
Abstract
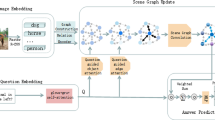
Visual Relational Reasoning is crucial for many vision-and-language based tasks, such as Visual Question Answering and Vision Language Navigation. In this paper, we consider reasoning on complex referring expression comprehension (c-REF) task that seeks to localise the target objects in an image guided by complex queries. Such queries often contain complex logic and thus impose two key challenges for reasoning: (i) It can be very difficult to comprehend the query since it often refers to multiple objects and describes complex relationships among them. (ii) It is non-trivial to reason among multiple objects guided by the query and localise the target correctly. To address these challenges, we propose a novel Modular Graph Attention Network (MGA-Net). Specifically, to comprehend the long queries, we devise a language attention network to decompose them into four types: basic attributes, absolute location, visual relationship and relative locations, which mimics the human language understanding mechanism. Moreover, to capture the complex logic in a query, we construct a relational graph to represent the visual objects and their relationships, and propose a multi-step reasoning method to progressively understand the complex logic. Extensive experiments on CLEVR-Ref+, GQA and CLEVR-CoGenT datasets demonstrate the superior reasoning performance of our MGA-Net.
Y. Zheng and Z. Wen—Contributed equally.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
Although RefCOCO datasets are biased and do not belong to the c-REF task, we conduct experiments on them and put the results into the supplementary material.
- 2.
We put the training algorithm into the supplementary material.
- 3.
We put the Implementation Details into the supplementary material.
References
Perez, E., Strub, F., De Vries, H., Dumoulin, V., Courville, A.: FiLM: visual reasoning with a general conditioning layer. In: AAAI Conference on Artificial Intelligence (AAAI) (2018)
Hudson, D.A., Manning, C.D.: Compositional attention networks for machine reasoning. In: International Conference on Learning Representations (ICLR) (2018)
Mao, J., Gan, C., Kohli, P., Tenenbaum, J.B., Wu, J.: The neuro-symbolic concept learner: interpreting scenes, words, and sentences from natural supervision. In: International Conference on Learning Representations (ICLR) (2019)
Anderson, P., et al.: Vision-and-language navigation: interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3674–3683 (2018)
Wang, X., et al.: Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6629–6638 (2019)
Nguyen, K., Dey, D., Brockett, C., Dolan, B.: Vision-based navigation with language-based assistance via imitation learning with indirect intervention. In: Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12527–12537 (2019)
Liu, R., Liu, C., Bai, Y., Yuille, A.L.: CLEVR-REF+: diagnosing visual reasoning with referring expressions. In: Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4185–4194 (2019)
Hudson, D.A., Manning, C.D.: GQA: a new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6700–6709 (2019)
Kazemzadeh, S., Ordonez, V., Matten, M., Berg, T.L.: ReferitGame: referring to objects in photographs of natural scenes. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 787–798 (2014)
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11–20 (2016)
Yu, L., et al.: MAttNet: modular attention network for referring expression comprehension. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1307–1315 (2018)
Yu, L., Tan, H., Bansal, M., Berg, T.L.: A joint speaker-listener-reinforcer model for referring expressions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3521–3529 (2017)
Wang, P., Wu, Q., Cao, J., Shen, C., Gao, L., Hengel, A.v.d.: Neighbourhood watch: referring expression comprehension via language-guided graph attention networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1960–1968 (2019)
Bajaj, M., Wang, L., Sigal, L.: G3raphGround: graph-based language grounding. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 4281–4290 (2019)
Hu, R., Rohrbach, A., Darrell, T., Saenko, K.: Language-conditioned graph networks for relational reasoning. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 10294–10303 (2019)
Li, Y., Tarlow, D., Brockschmidt, M., Zemel, R.S.: Gated graph sequence neural networks. In: International Conference on Learning Representations (ICLR) (2016)
Norcliffe-Brown, W., Vafeias, S., Parisot, S.: Learning conditioned graph structures for interpretable visual question answering. In: Advances in Neural Information Processing Systems (NeurIPS), pp. 8334–8343 (2018)
Chang, S., Yang, J., Park, S., Kwak, N.: Broadcasting convolutional network for visual relational reasoning. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 754–769 (2018)
Huang, H., Jain, V., Mehta, H., Ku, A., Magalhaes, G., Baldridge, J., Ie, E.: Transferable representation learning in vision-and-language navigation. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 7404–7413 (2019)
Ke, L., et al.: Tactical rewind: self-correction via backtracking in vision-and-language navigation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6741–6749 (2019)
Johnson, J., et al.: Inferring and executing programs for visual reasoning. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 2989–2998 (2017)
Hu, R., Andreas, J., Rohrbach, M., Darrell, T., Saenko, K.: Learning to reason: end-to-end module networks for visual question answering. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 804–813 (2017)
Cao, Q., Liang, X., Li, B., Li, G., Lin, L.: Visual question reasoning on general dependency tree. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7249–7257 (2018)
Hu, R., Rohrbach, M., Andreas, J., Darrell, T., Saenko, K.: Modeling relationships in referential expressions with compositional modular networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1115–1124 (2017)
Andreas, J., Rohrbach, M., Darrell, T., Klein, D.: Neural module networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 39–48 (2016)
Cirik, V., Morency, L., Berg-Kirkpatrick, T.: Visual referring expression recognition: what do systems actually learn? In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), pp. 781–787 (2018)
Gori, M., Monfardini, G., Scarselli, F.: A new model for learning in graph domains. In: Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), vol. 2, pp. 729–734. IEEE (2005)
Scarselli, F., Gori, M., Tsoi, A.C., Hagenbuchner, M., Monfardini, G.: The graph neural network model. IEEE Trans. Neural Networks 20, 61–80 (2008)
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. In: International Conference on Learning Representations (ICLR) (2017)
Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph attention networks. ar**v preprint ar**v:1710.10903 (2017)
Zeng, R., et al.: Graph convolutional networks for temporal action localization. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 7094–7103 (2019)
Huang, D., Chen, P., Zeng, R., Du, Q., Tan, M., Gan, C.: Location-aware graph convolutional networks for video question answering. In: AAAI Conference on Artificial Intelligence (AAAI), pp. 11021–11028 (2020)
Li, L., Gan, Z., Cheng, Y., Liu, J.: Relation-aware graph attention network for visual question answering. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 10313–10322 (2019)
Yang, S., Li, G., Yu, Y.: Dynamic graph attention for referring expression comprehension. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 4644–4653 (2019)
Yang, S., Li, G., Yu, Y.: Cross-modal relationship inference for grounding referring expressions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4145–4154 (2019)
Zhu, M., Zhang, Y., Chen, W., Zhang, M., Zhu, J.: Fast and accurate shift-reduce constituent parsing. In: ACL, vol. 1, pp. 434–443 (2013)
Pennington, J., Socher, R., Manning, C.D.: GloVe: global vectors for word representation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532–1543 (2014)
Schuster, M., Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 45, 2673–2681 (1997)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1724–1734 (2014)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: International Conference on Learning Representations (ICLR) (2015)
Krishna, R., et al.: Visual genome: connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vision 123, 32–73 (2017)
Johnson, J., Hariharan, B., van der Maaten, L., Fei-Fei, L., Zitnick, C.L., Girshick, R.B.: CLEVR: a diagnostic dataset for compositional language and elementary visual reasoning. In: Proceedings of the of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1988–1997 (2017)
Hu, R., Andreas, J., Darrell, T., Saenko, K.: Explainable neural computation via stack neural module networks. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 55–71 (2018)
Rohrbach, A., Rohrbach, M., Hu, R., Darrell, T., Schiele, B.: Grounding of textual phrases in images by reconstruction. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 817–834 (2016)
Acknowledgement
This work was partially supported by the Key-Area Research and Development Program of Guangdong Province 2019B010155002, Program for Guangdong Introducing Innovative and Entrepreneurial Teams 2017ZT-07X183, Fundamental Research Funds for the Central Universities D2191240.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Zheng, Y. et al. (2021). Modular Graph Attention Network for Complex Visual Relational Reasoning. In: Ishikawa, H., Liu, CL., Pajdla, T., Shi, J. (eds) Computer Vision – ACCV 2020. ACCV 2020. Lecture Notes in Computer Science(), vol 12627. Springer, Cham. https://doi.org/10.1007/978-3-030-69544-6_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-69544-6_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-69543-9
Online ISBN: 978-3-030-69544-6
eBook Packages: Computer ScienceComputer Science (R0)