truth was “absence versus presence” of CKD; CKD was defined as eGFR <60 mL/min/1.73 m2 or albuminuria and coded as a binary variable (no CKD versus CKD).
The utilized deep learning model was based on the ConvNeXT model. During the model training process, single images of each eye were separately inputted with a corresponding label. In the evaluation process, each image of the left and right eye had been assigned a probability score, and the average of these probability scores were considered as output of the examination, a process similar to ensemble learning with multiple models. This process showed improved performance than evaluating one image at a time each with a probability score. Our model design was almost identical to ConvNeXT, except for the dimension of the last fully connected layer, which was changed to one logit probability prediction. The logit that resulted from the last fully connected layer was converted to a probability with a sigmoid function, and we trained this model to minimize losses from the target and prediction. Further, we trained our model using the AdamW optimizer with a 0.0002 learning rate and cosine learning rate schedule for 50 epochs (Supplementary Fig. 3). For data augmentation, we used mixup, CutMix, RandAugment, contrast enhancement module, and random crop. Moreover, we not only adopted focal loss and exponential moving average but also used 384 × 384 size images. The cross-sectional performances of the deep learning algorithm’s prediction score in an internal validation set is provided in Supplementary Table 9. Once the deep-learning algorithm was trained, the probability of CKD presence could be calculated. This probability ranged from zero to one, with a high value indicating a high probability for having CKD. This “deep-learning-derived retina-CKD probability” was designed to calibrate the amount of association between the retinal microvascular signs and the presence of CKD. This deep-learning-derived retina-CKD probability alone without other clinical factors was tested to be capable of stratifying future CKD risk using two longitudinal cohorts of the UK Biobank and Korean Diabetic Cohort (Supplementary Table 10). Further, the deep-learning-derived retina-CKD probability was evaluated using Harrell’s c-statistic to show an incremental value over the eGFR model for CKD prediction (Supplementary Table 11).
Development and validation of Reti-CKD score: phase 2
In phase 2, the predictability of the deep-learning-derived retina-CKD probability was further enhanced by integrating clinical factors (Fig. 3). The Reti-CKD score was derived using the Cox proportional hazards model in the UK Biobank. After fitting the Cox proportional hazards model to the UK biobank cohort, we obtained the coefficients of the covariates. The baseline survival probability in the UK biobank at 5 years was 0.9980896. Reti-CKD score was modeled to be a failure probability at 5 years. The Cox model included age, sex, hypertension, diabetes, and deep-learning-derived retina-CKD probability. The clinical factors were chosen to derive a parsimonious model because they can be obtained from questionnaires without additional invasive measures, such as blood tests (Supplementary Table 12).
For Reti-CKD risk score validation, four-tier CKD risk groups were proposed based on Reti-CKD score quartiles (1st, 2nd, 3rd, and 4th quartile) in each cohort of the UK Biobank and Korean Diabetic Cohort. A conventional eGFR-based CKD risk score (i.e., eGFR-CKD score) was also derived using the Cox proportional hazards model in the UK Biobank for comparison (Supplementary Table 12). The performance of Reti-CKD and eGFR-CKD scores in prediction of CKD events were assessed in the UK Biobank and Korean Diabetic Cohort, respectively.
CKD incidence definition
In the UK Biobank, CKD incidence was defined according to the tenth revision of the International Statistical Classification of Diseases and Related Health Problems (ICD-10) codes and the Office of Population Censuses and Surveys Classification of Interventions and Procedures version 4 (OPCS-4) codes in primary care settings, hospital inpatient data, and death register records (Supplementary Table 13) The follow-up period began at the date of the first assessment and ended with death, CKD diagnosis, or the end of follow-up, whichever occurred first.
In the Korean Diabetic Cohort, CKD incidence was defined as two consecutive eGFR values of <60 mL/min/1.73 m2, the first of which was used as the index date. The follow-up period for each patient began when their retinal photographs were taken and ended on the date of CKD diagnosis or the last creatinine measurement.
Definition of covariates
The eGFR was calculated from serum creatinine using the Chronic Kidney Disease Epidemiology Collaboration equation (CKD-EPI)36. In the UK Biobank, diabetic history was determined by ICD-10 codes in any primary care setting and hospital inpatient data. Hypertension was defined as the use of antihypertensive medications in any primary care setting, hospital inpatient data, and self-reported medical history records. Similarly, in the Korean Diabetic Cohort, hypertension was established for patients on antihypertensive medication according to outpatient and inpatient prescription data.
Saliency maps
To explain how the deep learning model works, saliency maps were generated. We used guided backpropagation, which uses gradients of class probability for each image pixel, to demonstrate how pixels can affect the prediction results of the model37. Further, to obtain a more robust and clear visualization, we used the SmoothGrad technique, which averages gradients from images with random noise38.
Statistical analysis
Python 3.7 was used for development of the deep-learning algorithm, and Stata version 16.1 (Stata Corp, TX, USA) and R version 5.0.3 (R Foundation, Vienna, Austria) were used for survival analysis and model performance assessment. Statistical significance was set at P < 0.05. Descriptive statistics were provided for all datasets including health screening data, the UK Biobank, and the Korean Diabetic Cohort.
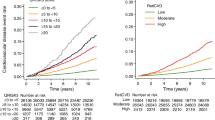
In the UK Biobank, each participant was followed up to 11.6 years from the date of the initial visit to the last follow-up date (February 28, 2021) or the date of CKD diagnosis. In the Korean Diabetic Cohort, each patient was followed up to 14.0 years from the date of the initial visit to the last follow-up date (February 28, 2022) or the date of CKD diagnosis. The cumulative incidence of CKD was evaluated across the quartiles defined by the Reti-CKD score using the Kaplan–Meier method and Cox proportional hazards model to estimate HRs. The eGFR-adjusted model included the baseline eGFR as a covariate.
The prognostic value of the Reti-CKD and eGFR-CKD scores in predicting CKD incidence was assessed using Harrell’s C-statistic and NRI39,40. Further, to obtain 95% CIs, we used a non-parametric bootstrap procedure with 1000 samples.
For sensitivity analyses, we additionally evaluated the performance of Reti-CKD in the entire population including prevalent CKD. Second, we repeated our survival analysis with participants with and without underlying diabetes or hypertension to evaluate predictability among different CKD etiologies. Third, analysis was done with participants identified as Caucasians in the UK Biobank. Fourth, landmark analysis was conducted using both cohorts after excluding subjects with a follow-up period of <1 year. Finally, analysis was done with eGFR converted form the CKD-EPI creatinine-cystatin equation41.
Data availability
The UK Biobank test dataset was obtained from the UK Biobank (application number 68428). The raw UK Biobank data-including the retinal photograph data reported here-are made available to researchers from universities and other research institutions with genuine research inquiries following IRB and UK Biobank approval. Data from South Korea are available to researchers who meet the criteria for access to confidential data. Data can be accessed upon request from the corresponding author, Jung Tak Park, Department of Internal Medicine, College of Medicine, Yonsei University, Seoul, South Korea (JTPARK@yuhs.ac).
Code availability
Code cannot be shared publicly because Reti-CKD is a commercial product. However, Reti-CKD are available to researchers who meet the criteria for access to confidential data; requests should be made to Mediwhale Inc. (info@mediwhale.com).
References
Kim, K. M., Oh, H. J., Choi, H. Y., Lee, H. & Ryu, D. R. Impact of chronic kidney disease on mortality: a nationwide cohort study. Kidney Res Clin. Pr. 38, 382–390 (2019).
Jankowski, J., Floege, J., Fliser, D., Böhm, M. & Marx, N. Cardiovascular disease in chronic kidney disease: pathophysiological insights and therapeutic options. Circulation 143, 1157–1172 (2021).
Thompson, S. et al. Cause of death in patients with reduced kidney function. J. Am. Soc. Nephrology JASN 26, 2504–2511 (2015).
GBD Chronic Kidney Disease Collaboration. Global, regional, and national burden of chronic kidney disease, 1990-2017: a systematic analysis for the Global Burden of Disease Study 2017. Lancet 395, 709–733 (2020).
**e, Y. et al. Analysis of the Global Burden of Disease study highlights the global, regional, and national trends of chronic kidney disease epidemiology from 1990 to 2016. Kidney Int. 94, 567–581 (2018).
Kidney Disease: Improving global outcomes (KDIGO) CKD work group. Chapter 2: Definition, identification, and prediction of CKD progression. Kidney Int. Suppl. 3, 63–72 (2013).
Waikar, S. S., Betensky, R. A. & Bonventre, J. V. Creatinine as the gold standard for kidney injury biomarker studies? Nephrol. Dialysis Transplant. 24, 3263–3265 (2009).
Lopez-Giacoman, S. & Madero, M. Biomarkers in chronic kidney disease, from kidney function to kidney damage. World J. Nephrol. 4, 57–73 (2015).
Soares, A. A. et al. Glomerular filtration rate measurement and prediction equations. Clin. Chem. Lab Med. 47, 1023–1032 (2009).
Naresh, C. N., Hayen, A., Craig, J. C. & Chadban, S. J. Day-to-day variability in spot urine protein-creatinine ratio measurements. Am. J. Kidney Dis. 60, 561–566 (2012).
Manski-Nankervis, J. E. et al. Screening and diagnosis of chronic kidney disease in people with type 2 diabetes attending Australian general practice. Aust. J. Prim. Health 24, 280–286 (2018).
Wong, C. W., Wong, T. Y., Cheng, C. Y. & Sabanayagam, C. Kidney and eye diseases: common risk factors, etiological mechanisms, and pathways. Kidney Int. 85, 1290–1302 (2014).
Sabanayagam, C. et al. Retinal microvascular caliber and chronic kidney disease in an Asian population. Am. J. Epidemiol. 169, 625–632 (2009).
Grunwald, J. E. et al. Association between progression of retinopathy and concurrent progression of kidney disease: findings from the chronic renal insufficiency cohort (CRIC) study. JAMA Ophthalmol. 137, 767–774 (2019).
Rim, T. H. et al. Prediction of systemic biomarkers from retinal photographs: development and validation of deep-learning algorithms. Lancet Digit Health 2, e526–e536 (2020).
Poplin, R. et al. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat. Biomed. Eng. 2, 158–164 (2018).
Sabanayagam, C. et al. A deep learning algorithm to detect chronic kidney disease from retinal photographs in community-based populations. Lancet Digit Health 2, e295–e302 (2020).
Eijkelkamp, W. B. et al. Albuminuria is a target for renoprotective therapy independent from blood pressure in patients with type 2 diabetic nephropathy: post hoc analysis from the Reduction of Endpoints in NIDDM with the Angiotensin II Antagonist Losartan (RENAAL) trial. J. Am. Soc. Nephrology 18, 1540–1546 (2007).
Ruospo, M. et al. Glucose targets for preventing diabetic kidney disease and its progression. Cochrane Database Syst. Rev. 6, Cd010137 (2017).
Shlipak, M. G. et al. The case for early identification and intervention of chronic kidney disease: conclusions from a Kidney Disease: Improving Global Outcomes (KDIGO) Controversies Conference. Kidney Int. 99, 34–47 (2021).
Coca, S. G., Ismail-Beigi, F., Haq, N., Krumholz, H. M. & Parikh, C. R. Role of intensive glucose control in development of renal end points in type 2 diabetes mellitus: systematic review and meta-analysis. Arch. Intern. Med. 172, 761–769 (2012).
Neal, B. et al. Canagliflozin and cardiovascular and renal events in type 2 diabetes. N. Engl. J. Med. 377, 644–657 (2017).
Cheung, K. L. et al. Risk factors for incident CKD in Black and White Americans: the REGARDS study. Am. J. Kidney Dis. S0272-6386, 00005-7 (2023).
Saran, R. et al. US renal data system 2018 annual data report: epidemiology of kidney disease in the United States. Am. J. Kidney Dis. 73, A7–a8 (2019).
Draznin, B. et al. 4. Comprehensive medical evaluation and assessment of comorbidities: standards of medical care in diabetes-2022. Diabetes Care 45, S46–s59 (2022).
Das, T. et al. Recently updated global diabetic retinopathy screening guidelines: commonalities, differences, and future possibilities. Eye 35, 2685–2698 (2021).
Unger, T. et al. 2020 International Society of Hypertension Global Hypertension Practice Guidelines. Hypertension 75, 1334–1357 (2020).
Kim, H. W. et al. Systolic blood pressure and chronic kidney disease progression in patients with primary glomerular disease. J. Nephrol. 34, 1057–1067 (2021).
Lee, J. Y. et al. Association of blood pressure with the progression of CKD: findings from KNOW-CKD study. Am. J. Kidney Dis. 78, 236–245 (2021).
Kidney Disease: Improving Global Outcomes (KDIGO) Glomerular Diseases Work Group. KDIGO 2021 clinical practice guideline for the management of glomerular diseases. Kidney Int. 100, S1–s276 (2021).
Kon, V., Linton, M. F. & Fazio, S. Atherosclerosis in chronic kidney disease: the role of macrophages. Nat. Rev. Nephrol. 7, 45–54 (2011).
Zhang, K. et al. Deep-learning models for the detection and incidence prediction of chronic kidney disease and type 2 diabetes from retinal fundus images. Nat. Biomed. Eng. 5, 533–545 (2021).
Adler, A. I. et al. Development and progression of nephropathy in type 2 diabetes: the United Kingdom Prospective Diabetes Study (UKPDS 64). Kidney Int 63, 225–232 (2003).
Gall, M. A., Hougaard, P., Borch-Johnsen, K. & Parving, H. H. Risk factors for development of incipient and overt diabetic nephropathy in patients with non-insulin dependent diabetes mellitus: prospective, observational study. BMJ 314, 783–788 (1997).
Altemtam, N., Russell, J. & El Nahas, M. A study of the natural history of diabetic kidney disease (DKD). Nephrol. Dial Transplant. 27, 1847–1854 (2012).
Levey, A. S. et al. A new equation to estimate glomerular filtration rate. Ann. Intern. Med. 150, 604–612 (2009).
Springenberg, J. T., Dosovitskiy, A., Brox, T. & Riedmiller, M. Striving for simplicity: the all convolutional net. Preprint at https://arxiv.org/abs/1412.6806 (2014).
Smilkov, D., Thorat, N., Kim, B., Viégas, F. & Wattenberg, M. Smoothgrad: removing noise by adding noise. Preprint at https://arxiv.org/abs/1706.03825 (2017).
Pencina, M. J., D’Agostino, R. B. Sr. & Steyerberg, E. W. Extensions of net reclassification improvement calculations to measure usefulness of new biomarkers. Stat. Med. 30, 11–21 (2011).
Pencina, M. J., D’Agostino, R. B. Sr., D’Agostino, R. B. Jr. & Vasan, R. S. Evaluating the added predictive ability of a new marker: from area under the ROC curve to reclassification and beyond. Stat. Med. 27, 157–172 (2008).
Inker, L. A. et al. Estimating glomerular filtration rate from serum creatinine and cystatin C. N. Engl. J. Med. 367, 20–29 (2012).
Acknowledgements
This study was supported by a grant from the Korean Nephrology Research Foundation (FMC, 2020) and the Medical data-driven hospital support project through the Korea Health Information Service (KHIS) grant, funded by the Ministry of Health & Welfare, Republic of Korea.
Author information
Authors and Affiliations
Contributions
All authors reviewed the literature, contributed to data interpretation, and read and approved the final manuscript. T.H.R. and J.T.P. conceptualized and designed the study. Y.S.J., H.B.K., Y.A.K., and J.T.P. collected data. H.K. and G.Y.L. developed the algorithm, and Y.S.J. and H.B.K. analyzed the data. All the authors drafted the manuscript. S.S.K., S.W.K. and J.T.P. revised the manuscript critically. S.S.K. confirmed that they had access to the datasets from South Korea. G.Y.L. confirmed that they had access to the datasets of the UK Biobank Study. Accordingly, S.S.K. and J.Y. accessed and verified each dataset during this study. Y.S.J. and T.H.R. are co-first authors.
Corresponding authors
Ethics declarations
Competing interests
T.H.R. was a former scientific adviser and owned stocks in Mediwhale. H.K. and G.L. are employees of Mediwhale, and G.L. owns stocks in Mediwhale. T.H.R. and G.L. hold the following patents that might have been affected by this study: 10–2018–0166720(KR), 10–2018–0166721(KR), 10–2018–0166722(KR), 62/694,901(US), 62/715,729(US), and 62/776,345 (US). All other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Joo, Y.S., Rim, T.H., Koh, H.B. et al. Non-invasive chronic kidney disease risk stratification tool derived from retina-based deep learning and clinical factors. npj Digit. Med. 6, 114 (2023). https://doi.org/10.1038/s41746-023-00860-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41746-023-00860-5
- Springer Nature Limited