
Abstract
We introduce SynthLog, an extension of the probabilistic logic programming language ProbLog, for synthesising inductive data models. Inductive data models integrate data with predictive and descriptive models, in a way that is reminiscent of inductive databases. SynthLog provides primitives for learning and manipulating inductive data models, it supports data wrangling, learning predictive models and constraints, and probabilistic and constraint reasoning. It is used as the back-end of the automated data scientist approach that is being developed in the SYNTH project. An overview of the SynthLog philosophy and language as well as a non trivial example of its use, is given in this paper.
Y. Dauxais, C. Gautrais and A. Dries—Have contributed equally.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Automated data science has received a lot of attention in the last decade [2], and has been recognized as an important challenge and solutions promise to democratize data science and make it available to non-expert end-users. Most current approaches tackle the problem of automatically constructing the best prediction pipeline [6, 7]. These approaches typically target expert end-users, that can understand most of the steps in the pipeline. In contrast, the SYNTH framework wants to democratize data science and make it available to the naive end-user. The central setting in SYNTH is that of autocompletion in spreadsheets [4]. Spreadsheets are used ubiquitously and the autocompletion task consists of predicting the next cell and value that the user wants to fill out, of course, under the assumption that there are sufficient regularities in the data to enable meaningful predictions.
The autocompletion task constitutes the front-end of the SYNTH framework, and it is easy to see how this can be included in spreadsheet software such as Excel. The back-end, however, consists of the SynthLog language that should support the underlying data science processes and components. This includes tools to automate various steps in data science, from data wrangling to predictive modeling and constraint learning. But rather than viewing this as a data science workflow or pipeline, SYNTH has the SynthLog language that allows the knowledgeable user to define and steer the data science process in a declarative manner. It is this language that we briefly introduce and illustrate in the present note. SynthLog builds on the inductive database idea [8] in that we are looking for a small and non-trivial set of primitives that supports data science processes. Rather than building on top of databases [9], however, SynthLog extends the probabilistic programming language ProbLog that already supports deductive and probabilistic inference, learning and (a limited form of) constraint processing, which are all important for data science.
The idea that SynthLog borrows from inductive databases is that it should treat models (such as predictors or constraints) as first class citizens, that is, SynthLog should support manipulating, constructing, using, and learning such models. Indeed, SynthLog should not only allow to handle the inputs and outputs of the data science components, but also to reason about which models should be learned, used or combined for a particular dataset or task. The models will be represented as SynthLog theories, which are essentially ProbLog programs, consisting of a set of probabilistic facts and clauses. Combining data science components then corresponds to performing operations on theories: adding/deleting facts, adding/deleting clauses, and combining theories.
In Sect. 2, we introduce the main contribution of this paper: the SynthLog language. Then, in Sect. 3, we present a case-study illustrating how SynthLog can be used to bridge many components of data science: from data wrangling to constraints.
2 Introduction to SynthLog
SynthLog is a language for supporting automated data science processes. It allows to construct and manipulate inductive data models. An Inductive Data Model (IDM) consists of (1) a set of data models (DM) that specifies an adequate data structure for the dataset (like a database), and (2) a set of inductive models (IMs), that is, a set of patterns and machine learning models (like classifiers) that have been discovered in the data. While the DM can be used to retrieve information about the dataset and to answer questions about specific data points, the IMs can be used to make predictions, find inconsistencies and redundancies, etc. IDMs integrate data and inductive models in a SynthLog theory.
SynthLog is built on top of the ProbLog probabilistic programming language. It essentially assumes that both the data models and the inductive models are ProbLog programs, and allows to refer to and manipulate such models by means of a new ProbLog operator. As SynthLog manipulates both data and inductive models, it borrows ideas from inductive databases that also consider both data and inductive models as first class citizens. For example, SynthLog follows the mantra of inductive databases that requires the closure property to be satisfied [3, 8]. In the SynthLog context this means that the result of any operation must be a theory, and thus must be a ProbLog program. At the same time, as each theory is a ProbLog program, SynthLog supports deductive and probabilistic reasoning, a form of answer set programming (through DTProbLog [1]) and machine learning. We first introduce ProbLog on a simple example, and then introduce the notion of a theory.
2.1 ProbLog by Example
ProbLog [5] is a probabilistic logic programming language, that extends Prolog by adding probabilistic primitives and inference. Let us take the example (from [5]) of a small social network, where smoking behavior depends on friendship among people.

For example, the first rule states that somebody that smokes has a probability of 40% to have asthma. Likewise, the second rule states that any person has a 30% chance of smoking. The query corresponds to the answer we want to get: we want to know the probability that person 2 has asthma. In this case, the result is 0.15.
As SynthLog extends ProbLog, which extends Prolog, a basic knowledge of Prolog and ProbLog is assumed in the remainder of this paper. For the interested reader, a more detailed presentation of ProbLog is availableFootnote 1.
2.2 SynthLog Theories
We now extend ProbLog with the notion of a theory. Each theory will consist of a ProbLog program and it will be possible to define theories through the scope operator
 . For example, the fact
. For example, the fact
 states that the theory or ProbLog program identified by
states that the theory or ProbLog program identified by
 contains the fact
contains the fact
 .
.
The following SynthLog listing defines various theories:

In this case, the clause
 is defined in the theory
is defined in the theory
 and is interpreted as
and is interpreted as
 . Beyond the syntactic sugar allowing to factorize the theory name in each terms in a clause, such representation allows to share constraints between theories and automatically interpret them. In this example, the
. Beyond the syntactic sugar allowing to factorize the theory name in each terms in a clause, such representation allows to share constraints between theories and automatically interpret them. In this example, the
 theory is the union of the
theory is the union of the
 and
and
 theories.
theories.
 contains the fact
contains the fact
 and the clause
and the clause
 . Thus,
. Thus,
 can be inferred. To support the inductive database aspect of SynthLog, and to allow for further manipulating inductive models, theories can be loaded from or stored in a database or file.
can be inferred. To support the inductive database aspect of SynthLog, and to allow for further manipulating inductive models, theories can be loaded from or stored in a database or file.
2.3 A Language for Data Science
To facilitate the use of SynthLog as a language dedicated to data science, several predicates are introduced to infer properties of relational datasets, build classifiers and learn or apply constraints on theories. SynthLog supports the definition of custom predicates, that take a theory (i.e. an inductive data model) as input and returns a theory as output. Many tasks fit within that framework: learners typically take data as input to output a model, data wrangling takes data as input and outputs data, applying a predictor requires data and model as input and outputs data. Some of these custom predicates are detailed in the next section.
3 Case Study: Auto-Completion
In this Section, we show how SynthLog can tackle a classic challenge in data science: automatically filling missing values in a spreadsheet. More precisely, these missing values are predicted with inductive models. The auto-completion task has been identified as a simple, yet challenging task, that illustrates the core of the SYNTH framework [4].
This case study shows that SynthLog successfully use both predictors, such as logistic regression; and probabilistic rules to infer the most likely missing values. We can therefore build on the large literature of the automation of predictor learning [7], while also providing an easy way to add user knowledge in the inference process. We also illustrate how inductive database ideas are used to store and query models depending on the task at hand. We use a toy dataset emulating sales of an ice-cream factory. The data is shown in Tables 1 and 2, with missing profit for the two rows in Table 2. It will be inferred using logistic regression combined with user defined constraints. The code performing the auto-completion is presented below:

In Line 1, we create the theory magic_cells from a csv file containing the data in Table 1, by using the custom predicate
 . Details about the custom predicates and their exact behavior are presented in Appendix A. Likewise, Line 2 creates the theory missing_data_cells by loading the data represented in Table 2.
. Details about the custom predicates and their exact behavior are presented in Appendix A. Likewise, Line 2 creates the theory missing_data_cells by loading the data represented in Table 2.
The rest of the program manipulates these 2 theories using SynthLog primitives and custom predicates to perform wrangling, prediction and inference. For example, Lines 4 and 5 perform wrangling, by using the custom predicate
 . More precisely, in Line 4,
. More precisely, in Line 4,
 transforms the theory magic_cells to output the theory magic_tables. The new theory magic_tables contains the same data as the theory magic_cells (i.e. the data from Table 1), but uses a different data model. Indeed,
transforms the theory magic_cells to output the theory magic_tables. The new theory magic_tables contains the same data as the theory magic_cells (i.e. the data from Table 1), but uses a different data model. Indeed,
 takes a cell based data model and transforms it into a table based data model. Details of this transformation are given in Appendix A. In this simple example, wrangling is straightforward, as the data is already nicely formatted. However,
takes a cell based data model and transforms it into a table based data model. Details of this transformation are given in Appendix A. In this simple example, wrangling is straightforward, as the data is already nicely formatted. However,
 still provides information about cell types and detects headers.
still provides information about cell types and detects headers.
From the theory magic_tables, the custom predicate
 learns an inductive model (Lines 7 to 9). More precisely, it learns a logistic regression modelFootnote 2 that predicts column 6 of Table T1 (the Table depicted in Table 1) from columns 3 and 4 of Table T1. The theory magic_predict contains this newly learned inductive model. The theory magic_predict also contains additional information about the learned inductive model: on which theory was it learned, using which columns and what type of inductive model it is. Kee** track of all these information allows us to easily query any model, hence treating them as first class citizens.
learns an inductive model (Lines 7 to 9). More precisely, it learns a logistic regression modelFootnote 2 that predicts column 6 of Table T1 (the Table depicted in Table 1) from columns 3 and 4 of Table T1. The theory magic_predict contains this newly learned inductive model. The theory magic_predict also contains additional information about the learned inductive model: on which theory was it learned, using which columns and what type of inductive model it is. Kee** track of all these information allows us to easily query any model, hence treating them as first class citizens.
Lines 11 to 13 query an inductive model by manipulating the theory magic_predict. To retrieve an inductive model, we simply specify its properties: it is a predictor and was trained on columns 3 and 4 from Table T1. If several inductive models in magic_predict satisfy these requirements, they are all used. SynthLog therefore handles models following the inductive database idea of treating them as first class citizens. Then, Line 14 applies the queried inductive model on the theory missing_data to create the new theory magic_predict, using the custom predicate
 . The theory magic_predict contains probabilistic facts representing the predictions of the logistic regression.
. The theory magic_predict contains probabilistic facts representing the predictions of the logistic regression.
Lines 16 and 17 create the theory final_pred by selecting a sub-part of the theory magic_predict, using a simple ProbLog rule. Lines 19 and 20 create a new inductive model, by storing a user-defined rule in the theory magic_constraints. This rule states that if column 5 of Table T in row X has a value below 300, then column 7 (profit) of Table T in row X has a value of 0 with probability 0.7. In this simple case, this rule could be specified by a user. However, SynthLog supports learning such rules through the use of custom predicates. Lines 21 and 22 add a sub-part of theory missing_data to the theory magic_constraints. Since the theory magic_constraints now contains
 predicates, the rule defined in Line 20 will automatically trigger, hence creating the probabilistic fact
predicates, the rule defined in Line 20 will automatically trigger, hence creating the probabilistic fact
 when applicable.
when applicable.
Finally, Lines 24 to 26 create the theory combined_pred by performing the union of sub-parts from the theories magic_constraints and final_pred through the
 operator of ProbLog. As SynthLog combines probabilistic facts from final_pred with the probabilistic rule from magic_constraints to create final_pred, probabilistic inference has to be performed. Because SynthLog extends ProbLog, it relies on its probabilistic inference mechanism to soundly combine both theories. As in ProbLog, the query of Line 28 determines what probabilistic facts the program should infer. In this case, we query for the theory final_pred to infer the cell values of Table 2, by combining the logistic regression predictions with the user defined rule. The result is shown in Table 3.
operator of ProbLog. As SynthLog combines probabilistic facts from final_pred with the probabilistic rule from magic_constraints to create final_pred, probabilistic inference has to be performed. Because SynthLog extends ProbLog, it relies on its probabilistic inference mechanism to soundly combine both theories. As in ProbLog, the query of Line 28 determines what probabilistic facts the program should infer. In this case, we query for the theory final_pred to infer the cell values of Table 2, by combining the logistic regression predictions with the user defined rule. The result is shown in Table 3.
Overall we have seen that SynthLog manipulates theories by using either custom predicates or native ProbLog operators. This simple way of manipulating theories is nonetheless powerful, as the resulting program is performing complex inference, taking into account predictive models and rules, while remaining simple to read.
4 Conclusion
We have introduced SynthLog, a declarative language for synthesising Inductive Data Models (IDM). IDMs integrate data and inductive models in a SynthLog theory. Theories can also be seen as ProbLog programs, consisting of probabilistic facts and clauses. Assembling data science components corresponds to manipulating theories, hence making SynthLog a language suitable for automating data science. As SynthLog is an extension of ProbLog, it natively supports probabilistic reasoning and we have illustrated through a use case how SynthLog can use probabilistic inference to effortlessly combine results from different type of models (predictors and constraints).
Having a language to assemble data science components, based on probabilistic logic, opens new possibilities. First, the inherent uncertainty of data and inductive models can be leveraged to perform probabilistic inference and provide predictions that reflect our confidence in our data and inductive models. Second, SynthLog handles different types of inductive models. More specifically, it handles rules or constraints along with other machine learning models. Hence, SynthLog provides a great opportunity to bridge user interaction and model learning through a unique language.
In the SYNTH framework, SynthLog is also first step towards the automation of data science. Indeed, with a single language combining all data science components, we can tackle the more challenging task of learning to learn, that is learning which SynthLog programs are suitable to automatically solve the data science task at hand.
Finally, the further development of SynthLog will likely require the development of new implementation techniques to support fast inference and learning. This will allow smoother user interaction and the analysis of larger datasets.
Notes
- 1.
- 2.
We use the scikit-learn library: https://scikit-learn.org/stable/index.html.
References
Van den Broeck, G., Thon, I., Van Otterlo, M., De Raedt, L.: DTProbLog: a decision-theoretic probabilistic Prolog. In: Twenty-Fourth AAAI Conference on Artificial Intelligence (2010)
De Bie, T., De Raedt, L., Hoos, H.H., Smyth, P.: Automating data science (dagstuhl seminar 18401). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik (2019)
De Raedt, L.: A perspective on inductive databases. ACM SIGKDD Explor. Newslett. 4(2), 69–77 (2002)
De Raedt, L., Blockeel, H., Kolb, S., Teso, S., Verbruggen, G.: Elements of an automatic data scientist. In: Duivesteijn, W., Siebes, A., Ukkonen, A. (eds.) IDA 2018. LNCS, vol. 11191, pp. 3–14. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01768-2_1
Dries, A., et al.: ProbLog2: probabilistic logic programming. In: Bifet, A., et al. (eds.) ECML PKDD 2015. LNCS (LNAI), vol. 9286, pp. 312–315. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-23461-8_37
Feurer, M., Klein, A., Eggensperger, K., Springenberg, J., Blum, M., Hutter, F.: Efficient and robust automated machine learning. In: Advances in Neural Information Processing Systems, pp. 2962–2970 (2015)
Hutter, F., Kotthoff, L., Vanschoren, J. (eds.): Automated Machine Learning: Methods, Systems, Challenges. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-05318-5. http://automl.org/book
Imielinski, T., Mannila, H.: A database perspective on knowledge discovery. Commun. ACM 39(11), 58–64 (1996)
Malec, M., Khot, T., Nagy, J., Blasch, E., Natarajan, S.: Inductive logic programming meets relational databases: an application to statistical relational learning. In: Inductive Logic Programming (ILP) (2016)
Verbruggen, G., De Raedt, L.: Automatically wrangling spreadsheets into machine learning data formats. In: Duivesteijn, W., Siebes, A., Ukkonen, A. (eds.) IDA 2018. LNCS, vol. 11191, pp. 367–379. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01768-2_30
Acknowledgements
This work has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No. [694980] SYNTH: Synthesising Inductive Data Models).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix A: SynthLog Custom Predicates Documentation
Appendix A: SynthLog Custom Predicates Documentation
-
 : loads the content of a csv file in a theory
: loads the content of a csv file in a theory-
Input
-
* csv file
-
-
Output: Theory with predicates:
-
 : row id, column id and value of each cell
: row id, column id and value of each cell
-
-
-
 : calls a data wrangler [10] to detect tables in the spreadsheet
: calls a data wrangler [10] to detect tables in the spreadsheet-
Input
-
* Theory with
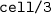 predicates
predicates
-
-
Output: Theory with predicates:
-
*
 : table id, top left row, top left column, height, width
: table id, top left row, top left column, height, width -
*
 : table id, row id, column id and value of each cell
: table id, row id, column id and value of each cell -
*
 : table id, row id, column id and type of each cell
: table id, row id, column id and type of each cell -
*
 : table id, column id, name, type, list of unique values
: table id, column id, name, type, list of unique values
-
-
-
 learns a scikit-learn predictor
learns a scikit-learn predictor-
Input
-
* Theory with
 predicates
predicates -
* Inductive model type (from scikit-learn models)
-
* List of columns to use as features
-
* List of columns to predict
-
-
Output: Theory with predicates:
-
*
 : inductive model
: inductive model -
*
 : inductive model, predicted column
: inductive model, predicted column -
*
 : inductive model, feature column
: inductive model, feature column
-
-
-
 makes prediction using a previously trained model
makes prediction using a previously trained model-
Input
-
* Theory with
 predicates
predicates -
* Inductive model
-
* List of columns to use as features
-
* List of columns to predict
-
-
Output: Theory with predicates:
-
*
 : table id, row id, column id and value of each cell
: table id, row id, column id and value of each cell -
*
 : inductive model
: inductive model -
*
 : inductive model, feature column
: inductive model, feature column -
*
 : inductive model, confidence score
: inductive model, confidence score
-
-
 : loads the content of a csv file in a theory
: loads the content of a csv file in a theory : row id, column id and value of each cell
: row id, column id and value of each cell : calls a data wrangler [
: calls a data wrangler [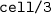 predicates
predicates : table id, top left row, top left column, height, width
: table id, top left row, top left column, height, width : table id, row id, column id and value of each cell
: table id, row id, column id and value of each cell : table id, row id, column id and type of each cell
: table id, row id, column id and type of each cell : table id, column id, name, type, list of unique values
: table id, column id, name, type, list of unique values learns a scikit-learn predictor
learns a scikit-learn predictor predicates
predicates : inductive model
: inductive model : inductive model, predicted column
: inductive model, predicted column : inductive model, feature column
: inductive model, feature column makes prediction using a previously trained model
makes prediction using a previously trained model predicates
predicates : table id, row id, column id and value of each cell
: table id, row id, column id and value of each cell : inductive model
: inductive model : inductive model, feature column
: inductive model, feature column : inductive model, confidence score
: inductive model, confidence scoreRights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Dauxais, Y. et al. (2020). SynthLog: A Language for Synthesising Inductive Data Models (Extended Abstract). In: Cellier, P., Driessens, K. (eds) Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2019. Communications in Computer and Information Science, vol 1167. Springer, Cham. https://doi.org/10.1007/978-3-030-43823-4_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-43823-4_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-43822-7
Online ISBN: 978-3-030-43823-4
eBook Packages: Computer ScienceComputer Science (R0)
