
Abstract
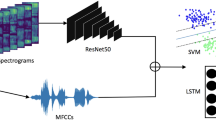
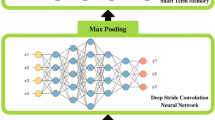
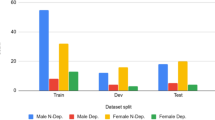
Intelligent monitoring systems and affective computing applications have emerged in recent years to enhance healthcare. Examples of these applications include assessment of affective states such as Major Depressive Disorder (MDD). MDD describes the constant expression of certain emotions: negative emotions (low Valence) and lack of interest (low Arousal). High-performing intelligent systems would enhance MDD diagnosis in its early stages. In this paper, we present a new deep neural network architecture, called EmoAudioNet, for emotion and depression recognition from speech. Deep EmoAudioNet learns from the time-frequency representation of the audio signal and the visual representation of its spectrum of frequencies. Our model shows very promising results in predicting affect and depression. It works similarly or outperforms the state-of-the-art methods according to several evaluation metrics on RECOLA and on DAIC-WOZ datasets in predicting arousal, valence, and depression. Code of EmoAudioNet is publicly available on GitHub: https://github.com/AliceOTHMANI/EmoAudioNet.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
References
GBD 2015 Disease and Injury Incidence and Prevalence Collaborators: Global, regional, and national incidence, prevalence, and years lived with disability for 310 diseases and injuries, 1990–2015: a systematic analysis for the Global Burden of Disease Study 2015, Lancet, vol. 388, no. 10053, pp. 1545–1602 (2015)
The National Institute of Mental Health: Depression. https://www.nimh.nih.gov/health/topics/depression/index.shtml. Accessed 17 June 2019
Valstar, M., et al.: AVEC 2016 - depression, mood, and emotion recognition workshop and challenge. In: Proceedings of the 6th International Workshop on Audio/visual Emotion Challenge, pp. 3–10. ACM (2016)
Ringeval, F., et al.: AVEC 2017 - real-life depression, and affect recognition workshop and challenge. In: Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, pp. 3–9. ACM (2017)
Jiang, H., Hu, B., Liu, Z., Wang, G., Zhang, L., Li, X., Kang, H.: Detecting depression using an ensemble logistic regression model based on multiple speech features. Comput. Math. Methods Medicine 2018 (2018)
Alghowinem, S., et al.: A comparative study of different classifiers for detecting depression from spontaneous speech. In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 8022–8026 (2013)
Valstar, M., et al.: AVEC 2013: the continuous audio/visual emotion and depression recognition challenge. In: Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, pp. 3–10 (2013)
Yang, L., Sahli, H., **a, X., Pei, E., Oveneke, M.C., Jiang, D.: Hybrid depression classification and estimation from audio video and text information. In: Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, pp. 45–51. ACM (2017)
Cummins, N., Epps, J., Breakspear M., Goecke, R.: An investigation of depressed speech detection: features and normalization. In: Twelfth Annual Conference of the International Speech Communication Association (2011)
Lopez-Otero, P., Dacia-Fernandez, L., Garcia-Mateo, C.: A study of acoustic features for depression detection. In: 2nd International Workshop on Biometrics and Forensics, pp. 1–6. IEEE (2014)
Ringeval, F., et al.: Av+EC 2015 - the first affect recognition challenge bridging across audio, video, and physiological data. In: Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge, pp. 3–8. ACM (2015)
He, L., Jiang, D., Yang, L., Pei, E., Wu, P., Sahli, H.: Multimodal affective dimension prediction using deep bidirectional long short-term memory recurrent neural networks. In: Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge, pp. 73–80. ACM (2015)
Ringeval, F., et al.: AVEC 2018 workshop and challenge: bipolar disorder and cross-cultural affect recognition. In: Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, pp. 3–13. ACM (2018)
Dhall, A., Ramana Murthy, O.V., Goecke, R., Joshi, J., Gedeon, T.: Video and image based emotion recognition challenges in the wild: EmotiW 2015. In: Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, pp. 423–426 (2015)
Haq, S., Jackson, P.J., Edge, J.: Speaker-dependent audio-visual emotion recognition. In: AVSP, pp. 53–58 (2009)
Low, L.S.A., Maddage, N.C., Lech, M., Sheeber, L.B., Allen, N.B.: Detection of clinical depression in adolescents’ speech during family interactions. IEEE Trans. Biomed. Eng. 58(3), 574–586 (2010)
Valstar, M., Schuller, B.W., Krajewski, J., Cowie, R., Pantic, M.: AVEC 2014: the 4th international audio/visual emotion challenge and workshop. In: Proceedings of the 22nd ACM International Conference on Multimedia, pp. 1243–1244 (2014)
Meng, H., Huang, D., Wang, H., Yang, H., Ai-Shuraifi, M., Wang, Y.: Depression recognition based on dynamic facial and vocal expression features using partial least square regression. In: Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, pp. 21–30 (2013)
Trigeorgis, G., et al.: Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5200–5204 (2016)
Ringeval, F., et al.: Prediction of asynchronous dimensional emotion ratings from audiovisual and physiological data. Pattern Recogn. Lett. 66, 22–30 (2015)
Ringeval, F., Schuller, B., Valstar, M., Cowie, R., Pantic, M.: AVEC 2015: the 5th international audio/visual emotion challenge and workshop. In: Proceedings of the 23rd ACM International Conference on Multimedia, pp. 1335–1336 (2015)
Tzirakis, P., Trigeorgis, G., Nicolaou, M.A., Schuller, B.W., Zafeiriou, S.: End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Topics Signal Process. 11(8), 1301–1309 (2017)
Al Hanai, T., Ghassemi, M.M., Glass, J.R.: Detecting depression with audio/text sequence modeling of interviews. In: Interspeech, pp. 1716–1720 (2018)
Dham, S., Sharma, A., Dhall, A.: Depression scale recognition from audio, visual and text analysis. ar**v preprint ar**v:1709.05865
Salekin, A., Eberle, J.W., Glenn, J.J., Teachman, B.A., Stankovic, J.A.: A weakly supervised learning framework for detecting social anxiety and depression. Proc. ACM Interact. Mobile Wearable Ubiquit. Technol. 2(2), 81 (2018)
Yang, L., Jiang, D., **a, X., Pei, E., Oveneke, M.C., Sahli, H.: Multimodal measurement of depression using deep learning models. In: Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, pp. 53–59 (2017)
Jain, R.: Improving performance and inference on audio classification tasks using capsule networks. ar**v preprint ar**v:1902.05069 (2019)
Chao, L., Tao, J., Yang, M., Li, Y.: Multi task sequence learning for depression scale prediction from video. In: 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), pp. 526–531. IEEE (2015)
Gupta, R., Sahu, S., Espy-Wilson, C.Y., Narayanan, S.S.: An affect prediction approach through depression severity parameter incorporation in neural networks. In: Interspeech, pp. 3122–3126 (2017)
Kang, Y., Jiang, X., Yin, Y., Shang, Y., Zhou, X.: Deep transformation learning for depression diagnosis from facial images. In: Zhou, J., et al. (eds.) CCBR 2017. LNCS, vol. 10568, pp. 13–22. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-69923-3_2
Yu, G., Slotine, J.J.: Audio classification from time-frequency texture. In: 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 1677–1680 (2009)
Ringeval, F., Sonderegger, A., Sauer, J., Lalanne, D.: Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In: 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), pp. 1–8. IEEE (2013)
Gratch, J., et al.: The distress analysis interview corpus of human and computer interviews. LREC, pp. 3123–3128 (2014)
Ma, X., Yang, H., Chen, Q., Huang, D., Wang, Y.: Depaudionet: an efficient deep model for audio based depression classification. In: Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, pp. 35–42 (2016)
Rejaibi, E., Komaty, A., Meriaudeau, F., Agrebi, S., Othmani, A.: MFCC-based recurrent neural network for automatic clinical depression recognition and assessment from speech. ar**v preprint ar**v:1909.07208 (2019)
Tzirakis, P., Zhang, J., Schuller, B.W.: End-to-end speech emotion recognition using deep neural networks. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5089–5093 (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Othmani, A., Kadoch, D., Bentounes, K., Rejaibi, E., Alfred, R., Hadid, A. (2021). Towards Robust Deep Neural Networks for Affect and Depression Recognition from Speech. In: Del Bimbo, A., et al. Pattern Recognition. ICPR International Workshops and Challenges. ICPR 2021. Lecture Notes in Computer Science(), vol 12662. Springer, Cham. https://doi.org/10.1007/978-3-030-68790-8_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-68790-8_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-68789-2
Online ISBN: 978-3-030-68790-8
eBook Packages: Computer ScienceComputer Science (R0)
