
Abstract
Compartmental models are commonly used in practice to investigate the dynamical response of infectious diseases such as the COVID-19 outbreak. Such models generally assume exponentially distributed latency and infectiousness periods. However, the exponential distribution assumption fails when the sojourn times are expected to distribute around their means. This study aims to derive a novel S (Susceptible)-E (Exposed)-P (Presymptomatic)-A (Asymptomatic)-D (Symptomatic)-C (Reported) model with arbitrarily distributed latency, presymptomatic infectiousness, asymptomatic infectiousness, and symptomatic infectiousness periods. The SEPADC model is represented by nonlinear Volterra integral equations that generalize ordinary differential equation-based models. Our primary aim is the derivation of a general relation between intrinsic growth rate r and basic reproduction number \(R_0\) with the help of the well-known Lotka–Euler equation. The resulting \(r-R_0\) equation includes separate roles of various stages of the infection and their sojourn time distributions. We show that \(R_0\) estimates are considerably affected by the choice of the sojourn time distributions for relatively higher values of r. The well-known exponential distribution assumption has led to the underestimation of \(R_0\) values for most of the countries. Exponential and delta-distributed sojourn times have been shown to yield lower and upper bounds of the \(R_0\) values depending on the r values. In quantitative experiments, \(R_0\) values of 152 countries around the world were estimated through our novel formulae utilizing the parameter values and sojourn time distributions of the COVID-19 pandemic. The global convergence, \(R_0=4.58\), has been estimated through our novel formulation. Additionally, we have shown that increasing the shape parameter of the Erlang distributed sojourn times increases the skewness of the epidemic curves in entire dynamics.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In December 2019, a novel enveloped RNA beta-coronavirus that causes coronavirus disease, COVID-19, emerged in Wuhan, China, and the disease has quickly turned into a global crisis. The effects of the spread of the disease and the factors affecting its spread have been investigated [1, 2]. In the COVID-19 outbreak, presymptomatic, asymptomatic, and symptomatic cases are known to have separate roles on the transmission chains [3,4,5,6] due to the considerable length of the incubation periods [7]. The COVID-19 outbreak has lower latency periods than the incubation periods, which explains the existence of the presymptomatic transmission [3]. Additionally, the role of presymptomatic and asymptomatic transmissions was shown to be around %50 of total cases [5].
The existence of the presymptomatic, asymptomatic, and symptomatic infectors led the mathematical modelers to derive suitable compartmental models [5, 8,9,10] for the COVID-19 outbreak. These models are represented by the ordinary differential equations (ODEs) system and have the exponential distribution assumption of the sojourn times. However, statistical analyses of the latency, presymptomatic, asymptomatic, and symptomatic periods of the COVID-19 outbreak with clinical data suggest that the necessity of the Erlang, lognormal, or Weibull-like probability distributions functions (pdf) to represent the sojourn times [11,12,13,14]. In this context, the exponentially distributed ODE models fail to represent the true dynamics by approximating the realistic pdf of sojourn times.
Non-exponentially distributed compartmental models such as the SIR [15, 16], the SEIR [17, 18] or the SEQIHR models [19,20,21] were extensively studied in the literature to represent the existing sojourn time distributions realistically. The idea behind such models consisted of using survival functions in the model equations. The resulting non-exponentially distributed models have been generally represented by the Volterra integral equations [19]. These models were derived from understanding the effect of the sojourn time distributions on non-pharmacological interventions such as quarantine and isolation [19,20,21]. Additionally, how and when exponential distribution assumptions may fail were investigated through these studies.
The basic reproduction number \(\left( R_0\right) \) of an outbreak denotes the mean number of secondary infections during which the whole population is susceptible, and the non-pharmacological interventions have not yet been implemented. As realized from the definition, one needs two critical parameters for the estimation of \(R_0\): the transmission rate and infectiousness period of an outbreak such as COVID-19 [8, 22]. For early dynamics of an outbreak, it is common to relate \(R_0\) with the intrinsic growth rate (r) of the stage functions [23,24,25,26]. In this context, various studies have been carried out to find more realistic \(r-R_0\) relations in the presence of an arbitrary distribution of the sojourn times. For example, widely considered formulations \(R_0=1+rT_P\) and \(R_0=\left( 1+rT_E\right) \left( 1+rT_P\right) \) (\(T_E\) and \(T_P\) are the mean latency and infectious periods) were shown to belong to the exponentially distributed SIR and SEIR models, respectively [25]. Generalizations of these formulae were done by using the well-known Euler–Lotka equations [27]. Thence, derivation of such a generalized relation \(r-R_0\) for the early dynamics of the COVID-19 outbreak is one of the primary aims of this study.

Graphical illustration for branching process of the SEPADC model. \(P_E\left( s\right) ,\ P_P\left( s\right) ,\ P_A\left( s\right) \) and \(P_D\left( s\right) \) denote the survival functions for exposed, presymptomatic, asymptomatic and symptomatic stages

Illustration of the various survival functions for latency and infectious periods with mean \(\mu =4\)
In this study, we have derived an S (Susceptible)-E (Exposed)-P (Presymptomatic)-A (Asymptomatic)-D (Symptomatic)-C (Reported) model by taking into account the arbitrary distribution of latency, presymptomatic, asymptomatic and symptomatic periods. Derivation of the SEPADC model is inspired by two facts: the existence of the separate roles of presymptomatic, asymptomatic, and symptomatic infectors [4] and the reality of the arbitrary distributions of the sojourn times [19]. Here we have shown that the exponential and delta-distributed models can be reduced from the general SEPADC model by converting the Volterra integral equations into the system of ODEs. Using the well-known Euler–Lotka equation, we have formulated \(r-R_0\) relation of the SEPADC model through the Laplace transforms of the pdf of sojourn time distributions. We have also shown that some existing \(r-R_0\) relations are exceptional cases of our \(r-R_0\) formula by considering the widely used exponential, delta, and Erlang distributions. \(R_0\) values of COVID-19 outbreak for 152 countries around the world are estimated through our novel \(r-R_0\) formulation. We have shown the global convergence, \(R_0=4.58\), through the Erlang distribution of the sojourn times. We have also studied how the sojourn time distributions affected the morphologies of the epidemic curves.
2 SEPADC model with arbitrary sojourn time distributions
2.1 Derivation of the SEPADC model
We assume that the whole population is divided into six categories with \(S\left( t\right) \) (susceptible), E(t) (exposed), P(t) (presymptomatic), A(t) (asymptomatic), D(t) (symptomatic) and C(t) (reported). The existence of the separate roles of the presymptomatic, asymptomatic, and symptomatic infectors for the dynamics of COVID-19 can be seen in various studies such as [4, 5]. Graphical illustration of our SEPADC model can be seen in Fig. 1. Let us denote the survival functions \(P_E,\ P_P,\ P_A,\ P_D:\left[ 0,\ \infty \right) \rightarrow [0,1]\) having the probability density functions \(p_{E},p_{P},p_{A},p_{D}:\left[ 0,\ \infty \right) \rightarrow \left[ 0,1\right] \) with the relation
where \(X=E,\ P,\ A,\ D.\) The survival function \(P_X\left( s\right) \) has the following properties [19].
The derivative of survival function is denoted by \(\dot{P}_X(s)\) and \(-\dot{P}_X(s)=p_X\left( s\right) \) yields the rate of removal from the state i at state age s. In mathematical epidemiology, exponential, delta, and gamma-distributed sojourn times are standard in practice [25], and some of the survival functions generated by these distributions are illustrated in Fig. 2.
In our modeling framework, susceptible persons become exposed if they encounter presymptomatic, asymptomatic, or symptomatic persons by considering bilinear incidence term \(\theta \left( t\right) \frac{S(t)}{N}\) with
where N is the total population, \(\beta \) is the constant transmission rate, \({\mu }_a\) is the reduction/extension factor of asymptomatic transmission, and \({\mu }_d\) is the reduction/extension factor of symptomatic transmission. The baseline transmission rate \(\beta \) is then varying according to the person’s stage since presymptomatic, asymptomatic, and symptomatic transmission rates may not be equivalent [4]. Thus, assuming S(0) as the initial number of susceptible persons, the following equation
is considered. Since \(\dot{S}\left( t\right) =-\theta \left( t\right) \frac{S\left( t\right) }{N}\), the number of exposed persons must satisfy the following equation by considering arbitrary survival function, \(P_E\left( s\right) \),
where \(\tilde{E}\left( t\right) \) represents the number of initially exposed and still exposed persons as
We assume that exposed persons continue their way by either becoming presymptomatic with probability \(\alpha \) or asymptomatic with probability \((1-\alpha ).\) Thus, since \(-\dot{P}_E(s)\) denotes the removal rate from the exposed stage, \(P\left( t\right) \) and \(A\left( t\right) \) should satisfy the following equations
where \(\tilde{P}(t)\) and \(\tilde{A}(t)\) represent the number of presymptomatic and asymptomatic persons who were either exposed or pre/asymptomatic at \(t=0\) defined by
Since asymptomatically recovered persons have no impact on reported cases, we omit the future of the asymptomatic persons after they are removed. Presymptomatic persons will be removed with the rate \(-\dot{P}_P(s)\) to become symptomatically infected and the equation of D(t) can be expressed as follows
where \(\tilde{D}(t)\) denotes the contributions of \(E\left( 0\right) ,\ P\left( 0\right) \) and \(D\left( 0\right) \) as follows
In our modeling framework, symptomatic persons become the reported ones after they complete their symptomatic periods with survival function \(P_D\left( s\right) \). Function \(P_D\left( s\right) \) can be realized as the probability of going to the hospital of a symptomatic person with age s. Thence, C(t) should satisfy the following equation
where \(\tilde{C}(t)\) represents the contributions of \(E\left( 0\right) ,\!\!\ P\left( 0\right) ,\) \(D\left( 0\right) \) and \(C\left( 0\right) \) as follows
Combining all these equations, we reach the following system of the Volterra integral equations representing our SEPADC model
where \(S\left( 0\right) ,\ E\left( 0\right) ,\ P\left( 0\right) ,\ A\left( 0\right) ,\ D\left( 0\right) ,C\left( 0\right) \le N\) are the given initial conditions of the model. The following subsection shows that the SEPADC model can be simplified with ordinary differential equations (ODEs) by considering exponential or delta distributions for sojourn times.
2.2 Special cases: exponential and delta distributions (SEPADC-e, SEPADC-d)
2.2.1 Exponentially distributed sojourn times, the SEPADC-e model
Here we reduce the Volterra integral equation system (15) into the system of ODEs by using \(P_i\left( s\right) =e^{-\frac{1}{T_i}s}\). Exponentially distributed sojourn times (EDST) with mean \(\frac{1}{T_i}\) and survival function \(P_i\left( s\right) =e^{-\frac{1}{T_i}s}\) for \(i=E,P,A,D\). The EDST assumption is the most common assumption for modeling COVID-19 [8, 10, 28]. The EDST assumption reduces system (15) into the following system of ODEs
where \(T_E,\ T_P,\ T_A\), and \(T_D\) stand for mean sojourn times of exposed, presymptomatic, asymptomatic, and symptomatic persons, respectively. Derivation of model (16) can be found in “Appendix A”. We call this model as the SEPADC-e model having the EDST assumption.
2.2.2 Delta-distributed sojourn times, the SEPADC-d model
The EDST assumptions fail when the sojourn times are distributed around their means. In such scenarios, a limit case with non-random or delta-distributed sojourn times (DDST) play a vital role by selecting the survival functions as [25]
where \(i=E,\ P,\ A,\ D\) and \(T_i\) are corresponding fixed sojourn times. The DDST assumption with survival functions (17) yields the following system of delay ODEs
where \(T_E,\ T_P,\ T_A\) and \(T_D\) are the fixed sojourn times of the corresponding states. The history of the number of infected persons is assumed to be zero, i.e., \(E\left( t\right) ,\ P\left( t\right) ,\ A\left( t\right) ,\ D\left( t\right) =0\) for \(t<0\) for simplicity. We call model (18) as SEPADC-d. The detailed derivation of the model (18) from the generalized model (15) can be found in “Appendix B”. Note that it is also possible to consider the Erlang distributed sojourn times and reduce the system (15) into \(4\left( k+1\right) +2\) dimensional ODEs where k is the shape parameter of the Erlang distribution [19]. For the sake of simplicity, we only derive the relations \(r-R_0\) in the presence of the Erlang distributions in the next section.
3 \(\varvec{r}\varvec{-}{\varvec{R}}_{\varvec{0}}\) relation for the SEPADC model
Early dynamics of the SEPADC model (15) with \(S\cong N\) provides a branching process as illustrated in Fig. 1 by considering separate roles of presymptomatic, asymptomatic, and symptomatic infectors. Thus, the SEPADC model (15) is compatible with earlier versions of branching models such as the SIR and SEIR [25]. In this context, it is inevitable to benefit from existing generalized formulae given in the literature [25, 27]
where r is the intrinsic growth rate of branching process, \(\beta (\tau )\) is the instantaneous function for infectivity at time \(\tau \), and \(\overline{A}(\tau )\) is the age of infection function. Equation (20) is also known as the Euler–Lotka equation [25, 27] and provides valuable insight over various types of renewal equations of compartmental models such as the SIR or SEIR models [27]. r denotes the intrinsic growth rate of a branching process and is equal to the growth rate of the system around the disease-free equilibrium (dfe), i.e., the largest eigenvalue of the linearized model around the dfe. Our SEPADC model (15) assumes constant infectivity rate \(\beta (\tau )=\beta \) and \(\overline{A}(\tau )\) have three contributions from \(P(t),\ A(t)\) and D(t) as follows
where \({\overline{A}}_X(\tau )\) denotes the age of infection function of the individual belonging to the stage X for \(X=P,A,D.\) Let us first formulate \({\overline{A}}_P(\tau )\) for general survival functions \(P_X\left( \tau \right) \) as follows
where \(p_E\left( x\right) \) denotes the probability density function (pdf) of the exposed stage. By using the relation given in Eq. (1), Eq. (22) can be written as
In a similar way, \({\overline{A}}_A(\tau )\) and \({\overline{A}}_D(\tau )\) can be stated as follows
Inserting Eqs. (23)–(25) into Eq. (20) and using \(\beta (\tau )=\beta \) lead to
Now, we should recall the Laplace transform of a function and the convolution integral as follows
Let us introduce the notation \(L\left\{ p_X(r)\right\} =L_X\left( r\right) \) and \(L\left\{ P_X(r)\right\} =L^X\left( r\right) .\) In the following proposition, we prove that \(L_{E+P+D}\left( r\right) \) can be expressed in terms of \(L_E\left( r\right) ,\) \(L_P\left( r\right) \) and \(L_D\left( r\right) \) to simplify Eq. (26).
Proposition 1
Prove that \(L_{E{+}P{+}D}\left( r\right) {=}\) \(\frac{1{-}L_E\left( r\right) L_P\left( r\right) L_D\left( r\right) }{r},\ L_{E{+}P}\left( r\right) {=}\frac{1-L_E\left( r\right) L_P\left( r\right) }{r}\) and \(L_{E+A}\left( r\right) =\frac{1-L_E\left( r\right) L_A\left( r\right) }{r}.\)
Proof
For simplicity, we only prove the first equality, and the remaining ones are special cases of the first one. According to the definition of \(p_{E+P+D}\left( r \right) ,\) Laplace transform of \(p_{E+P+D}\left( r \right) \) takes the following form
Let us define the following functions
Equation (29) can then be rewritten as
Since \(p_{E+P+D}\left( 0\right) =\int ^{\infty }_0{H\left( z\right) \textrm{d}z}=1,\) Eq. (31) becomes
or
We also need to see that \(L^E\left( r\right) =\frac{\left( 1-L_E\left( r\right) \right) }{r}\) by using the simple relation between \(p_E(r)\) and \(P_E(r)\) as follows
\(\square \)
By using Proposition 1 and Eq. (34) in Eq. (26), we reach the following general \(r-\beta \) relation
where
Let us denote the mean sojourn times at presymptomatic, asymptomatic, and symptomatic stages by \(T_P,\ T_A\), and \(T_D\), respectively. These values are given by
Thus, with the use of Eqs. (19) and (35), the general relation \(r-R_0\) of the SEPADC model (15) can be expressed as follows
Note that \({\left( R_0\right) }_{\text {SEPADC}}\) formula (38) generalizes many existing relations \(r-R_0\) proposed in the literature [25, 29]. For the sake of simplicity, let us denote again \({\left( R_0\right) }_{\text {SEPADC-e}}\,\ \ {\left( R_0\right) }_{\text {SEPADC-d}}\) and \({\left( R_0\right) }_{\text {SEPADC-er}}\) as the basic reproduction number formula in the presence of the exponential, delta, and Erlang distributed sojourn times, respectively. In “Appendix C”, we present some special formulae of \({\left( R_0\right) }_{\text {SEPADC-e}}\,\ {\left( R_0\right) }_{\text {SEPADC-d}}\) and \({\left( R_0\right) }_{\text {SEPADC-er}}\) derived from the general formula (38). The relation \(r-R_0\) given by (38) also permits different probability distributions for different stages. In the next section, we provide the most reliable pdf of sojourn times to estimate \(R_0\) values of 152 countries around the world.
4 Results
This section provides some estimates of local and global \(R_0\) values of the COVID-19 pandemic through our generalized formulation given in Eq. (38). Our theoretical results apply to the mathematical modeling of various infectious diseases; here, the hot topic is numerically addressed: \(R_0\) values of the COVID-19 pandemic. Note that the involvement of asymptomatic, presymptomatic, or symptomatic carriers in the dynamics does not affect our overall theoretical observations. As illustrated in “Appendix C”, various simplified models can be generated from the SEPADC model (15) and general relation \(r-R_0\) (38).
Finding \(R_0\) value of a country with Eq. (38) needs the following: using more reliable model parameters and sojourn time distributions, use of a reliable algorithm to find the growth rate of a country and the reported data of the country. The most reliable parameter values have been investigated and most have been taken from the study of [4], as presented in Table 1. Based on some clinical data and observations, we also consider the sojourn time distributions as the Erlang distributions with shape parameter \(k=4\) (see Table 1 and [4]). Additionally, we assume that the presymptomatic carriers are as infectious as the symptomatic carriers and the asymptomatic carriers are 50% less infectious with respect to the presymptomatic and symptomatic ones, i.e., \({\mu }_1=0.5,\ {\mu }_2=1\) [4]. According to a very detailed meta-analysis of [30], the presymptomatic ratio is taken as \(\alpha =0.75.\)
As realized from our theoretical analysis, observations of \(R_0\) values strictly depend on the growth rate \(\left( r\right) \) of the corresponding country. There exist various studies on the observation of r values of the COVID-19 pandemic [31,32,33]. Since declining from the exponential phases with non-pharmacological interventions occurs rapidly for most countries, finding the most reliable exponential phase of the given data is critical. In this study, we consider the following steps to obtain r values
-
1.
Consider the data pair \(\left( t,X\right) \) where \(t=[0,\ 1, \)\(\ldots ,N]\) is time vector (in day) and \(X=[x_0,\ x_1,\ldots \) , \(x_N]\) is cumulative cases of the country.
-
2.
Find all possible subvectors \(X_{ij}=[x_i,\ x_{i+1},\ldots , \) \( x_j]\) satisfying \(\left| j-i\right| \ge 9\) and \(x_j<10000.\)
-
3.
Obtain the slope of the linear fit of data \(\left( [i,\ i+1,\right. \) \(\left. \ldots ,j],ln\left( X_{ij}\right) \mathrm {\ }\right) \) as \(r_{ij}\) with corresponding \(R^2\) value denoted by \({RS}_{ij}.\)
-
4.
Determine r from the maximum possible \(r_{ij}\) satisfying \({RS}_{ij}>0.95.\)
This algorithm searches the possible series subvectors with at least ten elements less than or equal to 10000 and calculates the growth rate with the exponential fitting. Maximum of all possible growth rates satisfying \(R^2\mathrm {>0.95}\) is assigned as the desired growth rate. Taking the maximum is in line with the formal definition of the natural exponential phase: the natural exponential phase occurs when non-pharmacological or pharmacological interventions have not yet been implemented.
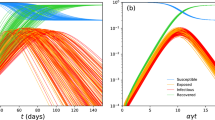
Daily confirmed cases of 214 countries had been obtained from the European Center for Disease Prevention and Control (ECDPC) [22]. Data from 152 out of 214 countries have given us representative intrinsic growth rates \(\left( r>0.05\right) \). The intrinsic growth rates of 34 out of 152 countries are presented in Table 2. As discussed earlier here, \({\left( R_0\right) }_{\text {SEPADC-er}}\) are calculated with the formula given in “Appendix C” and the parameter values given in Table 1. To observe the effect of the realistic sojourn time distributions, we also illustrate the values \({\left( R_0\right) }_{\text {SEPADC-e}}\) (exponential distribution of sojourn times) and \({\left( R_0\right) }_{\text {SEPADC-d}}\) (delta distribution of sojourn times) with the formulae in “Appendix C” and the mean parameter values in Table 1. \(r-{\left( R_0\right) }_{\text {SEPADC-er}},\) \(r-{\left( R_0\right) }_{\text {SEPADC-e}} \text { and } {r} {\left( R_0\right) }_{\text {SEPADC-d}}\mathrm {\ }\) curves are illustrated for 152 countries in Fig. 3. For these 34 out of 152 countries, \(r,\ {\beta }_{er},{\beta }_e,\ {\beta }_d,\) \({\left( R_0\right) }_{\text {SEPADC-er},\ \ }{\left( R_0\right) }_{\text {SEPADC-e}}\ \)and\(\ \ {\left( R_0\right) }_{\text {SEPADC-d}}\) values are presented in Table 2. \({\beta }_{er},\ {\beta }_e\ \)and\(\ {\beta }_d\) values refer to the naive transmission rates by considering the Erlang, exponential and delta distributions for sojourn times in Table 2.
According to Fig. 3 and Table 2, \({\left( R_0\right) }_{\text {SEPADC-e}}\ \)and \({\left( R_0\right) }_{\text {SEPADC-d}}\) provide optimistic and pessimistic \(R_0\) estimates for the COVID-19 outbreak depending on the growth rate of the given country. For relatively higher values of growth rates (\(r>0.158\), 89 out of 152 countries), \({\left( R_0\right) }_{\text {SEPADC-e}}\) underestimates \({\left( R_0\right) }_{\text {SEPADC-er}}\) and \({\left( R_0\right) }_{\text {SEPADC-d}}\ \) overestimates \({\left( R_0\right) }_{\text {SEPADC-er}}\)\(\left( {\left( R_0\right) }_{\text {SEPADC-e}}<{\left( R_0\right) }_{\text {SEPADC-er}}<{\left( R_0\right) }_{\text {SEPADC-d}}\right) \). On the other hand, for relatively low values of the growth rates \(\left( r<0.158\right) ,\) we observe the inequality \({\left( R_0\right) }_{\text {SEPADC-e}}>{\left( R_0\right) }_{\text {SEPADC-er}}>{\left( R_0\right) }_{\text {SEPADC-d}}\) and no considerable difference between any of the estimates. The threshold value \(r\cong 0.158\) depends on the existing parameters rather than the shape parameters (k) of the Erlang distributions. Since \(k=1\) yields the exponential distribution and \(k\rightarrow \infty \) yields the delta distribution, the more realistic Erlang estimate with \(k>1\) \({\left( R_0\right) }_{\text {SEPADC-er}}\) should always be between \({\left( R_0\right) }_{\text {SEPADC-e}}\ \)and\(\ {\left( R_0\right) }_{\text {SEPADC-d}}.\) Note that, if r is high enough, \({\left( R_0\right) }_{\text {SEPADC-d}}\) yields an upper bound among all possible \(R_0\) values and \({\left( R_0\right) }_{\text {SEPADC-e}}\) underestimates the actual \(R_0\) value.
According to Fig. 3, the sojourn time distributions play a significant role for the majority of the countries with higher r values. The benefit of our innovative formula is dependent on the early growth of the reported cases. Overall, we notice that the role of the pdf of sojourn times should be considered in the COVID-19 pandemic. On the other hand, if the early increase in reported cases is not significant (for a country or another pandemic), then the choice in pdf of sojourn times is negligible, and the SEPADC-e model (16) offers a computational advantage over the SEPADC model (15).

The basic reproduction numbers \({\left( R_0\right) }_{\text {SEPADC-er}}\), \({\left( R_0\right) }_{\text {SEPADC-d}}\) and \({\left( R_0\right) }_{\text {SEPADC-e}}\) are calculated for 152 countries around the world with \(r-R_0\) formulae given in “Appendix C”. The curves represent \(r-{\left( R_0\right) }_{\text {SEPADC-er}}\), \(r-{\left( R_0\right) }_{\text {SEPADC-e}}\) and \(r-{\left( R_0\right) }_{\text {SEPADC-d}}\) relations and the circles on the curves represent \(R_0\) values of a country having the corresponding growth rate

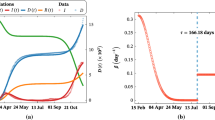
Smoothed (by taking 7-day moving means) data of cumulative cases (C(t)) versus daily patients \((\textrm{d}C(t)/\textrm{d}t)\) are obtained for 55 European countries (ECDPC dataset). The dashed lines denote the smoothed and normalized (by dividing the population of each country) \(\overline{C}\left( t\right) \) versus \(d\overline{C}\left( t\right) /\textrm{d}t\) relation. The global exponential phase must obey the relation \({\textrm{log} \left( \frac{\textrm{d}\overline{C}\left( t\right) }{\textrm{d}t}\right) \ }={\textrm{log} \left( \overline{C}\left( t\right) \right) \ }+\textrm{log}\mathrm {}(r)\) where r is the intrinsic growth rate. r value is calculated by fitting the sub-data (\(\overline{C}\left( t\right) \) versus \(d\overline{C}\left( t\right) /\textrm{d}t\)) of 55 countries that are obtained with our growth rate algorithm. The intercept of the black line gives us our global estimate \(r=0.254\)
We aim to estimate a global basic reproduction number using the parameter values given in Table 1. Determining a global intrinsic growth rate is vital for this process [22]. We follow the methodology provided by [22] by considering C(t) versus \(\textrm{d}C(t)/\textrm{d}t\) relation in the same phase space. First of all, to increase the reliability of the data, we have also smoothed C(t) and \(\textrm{d}C(t)/\textrm{d}t\) values by taking 7-day moving means \((C^S\left( t\right) =movmean\left( C\left( t\right) ,7\right) \) and \(\textrm{d}C^S(t)/\textrm{d}t=movmean(\textrm{d}C(t)/\textrm{d}t,7))\). To create a global perspective, the data is also normalized with the population of the countries, i.e., \(\overline{C}\left( t\right) =C^S\left( t\right) /N\) and \(\frac{\textrm{d}\overline{C}\left( t\right) }{\textrm{d}t}=\frac{1}{N}\frac{\textrm{d}C^S\left( t\right) }{\textrm{d}t}\). Since the exponential phase of an outbreak should obey the relation \(\frac{\textrm{d}\overline{C}\left( t\right) }{\textrm{d}t}=r\overline{C}\left( t\right) ,\) we get the line equation \({\textrm{log} \left( \frac{\textrm{d}\overline{C}\left( t\right) }{\textrm{d}t}\right) \ }={\textrm{log} \left( \overline{C}\left( t\right) \right) \ }+{\textrm{log} \left( r\right) \ }.\) In Fig. 4, \({\textrm{log} \left( \overline{C}\left( t\right) \right) \ }\) versus \({\textrm{log} \left( \frac{\textrm{d}\overline{C}\left( t\right) }{\textrm{d}t}\right) \ }\) corresponding to the first 100 days of the pandemic are illustrated through the dashed lines for 55 European countries [22]. Linear regions obey the exponential phase, and the remaining areas show a decline from the exponential phase. The global black dashed line is obtained using the only data in the exponential phases according to our growth rate algorithm. Thus, we find the global intrinsic growth rate as \(r=0.254.\) By considering the parameter values given in Table 1 (Erlang distributions of the sojourn times), we estimate the global convergence \({\left( R_0\right) }_{\text {SEPADC-er}}=R_0=4.58.\) Additionally, according to the exponential and delta distributions, we estimate \({\left( R_0\right) }_{\text {SEPADC-e}}=4.21\) and \({\left( R_0\right) }_{\text {SEPADC-d}}=4.88.\) Our global estimate \(R_0=4.58\) is in line with previous estimates such as \(R_0=4.5\) [22], \(R_0=4.1\) [34] and \(R_0=4.9\) [35].

Effects of the model parameters \(T_E\), \(T_P\), \(T_A\), \(T_D\), \(k_E\), \(k_P\), \(k_A\), \(k_D\), \(\alpha \), \(\mu _a\) and \(\mu _d\) on the \(R_0\) predictions by considering the \(\text {SEPADC-e}\), \(\text {SEPADC-er}\) and \(\text {SEPADC-d}\) models with \(r=0.254\)
Here we have shown how our theoretical formulations work with real data under some prior assumptions. The assumed parameter values such \(\alpha = 0.75\), \(\mu _a=0.5\), and \(\mu _d=1\) can vary between countries. To make more rigorous predictions, local estimations of such parameter values should be considered for each country. Nevertheless, we can see how the changing values of such parameter values affect the \(R_0\) predictions. By using the parameter values given in Table 1 and \(r=0.254\), we have illustrated the effect of changing values of each parameter \(T_E\), \(T_P\), \(T_A\), \(T_D\), \(k_E\), \(k_P\), \(k_A\), \(k_D\), \(\alpha \), \(\mu _a\) and \(\mu _d\) on the \(R_0\) predictions in Fig. 5. The results are calculated through \((R_0)_{\text {SEPADC}}\) formula (38) for the \(\text {SEPADC-e}\), \(\text {SEPADC-er}\) and \(\text {SEPADC-d}\) models. Increasing most of the parameters (by fixing intrinsic growth rate \(r=0.254\)), except the fraction of presymptomatic infections (\(\alpha \)), increases \(R_0\) values. \(R_0\) estimations of the \(\text {SEPADC-e}\) model is more sensitive the asymptomatic infections than both \(\text {SEPADC-er}\) and \(\text {SEPADC-d}\) models. Additionally, increasing the values of Erlang distributions’ shape parameters \(k_E\), \(k_P\), \(k_A\), \(k_D\) (from exponential distribution to delta distribution) yields asymptotically increasing pattern in \(R_0\) curve. The \(k-R_0\) curve shows how the \(\text {SEPADC-d}\) and \(\text {SEPADC-e}\) models overestimate and underestimate the \(R_0\) values, respectively. Additionally, Fig. 5 implies that the same exponential phase (\(r=0.254\)) can be approximated with different scenarios in model assumptions. Thus, increasing the reliability of \(R_0\) predictions highly depends on the prior information on such model parameters. Some prior clinical data can help in determining most of the parameters of our SEPADC model.
We observe how different sojourn time distributions affect the behavior of stage functions throughout the pandemic progress in Fig. 6 when the same intrinsic growth rate is assumed for all models. We have shown that the \(\text {SEPADC-e}\), \(\text {SEPADC-er}\), and \(\text {SEPADC-d}\) models require different \(\beta \) and \(R_0\) values to catch the same intrinsic growth rate. Figure 6 shows that different sojourn time distributions yield diverse epidemic curves even if they yield the same r values in the exponential phase. The \(\text {SEPADC-e}\) model leads to wider epidemic curves with less peak value than both the \(\text {SEPADC-er}\) and \(\text {SEPADC-d}\) models. On the other hand, \(\text {SEPADC-d}\) model yields narrower epidemic curves with higher peak values. In line with the skewness of the epidemic curves, the earliest peak time is observed for the \(\text {SEPADC-e}\) model. The SEPADC model can yield less skewed to highly skewed epidemic curves by considering various sojourn time distributions having the same expectations. Observing the epidemic curves of the countries may thus provide some insight into the selection of the sojourn time pdfs.

Epidemic curves of the \({\text {SEPADC-e}}\), \({\text {SEPADC-er}}\) and \({\text {SEPADC-d}}\) models by considering the parameter values given in Table 1 and \(r=0.399\) (the intrinsic growth rate estimated for Turkey)
5 Discussions and conclusions
In this study, the SEPADC model has been derived with arbitrary sojourn time distributions represented by the system of the Volterra integral equations. It has been proven that the SEPADC model generalizes the well-known exponential and delta-distributed compartmental models by taking into account the corresponding survival functions in the model. The SEPADC model consists of three infectious stages: presymptomatic, asymptomatic, and symptomatic. This assumption is in line with the existence of the separate roles of these stages for the COVID-19 pandemic [4]. Separate roles of these stages are due to the two known facts: they may have different survival functions and infectivity potentials. The SEPADC model includes both effects, and it is more likely to represent the expected dynamics than the existing SEIR [36] or SIR [22] models. Additionally, the SPC, SEPC, and SEPAC models are reduced from the SEPADC model depending on the corresponding infectious diseases and the importance of the separate roles of the exposed, presymptomatic, asymptomatic, and symptomatic stages. We have extensively reduced the SEPADC model (15) into the system of ODEs by considering the widely used exponential and delta distributions for sojourn times.
\(r-R_0\) relation of an outbreak determines the future dynamics and has great importance in mathematical epidemiology [23,24,25]. With the help of the well-known Euler–Lotka equation (20), we have derived a generalized relation \(r-R_0\) (38) for the SEPADC model by taking arbitrary sojourn time distributions into account. It has been here shown that by taking the Laplace transforms of the probability distribution functions of each stage, one can easily express \(R_0\) in terms of r. Note that in the absence of analytic expressions for the Laplace transforms, it is more suitable to use some quadrature formulas for the corresponding improper integrals. We have shown that some of the existing formulas in the literature [25] can be reduced from our formula (38). Since the extensive acceptance of the exponential, delta, and Erlang distributions for sojourn times, we have formulated \(r-R_0\) according to the distributions and model assumptions.
In the last part of this study, we have used our theoretical observations to evaluate the \({R}_0\) values of 152 countries around the world. A growth rate algorithm has been proposed to calculate the intrinsic growth rates from given data. We have shown that exponential and delta distributions yield optimistic and pessimistic estimates with respect to the most reliable Erlang distribution assumption [4]. According to our observations, higher values of intrinsic growth rates yield optimistic \({R}_0\) estimations of the exponentially distributed compartmental models. Additionally, the global convergence \({R}_0 =4.58 \), which is in line with previous estimates [22, 34, 35], has been obtained through our assumptions on the SEPADC model and global intrinsic growth rate estimate \(r=0.254.\)
To capture both early and entire dynamics, separate roles for presymptomatic, asymptomatic, and symptomatic infections yield more model parameters than the simple SIR model. Using clinical data to predict some parameters such as \(\alpha \), \(\mu _a\) or \(\mu _d\) as well as the shape of sojourn time pdfs, can reduce parameter uncertainty and increase the biological relevance of the \(\beta \) and \(R_0\) estimations. To increase the biological relevance of the parameters, we recommend using this strategy before fitting time series data from a certain country. If the individual roles of different infection phases are uncertain, the SEPADC model can be reduced to more simple models like the SIR or SEIR models. Furthermore, if epidemic curves follow less skewed patterns and there is no clinical data on the sojourn time pdfs, a simpler ODE model (16) rather than the general Volterra integral equation model (38) may be assumed to reduce computing complexity.
Availability of data and materials
Data and materials can be provided from the authors if required.
Code availability
The program codes can be provided from the authors if required.
References
Fattorini, D., Regoli, F.: Role of the chronic air pollution levels in the COVID-19 outbreak risk in Italy. Environ. Pollut. 264, 114732 (2020)
Liu, J., Zhou, J., Yao, J., et al.: Impact of meteorological factors on the COVID-19 transmission: a multi-city study in China. Sci. Total Environ. 726, 138513 (2020)
Zhao, S., Tang, B., Musa, S.S., et al.: Estimating the generation interval and inferring the latent period of COVID-19 from the contact tracing data. Epidemics 36, 100482 (2021)
Davies, N.G., Kucharski, A.J., Eggo, R.M., Gimma, A., Edmunds, W.J.: Effects of non-pharmaceutical interventions on COVID-19 cases, deaths, and demand for hospital services in the UK: a modelling study. Lancet Public Health 5, e375–e385 (2020)
Subramanian, R., He, Q., Pascual, M.: Quantifying asymptomatic infection and transmission of COVID-19 in New York City using observed cases, serology, and testing capacity. Proc. Natl. Acad. Sci. U.S.A. 118, e2019716118 (2021)
Mahmood, M., Ilyas, N.U., Khan, M.F., Hasrat, M.N., Richwagen, N.: Transmission frequency of COVID-19 through pre-symptomatic and asymptomatic patients in AJK: a report of 201 cases. Virol. J. 18, 1–8 (2021)
Rai, B., Shukla, A., Dwivedi, L.K.: Incubation period for COVID-19: a systematic review and meta-analysis. J. Public Health (2021). https://doi.org/10.1007/s10389-021-01478-1
Li, R., Pei, S., Chen, B., et al.: Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV-2). Science 368, 489–493 (2020)
Yang, W., Zhang, D., Peng, L., Zhuge, C., Hong, L.: Rational evaluation of various epidemic models based on the COVID-19 data of China. Epidemics 37, 100501 (2021)
Giordano, G., Blanchini, F., Bruno, R., et al.: Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat. Med. 26, 855–860 (2020)
Ferretti, L., Wymant, C., Kendall, M. et al.: Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing. Science 368(6491) (2020)
Kucharski, A.J., Russell, T.W., Diamond, C., et al.: Early dynamics of transmission and control of COVID-19: a mathematical modelling study. Lancet Infect. Dis. 20, 553–558 (2020)
Hellewell, J., Abbott, S., Gimma, A.: Feasibility of controlling COVID-19 outbreaks by isolation of cases and contacts. Lancet Glob. Health 8(4), e488–e496 (2020)
Kissler, S.M., Tedijanto, C., Goldstein, E., Grad, Y.H., Lipsitch, M.: Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period. Science 368, 860–868 (2020)
Greenhalgh, S., Rozins, C.: A generalized differential equation compartmental model of infectious disease transmission. Infect. Dis. Model. 6, 1073–1091 (2021)
Vergu, E., Busson, H., Ezanno, P.: Impact of the infection period distribution on the epidemic spread in a metapopulation model. PLoS ONE 5, e9371 (2010)
Champredon, D., Dushoff, J., Earn, D.J.D.: Equivalence of the Erlang-distributed SEIR epidemic model and the renewal equation. SIAM J. Appl. Math. 78, 3258–3278 (2018)
Porter, A.T., Oleson, J.J.: A path-specific SEIR model for use with general latent and infectious time distributions. Biometrics 69, 101–108 (2013)
Feng, Z., Xu, D., Zhao, H.: Epidemiological models with non-exponentially distributed disease stages and applications to disease control. Bull. Math. Biol. 69, 1511–1536 (2007)
Safi, M.A., Gumel, A.B.: Qualitative study of a quarantine/isolation model with multiple disease stages. Appl. Math. Comput. 218, 1941–1961 (2011)
Yang, Y., Xu, D., Feng, Z.: Analysis of a model with multiple infectious stages and arbitrarily distributed stage durations. Math. Model. Nat. Phenom. 3, 180–193 (2008)
Katul, G.G., Mrad, A., Bonetti, S., Manoli, G., Parolari, A.J.: Global convergence of COVID-19 basic reproduction number and estimation from early-time SIR dynamics. PLoS ONE 15, e0239800 (2020)
Wallinga, J., Lipsitch, M.: How generation intervals shape the relationship between growth rates and reproductive numbers. Proc. R. Soc. B Biol. Sci. 274, 599–604 (2007)
Roberts, M.G., Heesterbeek, J.A.P.: Model-consistent estimation of the basic reproduction number from the incidence of an emerging infection. J. Math. Biol. 55, 803–816 (2007)
Yan, P.: Separate roles of the latent and infectious periods in sha** the relation between the basic reproduction number and the intrinsic growth rate of infectious disease outbreaks. J. Theor. Biol. 251, 238–252 (2008)
Park, S.W., Cornforth, D.M., Dushoff, J., Weitz, J.S.: The time scale of asymptomatic transmission affects estimates of epidemic potential in the COVID-19 outbreak. Epidemics 31, 100392 (2020)
Diekmann, O., Heesterbeek, J.A.P.: Mathematical Epidemiology of Infectious Diseases: Model Building, Analysis and Interpretation. Wiley, New York (2000)
Serhani, M., Labbardi, H.: Mathematical modeling of COVID-19 spreading with asymptomatic infected and interacting peoples. J. Appl. Math. Comput. 66, 1–20 (2021)
Yan, P., Feng, Z.: Variability order of the latent and the infectious periods in a deterministic SEIR epidemic model and evaluation of control effectiveness. Math. Biosci. 224, 43–52 (2010)
Alene, M., Yismaw, L., Assemie, M.A., et al.: Magnitude of asymptomatic COVID-19 cases throughout the course of infection: a systematic review and meta-analysis. PLoS ONE 16, e0249090 (2021)
Kasilingam, D., Puvaneswaran, S., Prabhakaran, S., et al.: Exploring the growth of COVID-19 cases using exponential modelling across 42 countries and predicting signs of early containment using machine learning. Transbound. Emerg. Dis. 68, 1001–1018 (2021)
Musa, S.S., Zhao, S., Wang, M.H., et al.: Estimation of exponential growth rate and basic reproduction number of the coronavirus disease 2019 (COVID-19) in Africa. Infect. Dis. Poverty 9, 1–6 (2020)
Schonger, M., Sele, D.: How to better communicate the exponential growth of infectious diseases. PLoS ONE 15, e0242839 (2020)
Cao, Z., Zhang, Q., Lu, X., et al.: Estimating the effective reproduction number of the 2019-nCoV in China. MedRxiv (2020). https://doi.org/10.1101/2020.01.27.20018952
Roques, L., Klein, E., Papaix, J., Soubeyrand, S.: Mechanistic-statistical SIR modelling for early estimation of the actual number of cases and mortality rate from COVID-19. Biology 9(5), 97 (2020)
Saikia, D., Bora, K., Bora, M.P.: COVID-19 outbreak in India: an SEIR model-based analysis. Nonlinear Dyn. 104, 4727–4751 (2021)
Acknowledgements
This work was supported by TUBITAK, 2232 - International Fellowship for Outstanding Researchers, project number 11C244. All the results are in sole responsibility of the authors.
Funding
This work was supported by TUBITAK, 2232 - International Fellowship for Outstanding Researchers, Project Number 11C244. All the results are in sole responsibility of the authors.
Author information
Authors and Affiliations
Contributions
HT: conceptualization; data curation; formal analysis; investigation; methodology; resources; software; validation; visualization; writing—original draft; writing—review and editing. MS: supervision, writing—review and editing. ESK: supervision, writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
A: Exponentially distributed SEPADC model
In this part, we reduce the SEPADC model into the SEPADC-e model by assuming exponentially distributed sojourn times \(P_i\left( s\right) =e^{-\frac{1}{T_i}s}\) for \(i=E,P,A,D.\) It is easy to see that the differentiation of S(t) for t in the SEPADC model yields the first equation of SEPADC-e model (16). Inserting \(P_E\left( s\right) =e^{-\frac{1}{T_E}s}\) into the equation of E(t) and taking time derivative lead to
Observing
\(-\frac{1}{T_E}\int ^t_0{\theta \left( s\right) \frac{S\left( s\right) }{N}}e^{-\frac{1}{T_E}\left( t-s\right) }\textrm{d}\) \( =-\frac{1}{T_E}\left( E\left( t\right) -E\left( 0\right) e^{-\frac{1}{T_E}t}\right) \) and writing into Eq. (39) yields
Taking derivative of \(P\left( t\right) \) in SEPADC model (15) gives us
Use of the following equalities
and
Equation (41) becomes
In a similar way, equations of \(\frac{\textrm{d}A}{\textrm{d}t},\ \frac{\textrm{d}D}{\textrm{d}t}\) and \(\frac{\textrm{d}C}{\textrm{d}t}\) can be reduced from the SEPADC model (15) as described in model (16).
B: Delta-distributed SEPADC model
In this section, we briefly explain the derivation of the SEPADC-d model (18) from the model (15) by considering delta-distributed sojourn times having the following survival functions
where \(i=E,P,A,D\) and \(T_i\) denotes fixed sojourn time of the corresponding stage. We should first realize that \(P_i\left( s\right) \) can be written in terms of the piecewise Heaviside functions as follows
and we have the following remarkable equation
where \(\delta \) is the Dirac-delta function. The following property of the Dirac-delta functions will be heavily used in the derivation
where \(\varepsilon >0\) is arbitrary. For the simplicity, let us first define \(f(s)=\theta \left( s\right) \frac{S\left( s\right) }{N}\) and consider the history of state functions as follows

Equation of \(E\left( t\right) \) with survival function (45) becomes

Inserting \(f(t-s)=-\dot{S}(t-s)\) and evaluating integrals lead to
Taking time derivative of Eq. (50) and considering the condition (49) yield
According to model (15), equation of P(t) takes the following form
where \(\hat{P}(t)=\alpha \int ^t_0\int ^{\tau }_0{f(s)\left[ -\dot{P_E}\left( \tau -s\right) \right] P_P(t-\tau )}\) \(\textrm{d}s\textrm{d}\tau .\) Let us first rewrite \(\hat{P}(t)\) as
Since we consider zero histories for \(E\left( t\right) ,\ P\left( t\right) ,\ A\left( t\right) \) and \(\ D\left( t\right) \), we continue the analysis by considering \(\mathrm {t>}{\textrm{T}}_{\textrm{E}}\mathrm {+}{\textrm{T}}_{\textrm{P}}.\) According to Eqs. (47) and (48), Eq. (54) becomes
and the change of variables yield
Since \(f=-\dot{S},\) Eq. (56) gives us
According to the survival functions given in Eqs. (47) and (9), \(\frac{\textrm{d}\tilde{P}(t)}{\textrm{d}t}=0\) is obvious. Thus, taking the time derivative of Eq. (53) yields the equation of \(P\left( t\right) \) as follows
Derivation of \(\frac{\textrm{d}A}{\textrm{d}t}\) for model (18) is very similar to the derivation of \(\frac{\textrm{d}P}{\textrm{d}t}\) stated above. Let us reduce the equation of D(t) that occurred in the model (15). D(t) can be written in the following form
where
or equivalently
With the use of Eqs. (47) and (48) for integrals with respect to s and \(\tau \), one after another in Eq. (60) yields
Since \(f=-\dot{S}\), we get
Inserting Eq. (62) into (59) and taking time derivative lead to the following desired equation
where \(\frac{\textrm{d}\tilde{D}(t)}{\textrm{d}t}=0\) according to Eqs. (47) and (12). Derivation of \(\frac{\textrm{d}C}{\textrm{d}t}\) that occurred in the model (18) is like the derivation of \(\frac{\textrm{d}D}{\textrm{d}t}\), and we avoid repetitive analysis.
C: Some special formulae
Here we propose some special formulas reduced from our general \(r-R_0\) equation (38) in the presence of the exponential, delta, and Erlang distributions.
1.1 C.1: Exponential distribution
By considering \(p_i\left( s\right) =\frac{1}{T_i}e^{-\frac{1}{T_i}s}\), we can derive the following special formulations:
Case 1: If \(T_E,\ T_A,\ T_D\rightarrow 0\), then we get the SPC (SIR) model with the following \(r-R_0\) formula (see also [25])
Case 2: If \(\ T_A,\ T_D\rightarrow 0,\) then we get the SEPC (SEIR) model with the following \(r-R_0\) formula (see also [25])
Case 3: If \(T_D\rightarrow 0,\) then we get the SEPAC model with following \(r-R_0\) formula
with
Case 4: The SEPADC model has the following \(r-R_0\) formula
with
1.2 C.2: Delta distribution
If \(p_i\left( s\right) =\delta \left( s-T_i\right) ,\) one obtains the following special cases:
Case 1: If \(T_E,\ T_A,\ T_D\rightarrow 0,\) then the SPC (SIR) model has the following \(r-R_0\) formula (see also [25])
Case 2: If \(\ T_A,\ T_D\rightarrow 0,\) then the SEPC (SEIR) model has the following \(r-R_0\) formula (see also [25])
Case 3: If \(T_D\rightarrow 0,\) then the SEPAC model has the following \(r-R_0\) formula
with
Case 4: The SEPADC model has the following \(r-R_0\) formula
with
1.3 C.3: Erlang distribution
If \(p_i\left( s\right) =\frac{x^{k_i-1}e^{-\left( \frac{k_i}{T_i}s\right) }}{ \Gamma (k_i){\left( \frac{T_i}{k_i}\right) }^{k_i}}\) with the shape parameter \(k_i\in Z^+\)and \(T_i\) is the mean sojourn time, i.e., \(E\left[ p_i\left( s\right) \right] =T_i\), the following special cases can be expressed:
Case 1: If \(T_E,\ T_A,\ T_D\rightarrow 0,\) then the SPC (SIR) model yields the following \(r-R_0\) formula (see also [25])
Case 2: If \(\ T_A,\ T_D\rightarrow 0,\) then the SEPC (SEIR) model yields the following \(r-R_0\) formula (see also [25])
Case 3: If \(T_D\rightarrow 0,\) then the SEPAC model yields the following \(r-R_0\) formula
with
Case 4: The SEPADC model yields the following \(r-R_0\) formula
with
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tunc, H., Sari, M. & Kotil, S.E. Effect of sojourn time distributions on the early dynamics of COVID-19 outbreak. Nonlinear Dyn 111, 11685–11702 (2023). https://doi.org/10.1007/s11071-023-08400-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-023-08400-2