
Abstract
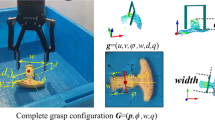
Gras** is an important and fundamental action for the interaction between robots and the environment. However, because gras** is a complex system engineering, there is still much room for development. At present, many studies use regression to solve the problem of grasp detection or use the unstable 3D point cloud as input, which may cause poor results to a certain extent. In this paper, we propose to use semantic segmentation of pixel-level classification to solve the problem of grasp pose detection. We adopt a grasp detection method based on the DeepLabv3+ model, which includes semantic segmentation and post-processing. In the semantic segmentation part, the classification mask of the objects is predicted through the input RGB image, and then the predicted objects of different classifications are fitted with the minimum bounding directed rectangle to obtain the two-dimensional grasp pose, and the final three-dimensional gras** pose is calculated through the conversion of the input depth image. On the validation dataset, we use the indicator of semantic segmentation to evaluate the proposed network and achieve a great result. In addition, the simulation robot experiment further verifies the effectiveness of the network.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Bicchi, A., Kumar, V.: Robotic gras** and contact: a review. In: Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation, vol. 1, pp. 348–353. IEEE, San Francisco (2000)
Bohg, J., Morales, A., Asfour, T., Kragic, D.: Data-driven grasp synthesis—a survey. IEEE Trans. Rob. 30(2), 289–309 (2014)
Dang, H., Allen, P.K.: Semantic gras**: planning robotic grasps functionally suitable for an object manipulation task. In: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 1311–1317. IEEE, Vilamoura-Algarve (2012)
Jiang, Y., Moseson, S., Saxena, A.: Efficient gras** from RGBD images: learning using a new rectangle representation. In: 2011 IEEE International Conference on Robotics and Automation, pp. 3304–3311. IEEE, Shanghai (2011)
Lenz, I., Lee, H., Saxena, A.: Deep learning for detecting robotic grasps. Int. J. Robot. Res. 34(4–5), 705–724 (2015)
Pinto, L., Gupta, A.: Supersizing self-supervision: learning to grasp from 50K tries and 700 robot hours. In: 2016 IEEE International Conference on Robotics and Automation, pp. 3406–3413. IEEE, Stockholm (2016)
Depierre, A., Dellandréa, E., Chen, L.: Jacquard: a large scale dataset for robotic grasp detection. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 3511–3516. IEEE, Madrid (2018)
Kumra, S., Kanan, C.: Robotic grasp detection using deep convolutional neural networks. In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 769–776. IEEE, Vancouver (2017)
Asir, U., Tang, J.B., Harrer, S.: GraspNet: an efficient convolutional neural network for real-time grasp detection for low-powered devices. In: 27th International Joint Conference on Artificial Intelligence, Stockholm, pp. 4875–4882 (2018)
Qi, C.R., Su, H., Mo, K.C., Guibas, L.J.: PointNet: deep learning on point sets for 3d classification and segmentation. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, pp. 652–660. IEEE, Honolulu (2017)
Qi, C.R., Su, H., Mo, K.C., Guibas, L.J.: PointNet plus plus: deep hierarchical feature learning on point sets in a metric space. In: 31st Annual Conference on Neural Information Processing Systems, Long Beach (2017)
Ten Pas, A., Gualtieri, M., Saenko, K., Platt, R.: Grasp pose detection in point clouds. Int. J. Robot. Res. 36(13–14), 1455–1473 (2017)
Liang, H.Z., et al.: PointNetGPD: detecting grasp configurations from point sets. In: 2019 International Conference on Robotics and Automation, pp. 3629–3635. IEEE, Montreal (2019)
Fang, H.S., Wang, C., Gou, M., Lu, C.: GraspNet-1Billion: a large-scale benchmark for general object gras**. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11441–11450. IEEE, Seattle (2020)
Gou, M., Fang, H.S., Zhu, Z., Xu, S., Wang, C., Lu, C.: RGB matters: learning 7-DoF grasp poses on monocular RGBD images. In: 2021 IEEE International Conference on Robotics and Automation, pp. 13459–13466. IEEE, **’an (2021)
Li, Y., Kong, T., Chu, R., Li, Y., Wang, P., Li, L.: Simultaneous semantic and collision learning for 6-DoF grasp pose estimation. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 3571–3578. IEEE, Prague (2021)
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11211, pp. 833–851. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01234-2_49
Zhao, H.S., Shi, J.P., Qi, X.J., Wang X.G., Jia J.Y.: Pyramid scene parsing network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, pp. 6230–6239. IEEE, Honolulu (2017)
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant No. 62003048) and the National Key Research and Development Program of China (Grant No. 2019YFB1309802).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, Q., Zhang, X., Li, H. (2022). A Grasp Pose Detection Network Based on the DeepLabv3+ Semantic Segmentation Model. In: Liu, H., et al. Intelligent Robotics and Applications. ICIRA 2022. Lecture Notes in Computer Science(), vol 13458. Springer, Cham. https://doi.org/10.1007/978-3-031-13841-6_67
Download citation
DOI: https://doi.org/10.1007/978-3-031-13841-6_67
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-13840-9
Online ISBN: 978-3-031-13841-6
eBook Packages: Computer ScienceComputer Science (R0)