
Abstract
Why is ordinary language vague? We argue that in contexts in which a cooperative speaker is not perfectly informed about the world, the use of vague expressions can offer an optimal tradeoff between truthfulness (Gricean Quality) and informativeness (Gricean Quantity). Focusing on expressions of approximation such as “around”, which are semantically vague, we show that they allow the speaker to convey indirect probabilistic information, in a way that can give the listener a more accurate representation of the information available to the speaker than any more precise expression would (intervals of the form “between”). That is, vague sentences can be more informative than their precise counterparts. We give a probabilistic treatment of the interpretation of “around”, and offer a model for the interpretation and use of “around”-statements within the Rational Speech Act (RSA) framework. In our account the shape of the speaker’s distribution matters in ways not predicted by the Lexical Uncertainty model standardly used in the RSA framework for vague predicates. We use our approach to draw further lessons concerning the semantic flexibility of vague expressions and their irreducibility to more precise meanings.




Similar content being viewed by others


Notes
Lipman (2009), in a signaling-game setting, proves that using a vague language, defined as using a mixed strategy over signals, cannot be optimal compared to using a pure strategy, which Lipman interprets as using a precise language. Prima facie, this result may seem to go counter to the result of optimality we establish in this paper. However, Lipman’s definition of vagueness in fact departs significantly from ours, and we do not endorse it. We leave a comparison between his result and our approach for another occasion.
Interlocutors typically assess vague expressions relative to implicit standards. See for example Verheyen et al. (2018) for empirical evidence that “tall” and “heavy”, applied to human figures, are ascribed in part relative to one’s own height and weight. However, Veltman’s effect can be produced by using an exact but a proportional/relative expression of comparison (e.g., “I am in the top 7%”). It cannot be said, therefore, that vague expressions are necessary in order to communicate relative information. We are indebted to A. Cremers and to an anonymous reviewer for this observation.
See Van der Henst et al. (2002) for a discussion of related cases, in which speakers prefer to round off the time even when they know it with high precision. Explicit use of “around” is not needed in such cases, “thirty students” can be used to mean “around thirty students”, or “five o’clock” to mean “about five o’clock”, as discussed by Lasersohn (1999).
This relies on both parts of Grice’s maxim of Quality, including “do not say that for which you lack adequate evidence”, which can be strengthened into Williamson (2000)’s norm of assertion (“assert only what you know”).
Accessing one’s confidence level may be a delicate matter too. One might argue that even reports of confidence levels are challenges to the Knowledge norm of assertion. However, our argument above does not rely on that premise, we may assume that the speaker has reliable access to her confidence levels. In practice the speaker can also say “probably between 60 and 80 persons”, or “I believe between 60 and 80 persons”, but they involve vague “hedges” in the sense of Lakoff (1973).
As pointed out by a referee, empirical sciences contain reports of magnitude estimates of form \(193\pm 5\) cm. This indicates that the true value lies in the interval (188, 198) with a certain probability, and it assumes a specific distribution (usually Gaussian) centered on 193. “Around”-sentences of natural language specify neither the distribution nor the boundaries, but our main point will be that they communicate that the target value is comparatively more probable than more remote values.
One significant difference is that in Lassiter and Goodman’s (2017) proposal, which is couched in the Rational Speech Act model, the joint reasoning about the variable of interest—say someone’s height—and the parameter of interpretation (e.g., a threshold for tall) does not take place at the level of the ‘literal listener’, but is carried out by the first-level pragmatic listener. This difference will prove to have important consequences when we develop a model for the speaker. See Sect. 8 and Appendix A for a detailed discussion.
\(D = \sum \nolimits _k P(x=k)\times \sum \nolimits _{i \ge |n-k|} P(y=i)\)—this is the sum of all terms that can be obtained from the numerator by instantiating x with all its possible values.
The symbol \(\propto \) reads ‘is proportional to’. More specifically, a statement of the form \(f(a| \ldots ) \propto g(a,\ldots )\) is shorthand for: \(f(a|\ldots ) = \frac{g(a,\ldots )}{\sum \nolimits _{a' \in A}g(a',\ldots )}\), where A is the domain over which the variable a ranges. So the above formula boils down to:
$$\begin{aligned} P(x=k\mid \hbox {} x \hbox {is}\, \hbox {around}\, n) = \dfrac{P(x=k) \times \sum \nolimits _{i \ge |n-k|} P(y=i)}{\sum \nolimits _{\hbox {} j \hbox {is}\, \hbox {in} \,\hbox {the} \,\hbox {support} \,\hbox {of} \,x} P(x=j) \times \sum \nolimits _{i \ge |n-j|} P(y=i)} \end{aligned}$$The proportionality factor ensures that the sum of all \(P(x= \ldots \mid \hbox {} x \hbox {is}\, \hbox {around}\, n)\), across all possible values for x, is 1, so that \(P(x=\ldots \mid \hbox {} x \hbox {is} \,\hbox {around} \,n)\) is a probability distribution.
Given that we want n to be the middle of the interval, making [0, 2n] the largest possible interval is natural when the numeral is used to talk about the cardinality of a set—since negative numbers are then not relevant. Ferson et al. (2015) provide experimental data showing that when asked to estimate the largest interval compatible with an around n-statement, people tend to pick an interval that is much narrower than [0, 2n]. Taken at face value, this could suggest that the prior distribution on y should categorically exclude too large intervals—since otherwise the posterior distribution resulting from an “around”-sentence would not categorically exclude any value that was not already excluded prior to the utterance. Such a conclusion is however not warranted, and depends on the ‘linking’ theory that provides the bridge between a specific model and people’s behavior in an experimental task. In our setup, even with a uniform prior distribution on the set of intervals of the form \([n- i, n+i]\), with \(i \le n\), as well as on the range of the variable of interest x, the listener’s posterior distribution after processing “around n” assigns very low probability to values that are very far from n. It is very plausible that, when asked to estimate an interval, people simply report an interval of values which receive a high enough probability, and therefore exclude values which, without being equal to 0, are in practice negligible.
We return to this point, and to its philosophical significance, in Sect. 10.
We refer to Mortier (2019) for a report on some preliminary results. In this study, we asked participants to select an interval for an around n-statement, and then asked them to report weights for each value in the selected interval, both for the around-sentence and for a between-sentence based on the same interval. The results confirmed the prediction made by the ratio inequality, but further work is needed to control for potential confounds.
For a general introduction to KL-divergence, see McElreath (2016, p. 179). The presentation we give is more specific to the communicative framework under discussion.
We use the natural logarithm throughout this paper.
For any two probability distributions \(P_1\) and \(P_2\), \(D_{KL}(P_1||P_2)\) is always positive. This reflects the fact that it measures the gain in information when one starts with a distribution \(P_2\) and makes an observation which results into a posterior distribution \(P_1\). In case \(P_1\) cannot be rationally reached from \(P_2\) (because \(P_2\) assigns probability 0 to some world-states that are assigned a non-null probability by \(P_1\)), the KL-divergence is infinite (see footnote 17).
It is worth mentioning here that using this measure indirectly captures Grice’s maxim of Quality. This is for the following reason. Suppose that the speaker is in no position to exclude a certain world-state \(x=j\), i.e. \(P_o(x=j) > 0\). Suppose she picked a message that would in fact exclude this state, i.e. such that \(P_m(x=j) = 0\). Then the quantity \(log\dfrac{P_o(x=k)}{P_m(x=k)}\) can be viewed as infinite (because the denominator in the fraction is 0), and so one term of the sum in the formula above will be infinite, as a result of which \(D_{KL}(P_o||P_m)\) is infinite, and U(m, o) is infinitely negative.
For simplicity, we ignore the possibility that two messages are exactly tied, i.e. have exactly the same utility. Furthermore, we assume here that the speaker is fully rational and picks the best message with probability 1. In Rational Speech Act models, the speaker is typically not assumed to be fully rational. Rather, she follows a so-called SoftMax rule whereby she is more likely to use the best message than the second best, more likely to use the second best than the third best, etc., but nevertheless does not pick the best message with probability 1. This difference is not important at this point. However in Sect. 6, where we develop a fully explicit RSA model, we use the SoftMax rule.
The reason this is the case is that for every value k in [1, 7], \(P_{\text {around }}(k)\) is closer to \(P_o(k)\) than \(P_{\text {between }}(k)\) is. \(P_{\text {between }}\) wins only for the extreme values 0 and 8 but since these values have anyway a null probability of occurrence according to \(P_o\), they do not play any role in the computation of the expected difference in surprisal, which is computed from the point of view of the speaker.
Parikh (1994) contains a pioneering account of the informational value of using vague sentences, which also consists in exhibiting a context in which the listener benefits from hearing a vague term. However, his argument is not the same. His point is basically that when speaker and listener have different semantic representations for a vague term, provided those representations overlap sufficiently, using that term can communicate more information to the listener than not using it, given some purpose (for instance, saying “the book is titled ‘X’ and it is blue”, instead of just “the book is titled ‘X”’). Our argument is different, and makes a stronger claim, for we compare the informational value of using a vague term to the informational value of using precise counterparts to that term (rather than that of not saying anything).
Importantly, as noted in footnote 8, we substantially depart from Lassiter and Goodman’s (2017) model and, more generally from models with lexical uncertainty (e.g., Bergen et al., 2012, 2016), which we discuss in Sect. 8 and Appendix A. In such models, the literal listener is relativized to a fixed value for y, and there are as many literal listeners as they are possibly values for y. It is only at the level of the first pragmatic listener that uncertainty about the value of y is factored in.
This is of course a gross oversimplification, since we only consider messages that are ‘centered’ on 4. The only reason we do this is that this limitation makes the model reasonably tractable and intelligible. Given that the set of observations we consider in Sect. 7.1 will result in posterior distributions which are themselves centered on 4, it is likely that other “between”-statements that would not be centered on 4 would be generally suboptimal for the speaker compared to the messages that we include in the model.
Regarding (12-b), note that in contrast with Eq. (BIR), we use here the joint distribution P(x, o) instead of just P(x). We obtain this formula in the same way as we obtained the one in Eq. (BIR). Bayes’ rule gives us (given that y is probabilistically independent of x and o):
$$\begin{aligned} L^0(x=k, o=o_j, y = i \mid d(x,4) \le y)\propto & {} P(d(x,4) \le y \mid x=k, o=o_j, y=i)\\ {}{} & {} \times P(x=k, o=o_j) \times P(y=i) \end{aligned}$$Obviously, \(P(d(x,4) \le y \mid x=k, o=o_j, y=i)\) is either 0 or 1, depending on whether \(d(k,4) \le y\), and the value of o does not play any role (that is, the literal meaning of the message does not carry any direct information about o, the observation that the speaker made, but only about x). So the above equation simplifies to:
$$\begin{aligned} L^0(x=k, o=o_j, y = i \mid d(x,4) \le y) \propto P(d(x,4) \le y \mid x=k, y=i) \times P(x=k, o=o_j) \times P(y=i) \end{aligned}$$and the rest of the computation proceeds in the same way as in Eq. (BIR). Note that we have:
\(L^0(x=k|m) \propto \sum \limits _{o_h \in O} L^0(x=k, o = o_h|m)\)
\( = \sum \limits _{o_h \in O} [P(x=k, o=o_h)\times \sum \limits _{i \ge |n-k|} P(y=i)]\)
\( = \sum \limits _{i \ge |n-k|} P(y=i) \times \sum \limits _{o_h \in O} P(x=k, o=o_h)\)
\( = \sum \limits _{i \ge |n-k|} P(y=i) \times P(x=k) = P(x=k) \times \sum \limits _{i \ge |n-k|} P(y=i).\)
Hence we recover Eq. (BIR).
\(\frac{1}{\uplambda }\) is often called the temperature parameter. When \(\uplambda \) tends to infinity, this quantity tends to 1 if m is the message that receives the highest utility, as with the ArgMax function. The use of SoftMax allows a nonoptimal solution at a certain recursion level to become optimal at a later level in the recursive model presented here (cf. footnote 28), whereas using ArgMax would preclude this possibility.
The code for this implementation (R scripts) as well as that of the alternative models discussed in Sect. 8 can be downloaded from https://github.com/BenSpec/ScriptsAround.
Values are rounded to 2 digits (here and elsewhere), but actually sum up to 1 in all columns (the value 0 thus sometimes corresponds to a non-zero but extremely small value). The choice of these nine distributions is for the sake of illustration, and we could stipulate other values in the case of peaked distributions.
This is by no means a necessary choice. But to make an already complex model reasonably tractable, we chose to restrict the set of possible observations to those that are ‘centered’ on 4, as this suffices to make our main point. Importantly, we can build a richer model, which includes precise observations for each possible value for x, with the result that the prior distribution on x is near uniform (or even such that the prior on the central value is less than the one on more peripheric values). Simulations show that this does not make any qualitative difference to the model’s predictions. The code for this richer model is available at https://github.com/BenSpec/ScriptsAround.
As noted in footnote 24, modeling the speaker as not being fully rational is necessary in order to derive this effect: with a fully rational speaker, the probability that \(S_1\) picks the around-message to communicate a peaked distribution with support [2, 6] would be 0, making the message not interpretable by \(L_1\) and subsequent listeners.
It was in part developed to deal with so-called Hurford Disjunctions, i.e. sentences like Mary ate some or all of the cookies, which imply that the speaker is not fully informed.
Technically speaking, many RSA models are written without explicit reference to Kullback–Leibler divergence, but it is easy to show, that they are fully equivalent to models that use the Kullback–Leibler divergence in the utility function of the speaker.
It seems that this subtle difference between the utility function defined in Goodman and Stuhlmüller (2013) and the one used in Bergen et al. (2016) has not been discussed at all in previous literature. To complicate the matter, as pointed out to us by Michael Franke and as hinted in Scontras et al. (2018, Chapter 2), in their actual implementation, Goodman and Stuhlmüller (2013) do not seem to have used the notion of utility they define in their paper, but to actually implement yet a different model. Thanks to Michael Franke for very helpful discussions.
Recently, another RSA model with meaning underspecification has been proposed by Franke and Bergen (2020), the Lexical Intention model (LI for short). In this model, the speaker chooses simultaneously a message and a meaning for the message, while in the LU model \(S^1\) is relativized to a certain interpretation function but does not choose one. The model has been applied only to cases where the speaker is assumed to be fully informed. If we extend it on the basis of the utility function used in the LU model for the more general case of a non-fully informed speaker, the utility (at level 1) of a pair <message, meaning> is defined by exactly the same formula as in the LU model, even though it has a different interpretation. This ensures that the limitation result proved in Appendix A for the LU model also holds for this version of the LI model. In fact, in this extended version of the LI model, within the setup described in Sect. 7, the “around 4”-statement is entirely uninformative, i.e. the pragmatic listener does not gain any information from it. However, if in fact we use a utility function identical to the one described in Appendix A, the resulting model makes predictions that are qualitatively similar to ours, at least for very high values for \(\uplambda \). Simulations can be found at https://github.com/BenSpec/ScriptsAround.
It might even be common knowledge that the target number for “around” is ruled out. An example from an anonymous referee is: “there might be a rule that congregations of a cult must gather in odd numbers. One member can brag about their congregation, saying: We have typically around 100 members”.
Reporting “around 18 children” is odd but not ruled out, for instance if the speaker tries to remember how many children attended class, by remembering how many children sat in each row, adds up the numbers, and wants to convey that the value obtained may be inaccurate.
It is also plausible that granularity considerations influence the interpretation of “around”-statements even when the speaker is not assumed to be fully knowledgeable. For instance, it might happen that “around 40” makes the interval [30, 50] particularly salient. One way to capture such an effect in our model would be to assume that the prior probability distribution over the intervals denoted by “around” is influenced by granularity considerations and, instead of being uniform, gives more weight to intervals contained in [30, 50], which would incorporate some of the insights from the literature (e.g., Krifka, 2007; Solt, 2014, Solt et al., 2017).
For a preliminary investigation of rounding in cases in which the speaker is perfectly informed, we refer to Mortier (2019), which develops a model within the Lexical Uncertainty framework where messages with round numbers are less costly than those using non-round numbers, so that a fully informed speaker might choose an “around”-message in order to avoid using a non-round number.
Most works in economic theory and game-theory accept some form of the Common Prior Assumption, and dispensing with this assumption leads to non-trivial conceptual and theoretic challenges, as discussed in Morris (1995).
Here is a way to do this:
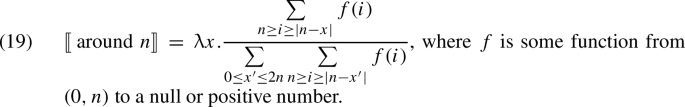
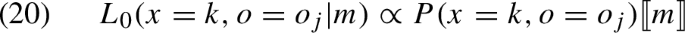
This is exactly equivalent to our official model when we identify f(i) with P(i).
Sutton (2018) recently argued that an adequate metasemantics for probabilistic treatment of vagueness is one in which vague expressions do not have truth-conditions proper, but default rules of use. Our account of the meaning of “around” maintains truth-conditions for “around”, but as just discussed they do not play any direct role, and our model could even be directly formulated in terms of a fuzzy semantics. In our model, the listener, when interpreting an “around”-statement, updates her probability distribution over worlds, but does not exclude any world from the common ground. We leave a more detailed discussion of this aspect, as well as of the rejoinders that could be made on behalf of epistemicism, for another occasion.
In Sect. 1 we provide the definition of the SoftMax function and restate Eqs. 3 and 6 in terms of it.
Strictly speaking, of course, \(U^1(m|o,i)\) is simply not defined, since \(\log (0)\) is not defined. The point is simply that the limit of \(\exp (f(x))\) in 0 is 0 when f diverges to \(-\infty \) in 0. Likewise, we also treat the function \(x\times \log (x)\) as evaluating to 0 in 0, because even though this function is not defined in 0, its limit in 0 is 0. Here and elsewhere we choose not to introduce explicit reasoning about limits in order to simplify the exposition, with no harmful effects.
To properly define this sequence, we choose once and for all an enumeration of all messages, and we order the sequence in accordance with this enumeration.
Recall that \(\overrightarrow{U^1_{o,i}}\) is a sequence that contains all the utilities achieved by messages that respect Quality with respect to o and i, ordered according to a fixed enumeration of all messages.
We can restrict the sum that defines \(U^2(m | o_1)\) and \(U^2(m | o_2)\) to the worlds of S, i.e. the support of \(P_{o_1}\) and \(P_{o_2}\), because for worlds w outside of S, \(P(w|o_1) = P(w|o_2) = 0\), \(P(w,o_1) = P(w,o_2) = 0\), and so the corresponding terms in the sum are of the forms \(0 \times log(0)\), i.e. 0—since the limit of \(x\times log(x)\) in 0 is 0.
This characterization of the listener happens to be identical (modulo differences in notations) to one that is discussed in Appendix B of Bergen et al. (2016), statement (41).
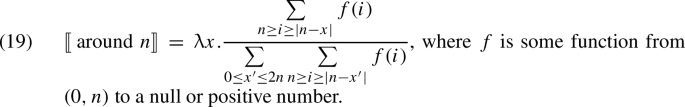
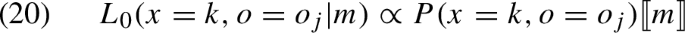
References
Bacon, A. (2018). Vagueness and thought. Oxford: Oxford University Press.
Barker, C. (2002). The dynamics of vagueness. Linguistics and Philosophy, 25, 1–36.
Bergen, L., Goodman, N., & Levy, R. (2012). That’s what she (could have) said: How alternative utterances affect language use. Proceedings of the Annual Meeting of the Cognitive Science Society, 34, 120–122.
Bergen, L., Levy, R., & Goodman, N. (2016). Pragmatic reasoning through semantic inference. Semantics and Pragmatics, 9(20). https://doi.org/10.3765/sp.9.20.
Borel, E. (1907). Un paradoxe économique: le sophisme du tas de blé et les vérités statistiques. La Revue du Mois, 4, 688–699. English translation in Erkenntnis (79), 1081–1088, 2014: An economic paradox: the sophism of the heap of wheat and statistical truths.
Channell, J. (1985). Vagueness as a conversational strategy. Nottingham Linguistic Circular, 14, 3–24.
Cobreros, P., Égré, P., Ripley, D., & van Rooij, R. (2012). Tolerant, classical, strict. The Journal of Philosophical Logic, 41(2), 347–385.
Douven, I. (2019). The rationality of vagueness. In R. Dietz (Ed.), Vagueness and rationality in language use and cognition (pp. 115–134). New York: Springer.
Égré, P., & Barberousse, A. (2014). Borel on the heap. Erkenntnis, 79, 1043–1079.
Égré, P., & Icard, B. (2018). Lying and vagueness. In J. Meibauer (Ed.), The Oxford handbook of lying (pp. 354–369). Oxford: Oxford University Press.
Égré, P., Ripley, D., & Verheyen, S. (2019). The sorites paradox in psychology. In S. Oms & E. Zardini (Eds.), The Sorites Paradox (pp. 263–286). Cambridge: Cambridge University Press.
Ferson, S., O’Rawe, J., Antonenko, A., Siegrist, J., Mickley, J., Luhmann, C., Sentz, K., & Finkel, A. (2015). Natural language of uncertainty: Numeric hedge words. International Journal of Approximate Reasoning, 57, 19–39.
Frank, M., Goodman, N., Lai, P., & Tenenbaum, J. (2009). Informative communication in word production and word learning. Proceedings of the Annual Meeting of the Cognitive Science Society, 31, 1228–1233.
Franke, M., & Bergen, L. (2020). Theory-driven statistical modeling for semantics and pragmatics: A case study on grammatically generated implicature readings. Language, 96(2), e77–e96.
Franke, M., & Correia, J. P. (2018). Vagueness and imprecise imitation in signalling games. The British Journal for the Philosophy of Science, 69(4), 1037–1067.
Frazee, J., & Beaver, D. (2010). Vagueness is rational under uncertainty. In M. Aloni, H. Bastiaanse, T. de Jager, & K. Schulz (Eds.), Logic, language and meaning. Amsterdam Colloquim 2009 (pp. 153–162). Berlin: Springer.
Goodman, N. D., & Stuhlmüller, A. (2013). Knowledge and implicature: Modeling language understanding as social cognition. Topics in Cognitive Science, 5(1), 173–184.
Grice, P. (1989). Logic and conversation. In Studies in the way of words (pp. 22–40). Harvard: Harvard University Press.
Kennedy, C. (2007). Vagueness and grammar: The semantics of relative and absolute gradable adjectives. Linguistics and Philosophy, 30(1), 1–45.
Krifka, M. (2007). Approximate interpretation of number words. In G. Bouma, I. Krämer, & J. Zwarts (Eds.), Cognitive foundations of communication (pp. 111–126). Amsterdam: Koninklijke Nederlands Akademie van Wetenschapen.
Lakoff, G. (1973). Hedges: A study in meaning criteria and the logic of fuzzy concepts. Journal of Philosophical Logic, 458–508.
Lasersohn, P. (1999). Pragmatic halos. Language, 75(3), 522–551.
Lassiter, D., & Goodman, N. D. (2017). Adjectival vagueness in a Bayesian model of interpretation. Synthese, 194(10), 3801–3836.
Lipman, B. L. (2009). Why is language vague? Ms., Boston University. https://sites.bu.edu/blipman/files/2021/10/vague5.pdf.
McElreath, R. (2016). Statistical rethinking: A Bayesian course with examples in R and Stan (1st ed.). Boca Raton: CRC Press.
Morris, S. (1995). The common prior assumption in economic theory. Economics & Philosophy, 11, 227–253.
Mortier, A. (2019). Semantics and pragmatics of approximation expressions. Master’s thesis, ENS, PSL University, under the supervision of Paul Égré and Benjamin Spector.
Oaksford, M., & Chater, N. (2003). Conditional probability and the cognitive science of conditional reasoning. Mind & Language, 18(4), 359–379.
Parikh, R. (1994). Vagueness and utility: The semantics of common nouns. Linguistics and Philosophy, 17(6), 521–535.
Russell, B. (1923). Vagueness. The Australasian Journal of Psychology and Philosophy, 1(2), 84–92.
Scontras, G., Tessler, M. H., & Franke, M. (2018). Probabilistic language understanding: An introduction to the Rational Speech Act framework. https://www.problang.org.
Smith, N. J. J. (2008). Vagueness and degrees of truth. Oxford: Oxford University Press.
Solt, S. (2014). An alternative theory of imprecision. Semantics and Linguistic Theory, 24, 514–533.
Solt, S. (2015). Vagueness and imprecision: Empirical foundations. Annual Review Linguistics, 1(1), 107–127.
Solt, S., Cummins, C., & Palmović, M. (2017). The preference for approximation. International Review of Pragmatics, 9(2), 248–268.
Sorensen, R. (1988). Blindspots. Oxford: Clarendon Press.
Sutton, P. R. (2018). Probabilistic approaches to vagueness and semantic competency. Erkenntnis, 83(4), 711–740.
van Deemter, K. (2009). Utility and language generation: The case of vagueness. Journal of Philosophical Logic, 38(6), 607.
Van der Henst, J.-B., Carles, L., & Sperber, D. (2002). Truthfulness and relevance in telling the time. Mind & Language, 17(5), 457–466.
van Tiel, B., Franke, M., & Sauerland, U. (2021). Probabilistic pragmatics explains gradience and focality in natural language quantification. Proceedings of the National Academy of Sciences, 118(9), e2005453118.
Veltman, F. (2001). Het verschil tussen vaag en niet precies. Inaugural lecture, 12 October 2001, University of Amsterdam. Amsterdam: Vossiuspers UvA.
Verheyen, S., Dewil, S., & Égré, P. (2018). Subjectivity in gradable adjectives: The case of tall and heavy. Mind & Language, 33(5), 460–479.
Williamson, T. (1994). Vagueness. London: Routledge.
Williamson, T. (2000). Knowledge and its limits. Oxford: Oxford University Press.
Wright, C. (1995). The epistemic conception of vagueness. The Southern Journal of Philosophy, 33(S1), 133–160.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Declaration of contribution
PE and BS share first authorship in this work. PE came up with the core idea of the paper, which he then developed with SV, BS, and AM. PE and SV originally proposed the model in Appendix B, and PE and BS later worked out its Bayesian counterpart. BS, AM and PE identified the ratio inequality, and AM investigated the model by PE-SV. BS is responsible for the speaker model and the RSA implementation, and for the comparison with the Lexical Uncertainy model. PE and BS jointly wrote the first complete draft of the paper, which the four authors finalized and revised together.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We owe special thanks to Leon Bergen, Emmanuel Chemla, Alexandre Cremers, Michael Franke, and Dan Lassiter, for their detailed feedback on specific aspects of the paper, as well as to three anonymous referees, and to our L &P editors Stefan Kaufmann and Regine Eckardt. We also thank audiences in Stuttgart (DGfS Annual Conference 2018), Groningen, Amsterdam, Aix-en-Provence, Brussels (LNAT 4), Berlin (Workshop “The Meaning of Numerals”), Stockholm, Turin (FEW 2019), London (COLAFORM Meeting), Nantes (OASIS 2), Munich, Oxford, New York, Melbourne, Créteil, and Paris (LINGUAE seminar; workshop “Signaling in Social Interactions”; workshop “Vagueness in the Sciences”). We thank the many colleagues present on those and other occasions for valuable discussions, in particular D. Atkinson, M. Ariel, A. Baltag, D. Bonnay, C. Hesse, B. Kooi, C. List, J. MacFarlane, S. Mascarenhas, P. Pagin, J. Peijnenburg, P. Schlenker, S. Solt, H. De Smet, J-W. Romeijn, U. Stojnic. This research was supported by the programs ANR PROBASEM (ANR-19-CE28-0004-01), ANR AMBISENSE (ANR-19-CE28-0019-01), and ANR FRONTCOG (ANR-17-EURE-0017). We also thank the ANR-DFG program COLAFORM (ANR-16-FRAL-0010), the van Gogh Project 42589PM, and the France-Berkeley Fund for additional support.
Appendices
Appendix A: A limitation result about the LU model
In this appendix, we prove that in the Lexical Uncertainty model (LU model, Bergen et al., 2016), if two observations \(o_1\) and \(o_2\) are such that the support of the conditional distributions \(P(w|o_1)\) and \(P(w|o_2)\) are the same, then, at every level of the recursion, the speaker’s probability of using a message m if she observed \(o_1\) is the same as if she observed \(o_2\). It follows that in the LU model, only the support of the subjective probability distribution of the speaker, and not its shape, plays a role in her choice of a message, in contrast with our model.
The LU model is defined by the following equations, where \(\llbracket m \rrbracket ^i(w)\) is the truth-value of the literal meaning of m, relative to the interpretation function i, in world w, and \(\llbracket m \rrbracket ^i\) denotes the set of worlds where m is true relative to interpretation i (in our setting, i is what determines the interpretation of “around”, i.e. a certain value for y). The parameter \(\uplambda \) is a non-null, positive real number. For any message m, c(m) is the cost of m, a null or positive real number. P is the prior distribution about the possible values of w (world state), o (observation) and i, and is such that the value taken by i is probabilistically independent from w and o.
-
1.
\(L^0(w,o | m,i) = \dfrac{P(w,o) \times \llbracket m \rrbracket ^i(w)}{P(\llbracket m \rrbracket ^i)}\)
-
2.
\(U^1(m|o,i) = (\sum \limits _{w}P(w | o) \times \log (L^0(w,o | m,i))) - c(m)\)
-
3.
\(S^1(m | o, i) = \dfrac{\exp (\uplambda U^1(m,o,i))}{ \sum \limits _{m'}\exp (\uplambda U^1(m',o,i))}\)
-
4.
\(L^1(w,o | m) = \dfrac{P(w,o)\times \sum \limits _{i} P(i)S^1(m | o, i)}{\alpha _1(m)}\), where \(\alpha _1(m) = \sum \limits _{w',o'} (P(w',o')\) \( \sum \limits _{i} P(i)S^1(m | o', i))\)
-
5.
For \(n \ge 1\), \(U^{n+1}(m|o) = (\sum \limits _w P(w| o)\log (L^n(w,o | m))) - c(m)\)
-
6.
\(S^{n+1}(m | o) = \dfrac{\exp (\uplambda U^{n+1}(m,o))}{\sum \limits _{m'} \exp (\uplambda U^{n+1}(m',o))}\)
-
7.
For \(n \ge 2\), \(L^n(w,o | m) = \dfrac{P(w,o) \times S^n(m | o)}{\alpha _n(m)}\), where \(\alpha _n(m) = \sum \limits _{w',o'}P(w',o')\) \(S^n(m | o')\)
Results to be proven
If o is an observation, \(P_o\) is the probability distribution over worlds defined by:
\(P_o(w) = P(w,o|o) = P(w|o)\)
-
1.
If two observations \(o_1\) and \(o_2\) are such that \(P_{o_1}\) and \(P_{o_2}\) have the same support (i.e. for every w, \(P(w|o_1)>0\) iff \(P(w|o_2) > 0\)), then for every message m and every interpretation function i, \(S^1(m|o_1, i) = S^1(m|o_2, i)\)
-
2.
If two observations \(o_1\) and \(o_2\) are such that \(P_{o_1}\) and \(P_{o_2}\) have the same support, then for every \(n \ge 2\), \(S^n(m|o_1) = S^n(m|o_2)\)
1.1 A.1: Proof strategy
The key ingredient of the proof is the following. Consider two observations \(o_1\) and \(o_2\) such that \(P_{o_1}\) and \(P_{o_2}\) have the same support (i.e. they assign a non-null probability to the same worlds). Consider the set of messages \({\mathcal {M}}\) that express a proposition that is entailed by this support under at least one interpretation i (a condition we call Weak Quality—as we shall see, other messages are not usable at all by a speaker who observed \(o_1\) or \(o_2\), as they violate Grice’s maxim of Quality, cf. (A-2) below). We prove that, at every level of recursion, the utility achieved by each message in \({\mathcal {M}}\) for a speaker who observed \(o_2\) is equal to the one achieved for a speaker who observed \(o_1\) plus a constant term which does not depend on the message. In other words, there is a quantity K which depends on the various parameters of the models and on \(o_1\) and \(o_2\) but crucially not on the message m, such that for every message m, \(U^n(m|o_2) = U^n(m|o_1) + K\).
Now, the speaker’s strategy in the RSA model as defined in Eqs. 3 and 6 is based on the so-called SoftMax function.Footnote 41 The SoftMax function turns a sequence of numerical values (in our case the utilities of each message relative to a certain observation) into a probability distribution over members of this sequence. In the RSA model, the speaker’s strategy relative to a given observation is obtained by applying the SoftMax function to the utilities of each message relative to this observation. The SoftMax function enjoys a property known as Translation Invariance, as we prove below.Footnote 42 That is, if, starting from a sequence of numerical values, we consider the sequence obtained by adding a constant term to each value, and then apply the SoftMax function to these shifted values, the resulting probability distribution over the members of the new sequence is exactly the same as the one obtained when applying the SoftMax function to the initial sequence. Since the utilities achieved by different messages relative to \(o_2\) can be obtained by adding a constant term to those achieved by the very same messages relative to \(o_1\) (as explained in the previous paragraph), this means that the resulting probability distribution over messages is the same for \(o_1\) and \(o_2\).
We will first prove that for \(S^1\), relative to a fixed interpretation i, the difference between the utility achieved by a message m in \({\mathcal {M}}\) relative to \(o_1\) and the one achieved by the same message relative to \(o_2\) does not depend on m, and is therefore the same across messages in \({\mathcal {M}}\). Thanks to Translation Invariance, this will ensure that for every m in \({\mathcal {M}}\) and every i, \(S^1(m|o_2, i) = S^1(m|o_1, i)\). Then we will do the same with \(S^2\)—there has to be a separate step for \(S^2\) because the variable i that appears in the definition of \(S^1\) no longer appears when \(n \ge 2\), so we start the inductive proof at level 2. Then we complete the proof by proving the inductive step: assuming that for every \(n \ge 2\), \(S^n(m|o_2) = S^n(m|o_1)\), we prove that at the level \(n+1\), the difference in the utility achieved by a message m in \({{\mathcal {M}}}\) relative to \(o_2\) and relative to \(o_1\) does not depend on m, which, thanks to Translation Invariance, ensures that for every m in \({{\mathcal {M}}}\), \(S^{n+1}(m|o_2) = S^{n+1}(m|o_1)\). At each step, the reason why the key result is observed is that the log-function which appears in the definition of the utility function turns products into sums, allowing us, together with the fact that probabilities sum up to 1, to separate terms which depend on m from those that depend on o, and all terms in which m appears cancel out when we consider the difference \(U(m|o_2)-U(m|o_1)\).
We now give the detailed proof.
1.2 A.2: Quality and Weak Quality
Definitions
-
1.
We say that a message m respects Quality with respect to an observation o and an interpretation i if, for every w, if \(P(w | o) > 0\), then \(\llbracket m \rrbracket ^i(w)=1\).
-
2.
We say that a message m respects Weak Quality with respect to an observation o if there exists an interpretation i such that \(P(i)>0\) and m respects Quality with respect to o and i.
Let \(o_1\) and \(o_2\) be two observations such that \(P_{o_1}\) and \(P_{o_2}\) have the same support, i.e. for every w, \(P(w|o_1)>0\) iff \(P(w|o_2) > 0\). From now on, \(o_1\) and \(o_2\) denote two such observations.

Proof of Lemma (A-1)
Obvious from the definitions of Quality and Weak Quality, and the fact that \(P_{o_1}\) and \(P_{o_2}\) have the same support.

Proof of the facts in (A-2)
First we prove the result for \(S^1\), then for \(S^2\) and then by induction for higher values of n.
Proof of (A-2-a)—If m does not respect Quality with respect to o and i, then for some w such that \(P(w|o) > 0\), \(\llbracket m \rrbracket ^i(w)=0\). For such a w, then, \(L^0(w,o|m,i)=0\), hence \(\log (L^0(w,o|m,i)) = - \infty \). So at least one term in the sum which defines \(U^1(m|o,i)\) evaluates to \(-\infty \), and so the sum itself does, hence \(U^1(m|o,i) = - \infty \).Footnote 43 Since \(S^1(m|o,i)\) involves exponentiating a quantity that is infinitely negative, we have \(S^1(m|o,i) = 0\). Reciprocally, if m does respect Quality with respect to o and i, then no term in the sum is infinitely negative, and \(U^1(m|o,i)\) is not infinitely negative either, and so \(S^1(m|o,i)>0\).
Proof of (A-2-b)—The proof is by induction.
Base-case (\(n=2\)): Suppose now that m does not respect Weak Quality with respect to o. Then for every i such that \(P(i)>0\), m does not respect Quality with respect to o, i; and so by the result just proven, every term in the sum \(\sum \nolimits _{i} P(i)S^1(m | o, i)\) is equal to 0, and so is the sum as a whole. As a result, \(L^1(w,o|m)=0\), for every w. From this it follows that the sum \(\sum \nolimits _w P(w| o)\log (L^1(w,o | m))\) evaluates to \(-\infty \), and therefore so does \(U^2(m|o)\). \(S^2(m|o)\) involves again exponentiating an infinitely negative value, so is equal to 0. Reciprocally, if m respects Weak Quality with respect to o, there is at least one i relative to which \(P(i)\times S^1(m | o, i)>0\), and therefore \(\sum \nolimits _{i} P(i)S^1(m | o, i)\) is not equal to 0. For every w such that \(P(w,o)>0\), then \(L^1(w,o|m)>0\), and therefore \(U^2(m|o)\) is not infinitely negative, and so \(S^2(m|o)>0\).
Inductive step: Finally, let assume that the result holds for \(S^n\) (Induction Hypothesis). Suppose again that m does not respect Weak Quality with respect to o. By the Induction Hypothesis, \(S^n(m|o)=0\), and therefore for every w, \(L^n(w,o|m)=0\) (given the definition of \(L^n\)). Then \(U^{n+1}(m|o) = - \infty \), as in each term of the sum that defines \(U^{n+1}(m|o)\), the \(\log \)-function takes 0 as its argument. It follows that \(S^{n+1}(m|o)=0\). Reciprocally, if m does respect Weak Quality with respect to o, then \(S^n(m|o)>0\), and therefore for every w such that \(P(w|o)>0\), \(L^n(w,o|m)>0\), from which it follows that \(U^{n+1}(m|o)\) is not infinitely negative and therefore that \(S^{n+1}(m|o) >0\).
1.3 A.3: Reformulating utility functions in terms of SoftMax, SoftMax invariance
The SoftMax function
The SoftMax function takes three arguments: a sequence of real numbers \(\textbf{x} = (x_1, \ldots , x_i)\), a member of this sequence, and the paratemer \(\uplambda \). It is defined as follows:
Reformulating the utility function in terms of SoftMax
Equation 3 is repeated here:
Note that in the denominator, every term of the sum corresponding to a message which does not respect Quality with respect to o and i is equal to 0 [because its utility is infinitely negative, and so after exponentiation we get 0, cf. (A-2-a)]. This means that we can restrict the denominator to the messages that respect Quality with respect to o and i.
Let \({\mathcal {M}}_o = <m_1, \ldots , m_j, \ldots>\) be an ordered sequence of messages which contains all and only the messages that respect Quality with respect to o and i.Footnote 44 The above equation can then be rewritten as:
Let \(\overrightarrow{U^1_{o,i}}\) be the sequence of numbers that one gets by applying the function \(U^1(\ldots |o,i)\) pointwise to the sequence \({\mathcal {M}}_o\) (i.e. \(\overrightarrow{U^1_{o,i}}= <U^1(m_1|o, i), \ldots , U^1(m_j|o,i), \ldots>\))
Then Eq. 3 can be rewritten as follows (when m respects Weak Quality with respect to o and i):

Consider now Eq. 6, which we repeat here:
For any n, if \(m'\) does not respect Weak Quality with respect to o, \(U^{n+1}(m'|o) = -\infty \) (cf. (A-2-b)), and every term in the sum in the denominator that corresponds to such a message \(m'\) is equal to 0 (exponentiation of \(-\infty \)). With \(\mathcal {M'}_o\) a sequence \(\{m_1,\ldots ,m_j, \ldots \}\) containing all and only the messages that respect Weak Quality with respect to o, we can restrict the sum to the members of \(\mathcal {M'}_o\). Let \(\overrightarrow{U^{n+1}_o}\) be the sequence that one gets by applying the function \(U^{n+1}(\ldots |o)\) pointwise to the sequence \(\mathcal {M'}_o\) (i.e. \(\overrightarrow{U^{n+1}_o}= <U^{n+1}(m_1|o), \ldots , U^{n+1}(m_j|o), \ldots>\)). We have (for m in \(\mathcal {M'}_o\)):

Translation Invariance of SoftMax
Notation: If \(\textbf{x}\) is a sequence of real numbers \(<x_1, \ldots , x_i, \ldots>\) and a is a real number, we notate \(\textbf{x} \oplus a\) the sequence \(<x_1 +a,\ldots , x_i + a, \ldots>\).

Proof
1.4 A.4: Proving the result for \(S^1\)
Recall that \(o_1\) and \(o_2\) are two observations such that \(P_{o_1}\) and \(P_{o_2}\) have the same support.

Proof of the Lemma in (A-6)
Let us assume that m, i and \(o_1\) and \(o_2\) meet the condition stated in (A-6), i.e. that m respects Quality with respect to i and \(o_1\), and with respect to i and \(o_2\).
Let us notate S the support of \(P_{o_1}\) and \(P_{o_2}\). Note that \(P(w|o_1) = 0\) if \(w \notin S\). Furthemore, since m respects Quality with respect to \(o_1\), \(o_2\), and i, then if \(w \in S\), \(\llbracket m \rrbracket ^i(w) = 1\). It follows that we can restrict the sum to the worlds in S (because all the terms in the sum are equal to 0 when w is not in S), and that, having done this, we can remove \(\llbracket m \rrbracket ^i(w)\) from the equation (since \(\llbracket m \rrbracket ^i(w)\) is always equal to 1 when \(w \in S\)). We can therefore continue as follows:
The same formula of course holds for \(o_2\), replacing every occurrence of \(o_1\) with \(o_2\). Given this, when we subtract \(U^1(m | o_1, i)\) from \(U^1(m | o_2, i)\), the terms that depend on m (\(- \log (P(\llbracket m \rrbracket ^i)) - c(m)\)) cancel out, and we get:
As promised, then, this difference does not depend on m or i.

Proof of (A-7)
First consider the case where m does not respect Quality with respect to \(o_1\), \(o_2\), i (again, relative to a fixed i, either it respects Quality for both \(o_1\) and \(o_2\), or for neither, cf. (A-1)). In this case, given the first fact in (A-2), \(S^1(m | o_1, i) = S^1(m | o_2, i) = 0\).
Consider now the case were m respects Quality with respect to \(o_1\), \(o_2\), i. Let us define \(K(o_1, o_2) = \sum \nolimits _{w \in S}P(w | o_2)\log (P(w,o_2)) - \sum \nolimits _{w \in S}P(w | o_1)\log (P(w,o_1))\). From the lemma in (A-6), we have: for every \(m'\) which respects Quality with respect to \(o_1\), \(o_2\), i,
Given that this result holds for all the messages that respect Quality with respect to \(o_1\), \(o_2\) and i (recall that the messages that respect Quality w.r.t. \(o_1\), i are the same as those that respect it w.r.t. \(o_2\), i), it can be restated as follows, using the notations introduced in Sect. 1:Footnote 45
Given (A-3) and Translation Invariance (A-5), we have:
1.5 A.5: Proving the result for \(n \ge 2\)

This will be a proof by induction.
Recall again that \(o_1\) and \(o_2\) are two observations such that \(P_{o_1}\) and \(P_{o_2}\) have the same support.
First, note that if a certain message m does not satisfy Weak Quality with respect to \(o_1\), \(o_2\), then given the second fact in (A-2), for any \(n \ge 2\), \(S^n(m|o_1)= S^n(m|o_2)=0\), so we can now ignore this case and assume for the rest of the proof that m does satisfy Weak Quality with respect to \(o_1\) and \(o_2\) (recall that it either respects it for both or neither, cf. Lemma (A-1)).
1.5.1 A.5.1: Base-Case: \(n =2\)
We start with a counterpart to the Lemma in (A-6).

Proof of (A-9)
Assume that m, \(o_1\) and \(o_2\) meet the condition of the above Lemma. Note that, since \(P_{o_1}\) and \(P_{o_2}\) have the same support, the interpretations i such that m respects Weak Quality with respect to \(o_1\) and i are the same as the interpretations i such that m respects Weak Quality with respect to \(o_2\) and i (cf. Lemma (A-1)). As before, we call S the support of \(P_{o_1}\) and \(P_{o_2}\). We have, given the definitions:Footnote 46
Likewise, we have:
Recall that for every i, \(S^1(m | o_1,i) = S^1(m | o_2, i)\) (Theorem in (A-7)). It follows that the quantities \(\log (\sum \nolimits _{i}P(i)S^1(m | o_1, i))\) and \(\log (\sum \nolimits _{i}P(i)S^1(m | o_2, i))\) are equal. Let us call this quantity X. We can rewrite the above formulae as:
A few lines of computation yield the lemma stated in (A-9):
As promised, this difference does not depend on m.
Using Translation Invariance to prove the base-case (\(n=2\))
To complete the proof for the base case (\(S^2(m|o_1) = S^2(m|o_2)\)), we just need to exploit again the Translation-Invariance property of SoftMax. The computation proceeds in exactly the same way as in the proof of the Theorem in (A-7):
With \(K(o_1, o_2) = \sum \nolimits _{w \in S} P(w | o_2)\log (P(w,o_2)) - \sum \nolimits _{w \in S} P(w | o_1)\log (P(w,o_1))\), we have, for any message m that respects Weak Quality with respect to \(o_1\), \(o_2\), \(U^2(m|o_2) = U^2(m|o_1) + K(o_1, o_2)\).
Since the messages that respect Weak Quality with respect to \(o_1\) and with respect to \(o_2\) are the same, we have:
We therefore have, thanks to Translation Invariance and (A-4):
1.5.2 A.5.2: Inductive step for the Theorem in (A-8)
Recall again that \(P_{o_1}\) and \(P_{o_2}\) have the same support.
Induction Hypothesis: We assume that \(S^n(m | o_2) = S^n(m | o_1)\).
We want to prove that \(S^{n+1}(m| o_2) = S^{n+1}(m | o_1)\).
As before, the key intermediate result is the following:

Proof of (A-10)
We have:
Likewise, we have:
By the induction hypothesis, \(\log (S^n(m | o_2)) = \log (S^n(m | o_1))\). Calling this quantity X, we then have:
The computation then proceeds exactly as in the proof for the Lemma in (A-9)—terms that depend on m cancel out when we take the difference between the two lines, and we so we can conclude the proof of (A-10):
Completing the proof using Translation Invariance
On the basis of (A-10), the proof that \(S^{n+1}(m|o_2) = S^{n+1}(m|o_1)\) proceeds in exactly the same way as in the case of \(n=2\), and boils down to Translation Invariance again.
With \(K(o_1, o_2) = \sum \nolimits _{w \in S} P(w | o_2)\log (P(w,o_2)) - \sum \nolimits _{w \in S} P(w | o_1)\log (P(w,o_1))\), we have, for any message m that respects Weak Quality with respect to \(o_1\), \(o_2\), \(U^{n+1}(m|o_2) = U^{n+1}(m|o_1) + K(o_1, o_2)\).
Since the messages that respect Weak Quality with respect to \(o_1\) and with respect to \(o_2\) are the same, we have:
Given Translation Invariance and (A-4), we have:
This completes the proof of (A-8).
Appendix B: An alternative model for the literal listener
The model presented in Sect. 3.2 was originally derived from a distinct model of the listener that we first came up with, which we present in this appendix for comparison. Although that model makes basically the same qualitative predictions, it is not a Bayesian model, and it makes different quantitative predictions.
Like the Bayesian model, this model assumes that the listener has a probability distribution P over the intervals selected by “around”, and over the possible values some variable x can take. However, the alternative model (written WIR, for Weighted Interpretation Rule) says that the listener’s posterior value of x upon hearing “x is around n”, notated \(L(x = \ldots |\ x\ \text {is around}\ n)\), is the sum of the conditional probabilities that x takes that value given that x belongs to a given interval, weighted by the probability of that interval:Footnote 47
To see the difference with the Bayesian model, recall Eq. BIR, which is reproduced here (with an explicit formula for the proportionality factor):
The two models are distinct. For instance, when P is uniform over values of x as well as over candidate meanings for “around”, the distribution \(L(x = \ldots |\ x\ \text {is around}\ n)\) is distinct from the one depicted in Fig. 2, and it is no longer linear, as represented in Fig. 5.

\(L(x=k|\ x\ \text {is around}\ n)\), with maximum interval [0, 40]
To see more precisely how the two models differ conceptually, the following observation will be useful. Let \(P_{post}\) be the posterior probability distribution resulting from updating P with the “around n” message in the Bayesian model, i.e.:
It can be proved that:
Equation WIR looks almost like BIR’, except that the first term in WIR is weighted by the prior distribution on the values of y (the candidate meanings for “around”) instead of the posterior. This is the sense in which the model proposed in WIR is not Bayesian. Instead of the listener updating also her probability of intervals after hearing “x is around n”, the listener does not make her interval probability depend on that information. The model is not illegitimate for that matter. Regarding our explananda, it makes the same central prediction: this model can be used to derive the Ratio Inequality. If we used this model in order to characterize the literal listener, we could still build an RSA model, in the same way as we did in Sect. 6, and we would derive qualitatively similar predictions.
The proof of BIR’ goes as follows. \(P_{post}\) being a probability distribution, it satisfies, for any k:
Let us develop the first factor in the sum, \(P_{post}(x=k\ |\ y=i)\). Since, in general, \(P_C(A|B) = P(A|B\wedge C)\) [where \(P_C\) is P conditionalized on event C] we have:
Since the random variables x and y are independent, the events \(\ulcorner y=i \urcorner \) and \(\ulcorner x=k \wedge x \in [n-i, n+i] \urcorner \) are independent, thanks to which we can simplify the formula above:
Plugging this equality into the sum above, we get exactly BIR’.
Appendix C: Two alternative RSA models (discussed in Sect. 8)
1.1 C.1. A variant of our model which uses the standard utility function
In our official model, the utility function for the speaker is defined by the following equations, where \(P_o\) is understood to be the posterior distribution over the variable of interest (here notated w, for world) induced by observation o, and \(L^n_m\) is the posterior distribution over w of the level-n listener who has processed a message m. These distributions, importantly, are not joint distributions over w and o.
Develo** the formula for KL-divergence, this is more explicitly cashed out as:
Note that that the second term, \(- \sum \nolimits _w P(w|o) \times \log (P(w|o))\), does not depend on the message m. For this reason it can be dropped: drop** this term amounts to adding a constant term to the utility of each message (relative to a fixed observation o), which has no effect when we apply the SoftMax function in order to derive the speaker’s behavior (Translation Invariance of SoftMax). So we can as well use the following utility function, with no change whatsoever in the behavior of the model:
Now, we can also consider a model whose general architecture is like ours, where the literal listener \(L^0\), in particular, is exactly the same as the one we defined, but where we use the utility function of Bergen et al. (2016), which is based on the KL-divergence between the joint distribution over (w, o) of the level-n listener, and the joint distribution of the speaker which results from an observation o (such a joint distribution assigns probability 0 to all pairs \((w,o')\) where \(o' \ne o\), i.e. \(P(w,o'|o) = P(w|o)\) if \(o'=o\), otherwise \(P(w,o'|o)=0\)).
This amounts to moving to the following utility function, as in Bergen et al. (2016) (ignoring the cost term):
Kee** all the other ingredients of the model presented in Sects. 6 and 7, we obtain, with such a model, numerically different results from those of our main model, but qualitatively similar ones, in the following sense: the pragmatic speaker (at different recursive depths) can have a preference for an “around”-statement over any “between”-statement in some situations where she is able to exclude the peripheral values 0 and 8 (and so could have said, e.g., between 1 and 7) but has a private distribution that is strongly biased towards values closer to 4. Crucially, for this model, the limitation result proved in Appendix A for the standard LU model does not hold.
1.2 C.2. A variant of the LU model where the utility function is as in our own model
We present here a modified LU model. The crucial difference with Bergen et al.’s (2016) LU model shows up in the utility functions (lines 2 and 5), where \(L^0(w,o|m,i)\) and \(L^n(w,o|m)\) have been replaced, respectively, with \(L^0(w|m,i)\) and \(L^n(w|m,i)\), which are themselves equal, respectively, to \(\sum \nolimits _{o'}L^0(w,o'|m,i)\) and \(\sum \nolimits _{o'}L^n(w,o'|m)\).
Importantly, the limitation result reported in Appendix A for the standard LU model no longer holds for this model.
-
1.
\(L^0(w,o | m,i) = \dfrac{P(w,o) \times \llbracket m \rrbracket ^i(w)}{P(\llbracket m \rrbracket ^i)}\)
-
2.
\(U^1(m|o,i) = (\sum \limits _{w}P(w | o) \times \log (L^0(w | m,i))) - c(m)\) \(= (\sum \limits _{w}[P(w | o) \times \log (\sum \nolimits _{o'}L^0(w,o' | m,i))]) - c(m)\)
-
3.
\(S^1(m | o, i) = \dfrac{\exp (\uplambda U^1(m,o,i))}{ \sum \limits _{m'}\exp (\uplambda U^1(m',o,i))}\)
-
4.
\(L^1(w,o | m) = \dfrac{P(w,o)\times \sum \nolimits _{i} P(i)S^1(m | o, i)}{\alpha _1(m)}\), where \(\alpha _1(m) = \sum \nolimits _{w',o'} (P(w',o')\times \) \(\sum \nolimits _{i} P(i)S^1(m | o', i))\)
-
5.
For \(n \ge 1\), \(U^{n+1}(m|o) = \sum \nolimits _w P(w| o)\log (L^n(w | m)) - c(m)\) \(=\sum \nolimits _{w}[P(w | o) \times \log (\sum \nolimits _{o'}L^n(w,o' | m))] - c(m)\)
-
6.
\(S^{n+1}(m | o) = \dfrac{\exp (\uplambda U^{n+1}(m,o))}{\sum \nolimits _{m'} \exp (\uplambda U^{n+1}(m',o))}\)
-
7.
For \(n \ge 2\), \(L^n(w,o | m) = \dfrac{P(w,o) \times S^n(m | o)}{\alpha _n(m)}\), where \(\alpha _n(m) = \sum \nolimits _{w',o'}P(w',o')\times \) \(S^n(m | o')\)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Égré, P., Spector, B., Mortier, A. et al. On the optimality of vagueness: “around”, “between” and the Gricean maxims. Linguist and Philos 46, 1075–1130 (2023). https://doi.org/10.1007/s10988-022-09379-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10988-022-09379-6