
Abstract
Sensors have different perceptive abilities against environment. Sensor fusion plays a crucial role at achieving better perception by accumulating the information acquired at different times. But, the decision of the observation may conflict with each other due to usage of different algorithms, thresholds on processing algorithms, and different perceptive character of sensors. This study presents the late fusion method applied to outputs provided by deep learning models fed by camera and lidar sensor’s measurement data. For camera sensor, a deep learning model as a multi-task network is proposed to multi-classify cars, motorcycles, bicycles, buses, trucks, and pedestrians under the category of dynamic traffic objects. In addition, color classified traffic lights and traffic signs with a capability of segmenting drivable area and detecting lane lines are classified under the category of static traffic objects. The proposed multi-network is trained and tested with the BDD100K dataset and benchmarked with publicly available multi-networks. The presented method is the second fastest multi-network reaching at 52 FPS runtime, ranked second based on the drivable area segmentation and lane line detection performance. For segmentation of dynamic objects, the network performance is increased by 22.45%, and considering mIoU overall performance increase is 3.96%. For a lidar sensor, a different modality is presented to detect objects. Two sensors’ data are fused by proposed fusion algorithm, and results are tested and evaluated with the KITTI dataset. The proposed fusion methodology outperforms the stand-alone lidar methods about 3.58% and 3.63% on BEV and 3D detection MAP, respectively. Overall, benchmarking with two distinct fusion approaches illustrates the effectiveness of the proposed method.























Similar content being viewed by others
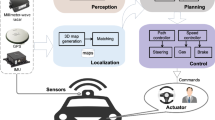


Data availability
Data used in this study are open. The data used to train our camera multi-segmentation network are available for download from the Berkeley Deep Drive Dataset [45], 100K Images repository at https://doi.org/10.1109/cvpr42600.2020.00271. Data used for camera and lidar fusion evaluation are available for download from the KITTI dataset [7] at https://doi.org/10.1109/CVPR.2012.6248074.
References
Buslaev A, Iglovikov VI, Khvedchenya E et al (2020) Albumentations: fast and flexible image augmentations. Information 11(2):125
Charles R, Su H, Kaichun M et al (2017) Pointnet: deep learning on point sets for 3d classification and segmentation. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 77–85. https://doi.org/10.1109/CVPR.2017.16
Chen LC, Zhu Y, Papandreou G et al (2018) Encoder–decoder with atrous separable convolution for semantic image segmentation. In: Ferrari V, Hebert M, Sminchisescu C et al (eds) Computer vision—ECCV 2018. Springer International Publishing, Cham, pp 833–851
Chen X, Ma H, Wan J et al (2017) Multi-view 3d object detection network for autonomous driving. In: 2017 IEEE conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 6526–6534. https://doi.org/10.1109/CVPR.2017.691
Cordts M, Omran M, Ramos S et al (2016) The cityscapes dataset for semantic urban scene understanding. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 3213–3223. https://doi.org/10.1109/CVPR.2016.350
Dai J, Li Y, He K et al (2016) R-fcn: object detection via region-based fully convolutional networks. In: Proceedings of the 30th international conference on neural information processing systems. Curran Associates Inc., Red Hook, NY, USA, NIPS’16, pp 379–387
Geiger A, Lenz P, Urtasun R (2012) Are we ready for autonomous driving? The Kitti vision benchmark suite. In: 2012 IEEE conference on computer vision and pattern recognition, pp 3354–3361. https://doi.org/10.1109/CVPR.2012.6248074
Girshick R, Donahue J, Darrell T et al (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: 2014 IEEE Conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 580–587, https://doi.org/10.1109/CVPR.2014.81
Han C, Zhao Q, Zhang S et al (2022) Yolopv2: better, faster, stronger for panoptic driving perception. ar**v preprint ar**v:2208.11434
He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR), pp 770–778. https://doi.org/10.1109/CVPR.2016.90
Hou Y, Ma Z, Liu C et al (2019) Learning lightweight lane detection cnns by self attention distillation. In: 2019 IEEE/CVF international conference on computer vision (ICCV). IEEE Computer Society, Los Alamitos, CA, USA, pp 1013–1021, https://doi.org/10.1109/ICCV.2019.00110
Kirillov A, Mintun E, Ravi N et al (2023) Segment anything. ar**v preprint ar**v:2304.02643
Ku J, Mozifian M, Lee J et al (2018) Joint 3d proposal generation and object detection from view aggregation. In: 2018 IEEE/RSI international conference on intelligent robots and systems (IROS), pp 1–8. https://doi.org/10.1109/IROS.2018.8594049
Lang AH, Vora S, Caesar H et al (2019) Pointpillars: fast encoders for object detection from point clouds. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 12689–12697. https://doi.org/10.1109/CVPR.2019.01298
Liang M, Yang B, Chen Y et al (2019) Multi-task multi-sensor fusion for 3d object detection. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 7337–7345. https://doi.org/10.1109/CVPR.2019.00752
Lin TY, Goyal P, Girshick R et al (2020) Focal loss for dense object detection. IEEE Trans Pattern Anal Mach Intell 42(2):318–327. https://doi.org/10.1109/TPAMI.2018.2858826
Liu L, Jiang H, He P et al (2019) On the variance of the adaptive learning rate and beyond. ar**v preprint ar**v:1908.03265
Liu W, Anguelov D, Erhan D et al (2016) Ssd: single shot multibox detector. In: Leibe B, Matas J, Sebe N et al (eds) Computer vision—ECCV 2016. Springer International Publishing, Cham, pp 21–37
Liu Z, Lin Y, Cao Y et al (2021) Swin transformer: hierarchical vision transformer using shifted windows. In: 2021 IEEE/CVF international conference on computer vision (ICCV). IEEE Computer Society, Los Alamitos, CA, USA, pp 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986
Liu Z, Mao H, Wu CY et al (2022) A convnet for the 2020s. In: 2022 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 11966–11976. https://doi.org/10.1109/CVPR52688.2022.01167
Organization WH (2018) Global status report on road safety. https://www.who.int/publications/i/item/9789241565684
Pan X, Shi J, Luo P et al (2018) Spatial as deep: spatial cnn for traffic scene understanding. In: Proceedings of the thirty-second AAAI conference on artificial intelligence and thirtieth innovative applications of artificial intelligence conference and eighth AAAI symposium on educational advances in artificial intelligence. AAAI Press, AAAI’18/IAAI’18/EAAI’18
Pang S, Morris D, Radha H (2020) Clocs: camera-lidar object candidates fusion for 3d object detection. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE Press, pp 10386–10393. https://doi.org/10.1109/IROS45743.2020.9341791
Qi CR, Liu W, Wu C et al (2018) Frustum pointnets for 3d object detection from rgb-d data. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 918–927. https://doi.org/10.1109/CVPR.2018.00102
Qian Y, Dolan JM, Yang M (2020) Dlt-net: joint detection of drivable areas, lane lines, and traffic objects. IEEE Trans Intell Transp Syst 21(11):4670–4679. https://doi.org/10.1109/TITS.2019.2943777
Radosavovic I, Kosaraju RP, Girshick R et al (2020) Designing network design spaces. In: 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 10425–10433. https://doi.org/10.1109/CVPR42600.2020.01044
Ranftl R, Bochkovskiy A, Koltun V (2021) Vision transformers for dense prediction. ar**v:2103.13413
Redmon J, Divvala S, Girshick R et al (2016) You only look once: unified, real-time object detection. In: 2016 IEEE conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 779–788. https://doi.org/10.1109/CVPR.2016.91
Russakovsky O, Deng J, Su H et al (2015) Imagenet large scale visual recognition challenge. Int J Comput Vis 115:211–252
Shi S, Wang X, Li H (2019) Pointrcnn: 3d object proposal generation and detection from point cloud. In: 2019 IEEE/CVF conference on computer vision and pattern recognition (CVPR), pp 770–779. https://doi.org/10.1109/CVPR.2019.00086
Shi S, Guo C, Jiang L et al (2020) Pv-rcnn: point-voxel feature set abstraction for 3d object detection. In: 2020 IEEE/CVF conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 10526–10535. https://doi.org/10.1109/CVPR42600.2020.01054
Shi S, Wang Z, Shi J et al (2021) From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Trans Pattern Anal Mach Intell 43(08):2647–2664. https://doi.org/10.1109/TPAMI.2020.2977026
Singh S (2015) Critical reasons for crashes investigated in the national motor vehicle crash causation survey
Sudre CH, Li W, Vercauteren T et al (2017) Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In: Cardoso MJ, Arbel T, Carneiro G et al (eds) Deep learning in medical image analysis and multimodal learning for clinical decision support. Springer International Publishing, Cham, pp 240–248
Tan M, Le Q (2019) Efficientnet: rethinking model scaling for convolutional neural networks. In: International conference on machine learning, PMLR, pp 6105–6114
Team OD (2020) Openpcdet: an open-source toolbox for 3d object detection from point clouds. https://github.com/open-mmlab/OpenPCDet
Teichmann M, Weber M, Zollner M et al (2018) Multinet: real-time joint semantic reasoning for autonomous driving. In: 2018 IEEE intelligent vehicles symposium (IV), pp 1013–1020. https://doi.org/10.1109/IVS.2018.8500504
Vora S, Lang AH, Helou B et al (2020) Pointpainting: sequential fusion for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 4604–4612
Vu D, Ngo B, Phan HN (2022) Hybridnets: end-to-end perception network. Ar**v abs/2203.09035. https://api.semanticscholar.org/CorpusID:247518557
Wang Z, Jia K (2019) Frustum convnet: sliding frustums to aggregate local point-wise features for amodal 3d object detection. In: 2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), pp 1742–1749. https://doi.org/10.1109/IROS40897.2019.8968513
Wu D, Liao MW, Zhang WT et al (2022) Yolop: you only look once for panoptic driving perception. Mach Intell Res 19(6):550–562
Xu D, Anguelov D, Jain A (2018) Pointfusion: deep sensor fusion for 3d bounding box estimation. In: 2018 IEEE/CVF conference on computer vision and pattern recognition, pp 244–253. https://doi.org/10.1109/CVPR.2018.00033
Yan Y, Mao Y, Li B (2018) Second: Sparsely embedded convolutional detection. Sensors. https://doi.org/10.3390/s18103337
Yu C, Gao C, Wang J et al (2021) Bisenet v2: bilateral network with guided aggregation for real-time semantic segmentation. Int J Comput Vis 129(11):3051–3068. https://doi.org/10.1007/s11263-021-01515-2
Yu F, Chen H, Wang X et al (2020) Bdd100k: a diverse driving dataset for heterogeneous multitask learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 2636–2645
Zhou Y, Tuzel O (2018) Voxelnet: end-to-end learning for point cloud based 3d object detection. In: 2018 IEEE/CVF conference on computer vision and pattern recognition (CVPR). IEEE Computer Society, Los Alamitos, CA, USA, pp 4490–4499. https://doi.org/10.1109/CVPR.2018.00472
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Çaldıran, B.E., Acarman, T. Late sensor fusion approach with a designed multi-segmentation network. Neural Comput & Applic (2024). https://doi.org/10.1007/s00521-024-10004-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00521-024-10004-9