
Abstract
Mean-variance portfolios have been criticized because of unsatisfying out-of-sample performance and the presence of extreme and unstable asset weights, especially when the number of securities is large. The bad performance is caused by estimation errors in inputs parameters, that is the covariance matrix and the expected return vector. Recent studies show that imposing a penalty on the 1-norm of the asset weights vector (i.e. \(\ell _{1}\)-regularization) not only regularizes the problem, thereby improving the out-of-sample performance, but also allows to automatically select a subset of assets to invest in. However, \(\ell _{1}\)-regularization might lead to the construction of biased solutions. We propose a new, simple type of penalty that explicitly considers financial information and then we consider several alternative penalties, that allow to improve on the \(\ell _{1}\)-regularization approach. By using U.S.-stock market data, we show empirically that the proposed penalties can lead to the construction of portfolios with an out-of-sample performance superior to several state-of-art benchmarks, especially in high dimensional problems.




Similar content being viewed by others

Notes
Note that sample covariance matrix estimates are singular when \({T\!<\!K}\).
The LASSO relies on imposing a constraint on the \(\ell _{1}\)-norm the regression coefficients. In this paper, \(\ell _{1}\)-regularization is used synonymously.
They claimed that a good penalty function should result in an estimator with three properties: unbiasedness, sparsity, and continuity. They also coined the term oracle property, which, in a nutshell, means that a strategy performs as well as when the true underlying model is known a priori.
This is a very useful approach for practitioners, among whom the so-called 130/30, 120/20, and 110/10 portfolios are very popular. These portfolios consist of, e.g., 130 percent long and 30 percent short positions.
Obviously, \(w8\) abbreviates weighted and \(Las\) LASSO.
It is relatively easy to choose a value for \(\eta \) because it can be directly interpreted as the threshold that determines how large an absolute portfolio weight must (at least) be to be constantly penalized.
The parameter \(\phi \) is simply a very small increment that prevents division by zero.
In the latter case firms were sorted according to the market (ME) and the book-to-market (BE/ME) value to obtain the firm portfolios. The data sets may be downloaded from the homepage of Kenneth French (http://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html), where information on the portfolio construction methods is also provided.
The largest data set consists of 1,036 assets, because in the course of data preparation, penny stocks and series with missing data were excluded.
This is different for the 98 firm portfolios (see the caption of Table 2).
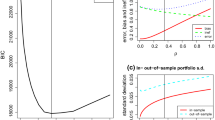
The abscissa denotes the number of active positions instead of the values of \(\lambda \), since the scaling of the latter differs among the penalties.
Note that the latter contain detailed results for five data sets and three covariance matrix estimators. These results do not only support the above findings but also provide various additional insights.
References
Behr P, Guettler A, Truebenbach F (2012) Using industry momentum to improve portfolio performance. J Bank Financ 36(5):1414–1423
Best M, Grauer J (1991) On the sensitivity of mean-variance-efficient portfolios to changes in asset means: Some analytical and computational results. Rev Financ Stud 4(2):315–342
Britten-Jones M (1999) The sampling error in estimates of mean-variance efficient portfolio weights. Ann Oper Res 54(2):655–671
Broadie M (1993) Computing efficient frontiers using estimated parameters. Ann Oper Res 45(1):2158
Brodie J, Daubechies I, DeMol C, Giannone D, Loris D (2009) Sparse and stable Markowitz portfolios. Proc Natl Acad Sci USA 106(30):12267–12272
Candes E, Waking M, Boyed S (2008) Enhancing sparsity by reweighted \(l_{1}\) minimization. J Fourier Anal Appl 14(5):877–905
Carrasco M, Noumon N (2011) Optimal portfolio selection using regularization. Working Paper University of Montreal. Available from http://www.unc.edu/maguilar/metrics/carrasco.pdf
Chan L, Karceski J, Lakonishok J (1999) On portfolio optimization: forecasting covariances and choosing the risk model. Rev Financ Stud 12(5):937–974
DeMiguel V, Garlappi J, Uppal R (2009a) Optimal versus naive diversification: How inefficient is the \(1/n\) portfolio strategy? Rev Financ Stud 22(5):1915–1953
DeMiguel V, Garlappi L, Nogales J, Uppal R (2009b) A generalized approach to portfolio optimization: Improving performance by constraining portfolio norms. Manag Sci 55(5):798–812
DeMiguel V, Nogales F (2009) Portfolio selection with robust estimation. Oper Res 57(3):560–577
Dickinson J (1974) The reliability of estimation procedures in portfolio analysis. J Financ Quant Anal 9(3):447–462
Fan J, Li R (2001) Variable selection via nonconcave penalized likelihood and its oracle properties. J Am Stat Assoc 96(456):1348–1360
Fan J, Zhang J, Yu K (2012) Vast portfolio selection with gross exposure constraints. J Am Stat Assoc 107(498):592–606
Fastrich B, Paterlini S, Winker P (2014) Cardinality versus \(q\)-norm constraints for index tracking. Quantitative Finance 14(11):2019–2032
Fernandes M, Rocha G, Souza T (2012) Regularized minimum-variance portfolios using asset group information, pp 1–28. Available from http://webspace.qmul.ac.uk/tsouza/index_arquivos/Page497.htm
Fernholz R, Garvy R, Hannon J (1998) Diversity weighted indexing. J Portf Manag 24(2):74–82
Figueirdo M, Nowak R, Wright S (2007) Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problems. IEEE J Sel Top Signal Process 1(4):586–596
Frank I, Friedman J (1993) A statistical view of some chemometrics regression tools. Technometrics 35(2):109–135
Frankfurter G, Phillips H, Seagle J (1971) Portfolio selection: the effects of uncertain means, variances, and covariances. J Financ Quant Anal 6(5):1251–1262
Frost P, Savarino J (1988) For better performance: constrain portfolio weights. J Portf Manag 15(1):29–34
Fu J (1998) Penalized regression: the bridge versus the lasso. J Comput Graph Stat 7(3):397–416
Gasso G, Rakotomamonjy A, Canu S (2009) Recovering sparse signals with a certain family of nonconvex penalties and DC programming. IEEE Trans Signal Process 57(12):4686–4698
Giomouridis D, Paterlini S (2010) Regular(ized) hedge funds. J Financ Res 33(3):223–247
Hoerl A, Kennard R (1970) Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12(1):55–67
Jagannathan R, Ma T (2003) Risk reduction in large portfolios: Why imposing the wrong constraints helps. J Financ 58(4):1651–1683
Jobson J, Korkie R (1980) Estimation for Markowitz efficient portfolios. J Am Stat Assoc 75(371):544–554
Jorion P (1986) Bayes-Stein estimation for portfolio analysis. J Financ Quant Anal 21(3):279–292
Knight K, Fu W (2000) Asymptotics for lasso-type estimators. Ann Stat 28(5):1356–1378
Ledoit O, Wolf M (2003) Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. J Empir Financ 10(5):603–621
Markowitz H (1952) Portfolio selection. J Financ 7(1):77–91
Merton R (1980) On estimating the expected return on the market: an exploratory investigation. J Financ Econ 8(4):323–361
Tibshirani R (1996) Regression shrinkage and selection via the Lasso. R Stat Soc 58(1):267–288
Weston J, Elisseeff A, Schölkopf B (2003) Use of the zero-norm with linear models and kernel methods. J Mach Learn Res 3:1439–1461
Yen Y-M (2010) A note on sparse minimum variance portfolios and coordinate-wise descent algorithms, pp 1–27. Available from http://papers.ssrn.com/sol3/papers.cfm?abstract_id=1604093
Yen Y-M, Yen T-J (2011) Solving norm constrained portfolio optimizations via coordinate-wise descent algorithms, pp 1–41. Available from http://personal.lse.ac.uk/yen/sp_090111.pdf
Zou H (2006) The adaptive lasso and its oracle properties. J Am Stat Assoc 101(476):1418–1429
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Fastrich, B., Paterlini, S. & Winker, P. Constructing optimal sparse portfolios using regularization methods. Comput Manag Sci 12, 417–434 (2015). https://doi.org/10.1007/s10287-014-0227-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-014-0227-5