
Abstract
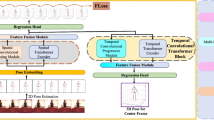
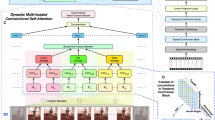
In this paper, we present an innovative framework for 2D-to-3D human pose estimation from video, harnessing the power of multi-scale multi-level spatial-temporal features. Our framework comprises three integral branch networks: A temporal feature core network, dedicated to extracting temporal coherence among frames, enabling a comprehensive understanding of dynamic human motion. A multi-scale feature branch network, equipped with multiple receptive fields of varying sizes, facilitating the extraction of multi-scale features, thus capturing fine-grained details across different scales. A multi-level feature branch network, tasked with extracting features from layers at various depths within the architecture, providing a nuanced understanding of pose-related information. Within our framework, these diverse features are seamlessly integrated to encapsulate intricate spatial and temporal relationships inherent to the human body. This integration effectively addresses challenges such as depth ambiguity and self-occlusions, culminating in substantially improved accuracy in pose estimation.Extensive experiments on Human3.6M and HumanEva-I show that our framework achieves competitive performance on 2D-to-3D human pose estimation in video. Code is available at: https://github.com/fll123/3Dhumanpose.











Similar content being viewed by others

Availability of data and materials
The data and materials that support the findings of this study are available from the corresponding author upon reasonable request. The Human3.6m and HumanEva datasets were used in this study. The human3.6m dataset can be obtained from the official website: http://vision.imar.ro/human3.6m/description.php. The humaneva dataset is available for non-commercial research purposes and can be downloaded from: http://humaneva.is.tue.mpg.de/.
Code Availability
Code is available at: https://github.com/fll123/3Dhumanpose.
References
Li Y, Ji B, Shi X, Zhang J, Kang B, Wang L (2020) TEA: Temporal excitation and aggregation for action recognition. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 906–915. https://doi.org/10.1109/CVPR42600.2020.00099
**: Using depth cameras for dense 3D modeling of indoor environments. In: Experimental robotics: The 12th international symposium on experimental robotics (ISER), pp 477–491. https://doi.org/10.1007/978-3-642-28572-1_33
Neverova N, Wolf C, Taylor GW, Nebout F (2014) Multiscale deep learning for gesture detection and localization. In: European conference on computer vision workshops (ECCV), pp 474–490. https://doi.org/10.1007/978-3-319-16178-5_33
Toshev A, Szegedy C (2014) Deeppose: Human pose estimation via deep neural networks. In: Conference on computer vision and pattern recognition (CVPR), pp 1653–1660. https://doi.org/10.1109/cvpr.2014.214
Nie X, Feng J, Zhang J, Yan S (2019) Single-stage multi-person pose machines. In: IEEE/CVF international conference on computer vision (ICCV), pp 6950–6959. https://doi.org/10.1109/ICCV.2019.00705
Wang Z, Nie X, Qu X, Chen Y, Liu S (2022) Distribution-aware single-stage models for multi-person 3D pose estimation. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 13086–13095. https://doi.org/10.1109/CVPR52688.2022.01275
Wu Q, Xu G, Li M, Chen L, Zhang X, **e J (2018) Human pose estimation method based on single depth image. IET Comput Vis 12(6):919–924. https://doi.org/10.1049/iet-cvi.2017.0536
Martinez J, Hossain R, Romero J, Little JJ (2017) A simple yet effective baseline for 3D human pose estimation. In: IEEE international conference on computer vision (ICCV), pp 2659–2668. https://doi.org/10.1109/ICCV.2017.288
Hossain MRI, Little JJ (2018) Exploiting temporal information for 3D human pose estimation. In: Proceedings of the european conference on computer vision (ECCV), pp 68–84. https://doi.org/10.1007/978-3-030-01249-6_5
Wang L, Chen Y, Guo Z, Qian K, Lin M, Li H, Ren JS (2019) Generalizing monocular 3D human pose estimation in the wild. In: IEEE/CVF international conference on computer vision workshop (ICCVW), pp 4024–4033. https://doi.org/10.1109/ICCVW.2019.00497
Pavllo D, Feichtenhofer C, Grangier D, Auli M (2019) 3D human pose estimation in video with temporal convolutions and semi-supervised training. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 7745–7754. https://doi.org/10.1109/CVPR.2019.00794
Pavlakos G, Zhu L, Zhou X, Daniilidis K (2018) Learning to estimate 3D human pose and shape from a single color image. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 459–468. https://doi.org/10.1109/CVPR.2018.00055
Pavlakos G, Zhou X, Derpanis KG, Daniilidis K (2017) Coarse-to-fine volumetric prediction for single-image 3D human pose. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 1263–1272. https://doi.org/10.1109/CVPR.2017.139
Lee K, Lee I, Lee S (2018) Propagating LSTM: 3D pose estimation based on joint interdependency. In: Proceedings of the european conference on computer vision (ECCV), pp 123–141. https://doi.org/10.1007/978-3-030-01234-2_8
Zhao L, Peng X, Tian Y, Kapadia M, Metaxas DN (2019) Semantic graph convolutional networks for 3D human pose regression. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 3420–3430. https://doi.org/10.1109/CVPR.2019.00354
Sifre L, Mallat S (2014) Rigid-motion scattering for texture classification. Comput Sci 3559:501–515. https://doi.org/10.48550/ar**v.1403.1687
Rangnekar A, Mokashi N, Ientilucci EJ, Kanan C, Hoffman MJ (2020) AeroRIT: A new scene for hyperspectral image analysis. IEEE Trans Geosci Remote Sens 58(11):8116–8124. https://doi.org/10.1109/tgrs.2020.2987199
Hara K, Kataoka H, Satoh Y (2018) Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 6546–6555. https://doi.org/10.1109/CVPR.2018.00685
Yan S, **ong Y, Lin D (2018) Spatial temporal graph convolutional networks for skeleton-based action recognition. 32(1). https://doi.org/10.48550/ar**v.1801.07455
Tome D, Russell C, Agapito L (2017) Lifting from the deep: Convolutional 3D pose estimation from a single image. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 5689–5698. https://doi.org/10.1109/CVPR.2017.603
Yang S, Wen J, Fan J (2022) Ghost shuffle lightweight pose network with effective feature representation and learning for human pose estimation. IET Comput Vis 16(6):525–540. https://doi.org/10.1049/cvi2.12110
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: IEEE conference on computer vision and pattern recognition (CVPR), pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L-C (2018) MobileNetV2: Inverted residuals and linear bottlenecks. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp. 4510–4520. https://doi.org/10.1109/CVPR.2018.00474
Li S, Chan AB (2015) 3D human pose estimation from monocular images with deep convolutional neural network. In: Asian conference on computer vision (ACCV), pp 332–347. https://doi.org/10.1007/978-3-319-16808-1_23
Glorot X, Bordes A, Bengio Y (2011) Deep sparse rectifier neural networks. In: Proceedings of the fourteenth international conference on artificial intelligence and statistics (AISTATS), vol 15, pp 315–323. https://proceedings.mlr.press/v15/glorot11a.html
Zhao Q, Sheng T, Wang Y, Tang Z, Chen Y, Cai L, Ling H (2019) M2Det: A single-shot object detector based on multi-level feature pyramid network. Proceedings of the AAAI conference on artificial intelligence. 33:9259–9266. https://doi.org/10.1609/aaai.v33i01.33019259
Xu T, Takano W (2021) Graph stacked hourglass networks for 3D human pose estimation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp 16100–16109. https://doi.org/10.1109/CVPR46437.2021.01584
Wu Y, Gao J (2021) Multi-scale spatial-temporal transformer for 3D human pose estimation. In: 5th International conference on vision, image and signal processing (ICVISP), pp 242–247. https://doi.org/10.1109/ICVISP54630.2021.00051
Newell A, Yang K, Deng J (2016) Stacked hourglass networks for human pose estimation. In: Proceedings of the european conference on computer vision (ECCV), pp 483–499. https://doi.org/10.48550/ar**v.1603.06937
Ionescu C, Papava D, Olaru V, Sminchisescu C (2014) Human3.6M?: Large scale datasets and predictive methods for 3D human sensing in natural environments. IEEE Trans Pattern Anal Mach Intell 36(7):1325–1339. https://doi.org/10.1109/TPAMI.2013.248
Sigal L, Balan AO, Black MJ (2010) Humaneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. Int J Comput Vis 87:4–27. https://doi.org/10.1007/s11263-009-0273-6
Liu R, Shen J, Wang H, Chen C, Cheung S-c, Asari V (2020) Attention mechanism exploits temporal contexts: Real-time 3D human pose reconstruction. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 5063–5072. https://doi.org/10.1109/CVPR42600.2020.00511
Zou Z, Tang W (2021) Modulated graph convolutional network for 3D human pose estimation. In: IEEE/CVF international conference on computer vision (ICCV), pp 11457–11467. https://doi.org/10.1109/ICCV48922.2021.01128
Chen Y, Wang Z, Peng Y, Zhang Z, Yu G, Sun J (2018) Cascaded pyramid network for multi-person pose estimation. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 7103–7112. https://doi.org/10.1109/CVPR.2018.00742
He K, Gkioxari G, Dollár P, Girshick R (2017) Mask R-CNN. In: IEEE international conference on computer vision (ICCV), pp 2980–2988. https://doi.org/10.1109/ICCV.2017.322
Tekin B, Márquez-Neila P, Salzmann M, Fua P (2017) Learning to fuse 2D and 3D image cues for monocular body pose estimation. In: IEEE international conference on computer vision (ICCV), pp 3961–3970. https://doi.org/10.1109/ICCV.2017.425
Pavlakos G, Zhou X, Daniilidis K (2018) Ordinal depth supervision for 3D human pose estimation. In: IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 7307–7316. https://doi.org/10.1109/CVPR.2018.00763
Acknowledgements
This work was jointly supported by Fujian University-Industry Cooperation Project of Research and Industrialization of Machine Vision driven Automatic sorting System under Grant 2021H6030, National Natural Science Foundation of China under Grants 61972166 and 62372190. In addition, we would like to thank **aoxiao Wu for her work on the comparison of model complexity, as well as the revision to the manuscript.
Funding
This work was jointly supported by Fujian University-Industry Cooperation Project of Research and Industrialization of Machine Vision driven Automatic sorting System under Grant 2021H6030, National Natural Science Foundation of China under Grants 61972166 and 62372190.
Author information
Authors and Affiliations
Contributions
Liling Fan and Zhenguo Gao conceived and designed the study; Liling Fan and Kunliang Jiang performed the experiments; Liling Fan, Zhenguo Gao and Weixue Zhou analyzed the data; and Liling Fan , Zhenguo Gao, Yanmin Luo, Kunliang Jiang and Weixue Zhou wrote the paper with input from all authors. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest/Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Fan, L., Jiang, K., Zhou, W. et al. 3D Human pose estimation from video via multi-scale multi-level spatial temporal features. Multimed Tools Appl (2024). https://doi.org/10.1007/s11042-023-17955-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11042-023-17955-6