
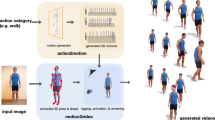
Abstract
Novel-View Human Action Synthesis aims to synthesize the movement of a body from a virtual viewpoint, given a video from a real viewpoint. We present a novel 3D reasoning to synthesize the target viewpoint. We first estimate the 3D mesh of the target body and transfer the rough textures from the 2D images to the mesh. As this transfer may generate sparse textures on the mesh due to frame resolution or occlusions. We produce a semi-dense textured mesh by propagating the transferred textures both locally, within local geodesic neighborhoods, and globally, across symmetric semantic parts. Next, we introduce a context-based generator to learn how to correct and complete the residual appearance information. This allows the network to independently focus on learning the foreground and background synthesis tasks. We validate the proposed solution on the public NTU RGB+D dataset. The code and resources are available at https://bit.ly/36u3h4K.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Notes
- 1.
https://renderpeople.com/, accessed September 2020.
- 2.
In practice, we manually annotate each of the \(N_f\) face into a unique body-part label.
References
Lakhal, M.I., Lanz, O., Cavallaro, A.: View-LSTM: novel-view video synthesis through view decomposition. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 7576–7586 (2019)
Bertel, T., Campbell, N.D.F., Richardt, C.: MegaParallax: casual 360\(^{\circ }\) panoramas with motion parallax. IEEE Trans. Vis. Comput. Graph. 25, 1828–1835 (2019)
Li, J., Wong, Y., Zhao, Q., Kankanhalli, M.: Unsupervised learning of view-invariant action representations. In: Neural Information Processing Systems (NeurIPS) (2018)
Rematas, K., Kemelmacher-Shlizerman, I., Curless, B., Seitz, S.: Soccer on your tabletop. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4738–4747 (2018)
Natsume, R., et al.: SiCloPe: silhouette-based clothed people. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4475–4485 (2019)
Saito, S., Huang, Z., Natsume, R., Morishima, S., Kanazawa, A., Li, H.: PIFu: Pixel-aligned implicit function for high-resolution clothed human digitization. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 2304–2314 (2019)
Lombardi, S., Simon, T., Saragih, J., Schwartz, G., Lehrmann, A., Sheikh, Y.: Neural volumes: learning dynamic renderable volumes from images. ACM Trans. Graph. (TOG) 38, (2019)
Thies, J., Zollhöfer, M., Theobalt, C., Stamminger, M., Nießner, M.: Image-guided neural object rendering. In: Proceedings of the International Conference on Learning Representations (ICLR) (2020)
Weng, C.Y., Curless, B., Kemelmacher-Shlizerman, I.: Photo Wake-Up: 3D character animation from a single photo. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5901–5910 (2019)
Mustafa, A., Hilton, A.: Semantically coherent co-segmentation and reconstruction of dynamic scenes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5583–5592 (2017)
Bansal, A., Vo, M., Sheikh, Y., Ramanan, D., Narasimhan, S.: 4D visualization of dynamic events from unconstrained multi-view videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5365–5374 (2020)
Bogo, F., Kanazawa, A., Lassner, C., Gehler, P., Romero, J., Black, M.J.: Keep It SMPL: automatic estimation of 3D human pose and shape from a single image. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 561–578 (2016)
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7122–7131 (2018)
Kanazawa, A., Zhang, J.Y., Felsen, P., Malik, J.: Learning 3D human dynamics from video. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5607–5616 (2019)
Kolotouros, N., Pavlakos, G., Black, M.J., Daniilidis, K.: Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 2252–2261 (2019)
Pavlakos, G., Kolotouros, N., Daniilidis, K.: TexturePose: supervising human mesh estimation with texture consistency. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 803–812 (2019)
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: a skinned multi-person linear model. ACM Trans. Graph. (TOG) 34, 248:1–248:16 (2015)
Pishchulin, L., Jain, A., Wojek, C., Andriluka, M., Thormälen, T., Schiele, B.: Learning people detection models from few training samples. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1473–1480 (2011)
Xu, F., et al.: Video-based characters: creating new human performances from a multi-view video database. ACM Trans. Graph. (TOG) 30, 32:1–32:10 (2011)
Siarohin, A., Lathuillère, S., Tulyakov, S., Ricci, E., Sebe, N.: first order motion model for image animation. In: Neural Information Processing Systems (NeurIPS) (2019)
Chen, X., Song, J., Hilliges, O.: Monocular neural image based rendering with continuous view control. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 4089–4099 (2019)
Bhatnagar, B.L., Tiwari, G., Theobalt, C., Pons-Moll, G.: Multi-garment net: learning to dress 3D people from images. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 5419–5429 (2019)
Alldieck, T., Magnor, M., Bhatnagar, B.L., Theobalt, C., Pons-Moll, G.: Learning to reconstruct people in clothing from a single RGB camera. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1175–1186 (2019)
Alldieck, T., Magnor, M., Xu, W., Theobalt, C., Pons-Moll, G.: Video based reconstruction of 3D people models. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8387–8397 (2018)
Ma, L., Jia, X., Sun, Q., Schiele, B., Tuytelaars, T., Van Gool, L.: Pose guided person image generation. In: Neural Information Processing Systems (NeurIPS) (2017)
Zhao, B., Wu, X., Cheng, Z.Q., Liu, H., Jie, Z., Feng, J.: Multi-view image generation from a single-view. In: Proceedings of the ACM International Conference on Multimedia (ACM-MM), pp. 383–391 (2018)
Zanfir, M., Oneata, E., Popa, A.I., Zanfir, A., Sminchisescu, C.: Human synthesis and scene compositing. In: Proceedings of the National Conference on Artificial Intelligence (AAAI), pp. 12749–12756 (2020)
Liu, W., Piao, Z., Jie, M., Luo, W., Ma, L., Gao, S.: Liquid war** GAN: a unified framework for human motion imitation, appearance transfer and novel view synthesis. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 5903–5912 (2019)
Li, Y., Huang, C., Loy, C.C.: Dense intrinsic appearance flow for human pose transfer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3688–3697 (2019)
Saito, M., Matsumoto, E., Saito, S.: Temporal generative adversarial nets with singular value clip**. In: Proceedings of the International Conference on Computer Vision (ICCV) (2017)
Tulyakov, S., Liu, M.Y., Yang, X., Kautz, J.: MoCoGAN: decomposing motion and content for video generation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1526–1535 (2018)
Vondrick, C., Pirsiavash, H., Torralba, A.: Generating videos with scene dynamics. In: Neural Information Processing Systems (NeurIPS) (2016)
Yang, C., Wang, Z., Zhu, X., Huang, C., Shi, J., Lin, D.: Pose guided human video generation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 204–219 (2018)
Wang, T.C., Liu, M.Y., Tao, A., Liu, G., Kautz, J., Catanzaro, B.: Few-shot video-to-video synthesis. In: Neural Information Processing Systems (NeurIPS) (2019)
Li, Y., Fang, C., Yang, J., Wang, Z., Lu, X., Yang, M.H.: Flow-grounded spatial-temporal video prediction from still images. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 609–625 (2018)
Raaj, Y., Idrees, H., Hidalgo, G., Sheikh, Y.: Efficient online multi-person 2D pose tracking with recurrent spatio-temporal affinity fields. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4615–4623 (2019)
Yang, L., Song, Q., Wang, Z., Jiang, M.: Parsing r-cnn for instance-level human analysis. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 364–373 (2019)
Siarohin, A., Sangineto, E., Lathuilière, S., Sebe, N.: Deformable GANs for pose-based human image generation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3408–3416 (2018)
Pumarola, A., Agudo, A., Sanfeliu, A., Moreno-Noguer, F.: Unsupervised person image synthesis in arbitrary poses. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8620–8628 (2018)
Liqian, M., Qianru, S., Stamatios, G., Luc, V.G., Bernt, S., Mario, F.: Disentangled Person Image Generation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 99–108 (2018)
Chan, C., Ginosar, S., Zhou, T., Efros, A.A.: Everybody dance now. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 5932–5941 (2019)
Esser, P., Sutter, E., Ommer, B.: A variational u-net for conditional appearance and shape generation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8857–8866 (2018)
Balakrishnan, G., Zhao, A., Dalca, A.V., Durand, F., Guttag, J.: Synthesizing images of humans in unseen poses. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8340–8348 (2018)
Qian, X., et al.: Pose-normalized image generation for person re-identification. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 661–678 (2018)
Raj, A., Sangkloy, P., Chang, H., Hays, J., Ceylan, D., Lu, J.: SwapNet: image based garment transfer. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 679–695 (2018)
Dong, H., Liang, X., Gong, K., Lai, H., Zhu, J., Yin, J.: Soft-gated war**-GAN for pose-guided person image synthesis. In: Neural Information Processing Systems (NeurIPS) (2018)
Alp Güler, R., Neverova, N., Kokkinos, I.: DensePose: dense human pose estimation in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7297–7306 (2018)
Neverova, N., Alp Guler, R., Kokkinos, I.: Dense pose transfer. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 128–143 (2018)
Shahroudy, A., Liu, J., Ng, T.T., Wang, G.: NTU RGB+D: a large scale dataset for 3d human activity analysis. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1010–1019 (2016)
Kato, H., Ushiku, Y., Harada, T.: Neural 3D mesh renderer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3907–3916 (2018)
Surazhsky, V., Surazhsky, T., Kirsanov, D., Gortler, S.J., Hoppe, H.: Fast exact and approximate geodesics on meshes. ACM Trans. Graph. (TOG) 24, 553–560 (2005)
Huber, P.J.: Robust estimation of a location parameter. Ann. Math. Stat. 35, 73–101 (1964)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 694–711 (2016)
Goodfellow, I., et al.: Generative adversarial nets. In: Neural Information Processing Systems (NeurIPS), pp. 2672–2680 (2014)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13, 600–612 (2004)
Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: FVD: a new metric for video generation. In: Proceedings of the International Conference on Learning Representations (ICLR) Workshops (2019)
Yang, Y., Ramanan, D.: Articulated human detection with flexible mixtures of parts. IEEE Trans. Pattern Anal. Mach. Intell. (PAMI) 35, 2878–2890 (2013)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. In: Proceedings of the International Conference on Learning Representations (ICLR) (2015)
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the International Conference on Computer Vision (ICCV), pp. 2242–2251 (2017)
Che, T., Li, Y., Jacob, A.P., Bengio, Y., Li, W.: Mode regularized generative adversarial networks. In: Proceedings of the International Conference on Learning Representations (ICLR) (2017)
Acknowledgements
This project acknowledges the use of the ESPRC funded Tier 2 facility, JADE.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Lakhal, M.I., Boscaini, D., Poiesi, F., Lanz, O., Cavallaro, A. (2021). Novel-View Human Action Synthesis. In: Ishikawa, H., Liu, CL., Pajdla, T., Shi, J. (eds) Computer Vision – ACCV 2020. ACCV 2020. Lecture Notes in Computer Science(), vol 12625. Springer, Cham. https://doi.org/10.1007/978-3-030-69538-5_26
Download citation
DOI: https://doi.org/10.1007/978-3-030-69538-5_26
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-69537-8
Online ISBN: 978-3-030-69538-5
eBook Packages: Computer ScienceComputer Science (R0)