
Abstract
Gastrointestinal stromal tumors (GISTs) are a rare type of tumor that can develop liver metastasis (LIM), significantly impacting the patient's prognosis. This study aimed to predict LIM in GIST patients by constructing machine learning (ML) algorithms to assist clinicians in the decision-making process for treatment. Retrospective analysis was performed using the Surveillance, Epidemiology, and End Results (SEER) database, and cases from 2010 to 2015 were assigned to the develo** sets, while cases from 2016 to 2017 were assigned to the testing set. Missing values were addressed using the multiple imputation technique. Four algorithms were utilized to construct the models, comprising traditional logistic regression (LR) and automated machine learning (AutoML) analysis such as gradient boost machine (GBM), deep neural net (DL), and generalized linear model (GLM). We evaluated the models' performance using LR-based metrics, including the area under the receiver operating characteristic curve (AUC), calibration curve, and decision curve analysis (DCA), as well as AutoML-based metrics, such as feature importance, SHapley Additive exPlanation (SHAP) Plots, and Local Interpretable Model Agnostic Explanation (LIME). A total of 6207 patients were included in this study, with 2683, 1780, and 1744 patients allocated to the training, validation, and test sets, respectively. Among the different models evaluated, the GBM model demonstrated the highest performance in the training, validation, and test cohorts, with respective AUC values of 0.805, 0.780, and 0.795. Furthermore, the GBM model outperformed other AutoML models in terms of accuracy, achieving 0.747, 0.700, and 0.706 in the training, validation, and test cohorts, respectively. Additionally, the study revealed that tumor size and tumor location were the most significant predictors influencing the AutoML model's ability to accurately predict LIM. The AutoML model utilizing the GBM algorithm for GIST patients can effectively predict the risk of LIM and provide clinicians with a reference for develo** individualized treatment plans.
Similar content being viewed by others


Introduction
Within the gastrointestinal tract, gastrointestinal stromal tumors (GISTs) are the most commonly encountered type of mesenchymal tumor1. As GISTs have the potential to be malignant2, previous study has indicated that more than half of patients with these tumors experience metastasis by the time they seek medical attention, with the liver being the most frequently affected location3,4,5. While the emergence of tyrosine kinase inhibitors (TKIs) such as imatinib has improved survival outcomes in patients with metastatic GIST6,7, secondary mutations and drug resistance may occur during adjuvant TKIs treatment, resulting in poor long-term outcomes for patients8.
Meanwhile, in the initial stages, numerous GIST patients present with no overt symptoms, and the liver metastases (LIM) can often be indistinguishable from other hepatic conditions on radiographic imaging, compounding the complexity of clinical diagnosis. The standard methods for screening LIM in patients with GISTs are magnetic resonance imaging (MRI) and positron emission tomography/computed tomography (PET/CT)9. Nonetheless, due to the high expense associated with MRI and the potential radiation harm from PET-CT, it is not advisable to use these techniques for LIM screening in all GIST patients.
Therefore, constructing a predictive model to accurately forecast the occurrence of LIM in patients with GIST is essential for guiding treatment decisions and improving patient prognosis. Wu et al.10 developed a nomogram to forecast the likelihood of distant metastases in patients with GISTs. Meanwhile, Zhou et al.11 employed a nomogram to predict the risk of LIM in GISTs patients. However, these traditional nomogram models are limited to linear regression approaches, constraining their capacity to handle complex and non-linear relationships. Furthermore, they do not consistently select the most predictive features during the feature selection process.
Automated machine learning (AutoML) is an advanced branch of machine learning (ML) known for enhancing prediction accuracy while saving time and effort12,13. While traditional ML demands deep expertise and ongoing fine-tuning, AutoML simplifies this by automating tasks like feature engineering and hyperparameter tuning. This speeds up modeling and broadens ML's accessibility. Leveraging AutoML models, clinicians can enhance the accuracy of their predictions regarding LIM development in GIST patients. However, no study have applied AutoML to predict LIM in GIST patients to date. To fill this gap, this study developed AutoML models using the Surveillance, Epidemiology, and End Results (SEER) database to predict LIM in GIST patients.
Materials and methods
Study population
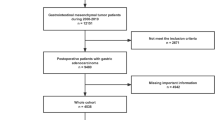
A retrospective analysis was performed on the SEER database (http://seer.cancer.gov), which is estimated to cover around 28% of the US population and contains comprehensive information on various clinical and pathological aspects of multiple cancers. The identification of GISTs was based on their ICD-O-3 code (8936). Given that the SEER database began providing information on the specific sites of metastatic GIST starting in 201014, we used the SEER*Stat software to select patient data from 2010 to 2017 and then sequentially divided this data into three sets. The training and validation sets were constructed using data from 2010 to 2015, while the test set was constructed using data from 2016 to 2017. We excluded the following patients: (1) The diagnosis was not verified by histopathology; (2) The status of liver metastasis was unknown. A flow chart depicting the study protocol is presented in Fig. 1. The presence of LIM in newly diagnosed GIST patients was determined using "SEER Combined Mets at DX-liver (2010Age was divided into two groups: ≤ 65 years (young group) and > 65 years (elderly group)15. The N stages were determined in accordance with the 7th edition of the American Joint Committee on Cancer (AJCC) Cancer Staging Manual16. Race was categorized into 3 groups: white, black, and others (including American Indian, Alaska Native and Asian/Pacifc Islander). The tumor location was categorized into 4 groups: stomach, small intestine, colon, and others (tumor locations with fewer than 20 reported cases primarily involve extragastrointestinal stromal tumors). Marital status was divided into two categories: married and unmarried (which includes divorced, separated, single, and widowed). The variable "CS site-specific factor 6" was utilized for the identification of the mitotic rate. The Institutional Review Board did not require approval for the study because SEER includes patient information that cannot be used to identify individuals.

Flow chart of the study. GISTs gastrointestinal stromal tumors, SEER Surveillance, Epidemiology, and End Results, GBM gradient boost machine, DL deep neural net, GLM generalized linear model, LASSO least absolute shrinkage and selection operator.
Multiple imputation
Owing to the presence of missing data in several variables such as race (1.0% of cases), tumor size (7.8% of cases), N stage (6.4% of cases), marital status (5.4% of cases), and mitotic rate (29.9% of cases), we employed a polytomous regression model using the multiple imputation (MI) feature in R software (version 4.1.0). This method was adopted to bolster the study's analytical robustness.
Logistic regression analysis
To address the problem of multiple collinear relationships among the explanatory variables, we conducted a univariate analysis using the least absolute shrinkage and selection operator (LASSO) regression model with the "λ" criterion. Subsequently, a binary logistic backward stepwise regression analysis was employed to further refine the model. The performance of the resulting model was assessed by calculating the area under the receiver operating characteristic curve (AUC), calibration curve, and decision curve analysis (DCA). DCA is a tool designed to evaluate the clinical benefits of predictive models. It primarily determines whether the application of a model at various probability thresholds offers advantages over blanket treatment strategies or opting for no treatment at all. The DCA curve illustrates the net benefit of the predictive model at different probability thresholds, aiding clinicians in better balancing risks and rewards during the decision-making process17. In addition, a nomogram, serving as a visual tool to translate the logistic regression model into an intuitive representation, was developed based on the independent risk factors identified in the multivariate analysis.
Automated machine learning
AutoML analysis was performed using the H2O package (version 3.42.0.3, 2023 release), which was installed from the H2O.ai platform (www.h2o.ai). H2O.ai stands as a premier platform dedicated to machine learning and artificial intelligence, crafted by the reputed company, H2O.ai. Renowned for its outstanding computational speed, adaptability, and intuitive design, it's a favored choice in the open-source community. A notable feature of the AutoML process in H2O is that it automatically selects appropriate algorithms and combines them into several ensemble models. The set of algorithms consisted of a randomized grid of Gradient Boosting Machines (GBMs), a randomized grid of Deep Neural Networks (DLs), and a fixed grid of Generalized Linear Models (GLMs). GBM, an ensemble method building successive decision trees to correct prior errors, excels in capturing complex patterns and offers high accuracy, making it apt for tasks like disease prognosis and risk stratification18. Meanwhile, GLM, which extends linear regression to accommodate non-normal response variables, stands out due to its interpretability, crucial for understanding clinical predictor-response relationships, and is widely employed in epidemiology to gauge predictors' effect on outcomes19. On the other hand, DL, utilizing multi-layered neural networks, shines in processing large datasets, particularly medical images and unstructured data, revolutionizing tasks such as disease diagnosis from X-rays and MRIs20. Hyperparameter optimization was carried out via a fivefold cross-validation grid search on the training set, evaluating various combinations of hyperparameters included in the grid search based on their AUCs. AutoML visualization was achieved through feature importance, SHAP, and LIME techniques. Using SHAP analysis, we were able to identify the critical features that significantly influenced the model predictions and their contribution to the overall model performance for a specific prediction21. LIME analysis showcased the contribution of each feature in predicting the outcome by randomly sampling instances from the validation set and the test set22. SHAP and LIME are both techniques used for model interpretability, but they differ in foundational approach and scope. SHAP, rooted in game theory, calculates feature contributions for predictions based on the Shapley value, ensuring a fair distribution among features and providing both global and local interpretability. On the other hand, LIME focuses on local explanations by perturbing the data and fitting an interpretable model to approximate black-box predictions.
Statistical analysis
In our study, we used the confusion matrix, which includes True Positives (TP), False Positives (FP), False Negatives (FN), and True Negatives (TN), to assess the performance of our classification model. True Positives (TP) represent the cases correctly identified as positive, while False Positives (FP) are the cases incorrectly identified as positive. False Negatives (FN) are cases incorrectly identified as negative, and True Negatives (TN) are the cases correctly identified as negative. To accurately assess the performance of our model, we computed several vital metrics. Sensitivity (or Recall) quantifies how effectively the model identifies actual positives, with its formula being TP/(TP + FN). Specificity evaluates the model's ability to correctly recognize actual negatives, calculated as TN/(TN + FP). The Positive Predictive Value (PPV) measures the accuracy of positive predictions, computed as TP/(TP + FP). Conversely, the Negative Predictive Value (NPV) gauges the accuracy of negative predictions, determined as TN/(TN + FN). Accuracy (ACC) reflects the model's overall correctness in classification, calculated using the formula TP + TN/(TP + TN + FP + FN). Lastly, the F1-Score, serving as the harmonic mean of PPV (Precision) and Sensitivity, offers a balanced measure of these two aspects, computed as 2 × PPV × Sensitivity/(PPV + Sensitivity). Categorical variables were presented as frequencies and percentages, and statistical comparisons between groups were performed using either the Chi-square test or Fisher exact test, depending on the sample size and distribution of data. The statistical significance level was set at P < 0.05 to determine the presence of significant differences between groups. All statistical analyses were conducted using the R software (version 4.1.0) to ensure accuracy and reproducibility of the results.
Results
Baseline characteristics of patients
A total of 6207 patients were included in this study. LIM was present in 662 cases, representing 10.7% of the entire cohort. The develo** dataset consisted of cases from 2010 to 2015, which were divided into training and validation cohorts in a 6:4 ratio (n = 2683 in the training group and n = 1780 in the validation group). The testing cohort comprised 1744 cases that met the inclusion criteria of being from the years 2016 to 2017. Among the 4463 patients in the develo** group, LIM was present in 476 cases (10.7%), while in the testing group, there were 186 cases (10.7%) of LIM out of a total of 1744 cases. Detailed baseline characteristics of patients are listed at Table 1, whereas Supplementary Table 1 offers a detailed breakdown of the demographic and clinical features of the two cohorts before MI. According to Table 2, the correlation analysis showed that in both the develo** and testing groups, four clinical characteristics (sex, N stage, tumor size, and mitotic rate) were significantly correlated (P < 0.05) with LIM.
Univariate and multivariate logistic regression analysis
The "λ" criterion obtained through fivefold cross-validation was utilized to apply the LASSO regression model, resulting in the selection of two out of eight variables as independent risk factors. Supplementary Fig. 1 illustrates that this method was utilized to resolve the issue of multiple collinear relationships among the explanatory variables. The final logistic model, which included two variables (tumor location and tumor size), was presented in the form of a nomogram and a score system, making it appropriate for clinical use (Fig. 2). Supplementary Fig. 2 illustrates the calibration curves for the training, validation, and test sets, which had mean absolute errors of 0.012, 0.008, and 0.003, respectively. These calibration curves indicate that the estimated risk produced by the LASSO model closely approximated the actual risk, suggesting a high level of reliability. According to the DCA plots for the LASSO model in the training set, validation set and test set, Supplementary Fig. 3 shows that if the threshold probability for predicting LIM by the LASSO model falls between 10 and 40%, an intervention may result in a benefit of 7%.

Nomogram of the LASSO model for predicting liver metastasis in patients with gastrointestinal stromal tumor. HPF high power field.
Automated machine learning analysis
A total of 41 models were built using four ML algorithms, namely GBM, DL, and GLM, with stacked ensemble models being excluded due to their limited interpretability. Delving deeper, the GBM yielded 19 models by tuning diverse hyperparameters. The DL method generated 19 models, capitalizing on a range of architectural setups, activation functions, and regularization techniques. Meanwhile, the GLM contributed 3 models, adjusting for variations in family distributions, link functions, and regularization intensities. Among the models built using the four ML algorithms, the GBM model (GBM_grid_1_AutoML_5_20231007_200850_model_6) demonstrated superior performance, achieving the highest AUC values and accuracy. Therefore, it was considered the most optimal model. According to Fig. 3, the most important feature was found to be tumor location, followed by tumor size, N stage, mitotic rate, sex, age, marital status, and race, in that order of decreasing importance. Additionally, the GBM and logistic regression models both identified tumor location and tumor size as important variables in predicting the outcome. The SHAP contribution plots generated by GBM algorithms are presented in Fig. 4, highlighting the eight variables with the greatest impact on the outcome. These variables are tumor size, tumor location, sex, mitotic rate, N stage, marital status, race, and age. When a variable's value approaches 1, the probability of a patient having LIM increases. This is exemplified by the SHAP plot in which the red dots representing tumor size larger than 5.0 cm are primarily situated on the right-hand side of the zero axis, indicating that patients with a large tumor size have a higher likelihood of experiencing LIM.

Variable importance of the GBM model in the training cohort, showing that tumor location was the most important feature, followed by tumor size, N stage, mitotic rate, etc.

SHAP of the GBM model in the training cohort. As a variable's value approaches 1, the likelihood of a patient develo** liver metastasis increases. SHAP SHapley Additive explanation, GBM gradient boost machine.
Table 3 indicates that the GBM algorithm demonstrated superior performance compared to the DL, GLM, and LASSO algorithms in the training, validation, and test cohorts in terms of AUC. The GBM algorithm achieved AUC values of 0.805, 0.780, and 0.795, respectively, which were higher than those of the DL algorithm (0.759, 0.729, and 0.746, respectively), the GLM algorithm (0.749, 0.719, and 0.737, respectively), and the LASSO algorithm (0.670, 0.610, and 0.567, respectively). Moreover, the GBM algorithm exhibited the highest accuracy values compared to the DL, GLM, and LASSO algorithms, as shown in Table 3. Figure 5, which features a LIME plot based on the GBM model, highlights the impact of significant variables on LIM of gGISTs. For instance, the GBM model predicted that case 1 in the validation set had a probability of 0.91 for LIM. N stage was deemed the most significant predictor of LIM, followed by mitotic rate, tumor location, maritial status, and race, while the impact of sex and tumor size on these factors was found to be opposite. According to Supplementary Fig. 4, the DCA plots of the AutoML models demonstrated a net benefit of approximately 5%.

LIME of the GBM model in the validation cohort. LIME Local Interpretable Model Agnostic Explanation.
Discussion
Using the SEER database, a nomogram for predicting GIST liver metastasis was established by Zhou et al.11. In reviewing their study, we identified certain variables with "unknown" values, potentially compromising predictive accuracy. To bolster the integrity of our data, mitigate bias, and preserve the original data's variability, we integrated MI techniques to address these missing entries. Simultaneously, leveraging the SEER database, we probed the efficacy of four ML algorithms in predicting the LIM for patients with GISTs. The results demonstrate that the GBM model performs better than other models, with an AUC of 0.780 and 0.795 in the validation and test sets, respectively. In comparison to the nomogram, the AutoML models we constructed demonstrates a higher AUC. Additionally, the GBM model has the highest accuracy among the AutoML models, achieving 0.700 and 0.706 in the validation and test sets, respectively. To sum up, the AutoML model utilizing the GBM algorithm has proven to be a valuable tool in predicting the risk of LIM in GIST patients, ultimately aiding clinicians in creating customized treatment plans.
In the realm of AutoML, ensuring model interpretability is not just important—it's paramount. While many of these models might operate as 'black boxes', tools like SHAP and LIME stand out as keystones to illuminate their predictive processes. Drawing from game theory, SHAP offers a comprehensive perspective on feature significance, whereas LIME delves deeper, providing granular insights into individual predictions by employing interpretable models on strategically altered data21,22. In concert, they enhance confidence in AutoML, a crucial element for making well-informed clinical decisions. Guided by this understanding, our research is poised to leverage the strengths of SHAP and LIME to provide a meticulous analysis of model interpretability. The SHAP plot, derived from a holistic data analysis, underscores that cases characterized by extensive tumor sizes, the occurrence of lymph node metastasis, and tumors located external to the gastrointestinal tract are more predisposed to liver metastasis, as shown in Fig. 4. Conversely, the LIME plot presents the liver metastasis likelihood for a singular, randomly sampled case, as delineated in Fig. 5.
In our investigation, both the nomogram and the GBM model's SHAP plot, as well as its feature importance chart, highlighted tumor location as a significant predictor for LIM in GIST patients. We noted an amplified risk of LIM when tumors were categorized as "others," primarily associated with extragastrointestinal stromal tumors (EGISTs). Traditionally, gastric gastrointestinal stromal tumors (G-GISTs) are considered to have a milder biological behavior than small gastrointestinal stromal tumors (S-GISTs), possessing less invasive and metastatic tendencies23. Research spearheaded by Miettinen et al.24 reported an elevated metastatic risk and tumor-related mortality for S-GISTs, especially when tumors exceed 5 cm in size. Concurrently, Kukar et al.25 found a tendency for distal metastasis among younger S-GISTs patients. Yet, our data suggests a similar LIM rate between G-GISTs and S-GISTs in both develo** and test cohorts. Intriguingly, when tumors were identified as "others" in the develo** cohort, there was a pronounced increase in LIM at 29.6% (102/345). This observation implies a higher propensity for LIM when GISTs are located outside the gastrointestinal domain. The predisposition of EGISTs for LIM could be ascribed to several reasons: (1) EGISTs might manifest more aggressive traits at molecular and genetic levels; (2) Their anatomical positioning could facilitate dissemination via the bloodstream, accentuating liver metastasis risks; (3) The relative obscurity and potential vagueness in symptoms of EGISTs could culminate in delayed diagnosis, thus presenting more advanced stages at detection.
According to the AutoML algorithms conducted in our study, tumor size and mitotic rate were identified as significant factors influencing LIM. Miettinen et al.'s study suggests that tumor size, rather than the mitotic rate, is a risk factor for GIST metastasis26. However, both Zhou et al.11 and Gaitanidis et al.27 found that both tumor size and mitotic rate are significantly associated with a higher risk of LIM, which is consistent with the results of our study. A larger tumor size indicates higher proliferative activity, facilitating the escape of tumor cells and their entry into the bloodstream or lymphatic system, ultimately leading to LIM. Similarly, a higher mitotic rate suggests increased abnormal proliferation, associated with greater malignancy and invasiveness. Faster cell division increases the likelihood of tissue invasion and migration. When the mitotic rate exceeds 5/50HPF, the chances of tumor cells entering the bloodstream or lymphatic system rise, promoting liver metastasis. Nonetheless, further research is required to fully comprehend the underlying mechanisms and related factors.
Our study also elucidated that the N stage serves as a significant risk factor for LIM. In contrast to other solid tumors, lymph node metastasis is exceedingly rare in patients with GISTs, and lymph node dissection is typically not necessary during surgery28. However, our findings revealed a heightened likelihood of LIM in cases with lymph node metastasis. Meanwhile, previous studies have consistently associated lymph node metastasis with poorer overall survival rates29,30. The propensity of GIST with lymph node metastasis to develop liver metastasis may be attributed to several factors. Firstly, the lymphatic system plays a crucial role in the dissemination of cancer cells. When cancer cells infiltrate and metastasize to regional lymph nodes, there is an increased likelihood of these cells gaining access to the bloodstream or lymphatic vessels, which can then transport them to distant sites, including the liver. Secondly, the presence of lymph node metastasis indicates a more advanced stage of the disease and a higher tumor burden. This suggests that the cancer cells have already exhibited an increased capacity for invasion and dissemination, making them more prone to establishing metastatic colonies in organs such as the liver.
Our study had some limitations. Firstly, this is a retrospective study based on the SEER database, where missing data and biases are inevitable. Nevertheless, we utilized MI methods to tackle the problem of missing data and reduce its influence on the analysis. Secondly, this study utilized the SEER database for analysis, which represents a specific population in the United States. While the study included validation and testing cohorts to evaluate the model, further validation through external cohorts may be necessary when generalizing the findings to other populations or regions. Thirdly, The proportion of patients manifesting LIM is notably low, suggesting potential data imbalance that might compromise the predictive model's accuracy. Moving forward, we plan to balance the dataset by possibly combining oversampling of the underrepresented class (patients with LIM) with undersampling of the dominant class. Additionally, we're contemplating the adoption of methods like the Synthetic Minority Over-sampling Technique (SMOTE) to produce synthetic samples for the minority class, an approach that has demonstrated efficacy in previous research. Despite these limitations, this is the first study to apply AutoML for predicting LIM in GIST, and it demonstrates superior predictive capability compared to previous research. Fourthly, in this study, approximately one-third of the mitotic index values were missing. Despite the application of MI techniques, there remains a potential risk of bias in the predictive models. Moving forward, we plan to implement advanced statistical techniques, including weighted analyses and model adjustments, to further mitigate potential biases arising from the missing data.
In conclusion, this study utilized AutoML algorithms to predict the risk of LIM in patients with GIST. The results showed that the GBM model outperformed other AutoML models in terms of performance and accuracy. Tumor size and tumor location were identified as the most significant predictors for accurately predicting LIM using the AutoML model. This study represents the first application of AutoML in predicting LIM in GIST patients, offering clinicians a valuable tool for develo** personalized treatment plans.
Data availability
Publicly available datasets were analyzed in this study. These data can be found here: https://seer.cancer.gov/. The datasets supporting the conclusions of this article are included within the article.
References
Akahoshi, K., Oya, M., Koga, T. & Shiratsuchi, Y. Current clinical management of gastrointestinal stromal tumor. World J. Gastroenterol. 24(26), 2806–2817. https://doi.org/10.3748/wjg.v24.i26.2806 (2018).
von Mehren M, Joensuu H. Gastrointestinal Stromal Tumors. J Clin Oncol. 2018;36(2):136–143. doi: https://doi.org/10.1200/JCO.2017.74.9705.
DeMatteo, R. P. et al. Two hundred gastrointestinal stromal tumors: Recurrence patterns and prognostic factors for survival. Ann. Surg. 231(1), 51–58. https://doi.org/10.1097/00000658-200001000-00008 (2000).
Yang, D. Y., Wang, X., Yuan, W. J. & Chen, Z. H. Metastatic pattern and prognosis of gastrointestinal stromal tumor (GIST): A SEER-based analysis. Clin. Transl. Oncol. 21(12), 1654–1662. https://doi.org/10.1007/s12094-019-02094-y (2019) (Epub 2019 Mar 23).
Shi, Y. N. et al. Gastrointestinal stromal tumor (GIST) with liver metastases: An 18-year experience from the GIST cooperation group in North China. Medicine (Baltimore). 96(46), e8240. https://doi.org/10.1097/MD.0000000000008240 (2017).
Mihara, Y. et al. Long-term survival by low-dose imatinib after recurrence of GIST. Gan To Kagaku Ryoho. 49(1), 63–65 (2022) (Japanese).
Liu, Z. et al. Comparison of prognosis between neoadjuvant imatinib and upfront surgery for GIST: A systematic review and meta-analysis. Front. Pharmacol. 29(13), 966486. https://doi.org/10.3389/fphar.2022.966486 (2022).
Kelly, C. M., Gutierrez Sainz, L. & Chi, P. The management of metastatic GIST: Current standard and investigational therapeutics. J. Hematol. Oncol. 14(1), 2. https://doi.org/10.1186/s13045-020-01026-6 (2021).
Lyu, Q. et al. 18F-FDG PET/CT and MR imaging features of liver metastases in gastrointestinal stromal tumors: A cross-sectional analysis. Ann. Transl. Med. 10(22), 1220. https://doi.org/10.21037/atm-22-5181 (2022).
Wu, H. et al. A new online dynamic nomogram: Construction and validation of a predictive model for distant metastasis risk and prognosis in patients with gastrointestinal stromal tumors. J. Gastrointest. Surg. 27(7), 1429–1444. https://doi.org/10.1007/s11605-023-05706-9 (2023) (Epub 2023 May 25).
Zhou, G. et al. A novel nomogram for predicting liver metastasis in patients with gastrointestinal stromal tumor: A SEER-based study. BMC Surg. 20(1), 298. https://doi.org/10.1186/s12893-020-00969-4 (2020).
Leite, D., Martins, A. Jr., Rativa, D., De Oliveira, J. F. L. & Maciel, A. M. A. An automated machine learning approach for real-time fault detection and diagnosis. Sensors (Basel). 22(16), 6138. https://doi.org/10.3390/s22166138 (2022).
Puri, M. Automated machine learning diagnostic support system as a computational biomarker for detecting drug-induced liver injury patterns in whole slide liver pathology images. Assay Drug Dev. Technol. 18(1), 1–10. https://doi.org/10.1089/adt.2019.919 (2020) (Epub 2019 May 31).
Murphy, J. D. et al. Increased risk of additional cancers among patients with gastrointestinal stromal tumors: A population-based study. Cancer. 121(17), 2960–2967. https://doi.org/10.1002/cncr.29434 (2015) (Epub 2015 Apr 30).
Tham, C. K. et al. Gastrointestinal stromal tumour in the elderly. Crit. Rev. Oncol. Hematol. 70(3), 256–261. https://doi.org/10.1016/j.critrevonc.2008.09.007 (2009) (Epub 2008 Oct 31).
Edge, S. B. & Compton, C. C. The American Joint Committee on Cancer: The 7th edition of the AJCC cancer staging manual and the future of TNM. Ann. Surg. Oncol. 17(6), 1471–1474. https://doi.org/10.1245/s10434-010-0985-4 (2010).
Vickers, A. J. & Holland, F. Decision curve analysis to evaluate the clinical benefit of prediction models. Spine J. 21(10), 1643–1648. https://doi.org/10.1016/j.spinee.2021.02.024 (2021) (Epub 2021 Mar 3).
Dash, T. K., Chakraborty, C., Mahapatra, S. & Panda, G. Gradient boosting machine and efficient combination of features for speech-based detection of COVID-19. IEEE J. Biomed. Health Inform. 26(11), 5364–5371. https://doi.org/10.1109/JBHI.2022.3197910 (2022) (Epub 2022 Nov 10).
Candia, J. & Tsang, J. S. eNetXplorer: An R package for the quantitative exploration of elastic net families for generalized linear models. BMC Bioinform. 20(1), 189. https://doi.org/10.1186/s12859-019-2778-5 (2019).
Chen, Y. et al. Using the H2O automatic machine learning algorithms to identify predictors of web-based medical record nonuse among patients in a data-rich environment: Mixed methods study. JMIR Med. Inform. 19(11), e41576. https://doi.org/10.2196/41576 (2023).
Nohara, Y., Matsumoto, K., Soejima, H. & Nakashima, N. Explanation of machine learning models using shapley additive explanation and application for real data in hospital. Comput. Methods Progr. Biomed. 214, 106584. https://doi.org/10.1016/j.cmpb.2021.106584 (2022) (Epub 2021 Dec 10).
Neves, I. et al. Interpretable heartbeat classification using local model-agnostic explanations on ECGs. Comput. Biol. Med. 133, 104393. https://doi.org/10.1016/j.compbiomed.2021.104393 (2021) (Epub 2021 Apr 16).
Guller, U. et al. Revisiting a dogma: Similar survival of patients with small bowel and gastric GIST. A population-based propensity score SEER analysis. Gastr. Cancer. 20(1), 49–60. https://doi.org/10.1007/s10120-015-0571-3 (2017) (Epub 2015 Dec 9).
Miettinen, M. & Lasota, J. Gastrointestinal stromal tumors: Pathology and prognosis at different sites. Semin. Diagn. Pathol. 23(2), 70–83. https://doi.org/10.1053/j.semdp.2006.09.001 (2006) (PMID: 17193820).
Kukar, M. et al. Gastrointestinal stromal tumors (GISTs) at uncommon locations: A large population based analysis. J. Surg. Oncol. 111(6), 696–701. https://doi.org/10.1002/jso.23873 (2015) (Epub 2015 Jan 5).
Miettinen, M., Sobin, L. H. & Lasota, J. Gastrointestinal stromal tumors of the stomach: A clinicopathologic, immunohistochemical, and molecular genetic study of 1765 cases with long-term follow-up. Am. J. Surg. Pathol. 29(1), 52–68. https://doi.org/10.1097/01.pas.0000146010.92933.de (2005).
Gaitanidis, A., Alevizakos, M., Tsaroucha, A., Simopoulos, C. & Pitiakoudis, M. Incidence and predictors of synchronous liver metastases in patients with gastrointestinal stromal tumors (GISTs). Am. J. Surg. 216(3), 492–497. https://doi.org/10.1016/j.amjsurg.2018.04.011 (2018) (Epub 2018 Apr 19).
Agaimy, A. & Wünsch, P. H. Lymph node metastasis in gastrointestinal stromal tumours (GIST) occurs preferentially in young patients < or = 40 years: An overview based on our case material and the literature. Langenbecks Arch. Surg. 394(2), 375–381. https://doi.org/10.1007/s00423-008-0449-5 (2009) (Epub 2008 Dec 23).
Stiles, Z. E. et al. Lymph node metastases in gastrointestinal stromal tumors: An uncommon event. Ann. Surg. Oncol. 29(13), 8641–8648. https://doi.org/10.1245/s10434-022-12582-1 (2022) (Epub 2022 Oct 5).
Gaitanidis, A., El Lakis, M., Alevizakos, M., Tsaroucha, A. & Pitiakoudis, M. Predictors of lymph node metastasis in patients with gastrointestinal stromal tumors (GISTs). Langenbecks Arch. Surg. 403(5), 599–606. https://doi.org/10.1007/s00423-018-1683-0 (2018) (Epub 2018 May 31).
Funding
This study was supported by the Changshu Science and Technology Program (CY202339), the Changshu Health Science and Technology Plan Guiding Project (CSWSZD202204), the Suzhou Youth Science and Technology Project for the Advancement of Science, Education, and Health (KJXW2023067), and the Suzhou 23rd Batch of Science and Technology Development Plan (Clinical Trial Institution Capability Enhancement) Project (SLT 2023006).
Author information
Authors and Affiliations
Contributions
L.L.contributed to data collection and writing. R.Z. was responsible for statistical analysis. Y.S. downloaded the data. Y.S. and J.S. contributed to revising this dissertation. X.X. and J.S. managed this project and provided the funding. All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Liu, L., Zhang, R., Shi, Y. et al. Automated machine learning for predicting liver metastasis in patients with gastrointestinal stromal tumor: a SEER-based analysis. Sci Rep 14, 12415 (2024). https://doi.org/10.1038/s41598-024-62311-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-62311-9
- Springer Nature Limited