
Abstract
Effective vectorization is becoming increasingly important for high performance and energy efficiency on processors with wide SIMD units. Compilers often require programmers to identify opportunities for vectorization, using directives to disprove data dependences. The OpenMP 4.x SIMD directives strive to provide portability. We investigate the ability of current compilers (GNU, Clang, and Intel) to generate SIMD code for microbenchmarks that cover common patterns in scientific codes and for two kernels from the VASP and the MOM5/ERGOM application. We explore coding strategies for improving SIMD performance across different compilers and platforms (Intel® Xeon® processor and Intel® Xeon Phi™ (co)processor). We compare OpenMP* 4.x SIMD vectorization with and without vector data types against SIMD intrinsics and C++ SIMD types. Our experiments show that in many cases portable performance can be achieved. All microbenchmarks are available as open source as a reference for programmers and compiler experts to enhance SIMD code generation.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
On modern CPUs, effective use of SIMD (Single Instruction, Multiple Data) is essential to approach peak performance. Data parallelism is achieved with a combination of multiple threads and increasingly-wide SIMD units. On the Intel® Xeon Phi™ (co)processor, for instance, the 8-wide double-precision SIMD units can provide up to one order of magnitude higher performance per core. Exploiting SIMD for codes with complex control flow, leading to masking and execution overhead, can be difficult. In some cases, unleashing the full performance potential of computational loops can require expertise in language interfaces, compiler features, and microarchitecture.
Thankfully, the community is converging on a vectorization standard, in OpenMP 4.x, that eases the programming burden. Just as OpenMP has historically provided a way for users to direct execution to be parallelized across threads, it now provides ways to parallelize across SIMD lanes by means of compiler directives. The latter are necessary to disambiguate dependences among loop iterations and communicate vectorization opportunities to the compiler. Our analysis shows that it can yield effective results.
This paper assesses the SIMD capabilities of the current GNU, Clang, and Intel compilers and makes the following contributions: (1) We show limitations of compiler-driven SIMD code generation, and (2) propose coding strategies both to remedy SIMD vectorization issues and to gain SIMD performance in a portable way using OpenMP 4.x. (3) We demonstrate the effectiveness of our SIMD coding strategies for microbenchmarks and two real-world kernels from the VASP and MOM5/ERGOM application.
2 Related Work
The development of techniques to transform (sequential) loop structures into parallelized constructs became a major concern with the arrival of vector and array computer systems in the 1980s. Parafrase [1], KAP [2, 3], PFC [4], and VAST [5] are well-known examples of source code transformation tools at that time. To our knowledge, most of the work targets the transformation of complex loop structures into SIMD code, resulting in alternatives to standard compilers. Our approach, however, is to follow a set of SIMD coding schemes that leverage standards and foster portability across compilers. EXPAND [6] is a research compiler which implements an expansion approach. It targets a whole C function which is semantically transformed by replacing operators and operands with their SIMD equivalents. For twelve intrinsic functions of the GNU math library, speedups range from 2x to 11x on a PowerPC G5. Scout [7] is a configurable C source-to-source translator that generates code with SIMD intrinsics. Vectorization and other optimizations take place at the level of the syntax tree generated by the Clang parser. After basic optimizations, e. g., function inlining, the unroll-and-jam technique is applied to vectorize the loop body. For selected CFD kernels, speedups range from 1.5x to 4x on 8 AVX SIMD lanes (Sandy Bridge). Unlike EXPAND and Scout, our vectorization strategy, which includes the expansion step as well, further includes vectorization of nested loops and deep calling trees, as we demonstrate using the VASP and the MOM5/ERGOM codes. Furthermore, our strategy applies high-level code transformations to achieve portability across platforms and applicability across programming languages. The Whole-Function Vectorization (WFV) algorithm [8] transforms a scalar function into multiple parallel execution paths using SIMD instructions. WFV can provide a language- and platform-independent code transformation at the level of the LLVM IR. In a rendering system, they achieve up to 3.9x speedup on 4 SIMD lanes.
3 SIMD Vectorization
In this section, we show the impact of using different forms of the OpenMP 4.x constructs. Due to the considered architectures and for simplicity, we interchangeably use the terms SIMD vector and vector in the following.
3.1 Compiler and Library Support for SIMD Vectorization
No matter how aggressive compilers are at SIMD vectorization, they have fundamental theoretical limitations (cf. Rice’s Theorem [9]). Compilers perform code analysis to disprove loop dependences [10, 11], and attempt vectorization only if code generation for SIMD-capable targets is selected, if aggressive optimization levels are enabled, and if it is safe. We use the following configurations: GNU GCC 5.3 and Clang 3.9 (from SVN repository) compiler: -O3 -ftree-vectorize -ffast-math -mavx2 -mfma; Intel 16.0.3 compiler: -O3 -fp-model fast=2 -xcore-avx2; for the Intel Xeon Phi (coprocessor) -mmic (Knights Corner, KNC) and -xmic-avx512 (Knights Landing, KNL) is used instead of -xcore-avx2, respectively. Optimizing math functions like exp and sqrt is important since they often account for a significant fraction of computational time. Scalar versions of those functions are typically provided by system math libraries like libm, and vector versions are commonly available in modern compilers. They extend their scalar equivalents by using SIMD vectors rather than scalars. Their semantics are mostly the same, except for error and exception handling, and accuracy. The availability of such math vector functions depends on the compiler and underlying architecture. The configurations used in this paper are: GNU GCC 5.3 with libmvec (GLIBC 2.22) [12], and Intel compiler 16.0.3 with SVML (Short Vector Math Library) [13]. libmvec and SVML contain different sets of vectorized math functions [14, 15]. GCC restricts calls into libmvec to within OpenMP SIMD constructs only, whereas the Intel Compiler uses SVML for any vectorized code.
3.2 OpenMP 4.x SIMD Directives
If compilers fail in vectorizing loop bodies, programmers need to give additional information to the compiler, e. g., by means of directives, which we call explicit vectorization, or by going to the extreme of low-level programming using C SIMD intrinsics, to override conservatism induced by language standards. If a loop body contains calls to functions that the compiler cannot directly generate SIMD code for (like libmvec or SVML), it has to fall back to invoking these functions once per SIMD lane, and it must pack and unpack data into and out of SIMD registers. Providing a SIMD-enabled function reduces calling overhead, increases parallelism, and avoids path length increases, yielding better overall performance. The OpenMP 4.x specification standardizes directives that are consistently implemented across different compilers. The simd construct forces loops to be vectorized, and the declare simd directive creates SIMD-enabled functions, according to a well-defined ABI [16]. A simple example could be:

The simd construct instructs the compiler to partition the set of iterations of the loop into chunks of appropriate size so as to match with the SIMD capabilities of the processor. With optional clauses, programmers can specify additional properties and transformations of the loop code, e. g., privatization and reductions, that allow loop iterations to be executed independently in SIMD lanes. In the example, we explicitly define the vector length to be four with clause simdlen(4), and inform the compiler that both arrays x and y are already aligned to 32 bytes.
The declare simd directive augments function definitions and function declarations. Functions tagged with the directive are vectorized by promoting the formal function arguments and the return value (if any) into vector arguments. This was first introduced with Intel® Cilk™ Plus, known as vector_variant or vector attribute [17], but unlike OpenMP 4.x, it is not a standard. Programmers may override this behavior to retain scalar arguments that are broadcast to fill a vector with clause uniform, or express loop-carried dependences that have a linear progression with clause linear. That way, vectorizable loops can invoke suitable vector versions of functions by passing vector registers as arguments.
Table 1 illustrates the effect of adding optional clauses to an OpenMP SIMD (SIMD-enabled) function for our “simple” microbenchmark (see Sect. 5.1), encapsulating the log function. As can be seen, giving the compiler more information about the intended usage and properties of the function arguments helps generate better vectorized code for the function. More information about the full capabilities of the OpenMP 4.x SIMD feature can be found in [18].
4 Coding Strategies to Gain SIMD Performance
Our observation when writing code for execution on SIMD units is that compiler capabilities vary dramatically when codes are not designed with SIMD in mind from the very beginning. It is obvious that programmers need a (portable) SIMD coding scheme that different compilers can equally understand and generate code for. In this paper, we focus on SIMD vectorization of functions or subroutines as these are the most complex and complicated cases in getting performance. Our premise is that any loop body can be viewed as an inlined call to a function that contains the loop body:

In the following, our discussion focuses on the OpenMP 4.x declare simd construct introduced in Sect. 3.2, which is simple to use for whole function vectorization. But it lacks a mechanism to explicitly switch back to scalar execution within a SIMD function, e. g., when library calls are present. Furthermore, only the GNU and Intel compiler currently support it. The latest Clang compiler, version 3.9, ignores the directive. The next paragraphs describe how to work around these issues.
(General) SIMD functions: To enhance what is provided by the simd declare directive, and to potentially enable SIMD functions with the Clang compiler in a way that also applies to Fortran code, we propose the following high-level code transformation scheme, given a scalar definition of function foo:
-
(1)
Define vector and mask data types, e. g.,

where SIMDLEN_LOGICAL_REAL64 is a multiple of the hardware’s native SIMD vector length or vector width.
-
(2)
Replace all scalar function arguments by vector arguments for the SIMD equivalent vfoo and introduce a masking argument m to allow calling vfoo conditionally, e. g.,
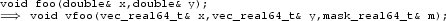
-
(3)
Within vfoo, vector arguments are processed by extending foo’s function body with a SIMD loop with the adjusted trip count. Accesses to scalar arguments in foo are replaced by accessing the components of vfoo’s vector arguments instead:

-
(4)
At the call site, split the SIMD loop candidate into chunks of size SIMDLEN_LOGI CAL_REAL64 by changing the loop increment accordingly, and if necessary introduce a prolog and an epilog for vector un-/packing after/before the call to vfoo, e. g.,


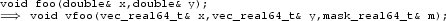


Splitting SIMD loops that are inside SIMD functions into parts enables mixing vectorizable parts and unvectorizable serialized parts. The major differences with explicit vectorization are (1) we use the “standard” omp simd on a for loop over the vector length, (2) we use vector data types as arguments to a function created from the loop body to enable nesting, and (3) we use masking to facilitate conditional execution for branching and early exits. Hereafter, we refer to this coding scheme as “enhanced explicit vectorization” to emphasize its distinction to “explicit vectorization” with OpenMP 4.x SIMD functions.
Branching: SIMD execution with divergent control flow happens because of branches whose predicates evaluate differently across the SIMD lanes. This can be handled by using masked vector operations, if supported by the vector instruction set. Masks signal whether each SIMD lane is “active” or “inactive” for a given execution. Control flow can also be handled with a sequence of consecutive branches, and unmasked operations followed by blend operations. If more than one branch is taken, the effective speedup due to SIMD execution reduces with the costs and the number of the branches. Figure 1 illustrates the scalar and SIMD execution of a loop containing an if-else branch. Throughout iterations 0..3, both the if and the else branch is taken. Assuming they are equally expensive, the speedup over scalar execution is at most 2x for these iterations.

Scalar and SIMD vector execution of a loop containing an if-else branch using 4 SIMD lanes. Lanes for which the vector mask is “inactive” are marked by crosses.
Depending on the compiler’s strategy for handling conditional code execution, it can be meaningful to reduce vector masks beforehand to avoid unnecessary operations, e. g., “expensive” math calls. If, for instance, a predicate initiating the execution of a code section evaluates to false on all SIMD lanes, the entire section can be skipped:

Local copies of frequently-accessed memory references: Loops containing frequent access to the same memory reference(s) should be transformed such that memory loads happen just once into SIMD lanes. These local copies then should be used instead of referencing memory, thereby lowering the number of load operations and potentially increasing the performance.
Arrays on SIMD lanes (SIMD function context): Local arrays with size [d] in the scalar code need to be expanded to two-dimensional arrays of size [d][“SIMD width”] in the SIMD case, where the first dimension is contiguous in main memory. Unfortunately, the (Intel) compiler does not manage to optimize for the desired data layout. Currently, the only high-level approach to solve that issue is manual privatization of the array—Intel specific—or using the enhanced explicit vectorization scheme:
-
(a)
The compiler does not optimize for the desired data layout: scatter is generated.
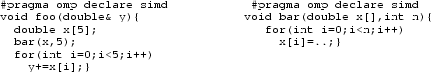
-
(b)
Using “enhanced explicit vectorization:” it works out of the box.

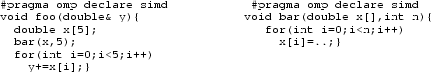

Loops on SIMD lanes: Loops within a SIMD context can be challenging to optimize for an effective execution. If the loop trip count is a constant, each SIMD lane performs the same number of loop iterations causing no load imbalances across the lanes. If it is not, and the loop terminates differently from lane to lane, SIMD utilization might be worse. One solution to that issue is implementing dynamic SIMD scheduling, where lanes are dynamically assigned outstanding loop iterations if there are any [19]. However, here, we simply describe how to manage loops on SIMD lanes with enhanced explicit vectorization (the SIMD loop is placed inside the while loop):

Manual vectorization with SIMD intrinsics and C++ SIMD classes: A very low-level approach to writing SIMD code is using intrinsic functions. This approach gives the programmer maximum control and flexibility without having to rely on the compiler’s vectorization capabilities. On the downside, the code is hard to write and not portable, as the intrinsics are specific to a certain SIMD extension (e.g. SSE, AVX, AVX2).
A higher-level approach to manual vectorization is encapsulating intrinsics in C++ classes and overloaded operators. The main abstraction is a vector type, e. g., double_v, that offers operators for element-wise operations. Together with a query-able vector width, this allows for portable SIMD code that is valid within the C++ language. All conditional coding paths and potential remainder situations need to be handled through masking, potentially with multiple versions of a function, or blocks of code, that check for an empty, a full or a mixed mask to avoid unnecessary operations. This leads to a trade-off between performance and redundant code. We use Vc [20] for our microbenchmarks, as it provides an API with masking support and vector math-functions.
Masked math calls: We are aware only of the Intel compiler supporting conditional math function calls through SVML. However, an explicit SVML interface is missing. Instead unmasked calls need to be followed by a vector blend operation. For inactive SIMD lanes it is important to input values to these calls that assure fast convergence without causing floating point exceptions. We observed significant performance gains, when assigning, e. g., 1.0 to inactive SIMD lanes before calling exp unconditionally.
Source-to-source code translation: The coding scheme and SIMD optimizations presented in this section can be simply integrated into a source-to-source translator. As a proof-of-concept, we built a prototype of such a tool that allows automatic SIMD code generation for our microbenchmarks (Sect. 5.1) using enhanced explicit vectorization.
5 Microbenchmarks and Real-World Codes
To demonstrate the effectiveness of the proposed SIMD coding schemes, we use a combination of microbenchmarks and real-world kernels. The performance has been evaluated for: (1) auto-vectorized reference, (2) explicit vectorization, (3) enhanced explicit vectorization, (4) SIMD intrinsics, and (5) Vc (C++ SIMD class) library.
5.1 Microbenchmarks
Our microbenchmarks are minimal, directed tests that represent common patterns in real-world codes: (a) simple math function call, (b) conditional math function call, (c) conditional return, (d) nested branching with math function calls inside the branches, and (e) loop on SIMD lanes with varying trip count. Besides the reference implementations, we provide versions using OpenMP 4.x SIMD functions, the enhanced explicit vectorization scheme, SIMD intrinsics, and C++ SIMD class vectorization. Additionally, our implementations use OpenMP threading to run multiple instances of the benchmark concurrently. All versions can be found online [21].
Benchmarking setup: All microbenchmarks have been executed on an Intel Xeon E5-2680v3 CPU (Haswell),Footnote 1 an Intel Xeon Phi 7120P (KNC) coprocessor, and an Intel Xeon Phi 7210 (KNL) processor.

For all benchmarks we use arrays of 8192 double-precision random numbers chosen uniformly over \([-1.0,+1.0]\)—in all cases we use exactly the same random numbers. With \(x_1\), \(x_2\), and y as input and output for the kernels, respectively, this results in 192 KiB data per kernel instance, which on both CPU and KNC/KNL fits into the per-core data cache. That allows us to focus on core performance, rather than diluting vectorization effectiveness results with caching effects. All kernels are called conditionally to reflect a realistic calling context as found in applications, which prevents compiler optimizations on fully occupied masks. The number of OpenMP threads, and hence kernel instances, used for benchmarking has been chosen to use all cores in the package: 12 on Haswell, 120 on KNC (due to 2-cycle decode), and 64 on KNL.
Each benchmark setup has been executed 10 times for statistics, where the first 4 runs were skipped (warmup). For all runs, we found the maximum absolute relative error across all array elements to be less than \(10^{-14}\) off compared to the scalar reference, showing the correctness of our implementations. Execution times for all five microbenchmarks calling exp within their function bodies are illustrated in Fig. 2. We only show results for selected runs, where simdlen=x with x=8 on Haswell and x=16 in KNC and KNL, respectively. All benchmark results is available online.

On the Haswell platform, explicit vectorization gives acceptable performance only with the Intel compiler. GNU achieves only little success and none for Clang. Clang works only with the C++ SIMD classes and has no equivalent of libmvec or SVML, while Vc implements its own SIMD math functions. Using enhanced explicit vectorization, the performance gets close to SIMD intrinsics with both the Intel and GNU compiler. In some cases it is superior to intrinsics. Even though Clang benefits from enhanced explicit vectorization, it cannot compete with GNU and Intel. On KNC, enhanced explicit vectorization is on a par with explicit vectorization and SIMD intrinsics. On KNL, it ranges between the two.
Except for the while loop kernel, SIMD execution gives speedups between 2x and 4x on Haswell, and up to 2.5x on KNC and KNL. It is somehow surprising that the effect of vectorization is more visible on Haswell than on KNC and KNL. We found that using simdlen=8 on Haswell results in a major performance gain over using simdlen=4, as is the native SIMD width on that platform when 64-bit words are processed. On KNC/KNL, however, going from simdlen=8 to 16 gives only a slight performance increase. For the while loop kernel the performance gain due to SIMD execution is notable on Haswell only when enhanced explicit vectorization is used together with the Intel compiler, on KNC in all cases except Vc, and on KNL only with intrinsics.
We further found that while Intel successfully vectorized all kernels, it is not able to vectorize through the Vc’s C++ SIMD class abstraction layers. With the GNU and Clang compiler, we did not observe this behavior, but found Vc be a bit slower than manual vectorization with intrinsics.

Runtimes of the five microbenchmarks for different SIMD coding strategies using the GNU, Clang, and Intel compiler on Haswell, and Intel Xeon Phi KNC and KNL. The per-thread work-load is the same for each architecture. Vc on KNL uses AVX2, as AVX512 is not implemented yet.
5.2 Real-World Codes
In this subsection, we demonstrate the effectiveness of the enhanced explicit vectorization scheme when used within two real-world applications, VASP and MOM5/ERGOM. Both of these are Fortran codes, where SIMD can only be introduced via high-level programming—SIMD intrinsics and C++ SIMD classes are not directly accessible. Moreover, the community tends to avoid mixing Fortran and C/C++.
VASP 5 [22, 23] is a well-known program for atomic scale materials modeling, e. g., electronic structure calculations and quantum-mechanical molecular dynamics from first principles. One of the computational hotspots is the calculation of electronic properties on a grid by means of a hybrid DFT functional. SIMD vectorization over the grid points includes a calling tree with subroutines which themselves contain a combination of nested branching together with conditional function calls and loops with low trip counts. Vectorization of the grid loop hence means vectorization along the calling tree, which requires the SIMD function feature. The integration of enhanced explicit vectorization mainly consisted of a simple scalar-vector replacement of variables that serve as input and output parameters of the relevant functions. Loops within these functions have been annotated with the novector directive, to deactivate compiler vectorization as the execution already happens in the SIMD context. Local arrays within the function bodies have been expanded to two-dimensional arrays as described in Sect. 5.1. As a result of these adaptions, we have the SIMD vector code at hand, which is beneficial for code debugging—this is not the case with explicit vectorization. In fact, we used the enhanced explicit vectorization code to trace (and eventually fix) faulty program outputs of the initial code base with explicit vectorization to an incorrect expansion of local array definitions.
MOM [24] (Modular Ocean Model) is a program to perform numerical ocean simulations that is utilized for research and operations from the coasts to the globe. With ERGOM (Ecological Regional Ocean Model), MOM is extended by a bio-geochemical model that incorporates the nitrogen and phosphorus cycle. Within the ERGOM module, this cycle is modeled by numerical integration of a rate equation using an Euler integrator. The latter is at the core of a loop over grid points (hotspot), and happens to converge differently from one grid point to another, potentially causing imbalances among the SIMD lanes. Vectorization of the Euler integration scheme means to vectorize along a “while loop” which is inside the SIMD loop over grid points.
Unlike the microbenchmarks, VASP and MOM5/ERGOM kernels are much more complex and exhibit a combination of the different patterns described in this paper. For VASP, we found that performance with explicit vectorization using the OpenMP 4.x SIMD declare construct was inhibited by local array definitions within any of the core routines along the calling tree. We achieved better performance with the enhanced explicit vectorization scheme already in the first instance. For MOM5/ERGOM we achieved success with the enhanced explicit vectorization scheme only. With explicit vectorization we observed faulty simulation outputs. Due to the complexity of the hotspot code section—several hundreds of lines of code within the SIMD context—we were not able to figure out the origin of the faulty outputs.
Performance gains for the hotspot sections (not program performance gain) in VASP and MOM5 are summarized in Table 2. The values show that the enhanced explicit vectorization scheme is an effective high-level approach to gaining SIMD performance.
6 Summary
We investigated the vectorization capabilities of current compilers that support OpenMP 4.x: GNU, Clang, and Intel. We focused on SIMD functions, because called library functions that are not inlinable are common and they account for a significant fraction of execution time. For a set of microbenchmarks implementing code patterns usually present in scientific codes, we found that only the Intel compiler is able to generate effective vector versions of scalar function definitions, even in case of irregularities within the calling context and the functions themselves, e. g., branching or loops with dynamic trip counts. As an alternative to OpenMP 4.x SIMD functions, we propose a vector coding scheme, “enhanced explicit vectorization,” that relies on explicit vector data types together with OpenMP 4.x SIMD loop vectorization to process the vectors. Using this coding scheme, both the GNU and the Intel compiler can close up to or even exceed the performance with manual vector coding using SIMD intrinsics or C++ SIMD classes like Vc. Also the Clang compiler benefits from enhanced explicit vectorization, since it lacks the OpenMP SIMD function feature, but stays behind GNU and Intel, because of missing vector math functions. We showed the effectiveness of our approach for the microbenchmarks, and its portability across compilers. We also showed benchmarking results for two real-world codes, VASP and MOM5/ERGOM, where we successfully integrated the enhanced explicit vectorization scheme. We think that despite various findings and issues which occurred during our analysis, OpenMP 4.x provides a sound base for compiler and language independent SIMD vectorization. Combining it with our enhanced explicit vectorization scheme allows more control over compiler vectorization. We expect future compiler versions to improve support of OpenMP 4.x further.
Notes
- 1.
For CPU benchmarks, the core clock frequency has been set to 1.9 GHz (AVX base frequency) to avoid comparing vector runs against scalar runs with overclocked cores.
References
Kuck, D., Kuhn, R., Leasure, B., Wolfe, M.: The structure of an advanced retargetable vectorizer. In: Tutorial on Supercomputers: Designs and Applications, pp. 163–178. IEEE Press, New York (1984)
Davies, I., Huson, C., Macke, T., Leasure, B., Wolfe, M.: The KAP/S-1: an advanced source-to-source vectorizer for the S-l Mark IIa supercomputer. In: Proceedings of the 1986 International Conference on Parallel Processing, pp. 833–835. IEEE Press, New York (1986)
Davies, I., Huson, C., Macke, T., Leasure, B., Wolfe, M.: The KAP/205: an advanced source-to-source vectorizer for the Cyber 205 supercomputer. In: Proceedings of the 1986 International Conference on Parallel Processing, pp. 827–832. IEEE Press, New York (1986)
Allen, J., Kennedy, K.: PFC: A program to convert Fortran to parallel form. Report MASC-TR82-6, Rice Univ. Houston, Texas, March 1982
Brode, B.: Precompilation of Fortran programs to facilitate array processing. Computer 14(9), 46–51 (1981)
Shin, J.: SIMD Programming by Expansion. Technical report, Mathematics and Computer Science Division, Argonne National Laboratory Argonne, IL 60439 USA (2007). http://www.mcs.anl.gov/papers/P1425.pdf
Krzikalla, O., Feldhoff, K., Müller-Pfefferkorn, R., Nagel, W.E.: Scout: a source-to-source transformator for SIMD-Optimizations. In: Alexander, M., et al. (eds.) Euro-Par 2011, Part II. LNCS, vol. 7156, pp. 137–145. Springer, Heidelberg (2012)
Karrenberg, R., Hack, S.: Whole function vectorization. In: International Symposium on Code Generation and Optimization. CGO (2011)
Rice, H.: Classes of recursively enumerable sets and their decision problems. Trans. Am. Math. Soc. 74, 358–366 (1953)
Bacon, D., Graham, S., Sharp, O.: Compiler transformations for high-performance computing. ACM Comput. Surv. 26(4), 345–420 (1994)
Wolfe, M.: High-Performance Compilers for Parallel Computing. Pearson, Redwood City (1995)
Senkevich, A.: Libmvec (2015). https://sourceware.org/glibc/wiki/libmvec
Intel: Intrinsics for Short Vector Math Library Operations (2015). https://software.intel.com/en-us/node/583200
O’Donell, C.: The GNU C Library version 2.22 is now available (2015). https://www.sourceware.org/ml/libc-alpha/2015-08/msg00609.html
Intel: Vectorization and Loops (2015). https://software.intel.com/en-us/node/581412
Intel(R) Mobile Computing and Compilers: Vector Function Application Binary Interface, Version 0.9.5 (2013). https://www.cilkplus.org/sites/default/files/open_specifications
Intel: Intel Cilk Plus Language Extension Specification (2013). https://www.cilkplus.org/sites/default/files/open_specifications/Intel_Cilk_plus_lang_spec_1.2.htm
OpenMP Architecture Review Board: OpenMP Application Program Interface, Version 4.5 (2015). http://www.openmp.org/
Krzikalla, O., Wende, F., Höhnerbach, M.: Dynamic SIMD vector lane scheduling. In: Proceedings of the ISC 2016 IXPUG Workshop. LNCS. Springer (2016). www.ixpug.org
Kretz, M., Lindenstruth, V.: Vc: a C++ library for explicit vectorization. Softw. Pract. Exper. 42(11), 1409–1430 (2012)
This paper: Code samples hosted on https://github.com/flwende/simd_benchmarks
Kresse, G., Furthmüller, J.: Efficient iterative schemes for ab initio total-energy calculations using a plane-wave basis set. Phys. Rev. B 54, 11169–11186 (1996)
Kresse, G., Joubert, D.: From ultrasoft pseudopotentials to the projector augmented-wave method. Phys. Rev. B 59, 1758–1775 (1999)
Griffies, S.M.: Elements of the Modular Ocean Model (MOM). NOAA Geophysical Fluid Dynamics Laboratory, Princeton, USA (2012)
Acknowledgments
This work is supported by Intel within the IPCC activities at ZIB, and partially supported by the project SECOS—“The Service of Sediments in German Coastal Seas” (Subproject 3.2, grant BMBF 03F0666D). We would like to acknowledge G. Kresse and M. Marsman for collaboration on VASP tuning. (Intel, Xeon and Xeon Phi are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. * Other brands and names are the property of their respective owners. Performance tests are measured using specific computer systems, components, software, operations, and functions. Any change to any of those factors may cause the results to vary. Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Wende, F., Noack, M., Steinke, T., Klemm, M., Newburn, C.J., Zitzlsberger, G. (2016). Portable SIMD Performance with OpenMP* 4.x Compiler Directives. In: Dutot, PF., Trystram, D. (eds) Euro-Par 2016: Parallel Processing. Euro-Par 2016. Lecture Notes in Computer Science(), vol 9833. Springer, Cham. https://doi.org/10.1007/978-3-319-43659-3_20
Download citation
DOI: https://doi.org/10.1007/978-3-319-43659-3_20
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-43658-6
Online ISBN: 978-3-319-43659-3
eBook Packages: Computer ScienceComputer Science (R0)