
Abstract
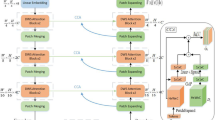
In recent years, the Vision Transformer has gradually replaced the CNN as the mainstream method in the field of medical image segmentation due to its powerful long-range dependencies modeling ability. However, the segmentation network leveraging pure transformer performs poor in feature expression because of the lack of convolutional locality. Besides, the channel dimension information are lost in the network. In this paper, we propose a novel segmentation network termed CTC-Net to address these problems. Specifically, we design a feature-enhanced transformer module with spatial-reduction attention to extract the region details in the image patches by the depth-wise convolution. Then, the point-wise convolution is leveraged to capture non-linear relationship in the channel dimension. Furthermore, a parallel convolutional encoder branch and an inverted residual coordinate attention block are designed to mine the clear dependencies of local context, channel dimension features and location information. Extensive experiments on Synapse Multi-organ CT and ACDC (Automatic Cardiac Diagnosis Challenge) datasets show that our method outperforms the methods based on CNN and pure transformers, obtaining up to 1.72\(\%\) and 0.68\(\%\) improvement in DSC scores respectively.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Sahiner, B., Pezeshk, A., Hadjiiski, L.M., et al.: Deep learning in medical imaging and radiation therapy. Med. Phys. 46(1), e1–e36 (2019)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3431–3440 (2015)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Zhou, Z., Siddiquee, M.M.R., Tajbakhsh, N., et al.: UNet++: redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 39(6), 1856–1867 (2019)
Diakogiannis, F.I., Waldner, F., Caccetta, P., et al.: ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote. Sens. 162, 94–114 (2020)
Oktay, O., Schlemper, J., Folgoc, L.L., et al.: Attention U-Net: learning where to look for the pancreas. ar**v preprint ar**v:1804.03999 (2018)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al.: An image is worth 16 \(\times \) 16 words: transformers for image recognition at scale. ar**v preprint ar**v:2010.11929 (2020)
Vaswani, A., Shazeer, N., Parmar, N., et al. : Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Chen, J., Lu, Y., Yu, Q., et al.: TransUNet: transformers make strong encoders for medical image segmentation. ar**v preprint ar**v:2102.04306 (2021)
Cao, H., et al.: Swin-Unet: Unet-like pure transformer for medical image segmentation. In: Karlinsky, L., Michaeli, T., Nishino, K. (eds.) Proceedings of the Computer Vision, ECCV 2022 Workshops, Part III, Tel Aviv, Israel, 23–27 October 2022, pp. 205–218. Springer, Cham (2023). https://doi.org/10.1007/978-3-031-25066-8_9
Liu, Z., Lin, Y., Cao, Y., et al.: Swin transformer: hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 10012–10022 (2021)
Huang, X., Deng, Z., Li, D., et al.: MISSFormer: an effective transformer for 2D medical image segmentation. IEEE Trans. Med. Imaging 42, 1484–1494 (2022)
He, K., Zhang, X., Ren, S., et al.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Wang, W., **e, E., Li, X., et al.: Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 568–578 (2021)
Hou, Q., Zhou, D., Feng, J.: Coordinate attention for efficient mobile network design. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13713–13722 (2021)
Deng, J., Dong, W., Socher, R., et al. : ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2019)
Wang, H., **e, S., Lin, L., et al.: Mixed transformer U-Net for medical image segmentation. In: 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). ICASSP 2022, pp. 2390–2394. IEEE (2022)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, S., Xu, Y., Wu, Z., Wei, Z. (2023). CTC-Net: A Novel Coupled Feature-Enhanced Transformer and Inverted Convolution Network for Medical Image Segmentation. In: Lu, H., Blumenstein, M., Cho, SB., Liu, CL., Yagi, Y., Kamiya, T. (eds) Pattern Recognition. ACPR 2023. Lecture Notes in Computer Science, vol 14407. Springer, Cham. https://doi.org/10.1007/978-3-031-47637-2_21
Download citation
DOI: https://doi.org/10.1007/978-3-031-47637-2_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-47636-5
Online ISBN: 978-3-031-47637-2
eBook Packages: Computer ScienceComputer Science (R0)