Search
Search Results
-
A Neural Network Architecture for Accurate 4D Vehicle Pose Estimation from Monocular Images with Uncertainty Assessment
This paper proposes a new neural network architecture for estimating the four degrees of freedom poses of vehicles from monocular images in an...
-
Deep-learning based system for effective and automatic blood vessel segmentation from Retinal fundus images
The segmentation of blood vessels through color fundus images is a difficult and time-consuming task that requires experienced clinicians. Recently,...

-
Neural attention for image captioning: review of outstanding methods
Image captioning is the task of automatically generating sentences that describe an input image in the best way possible. The most successful...
-
Using the New YoLo Models in Detecting Small-Sized Objects in the Case of Rice Grains on Branche
Identifying a small-sized object is of interest to many studies, especially the rice grain on the branch. Due to its significance to the evaluation...
-
The Geometry Enhanced Deep Implicit Function Based 3D Reconstruction for Objects in a Real-Scene Image
For the 3D reconstruction of objects in a real scene, the state-of-the-art scheme is to detect and identify the target by a classic deep neural...
-
A comprehensive survey on human pose estimation approaches
The human pose estimation is a significant issue that has been taken into consideration in the computer vision network for recent decades. It is a...

-
Computational Image Analysis Techniques, Programming Languages and Software Platforms Used in Cancer Research: A Sco** Review
Background: Cancer-related research, as indicated by the number of entries in Medline, the National Library of Medicine of the USA, has dominated the...
-
Video super-resolution based on deep learning: a comprehensive survey
Video super-resolution (VSR) is reconstructing high-resolution videos from low resolution ones. Recently, the VSR methods based on deep neural...

-
Self-Enhanced Attention for Image Captioning
Image captioning, which involves automatically generating textual descriptions based on the content of images, has garnered increasing attention from...

-
Syntax Tree Constrained Graph Network for Visual Question Answering
Visual Question Answering (VQA) aims to automatically answer natural language questions related to given image content. Existing VQA methods...
-
Engineering the Future: A Deep Dive into Remote Inspection and Reality Capture for Railway Infrastructure Digitalization
The growing importance of the railway sector demands efficient inspection and maintenance. Traditional methods are labor-intensive and costly,...
-
MEDAS: an open-source platform as a service to help break the walls between medicine and informatics
In the past decade, deep learning (DL) has achieved unprecedented success in numerous fields, such as computer vision and healthcare. Particularly,...

-
Rapid Seismic Risk Assessment of Bridges Using UAV Aerial Photogrammetric Survey
In this paper a framework for the rapid seismic risk assessment of bridges using aerial surveys using Unmanned Aerial Systems is presented. The...
-
GSNet: Joint Vehicle Pose and Shape Reconstruction with Geometrical and Scene-Aware Supervision
We present a novel end-to-end framework named as GSNet (Geometric and Scene-aware Network), which jointly estimates 6DoF poses and reconstructs...
-
Local self-attention in transformer for visual question answering
Visual Question Answering (VQA) is a multimodal task that requires models to understand both textual and visual information. Various VQA models have...

-
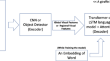
Transformer based Multitask Learning for Image Captioning and Object Detection
In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image...
-
Automatic oral cancer detection and classification using modified local texture descriptor and machine learning algorithms
Oral cancer is the most extensive universal problem, with 10.3 million deaths in 2020 by the World Health Organization (WHO). It is the most common...

-
A Shield Machine Segment Position Recognition Algorithm Based on Improved Voxel and Seed Filling
In response to the problems of low execution efficiency and poor real-time performance of traditional point cloud clustering algorithms when there is...
-
3D Object Detection for Autonomous Driving: A Comprehensive Survey
Autonomous driving, in recent years, has been receiving increasing attention for its potential to relieve drivers’ burdens and improve the safety of...

-
InterCap: Joint Markerless 3D Tracking of Humans and Objects in Interaction
Humans constantly interact with daily objects to accomplish tasks. To understand such interactions, computers need to reconstruct these from cameras...