
Abstract
This study utilizes the parametric approach (GARCH-based models) and the semi-parametric approach of Hull and White (Journal of Risk 1: 5–19, 1998) (HW-based models) to estimate the Value-at-Risk (VaR) through the accuracy evaluation of accuracy for the eight stock indices in Europe and Asia stock markets. The measure of accuracy includes the unconditional coverage test by Kupiec (Journal of Derivatives 3: 73–84, 1995) as well as two loss functions, quadratic loss function, and unexpected loss. As to the parametric approach, the parameters of generalized autoregressive conditional heteroskedasticity (GARCH) model are estimated by the method of maximum likelihood and the quantiles of asymmetric distribution like skewed generalized student’s t (SGT) can be solved by composite trapezoid rule. Sequentially, the VaR is evaluated by the framework proposed by Jorion (Value at Risk: the new benchmark for managing financial risk. New York: McGraw-Hill, 2000). Turning to the semi-parametric approach of Hull and White (Journal of Risk 1: 5–19, 1998), before performing the traditional historical simulation, the raw return series is scaled by a volatility ratio where the volatility is estimated by the same procedure of parametric approach. Empirical results show that the kind of VaR approaches is more influential than that of return distribution settings on VaR estimate. Moreover, under the same return distributional setting, the HW-based models have the better VaR forecasting performance as compared with the GARCH-based models. Furthermore, irrespective of whether the GARCH-based model or HW-based model is employed, the SGT has the best VaR forecasting performance followed by student’s t, while the normal owns the worst VaR forecasting performance. In addition, all models tend to underestimate the real market risk in most cases, but the non-normal distributions (student’s t and SGT) and the semi-parametric approach try to reverse the trend of underestimating.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

Notes
- 1.
This means if you had 200 past returns and you wanted to know with 99 % confidence what’s the worst you can do, you would go to the 2nd data point on your ranked series and know that 99 % of the time you will do no worse than this amount.
- 2.
Large changes tend to be followed by large changes, of either sign, and small changes tend to be followed by small changes.
- 3.
See Faires and Burden (2003) for more details.
- 4.
The parameters are estimated by QMLE (quasi-maximum likelihood estimation; QMLE) and the BFGS optimization algorithm, using the econometric package of WinRATS 6.1.
References
Aloui, C., & Mabrouk, S. (2010). Value-at-risk estimations of energy commodities via long-memory, asymmetry and fat-tailed GARCH models. Energy Policy, 38, 2326–2339.
Angelidis, T., Benos, A., & Degiannakis, S. (2004). The use of GARCH models in VaR estimation. Statistical Methodology, 1, 105–128.
Bali, T. G., & Theodossiou, P. (2007). A conditional-SGT-VaR approach with alternative GARCH models. Annals of Operations Research, 151, 241–267.
Bhattacharyya, M., Chaudhary, A., & Yadav, G. (2008). Conditional VaR estimation using Pearson’s type IV distribution. European Journal of Operational Research, 191, 386–397.
Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31, 307–327.
Bollerslev, T., Chou, R. Y., & Kroner, K. F. (1992). ARCH modeling in finance: A review of the theory and empirical evidence. Journal of Econometrics, 52, 5–59.
Cabedo, J. D., & Moya, I. (2003). Estimating oil price ‘Value at Risk’ using the historical simulation approach. Energy Economics, 25, 239–253.
Chan, W. H., & Maheu, J. M. (2002). Conditional jump dynamics in stock market returns. Journal of Business Economics Statistics, 20, 377–389.
Chang, T. H., Su, H. M., & Chiu, C. L. (2011). Value-at-risk estimation with the optimal dynamic biofuel portfolio. Energy Economics, 33, 264–272.
Chen, Q., Gerlach, R., & Lu, Z. (2012). Bayesian value-at-risk and expected shortfall forecasting via the asymmetric Laplace distribution. Computational Statistics and Data Analysis, 56, 3498–3516.
Degiannakis, S., Floros, C., & Dent, P. (2012). Forecasting value-at-risk and expected shortfall using fractionally integrated models of conditional volatility: International evidence. International Review of Financial Analysis, 27, 21–33.
Faires, J. D., & Burden, R. (2003). Numerical methods (3rd ed.). Pacific Grove: Tomson Learning.
Gebizlioglu, O. L., Şenoğlu, B., & Kantar, Y. M. (2011). Comparison of certain value-at-risk estimation methods for the two-parameter Weibull loss distribution. Journal of Computational and Applied Mathematics, 235, 3304–3314.
Gençay, R., Selçuk, F., & Ulugülyaˇgci, A. (2003). High volatility, thick tails and extreme value theory in value-at-risk estimation. Insurance: Mathematics and Economics, 33, 337–356.
Giot, P., & Laurent, S. (2003a). Value-at-risk for long and short trading positions. Journal of Applied Econometrics, 18, 641–664.
Giot, P., & Laurent, S. (2003b). Market risk in commodity markets: A VaR approach. Energy Economics, 25, 435–457.
Hartz, C., Mittnik, S., & Paolellad, M. (2006). Accurate value-at-risk forecasting based on the normal-GARCH model. Computational Statistics & Data Analysis, 51, 2295–2312.
Huang, Y. C., & Lin, B. J. (2004). Value-at-risk analysis for Taiwan stock index futures: Fat tails and conditional asymmetries in return innovations. Review of Quantitative Finance and Accounting, 22, 79–95.
Hull, J., & White, A. (1998). Incorporating volatility updating into the historical simulation method for value-at-risk. Journal of Risk, 1, 5–19.
Jarque, C. M., & Bera, A. K. (1987). A test for normality of observations and regression residuals. International Statistics Review, 55, 163–172.
Jorion, P. (2000). Value at risk: The new benchmark for managing financial risk. New York: McGraw-Hill.
Kupiec, P. (1995). Techniques for verifying the accuracy of risk management models. The Journal of Derivatives, 3, 73–84.
Lee, C. F., & Su, J. B. (2011). Alternative statistical distributions for estimating value-at-risk: Theory and evidence. Review of Quantitative Finance and Accounting, 39, 309–331.
Lee, M. C., Su, J. B., & Liu, H. C. (2008). Value-at-risk in US stock indices with skewed generalized error distribution. Applied Financial Economics Letters, 4, 425–431.
Lopez, J. A. (1999). Methods for evaluating value-at-risk estimates. Federal Reserve Bank of San Francisco Economic Review, 2, 3–17.
Lu, C., Wu, S. C., & Ho, L. C. (2009). Applying VaR to REITs: A comparison of alternative methods. Review of Financial Economics, 18, 97–102.
Sadeghi, M., & Shavvalpour, S. (2006). Energy risk management and value at risk modeling. Energy Policy, 34, 3367–3373.
So, M. K. P., & Yu, P. L. H. (2006). Empirical analysis of GARCH models in value at risk estimation. International Financial Markets, Institutions & Money, 16, 180–197.
Stavroyiannis, S., Makris, I., Nikolaidis, V., & Zarangas, L. (2012). Econometric modeling and value-at-risk using the Pearson type-IV distribution. International Review of Financial Analysis, 22, 10–17.
Su, J. B., & Hung, J. C. (2011). Empirical analysis of jump dynamics, heavy-tails and skewness on value-at-risk estimation. Economic Modelling, 28, 1117–1130.
Theodossiou, P. (1998). Financial data and the skewed generalized t distribution. Management Science, 44, 1650–1661.
Vlaar, P. J. G. (2000). Value at risk models for Dutch bond portfolios. Journal of Banking & Finance, 24, 1131–1154.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Appendix 1: The Left-Tailed Quantiles of the Standardized SGT
The standardized SGT distribution was derived by Lee and Su (2011) and expressed as follows:
where \( \uptheta =\frac{1}{\mathrm{S}\left(\uplambda \right)}\mathrm{B}{\left(\frac{1}{\upkappa},\frac{\mathrm{n}}{\upkappa}\right)}^{\frac{1}{2}}\mathrm{B}{\left(\frac{3}{\upkappa},\frac{\mathrm{n}-2}{\upkappa}\right)}^{-\frac{1}{2}},\mathrm{S}\left(\uplambda \right)=\sqrt{1+3{\uplambda}^2-4{\mathrm{A}}^2{\uplambda}^2} \),
\( \mathrm{A}=\mathrm{B}\left(\frac{2}{\upkappa},\frac{\mathrm{n}-1}{\upkappa}\right)\mathrm{B}{\left(\frac{1}{\upkappa},\frac{\mathrm{n}}{\upkappa}\right)}^{-0.5}\mathrm{B}{\left(\frac{3}{\upkappa},\frac{\mathrm{n}-2}{\upkappa}\right)}^{-0.5} \), \( \updelta =\frac{2\uplambda \mathrm{A}}{\mathrm{S}\left(\uplambda \right)} \), \( \mathrm{C}=\frac{\upkappa}{2\uptheta}\mathrm{B}{\left(\frac{1}{\upkappa},\frac{\mathrm{n}}{\upkappa}\right)}^{-1} \)
where κ, n, and λ are scaling parameters and C and θ are normalizing constants ensuring that f(•) is a proper p.d.f. The parameters κ and n control the height and tails of density with constraints κ > 0 and n > 2, respectively. The skewness parameter λ controls the rate of descent of the density around the mode of ε t with − 1 < λ < 1. In the case of positive (resp. negative) skewness, the density function skews toward the right (resp. left). Sign is the sign function, and B(•) is the beta function. The parameter n has the degrees of freedom interpretation in case λ = 0 and κ = 2. Particularly, the SGT distribution generates the student’s t distribution for λ = 0 and κ = 2. Moreover, the SGT distribution generates the normal distribution for λ = 0, κ = 2, and n = ∞.
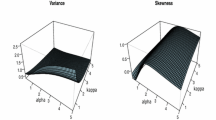
As observed from Table 51.2, the shape parameters in SGT distribution, the fat-tail parameter (n) ranges from 4.9846 (KLSE) to 21.4744 (KOSPI), and the fat-tail parameter (κ) is between 1.5399 (KOSPI) and 2.3917 (Bombay). The skewness parameter (λ) ranges from −0.1560 (Bombay) to −0.0044 (KLSE). Therefore, the left-tailed quantiles of the SGT distribution with various combinations of shape parameters (−0.15 ≤ λ ≤ 0.05; 1.0 ≤ κ ≤ 2.0; n = 10) at alternate levels are obtained by the composite trapezoid rule and are listed in Table 51.6. Moreover, Fig. 51.3 depicts the left-tailed quantiles surface of SGT (versus normal) distribution with various combinations of shape parameters (−0.25 ≤ λ ≤ 0.25; 0.8 ≤ κ ≤ 2.0;n = 10 and 20) at 10 %, 5 %, 1 %, and 0.5 % levels. Notably, Fc(ε t ;κ = 2, λ = 0, n = ∞) where c = 0.1, 0.05, 0.01, and 0.005 in Fig. 51.3 represents the left-tailed quantiles of normal distribution at 10 %, 5 %, 1 %, and 0.5 % levels, which is −1.28155, −1.64486, −2.32638, and −2.57613, respectively.


The left-tailed quantiles of SGT distribution with n = 10, 20, and various combinations (κ, λ). (a) 10 %, (b) 5 %, (c) 1 %, (d) 0.5 % confidence levels
Appendix 2: The Procedure of Parametric VaR Approach
The parametric method is very popular because the only variables you need to do the calculation are the mean and standard deviation of the portfolio, indicating the simplicity of the calculations. Moreover, from the literatures’ review mentioned above, numerous studies focused on the parametric approach of the GARCH family variance specifications to estimate the VaR. Furthermore, numerous time series data of financial assets appear to exhibit autocorrelated and volatility clustering, and the unconditional distribution of those returns displays leptokurtosis and a moderate amount of skewness. This study thus considers the applicability of the GARCH(1,1) model with three conditional distributions (the normal, student’s t, and SGT distributions) to estimate the corresponding volatility in terms of different stock indices, then employs the framework of Jorion (2000) to evaluate the VaR of parametric approach. We take an example of the GARCH-SGT model. The methodology of parametric VaR approach is based on a rolling window procedure. The window size is fixed at 2,000 observations. More specifically, the procedure is conducted in the following manner:
-
Step 1: For each data series, using the econometric package of WinRATS 6.1, the parameters are estimated with a sample of 2,000 daily returns by quasi-maximum likelihood estimation (QMLE) of log-likelihood function such as Eq. 51.10 and by the BFGS optimization algorithm. Thus, with ψ = [μ, ω, α, β, κ, λ, n], the vector of parameters is estimated. The empirical results of GARCH-SGT model are listed in Table 51.2 for all stock indices surveyed in this paper. As to the empirical results of GARCH-N and GARCH-T models, they are also provided by the same approach.
-
Step 2: Based on the framework of the parametric techniques (Jorion 2000), the 1-day-ahead VaR based on GARCH-SGT model can be calculated by Eq. 51.11. Then the one-step-ahead VaR forecasts are compared with the observed returns, and the comparative results are recorded for subsequent evaluation using statistical tests.
-
Step 3: The estimation period is then rolled forwards by adding one new day and drop** the most distant day. By replicating step 1 and step 2, the vector of parameters is estimated, and then the 1-day-ahead VaR can be calculated for the next 500 days.
-
Step 4: For the out-sample period (500 days), via the comparable results between the one-step-ahead VaR forecasts and the observed returns, the 1-day-ahead BLF, QLF, and UL can be calculated by using Eqs. 51.13, 51.14 and 51.16. On the other hand, the unconditional coverage test, LRuc, is evaluated by employing Eq. 51.15. Thereafter, with regard to the GARCH-based models with alternate distributions (GARCH-N, GARCH-T, and GARCH-SGT), the unconditional coverage test (LRuc) and three loss functions (failure rate, AQLF, and UL) are obtained and are reported in the left panel of Tables 51.3, 51.4 and 51.5 for 95 %, 99 %, and 99.5 % levels.
Appendix 3: The Procedure of Semi-parametric VaR Approach
In this paper, we use the approach proposed by Hull and White (1998) as a representative of the semi-parametric approach. This method mainly couples a weighting scheme of volatility with the traditional historical simulation. Hence, it can be regarded as a straightforward extension of traditional historical simulation. The weighting scheme of volatility is expressed as follows. Instead of using the actual historical percentage changes in market variables for the purposes of calculating VaR, we use historical changes that have been adjusted to reflect the ratio of the current daily volatility to the daily volatility at the time of the observation and assume that the variance of each market variable during the period covered by the historical data is monitored using a GARCH-based models. We take an example of the HW-SGT model. This methodology is explained in the following five steps:
-
Step 1: For each data series, using the econometric package of WinRATS 6.1, the parameters are estimated with a sample of 2,000 daily returns by quasi-maximum likelihood estimation (QMLE) of log-likelihood function such as Eq. 51.10 and by the BFGS optimization algorithm. Thus, with ψ = [μ, ω, α, β, κ, λ, n], the vector of parameters is estimated. This step is the same as the first step of parametric approach. Consequently, a series of daily volatility estimates, {σ1, σ2, σ3,......, σt=T}, are obtained where T is the number of estimated samples and equals 2,000 in this study.
-
Step 2: The modified return series are obtained by the raw return series multiplied by the ratio of the current daily volatility to the daily volatility at the time of the observation, σT/σi. That is, the modified return series are expressed as {r1 *, r2 *, r3 *,......, rt=T *}, where ri * = ri(σT/σi).
-
Step 3: Resort this modified return series ascendingly to achieve the empirical distribution. Thus, VaR is the percentile that corresponds to the specified confidence level. Then the one-step-ahead VaR forecasts are compared with the observed returns, and the comparative results are recorded for subsequent evaluation using statistical tests.
-
Step 4: The estimation period is then rolled forwards by adding one new day and drop** the most distant day. By replicating steps 1–3, the vector of parameters is estimated, and then the 1-day-ahead VaR can be calculated for the next 500 days. This step is the same as the third step of parametric approach.
-
Step 5: For the out-sample period (500 days), via the comparable results between the one-step-ahead VaR forecasts and the observed returns, the 1-day-ahead BLF, QLF, and UL can be calculated by using Eqs. 51.13, 51.14, and 51.16. On the other hand, the unconditional coverage test, LRuc, is evaluated by employing Eq. 51.15. Thereafter, with regard to HW-based models with alternate distributions (HW-N, HW-T, and HW-SGT), the unconditional coverage test (LRuc) and three loss functions (failure rate, AQLF, and UL) are obtained and are reported in the right panel of Tables 51.3, 51.4 and 51.5 for 95 %, 99 %, and 99.5 % levels.
Rights and permissions
Copyright information
© 2015 Springer Science+Business Media New York
About this entry
Cite this entry
Lee, CF., Su, JB. (2015). Value-at-Risk Estimation via a Semi-parametric Approach: Evidence from the Stock Markets. In: Lee, CF., Lee, J. (eds) Handbook of Financial Econometrics and Statistics. Springer, New York, NY. https://doi.org/10.1007/978-1-4614-7750-1_51
Download citation
DOI: https://doi.org/10.1007/978-1-4614-7750-1_51
Published:
Publisher Name: Springer, New York, NY
Print ISBN: 978-1-4614-7749-5
Online ISBN: 978-1-4614-7750-1
eBook Packages: Business and Economics