
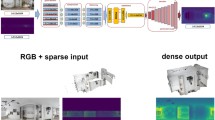
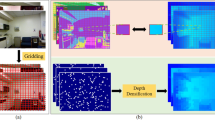
Abstract
Existing depth completion methods are often targeted at a specific sparse depth type and generalize poorly across task domains. We present a method to complete sparse/semi-dense, noisy, and potentially low-resolution depth maps obtained by various range sensors, including those in modern mobile phones, or by multi-view reconstruction algorithms. Our method leverages a data-driven prior in the form of a single image depth prediction network trained on large-scale datasets, the output of which is used as an input to our model. We propose an effective training scheme where we simulate various sparsity patterns in typical task domains. In addition, we design two new benchmarks to evaluate the generalizability and robustness of depth completion methods. Our simple method shows superior cross-domain generalization ability against state-of-the-art depth completion methods, introducing a practical solution to high-quality depth capture on a mobile device.
Similar content being viewed by others

References
S. S. Shi, C. X. Guo, L. Jiang, Z. Wang, J. P. Shi, X. G. Wang, H. S. Li. PV-RCNN: Point-voxel feature set abstraction for 3D object detection. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, pp. 10526–10535, 2020. DOI: https://doi.org/10.1109/CVPR42600.2020.01054.
Y. Wang, W. L. Chao, D. Garg, B. Hariharan, M. Campbell, K. Q. Weinberger. Pseudo-LiDAR from visual depth estimation: Bridging the gap in 3D object detection for autonomous driving. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, pp. 8437–8455, 2019. DOI: https://doi.org/10.1109/CVPR.2019.00864.
R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohi, J. Shotton, S. Hodges, A. Fitzgibbon. KinectFusion: Real-time dense surface map** and tracking. In Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, pp. 127–136, 2011. DOI: https://doi.org/10.1109/IS-MAR.2011.6092378.
R. Mur-Artal, J. D. Tardós. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Transactions on Robotics, vol. vol. 33, no. 5, pp. 1255–1262, 2017. DOI: https://doi.org/10.1109/TRO.2017.2705103.
G. K. Xu, W. Yin, H. Chen, C. H. Shen, K. Cheng, F. Zhao. FrozenRecon: Pose-free 3D scene reconstruction with frozen depth models. In Proceedings of IEEE/CVF International Conference on Computer Vision, Paris, France, pp. 9276–9286, 2023. DOI: https://doi.org/10.1109/ICCV51070.2023.00854.
T. Schöps, J. L. Schönberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, A. Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, pp. 2538–2547, 2017. DOI: https://doi.org/10.1109/CVPR.2017.272.
Y. Yao, Z. X. Luo, S. W. Li, J. Y. Zhang, Y. F. Ren, L. Zhou, T. Fang, L. Quan. BlendedMVS: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, pp. 1787–1796, 2020. DOI: https://doi.org/10.1109/CVPR42600.2020.00186.
F. H. Zhang, V. Prisacariu, R. G. Yang, P. H. S. Torr. GA-Net: Guided aggregation net for end-to-end stereo matching. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, pp. 185–194, 2019. DOI: https://doi.org/10.1109/CVPR.2019.00027.
Y. D. Zhang, T. Funkhouser. Deep depth completion of a single RGB-D image. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, pp. 175–185, 2018. DOI: https://doi.org/10.1109/CVPR.2018.00026.
D. Senushkin, M. Romanov, I. Belikov, N. Patakin, A. Konushin. Decoder modulation for indoor depth completion. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, Prague, Czech Republic, pp. 2181–2188, 2021. DOI: https://doi.org/10.1109/IROS51168.2021.9636870.
Y. K. Huang, T. H. Wu, Y. C. Liu, W. H. Hsu. Indoor depth completion with boundary consistency and self-attention. In Proceedings of IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Republic of Korea, pp. 1070–1078, 2019. DOI: https://doi.org/10.1109/ICCVW.2019.00137.
X. J. Cheng, P. Wang, C. Y. Guan, R. G. Yang. CSPN++: Learning context and resource aware convolutional spatial propagation networks for depth completion. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, USA, pp. 10615–10622, 2020. DOI: https://doi.org/10.1609/aaai.v34i07.6635.
J. Park, K. Joo, Z. Hu, C. K. Liu, I. S. Kweon. Non-local spatial propagation network for depth completion. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, pp. 120–136, 2020. DOI: https://doi.org/10.1007/978-3-030-58601-0_8.
Y. Xu, X. G. Zhu, J. P. Shi, G. F. Zhang, H. J. Bao, H. S. Li, Depth completion from sparse LiDAR data with depth-normal constraints. In Proceedings of IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, pp. 2811–2820, 2019. DOI: https://doi.org/10.1109/ICCV.2019.00290.
J. X. Qiu, Z. P. Cui, Y. D. Zhang, X. D. Zhang, S. C. Liu, B. Zeng, M. Pollefeys. DeepLiDAR: Deep surface normal guided depth prediction for outdoor scene from sparse LiDAR data and single color image. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019, pp. 3308–3317. DOI: https://doi.org/10.1109/CVPR.2019.00343.
X. J. Cheng, P. Wang, R. G. Yang. Learning depth with convolutional spatial propagation network. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. vol. 42, no. 10, pp. 2361–2379, 2020. DOI: https://doi.org/10.1109/TPAMI.2019.2947374.
N. Silberman, D. Hoiem, P. Kohli, R. Fergus. Indoor segmentation and support inference from RGBD images. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, pp. 746–760, 2012. DOI: https://doi.org/10.1007/978-3-642-33715-4_54.
J. Uhrig, N. Schneider, L. Schneider, U. Franke, T. Brox, A. Geiger. Sparsity invariant CNNs. In Proceedings of International Conference on 3D Vision, Qingdao, China, pp. 11–20, 2017. DOI: https://doi.org/10.1109/3DV.2017.00012.
X. J. Cheng, P. Wang, R. G. Yang. Depth estimation via affinity learned with convolutional spatial propagation network. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, pp. 108–125, 2018. DOI: https://doi.org/10.1007/978-3-030-01270-0_7.
S. Imran, X. M. Liu, D. Morris. Depth completion with twin surface extrapolation at occlusion boundaries. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, pp. 2583–2592, 2021. DOI: https://doi.org/10.1109/CVPR46437.2021.00261.
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, Canada, pp. 23–30, 2017. DOI: https://doi.org/10.1109/IROS.2017.8202133.
J. Tobin, L. Biewald, R. Duan, M. Andrychowicz, A. Handa, V. Kumar, B. McGrew, A. Ray, J. Schneider, P. Welinder, W. Zaremba, P. Abbeel. Domain randomization and generative models for robotic gras**. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, pp. 3482–3489, 2018. DOI: https://doi.org/10.1109/IROS.2018.8593933.
S. Zakharov, W. Kehl, S. Ilic. DeceptionNet: Network-driven domain randomization. In Proceedings of IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, pp. 532–541, 2019. DOI: https://doi.org/10.1109/ICCV.2019.00062.
W. Yin, J. M. Zhang, O. Wang, S. Niklaus, L. Mai, S. M. Chen, C. H. Shen. Learning to recover 3D scene shape from a single image. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, pp. 204–213, 2021. DOI: https://doi.org/10.1109/CVPR46437.2021.00027.
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, V. Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. vol. 44, no. 3, pp. 1623–1637, 2022. DOI: https://doi.org/10.1109/TPAMI.2020.3019967.
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niebner, M. Savva, S. R. Song, A. Zeng, Y. D. Zhang. Matter-port3D: Learning from RGB-D data in indoor environments. In Proceedings of International Conference on 3D Vision, Qingdao, China, pp. 667–676, 2017. DOI: https://doi.org/10.1109/3DV.2017.00081.
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, M. Nießner. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017, pp. 2432–2443. DOI: https://doi.org/10.1109/CVPR.2017.261.
I. Vasiljevic, N. Kolkin, S. Y. Zhang, R. T. Luo, H. C. Wang, F. Z. Dai, A. F. Daniele, M. Mostajabi, S. Basart, M. R. Walter, G. Shakhnarovich. DIODE: A dense indoor and outdoor DEpth dataset, [Online], Available: https://arxiv.org/abs/1908.00463, 2019.
J. L. Schönberger, E. L. Zheng, J. M. Frahm, M. Pollefeys. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, pp 501–518, 2016. DOI: https://doi.org/10.1007/978-3-319-46487-9_31.
L. Huynh, P. Nguyen, J. Matas, E. Rahtu, J. Heikkila. Boosting monocular depth estimation with lightweight 3D point fusion. In Proceedings of IEEE/CVF International Conference on Computer Vision, Montreal, Canada, pp. 12747–12756, 2021. DOI: https://doi.org/10.1109/ICCV48922.2021.01253.
Y. Chen, B. Yang, M. Liang, R. Urtasun. Learning joint 2D-3D representations for depth completion. In Proceedings of IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, pp. 10022–10031, 2019. DOI: https://doi.org/10.1109/ICCV.2019.01012.
W. F. Chen, S. Y. Qian, J. Deng. Learning single-image depth from videos using quality assessment networks. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, pp. 5597–5606, 2019. DOI: https://doi.org/10.1109/CVPR.2019.00575.
Y. C. Yang, A. Wong, S. Soatto. Dense depth posterior (DDP) from single image and sparse range. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, pp. 3348–3357, 2019. DOI: https://doi.org/10.1109/CVPR.2019.00347.
C. D. Herrera, J. Kannala, L. Ladický, J. Heikkilä. Depth map inpainting under a second-order smoothness prior. In Proceedings of Scandinavian Conference on Image Analysis, Espoo, Finland, pp. 555–566, 2013. DOI: https://doi.org/10.1007/978-3-642-38886-6_52.
K. Matsuo, Y. Aoki. Depth image enhancement using local tangent plane approximations. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, pp. 3574–3583, 2015. DOI: https://doi.org/10.1109/CVPR.2015.7298980.
A. A. Albishri, S. J. H. Shah, Y. Lee. CU-Net: Cascaded u-net model for automated liver and lesion segmentation and summarization. In Proceedings of IEEE International Conference on Bioinformatics and Biomedicine, San Diego, USA, pp. 1416–1423, 2019. DOI: https://doi.org/10.1109/BIBM47256.2019.8983266.
G. K. Xu, W. Yin, H. Chen, C. H. Shen, K. Cheng, F. Wu, F. Zhao. Towards 3D scene reconstruction from locally scale-aligned monocular video depth, [Online], Available: https://arxiv.org/abs/2202.01470, 2023.
D. Eigen, C. Puhrsch, R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, pp. 2366–2374, 2014. DOI: https://doi.org/10.5555/2969033.2969091.
W. Yin, Y. F. Liu, C. H. Shen, Y. L. Yan. Enforcing geometric constraints of virtual normal for depth prediction. In Proceedings of IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, pp. 5683–5692, 2019. DOI: https://doi.org/10.1109/ICCV.2019.00578.
F. Y. Liu, C. H. Shen, G. S. Lin, I. Reid. Learning depth from single monocular images using deep convolutional neural fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. vol. 38, no. 10, pp. 2024.2039, 2016. DOI: https://doi.org/10.1109/TPAMI.2015.2505283.
K. **an, J. M. Zhang, O. Wang, L. Mai, Z. Lin, Z. G. Cao. Structure-guided ranking loss for single image depth prediction. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, USA, pp. 608–617, 2020. DOI: https://doi.org/10.1109/CVPR42600.2020.00069.
J. W. Bian, H. Y. Zhan, N. Y. Wang, Z. C. Li, L. Zhang, C. H. Shen, M. M. Cheng, I. Reid. Unsupervised scale-consistent depth learning from video. International Journal of Computer Vision, vol. vol. 129, no. 9, pp. 2548.2564, 2021. DOI: https://doi.org/10.1007/s11263-021-01484-6.
C. Godard, O. Mac Aodha, M. Firman, G. Brostow. Digging into self-supervised monocular depth estimation. In Proceedings of IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, pp. 3827–3837, 2019. DOI: https://doi.org/10.1109/ICCV.2019.00393.
W. Yin, X. L. Wang, C. H. Shen, Y. F. Liu, Z. Tian, S. C. Xu, C. M. Sun, D. Renyin. DiverseDepth: Affine-invariant depth prediction using diverse data, [Online], Available: https://arxiv.org/abs/2002.00569, 2020.
J. P. Wang, P. Wang, X. X. Long, C. Theobalt, T. Komura, L. J. Liu, W. P. Wang. NeuRIS: Neural reconstruction of indoor scenes using normal priors. In Proceedings of the 17th European Conference on Computer Vision, Tel Aviv, Israel, pp. 139–155, 2022. DOI: https://doi.org/10.1007/978-3-031-19824-3_9.
F. C. Ma, S. Karaman. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of IEEE International Conference on Robotics and Automation, Brisbane, Australia, pp. 4796–4803, 2018. DOI: https://doi.org/10.1109/ICRA.2018.8460184.
E. Rosten, T. Drummond. Machine learning for high-speed corner detection. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, pp. 430–443, 2006. DOI: https://doi.org/10.1007/11744023_34.
S. F. Liu, S. De Mello, J. W. Gu, G. Y. Zhong, M. H. Yang, J. Kautz. Learning affinity via spatial propagation networks. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, USA, pp. 1519–1529, 2017. DOI: https://doi.org/10.5555/3294771.3294916.
S. Imran, Y. F. Long, X. M. Liu, D. Morris. Depth coefficients for depth completion. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, USA, pp. 12438–12447, 2019. DOI: https://doi.org/10.1109/CVPR.2019.01273.
B. U. Lee, K. Lee, I. S. Kweon. Depth completion using plane-residual representation. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, USA, pp. 13911–13920, 2021. DOI: https://doi.org/10.1109/CVPR46437.2021.01370.
D. Seichter, M. Kohler, B. Lewandowski, T. Wengefeld, H. M. Gross. Efficient RGB-D semantic segmentation for indoor scene analysis. In Proceedings of IEEE International Conference on Robotics and Automation, **’an, China, pp. 13525–13531, 2020. DOI: https://doi.org/10.1109/ICRA48506.2021.9561675.
A. R. Zamir, A. Sax, W. Shen, L. Guibas, J. Malik, S. Savarese. Taskonomy: Disentangling task transfer learning. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, USA, pp. 3712–3722, 2018. DOI: https://doi.org/10.1109/CVPR.2018.00391.
Y. Kim, H. Jung, D. Min, K. Sohn. Deep monocular depth estimation via integration of global and local predictions. IEEE Transactions on Image Processing, vol. vol. 27, no. 8, pp. 4131–4144, 2018. DOI: https://doi.org/10.1109/TIP.2018.2836318.
W. S. Wang, D. L. Zhu, X. W. Wang, Y. Y. Hu, Y. H. Qiu, C. Wang, Y. F. Hu, A. Kapoor, S. Scherer. TartanAir: A dataset to push the limits of visual SLAM. In Proceedings of IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, USA, pp. 4909–4916, 2020. DOI: https://doi.org/10.1109/IROS45743.2020.9341801.
K. M. He, X. Y. Zhang, S. Q. Ren, J. Sun. Deep residual learning for image recognition. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, pp. 770–778, 2016. DOI: https://doi.org/10.1109/CVPR.2016.90.
R. Garg, N. Wadhwa, S. Ansari, J. Barron. Learning single camera depth estimation using dual-pixels. In Proceedings of IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, pp. 7627–7636, 2019. DOI: https://doi.org/10.1109/ICCV.2019.00772.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors declared that they have no conflicts of interest to this work.
Additional information
Guangkai Xu received the B. Eng. degree in automation in the School of Automation Engineering, the University of Electronic Science and Technology of China (UESTC), China in 2020, and M. Eng. degree in control science and engineering in the School of Information Science and Technology, University of Science and Technology of China (USTC), China in 2023. Currently, he is a Ph. D. degree candidate in the College of Computer Science and Technology, Zhejiang University, China.
His research interests include monocular depth estimation, 3D scene reconstruction and rendering, and visual-language models.
Wei Yin received the Ph. D. degree in computer science from University of Adelaide, Australia in 2022. Currently, he is a senior research engineer at Dajiang Technology in ShenZhen, China.
His research interests include autonomous driving and 3D reconstruction.
Jianming Zhang received the Ph. D. degree in computer vision with Prof. Stan Sclaroff at Boston University, USA in 2016. Currently, he is a researcher at Adobe in California, USA.
His research interests include deep learning, image processing and intelligent systems.
Oliver Wang received the B. Sc. degree in computer science from Cornell University, USA in 2003, the M. Sc. and Ph. D. degrees in computer science from University of California, Santa Cruz, USA in 2006 and 2010, respectively. He is currently a senior staff research scientist at Google research, USA.
His research interests include image and video processing/editing, computer vision, machine learning and photography.
Simon Niklaus received the Ph. D. degree in computer science from Portland State University, USA in 2020. He is a researcher at Adobe, USA. He is a student of Feng Liu and is grateful for his internship at Adobe while working with Long Mai on the 3D Ken Burns project, and his internship at Google while working with Tianfan Xue on an undisclosed project within Marc Levoy’s team, and his first years at Adobe when he was reporting to Oliver Wang.
His research interests include AI & machine learning, computer vision, imaging & video, graphics (2D & 3D)
Simon Chen received the Ph. D. degree in electrical engineering with Prof. Robert Haralick, University of Washington, USA in 1995. He is currently a senior principal scientist at Adobe, USA.
His research interests include image processing, computer vision, deep learning and applications.
Jia-Wang Bian received the B. Eng. degree in computer science from Nankai University, China in 2016. After that, he did a research assistant job at the Singapore University of Technology and Design, Singapore. He received the Ph. D. degree in computer science from the University of Adelaide, Australia in 2022. Also, he did research intern jobs in research institutes/companies, including the Advanced Digital Sciences Center, Tusimple, Amazon, and Facebook. He is currently a postdoctoral researcher at the University of Oxford, UK.
His research interest is 3D computer vision.
Rights and permissions
About this article

Cite this article
Xu, G., Yin, W., Zhang, J. et al. Towards Domain-agnostic Depth Completion. Mach. Intell. Res. (2024). https://doi.org/10.1007/s11633-024-1494-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11633-024-1494-4