
Abstract
Background
Living kidney donors are screened pre-donation to estimate the risk of end-stage kidney disease (ESKD). We evaluate Machine Learning (ML) to predict the progression of kidney function deterioration over time using the estimated GFR (eGFR) slope as the target variable.
Methods
We included 238 living kidney donors who underwent donor nephrectomy. We divided the dataset based on the eGFR slope in the third follow-up year, resulting in 185 donors with an average eGFR slope and 53 donors with an accelerated declining eGFR-slope. We trained three Machine Learning-models (Random Forest [RF], Extreme Gradient Boosting [XG], Support Vector Machine [SVM]) and Logistic Regression (LR) for predictions. Predefined data subsets served for training to explore whether parameters of an ESKD risk score alone suffice or additional clinical and time-zero biopsy parameters enhance predictions. Machine learning-driven feature selection identified the best predictive parameters.
Results
None of the four models classified the eGFR slope with an AUC greater than 0.6 or an F1 score surpassing 0.41 despite training on different data subsets. Following machine learning-driven feature selection and subsequent retraining on these selected features, random forest and extreme gradient boosting outperformed other models, achieving an AUC of 0.66 and an F1 score of 0.44. After feature selection, two predictive donor attributes consistently appeared in all models: smoking-related features and glomerulitis of the Banff Lesion Score.
Conclusions
Training machine learning-models with distinct predefined data subsets yielded unsatisfactory results. However, the efficacy of random forest and extreme gradient boosting improved when trained exclusively with machine learning-driven selected features, suggesting that the quality, rather than the quantity, of features is crucial for machine learning-model performance. This study offers insights into the application of emerging machine learning-techniques for the screening of living kidney donors.
Graphical abstract

Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Living kidney donors face the same risk of develo** end-stage kidney disease (ESKD) as the general population [1, 2]. However, recent studies have called this statement into question [3, 4]. Many transplantation centers encounter a heterogeneous donor pool that is different from the healthy study cohorts of older investigations. Due to long transplantation waiting lists, donors with a lower starting glomerular filtration rate (GFR) or other risk factors such as smoking history may be eligible for donation.
Therefore, thorough screening before donation is essential. Various pre-donation risk assessments have been developed to identify the donors at risk for ESKD [5,6,7]. We use the ESKD risk score for donors which was first published in 2016 by Grams et al. [7]. All risk scores provide applicable tools for clinical practice but are based on statistical approaches. This is where Artificial Intelligence (AI) comes into play based on our hypothesis that artificial intelligence has the potential to improve predictions.
Whereas classic statistics outline relationships between a data sample and a population, Machine Learning (ML), a subgroup of artificial intelligence, is capable of making personalized predictions about a desired outcome by attempting to uncover hidden patterns within the provided data [8]. The goal of identifying borderline donors may be facilitated with machine learning, enabling this donor group to be educated in detail about their possibly increased risk of kidney failure after donation and initiating intensified follow-up care.
The main focus of machine learning studies in transplantation has been on the outcome of graft function and the prediction of graft failure [9,10,11]. When it comes to donors, machine learning research is very scarce. To our knowledge, there is only one recent work using machine learning, carried out by a Korean study group, to predict renal adaptation of living kidney donors [12].
Our study aims to test different machine learning techniques to classify the average eGFR slope or the accelerated declining eGFR slope of living kidney donors, utilizing distinct subsets of the provided data, including parameters from the ESKD risk score, clinical data, and histopathological parameters. We chose the eGFR slope as our target for predictions since it represents a dynamic parameter over time of kidney function.
Methods
Objects and inclusion criteria
For this retrospective study, a total of 238 living kidney donors (sex at birth, female/male [%]: 154 [65]/84 (35); mean age [standard deviation, SD]: 54 [10]) after donor nephrectomy between 2009 and 2020 at the Department of General, Visceral, Cancer and Transplant Surgery, University Hospital of Cologne, Germany, were included. Hand-assisted retroperitoneoscopic donor nephrectomy (HARP) was the surgical technique used [13]. Inclusion criteria were donors who had completed 3 years of postoperative follow-up with complete documentation of serum creatinine values pre-donation and at year 1, 2 and 3 after donation to calculate the estimated GFR (eGFR) at each time point. Included patient characteristics can be divided into three groups:
-
1.
Clinical characteristics of the risk tool for ESKD for kidney donor candidates (age, sex at birth, eGFR, systolic blood pressure, hypertension medication, body mass index [BMI], urine albumin creatinine ratio [ACR] and smoking history) [7]. Non-insulin-independent diabetes and race were excluded from the dataset due to one-dimensional distribution. We excluded outliers (n = 2) in albumin creatinine ratio to ensure no distorted model performance.
-
2.
Other donor characteristics assessed preoperatively (height, weight, smoking pack years, serum creatinine, side of the removed kidney, renal cortex volumetry of the graft and of the remaining kidney, and their ratio [remaining to transplant cortex volumetry]). Renal cortex volumetry was assessed from preoperative computed tomography (CT) scans [14].
-
3.
Histopathological assessment of the time-zero biopsy of the graft (total glomeruli, global glomerulosclerosis, ratio glomerulosclerosis [global glomerulosclerosis to total glomeruli], Banff Lesion Scores [15] of glomerulitis g, tubular atrophy ct, and arteriolar hyalinosis ah). We omitted the other Banff Lesion Scores due to one-dimensional distribution. To ensure that only representative core biopsies were included, a minimum set of ten glomeruli was defined to be representative [16].
The final dataset comprised 22 donor features and a missing feature rate of 17.7%, mainly due to incomplete documentation of the time-zero biopsy. A detailed description of the feature distribution is provided in Table 1. The Ethics Committee of the Faculty of Medicine, University of Cologne, Germany, approved this retrospective study (reference number: 23-1462-retro) and waived the need for patient consent. Data analysis was performed in accordance with relevant guidelines, as outlined by the Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD) statement [17].
Labeling, feature pre-processing and engineering
The dataset was dichotomized into two groups based on the overall decline in eGFR (eGFR slope) over the first, second, and third year after donation. We defined an average decline of the eGFR in year 3 of the follow-up at a rate of < 1 mL/min/1.73 m2/year (average eGFR slope) based on the normal decline in kidney function of approximately 1 mL/min/1.73 m2/year [18]. An accelerated decline of the eGFR in year 3 at a rate of ≥ 1 mL/min/1.73 m2/year was considered a relevant deterioration in kidney function and is referred to as an accelerated declining eGFR slope throughout the remainder of this study for easier readability. Labeling resulted in an unbalanced dataset (average eGFR slope: 185 donors, 78%; accelerated declining eGFR slope: 53 donors, 22%). We used class weights in favor of the underrepresented class. We performed feature engineering of the 7 categorical and 15 continuous variables within scikit learn Pipelines to ensure proper pre-processing of the respective training and test data. We normalized continuous variables to impute missing data points using scikit learns’s k-Nearest Neighbor imputer (n_neighbors = 3). Missing values in categorial data were imputed with the most frequent variable. All categorical features were then converted into dummy variables with one-hot-encoding. In case of binary variables, the first dummy variable was dropped.
Feature selection via sequential forward selection
We performed machine learning-driven sequential forward selection (SFS) for each algorithm on the entire dataset using the open-source MLxtend library [19]. This methodology is considered model-agnostic, meaning that feature selection is independent of the architecture of the model but is based on its influence on performance metrics [20]. The best estimator of each model after hyperparameter search was utilized for sequential forward selection with stratified 5 Cross-Validation (CV)-folds aiming to find the smallest subset of features for the best cross-validation-model performance. The evaluation of model performance after feature selection on the training folds was conducted solely on the respective testing fold to prevent data leakage. The important features that were identified served as a reduced dataset for model training, respectively.
Study design
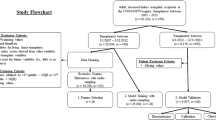
The study design contains two major parts to classify the eGFR slope at year three post-donation (Fig. 1):
-
1.
We utilized both the entire dataset and two predefined subsets generated from the entire dataset for model training to evaluate model performance:
Dataset 1: Parameters of the ESKD risk score (n features = 8, n features after one-hot encoding = 10)
Dataset 2: Dataset 1 + other clinical parameters (n features = 16, n features after one-hot encoding = 18)
Dataset 3: Whole dataset including histopathological parameters (N features = 22, N features after one-hot encoding = 26)
-
2.
Feature Selection with sequential forward selection was only performed on Dataset 3 for each model. We subsequently utilized the selected important features to retrain the models and to evaluate model performance, respectively.

Flow diagram of the study design. First, distinct subsets (dataset 1 and 2) and the whole dataset 3 were used for model training with Random Forest (RF), XG Boost (XG), Support Vector Machine (SVM) and Logistic regression (LR) to classify eGFR slope of living kidney donors in the third follow-up year (y3). Second, for each model, ML-driven feature selection was performed on the entire dataset resulting in a correspondingly selected feature dataset for model retraining and predictions
Machine learning models
We used supervised machine learning techniques for binary classification using the scikit learn package [3, 4]. Identifying these at-risk donors is still an unmet need in clinical practice.
We used the eGFR slope as our target for predictions. As a dynamic parameter, we consider the eGFR slope to be a better parameter for assessing donor kidney function than just eGFR at a specific time point during follow-up. Particularly for donors with borderline pre-donation eGFR, the extent of eGFR changes over time provides a more comprehensive picture of the current kidney function compared to past time-points, and reflects the approach of clinicians by putting eGFR in a temporal context.
The use of eGFR slope as a surrogate parameter to evaluate kidney function has been discussed in previous literature [35–39]. A recently published meta-analysis reported associations between treatment effects altering the GFR slope and the respective clinical endpoints targeting worsening kidney function. The authors concluded that GFR slope serves as a good surrogate parameter for evaluating kidney function in clinical trials [38], which has also been considered by regulatory agencies such as the U.S. Food and Drug Administration (FDA) [40] and the European Medicines Agency (EMA) [41].
A normal decline in kidney function is approximately 1 mL/min/1.73 m2/year [18]. The median eGFR slope of our donor collective was − 0.33 mL/min/1.73 m2/year, which is consistent with previous findings reporting the measured GFR slope of donors to be around − 0.4 mL/min/1.73 m2/year [2, 42]. Based on these findings, we defined a relevant eGFR slope at − 1 mL/min/1.73 m2/year in the third follow-up year. This resulted in an unbalanced dataset with 185 donors in the average eGFR slope cohort and 53 donors in the accelerated declining eGFR slope cohort.
Neither the ESKD risk score nor the descriptive statistics of the other pre-donation donor features used for model training effectively discriminated the donor cohort with the accelerated declining eGFR slope. Therefore, we employed machine learning to effectively identify this donor cohort. Three machine learning models (random forests, extreme gradient boosting, support vector machines) and logistic regression as the state-of-the-art model were utilized to predict accelerated declining eGFR slope of our donor cohort. Overall, no model sufficiently predicted the outcome. Neither of the models exceeded an AUC of 0.7 or an F1 score of 0.5.
Also, Jeon et al. [12] reported mediocre performance with machine learning in predicting the percentage of renal adaptation (6–12 months post-donation eGFR/pre-donation eGFR, cut-off: 65% of pre-donation eGFR after donation) of kidney donors after training with preoperatively assessed donor features. The authors reported an AUC of 0.63, which is similar to our results. They additionally trained the machine learning model to predict the absolute median eGFR of the second half of the first follow-up year (cut-off: 60 mL/min/1.73 m2). Here, clearly improved model performance with an AUC of 0.85 was observed. However, we consider predicting excretory kidney function decline to be superior to predicting GFR alone, as discussed above.
Despite the low predictive performance of the machine learning models, there are some observed trends of the distinct model performances when trained on different data subsets. The first data subset we used for model training included patient characteristics for calculating the ESKD risk score for kidney donors. The risk score was first introduced in 2016 by Grams et al. [7] after observing more than 4,000,000 individuals who were formally eligible for kidney donation, for 4–16 years. In our transplant center, we use this risk score to screen for potential donor candidates and to exclude donors at risk. Our interest was to find out whether these well-established parameters are sufficient to predict accelerated declining eGFR slope with machine learning.
The calculated 15-year and lifetime ESKD risk score for our donor cohort was below 1% for both eGFR-slope cohorts. Interestingly, a statistically significant difference was noted for the 15-year ESKD risk score. However, the differences in the absolute values were marginal. The calculated risk scores themselves were not included in model training. Likewise, we did not consider non-insulin dependent diabetes and race for model training due to one-dimensionality in our patient cohort.
The best performance using the risk score dataset was noted for support vector machines, which are known to be efficient with small datasets [43]. However, differences in model performance compared to the other models were marginal. In our study, machine learning models failed to adequately predict accelerated declining eGFR slope after being trained on previously evaluated patient characteristics for ESKD risk-prediction.
Subsequently, we integrated more features into the dataset and expected improved predictions related to the greater amount of information. We included additional donor details such as body weight, height, pack years, or renal cortex volumetry from CT scans (Dataset 2). For the entire dataset (Dataset 3), results of the time-zero biopsy, including Banff Lesion Scores, were added. Even though the histology of living donor kidneys is not available in pre-donation screening, results of the time-zero biopsy might affect the remaining renal outcome of living kidney donors.
Including more parameters led to slightly better results for random forests and extreme gradient boosting but worsened the predictions for support vector machines. Logistic regression showed consistent performance across the different data subsets. Barah et al. [44] also reported a slight improvement in model performance for predicting kidney discard with machine learning after adding parameters from the graft biopsy. Nevertheless, expanding the dataset with predefined features did not improve predicting donors with an accelerated declining eGFR slope.
Finally, we applied machine learning-driven feature selection to the whole dataset. We used model agnostic sequential feature selection in a forward approach by sequentially adding the most informative features to enhance model performance in k-fold cross-validation [20]. After sequential forward selection, each model exhibited a different subset of best predictive features. Eight and six best predictive features were found for logistic regression/support vector machines and extreme gradient boosting/random forests, respectively. We then retrained each model with the respective selected features. A clear improvement in prediction was observed for extreme gradient boosting and random forests. Both ensemble methods revealed a k-fold AUC of 0.66 and a k-fold F1 score of 0.44, and outperformed logistic regression and support vector machines which did not show improved predictive performance. These findings are consistent with previous machine learning studies in kidney transplantation: Feature selection improved predictive performance [9], and random forests or extreme gradient boosting outperformed logistic regression [9, 10, 44].
The best predictive features that appeared in all four models after sequential forward selection were the features related to smoking, namely smoking history or pack years, and the Banff Lesion Score g (glomerulitis). Smoking as a cardiovascular risk factor is widely known to enhance the incidence of develo** chronic kidney disease [45]. Therefore, it is not surprising that all four models use features related to smoking to improve predictions for accelerated declining eGFR slope.
The Banff classification is designed for allograft pathologies [15]. Nevertheless, pathologies in the time-zero biopsy provide insights about the donor’s remaining kidney. The Banff g lesion score classifies the proportion of microvascular inflammation within glomeruli which may be linked to antibody-mediated graft rejection or to recurrent or de novo glomerulonephritis [15]. Previous studies reported that glomerulitis was associated with allograft pathologies or graft failure [46–50]. The conclusive determination of whether the reasons for glomerulitis may be recipient-associated, such as humoral rejection or recurrence of an underlying condition, is hindered by inconsistent documentation regarding the timing of biopsy acquisition in relation to reperfusion. Whether the presence of glomerulitis in the time-zero biopsy of the graft allows a conclusion to be drawn about the outcome of the remaining kidney function of living kidney donors needs to be investigated in further studies.
From a data science perspective, we faced a few hurdles that accounted for the moderate model performances. We trained our models on a small dataset that was unbalanced and consisted of missing values. There is a widespread belief that artificial intelligence is designed to only recognize patterns in large amounts of data. However, small datasets are common in the medical field. Althnian et al. [51] empirically investigated the influence of data size on the performance of machine learning models using datasets from the medical domain. They found that it is not the data size itself that affects the predictive ability, but rather how closely the data reflect the general distribution of a patient cohort. These findings are consistent with the results of our study: Not including more data but identifying the predictive features and retraining the models without redundant features improved the predictions.
The limitations of our study are that we used the eGFR values instead of measured GFR to calculate the eGFR slope. Our dataset consisted of missing values, mainly due to incomplete documentation of the histopathological parameters. There are no gold standards in data science for the allowed number of missing values in a dataset, which, thus, remains a field of empirical testing. We did not include all parameters that define the Banff classification due to one-dimensionality. Our dataset stemmed from one transplantation center. The performance of the machine learning models was evaluated by k-fold cross-validation which allows to investigate the ability of the models to generalize the information. To further test the predictive performance and generalizability of the models, an external test set is required for validation.
Conclusion
Our aim was to predict accelerated declining eGFR slope of living kidney donors using machine learning. Training the models with distinct predefined data subsets did not produce satisfactory predictions for any model. However, the predictive performance of the random forests and extreme gradient boosting improved and outperformed logistic regression after training with only important features after machine learning-driven feature selection. Future studies need to be conducted with extended data size to evaluate whether machine learning can sufficiently predict the eGFR slope to identify donors at risk for declining kidney function.
Data availability
The dataset generated during the current study is available from the corresponding author on reasonable request.
Abbreviations
- ACR:
-
Urine albumin creatinine ratio
- AI:
-
Artificial intelligence
- AUC:
-
Area under the curve
- BMI:
-
Body mass index
- CKD-EPI:
-
Chronic Kidney Disease Epidemiology Collaboration
- CV:
-
Cross-validation
- CT:
-
Computed tomography
- eGFR:
-
Estimated glomerular filtration rate
- ESKD:
-
End-stage kidney disease
- HARP:
-
Hand-assisted retroperitoneoscopic donor nephrectomy
- IQR:
-
Interquartile range
- LR:
-
Logistic regression
- ML:
-
Machine learning
- RF:
-
Random forest
- SD:
-
Standard deviation
- SFS:
-
Sequential forward selection
- SVM:
-
Support vector machine
- XG:
-
Extreme gradient (XG) boosting
References
Fehrman-Ekholm I et al (1997) Kidney donors live longer. Transplantation 64(7):976–978. https://doi.org/10.1097/00007890-199710150-00007
Ibrahim HN et al (2009) Long-term consequences of kidney donation. N Engl J Med 360(5):459–469. https://doi.org/10.1056/NEJMoa0804883
Mjøen G et al (2014) Long-term risks for kidney donors. Kidney Int 86(1):162–167. https://doi.org/10.1038/ki.2013.460
Muzaale AD et al (2014) Risk of end-stage renal disease following live kidney donation. JAMA 311(6):579–586. https://doi.org/10.1001/jama.2013.285141
Ibrahim HN et al (2016) Renal function profile in white kidney donors: the first 4 decades. J Am Soc Nephrol 27(9):2885–2893. https://doi.org/10.1681/asn.2015091018
Massie AB et al (2017) Quantifying postdonation risk of ESRD in living kidney donors. J Am Soc Nephrol 28(9):2749–2755. https://doi.org/10.1681/asn.2016101084
Grams ME et al (2016) Kidney-failure risk projection for the living kidney-donor candidate. N Engl J Med 374(5):411–421. https://doi.org/10.1056/NEJMoa1510491
Bzdok D, Altman N, Krzywinski M (2018) Statistics versus machine learning. Nat Methods 15(4):233–234. https://doi.org/10.1038/nmeth.4642
Kawakita S et al (2020) Personalized prediction of delayed graft function for recipients of deceased donor kidney transplants with machine learning. Sci Rep 10(1):18409. https://doi.org/10.1038/s41598-020-75473-z
Minato A et al (2023) Machine learning model to predict graft rejection after kidney transplantation. Transplant Proc. https://doi.org/10.1016/j.transproceed.2023.07.021
Naqvi SAA et al (2021) Predicting kidney graft survival using machine learning methods: prediction model development and feature significance analysis study. J Med Internet Res 23(8):e26843. https://doi.org/10.2196/26843
Jeon J et al (2023) Prediction tool for renal adaptation after living kidney donation using interpretable machine learning. Front Med (Lausanne) 10:1222973. https://doi.org/10.3389/fmed.2023.1222973
Wadstrom J, Lindstrom P (2002) Hand-assisted retroperitoneoscopic living-donor nephrectomy: initial 10 cases. Transplantation 73(11):1839–1840. https://doi.org/10.1097/00007890-200206150-00024
Wahba R et al (2016) Computed tomography volumetry in preoperative living kidney donor assessment for prediction of split renal function. Transplantation 100(6):1270–1277. https://doi.org/10.1097/tp.0000000000000889
Roufosse C et al (2018) A 2018 reference guide to the banff classification of renal allograft pathology. Transplantation 102(11):1795–1814. https://doi.org/10.1097/tp.0000000000002366
Racusen LC et al (1999) The Banff 97 working classification of renal allograft pathology. Kidney Int 55(2):713–723. https://doi.org/10.1046/j.1523-1755.1999.00299.x
Collins GS et al (2015) transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Br J Surg 102(3):148–158. https://doi.org/10.1002/bjs.9736
Waas T et al (2021) Distribution of estimated glomerular filtration rate and determinants of its age dependent loss in a German population-based study. Sci Rep 11(1):10165. https://doi.org/10.1038/s41598-021-89442-7
Raschka S (2018) MLxtend: providing machine learning and data science utilities and extensions to Python’s scientific computing stack. J Open Source Softw 3(24):638. https://doi.org/10.21105/joss.00638
Ferri FJ et al (1994) Comparative study of techniques for large-scale feature selection. In: Gelsema ES, Kanal LS (eds) machine intelligence and pattern recognition. North-Holland, Amsterdam, pp 403–413. https://doi.org/10.1016/B978-0-444-81892-8.50040-7
Pedregosa F et al (2011) Scikit-learn: machine learning in Python. J Mach Learn Res 12:2825–2830. https://doi.org/10.48550/ar**v.1201.0490
Breiman L (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Chen T, Guestrin C (2016) XGBoost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 785–794. https://doi.org/10.1145/2939672.2939785
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297. https://doi.org/10.1007/BF00994018
Kleinbaum DG (1994) Introduction to logistic regression. Logistic regression: a self-learning text. Springer, New York, pp 1–38. https://doi.org/10.1007/978-1-4757-4108-7_1
Levey AS et al (2009) A new equation to estimate glomerular filtration rate. Ann Intern Med 150(9):604–612. https://doi.org/10.7326/0003-4819-150-9-200905050-00006
Hand DJ, Christen P, Kirielle N (2021) F*: an interpretable transformation of the F-measure. Mach Learn 110(3):451–456. https://doi.org/10.1007/s10994-021-05964-1
McKinney W (2010) Data structures for statistical computing in python. In: Proceedings of the 9th Python in science conference, Austin, TX
Harris CR et al (2020) Array programming with NumPy. Nature 585(7825):357–362. https://doi.org/10.1038/s41586-020-2649-2
Hunter JD (2007) Matplotlib: a 2D graphics environment. Comput Sci Eng 9(03):90–95. https://doi.org/10.1109/MCSE.2007.55
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors have no disclosures, and had no financial support.
Ethical approval
The Ethics Commission of the Faculty of Medicine, University of Cologne, Germany, approved this retrospective study (reference number: 23–1462-retro) and waived the need for patient consent. Data analysis and all methods were performed in accordance with the standards as laid down in the 1964 Declaration of Helsinki.
Consent to publication
We confirm that this manuscript has not been published elsewhere and is not under consideration by another journal. All authors have approved the manuscript and agree with its submission to Journal of Nephrology.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lukomski, L., Pisula, J., Wagner, T. et al. First experiences with machine learning predictions of accelerated declining eGFR slope of living kidney donors 3 years after donation. J Nephrol (2024). https://doi.org/10.1007/s40620-024-01967-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40620-024-01967-y