
Abstract
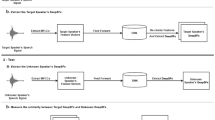
Speaker recognition is a biometric modality which utilize speaker’s speech segments to recognize identity, determining whether the test speaker belongs to one of the enrolled speakers. In order to improve the robustness of i-vector framework on cross-channel conditions and explore the nova method for applying deep learning to speaker recognition, the Stacked Auto-encoders is applied to get the abstract extraction of the i-vector instead of applying PLDA. After pre-processing and feature extraction, the speaker and channel independent speeches are employed for UBM training. The UBM is then used to extract the i-vector of the enrollment and test speech. Unlike the traditional i-vector framework, which uses linear discriminant analysis (LDA) to reduce dimension and increase the discrimination between speaker subspaces, this research use stacked auto-encoders to reconstruct the i-vector with lower dimension and different classifiers can be chosen to achieve final classification. The experimental results show that the proposed method achieves better performance than the-state-of-the-art method.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Atal, B.S., Hanaver, S.L.: Speech analysis and synthesis by linear prediction of the speech wave. J. Acoust. Soc. Am. 50(2), 637–655 (1971)
Doddington, G.R., Flanagan, J.L., Lummis, R.C.: Automatic speaker verification by non-linear time alignment of acoustic parameters (3700815) (1972)
Member, S.B.D.: Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. Read. Speech Recogn. 28(4), 65–74 (1990)
Reynolds, D.A., Quatieri, T.F., Dunn, R.B.: Speaker verification using adapted gaussian mixture models (2000)
Campbell, W.M.: Generalized linear discriminant sequence kernels for speaker recognition (2002)
Kenny, P.: Joint factor analysis of speaker and session variability: theory and algorithms. Technical report (2005)
Dehak, N., Kenny, P.J., Dehak, R., Dumouchel, P., Ouellet, P.: Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 19(4), 788–798 (2011)
Mclaren, M.L., Leeuwen, D.A.V.: Source-normalised IDA for robust speaker recognition using i-vectors. In: IEEE International Conference on Acoustics (2011)
Prince, S.J.D., Elder, J.H.: Probabilistic linear discriminant analysis for inferences about identity (2007)
Song, Y., Hong, X., Jiang, B., Cui, R., Mcloughlin, I.V., Dai, L.R.: Deep bottleneck network based i-vector representation for language identification (2015)
Matejka, P., Zhang, L., Ng, T., Mallidi, S.H., Glembek, O., Ma, J., Zhang, B.: Neural network bottleneck features for language identification. In: Proceedings of the Speaker and Language Recognition Workshop (Odyssey 2014), pp. 299–304 (2014)
Zhang, Z., Wang, L., Kai, A., Yamada, T., Li, W., Iwahashi, M.: Deep neural network-based bottleneck feature and denoising autoencoder-based dereverberation for distant-talking speaker identification. EURASIP J. Audio Speech Music Process. 2015(1), 12 (2015)
Campbell, W.M., Sturim, D.E., Reynolds, D.A.: Support vector machines using GMM supervectors for speaker verification. IEEE Signal Process. Lett. 13(5), 308–311 (2006)
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back propagating errors. Nature 323, 533–536 (1986)
Lamel, L.F., Gauvain, J.L.: A phone-based approach to non-linguistic speech feature identification. Comput. Speech Lang. 9(1), 87–103 (1995)
Bocklet, T., Maier, A., Bauer, J.G., Burkhardt, F., Noth, E.: Age and gender recognition for telephone applications based on GMM supervectors and support vector machines. In: IEEE International Conference on Acoustics (2008)
**a, R., Deng, J., Schuller, B., Liu, Y.: Modeling gender information for emotion recognition using denoising autoencoder. In: IEEE International Conference on Acoustics (2014)
Shafey, L.E., Khoury, E., Marcel, S.: Audio-visual gender recognition in uncontrolled environment using variability modeling techniques. In: IEEE International Joint Conference on Biometrics (2014)
Acknowledgements
This research was supported by National Natural Science Foundation of China (No.61901165, 61501199), Science and Technology Research Project of Hubei Education Department (No. Q20191406), Hubei Natural Science Foundation (No. 2017CFB683), and self-determined research funds of CCNU from the colleges’ basic research and operation of MOE (No. CCNU20ZT010).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Wang, Z., Zeng, C., Duan, S., Ouyang, H., Xu, H. (2021). Robust Speaker Recognition Based on Stacked Auto-encoders. In: Barolli, L., Li, K., Enokido, T., Takizawa, M. (eds) Advances in Networked-Based Information Systems. NBiS 2020. Advances in Intelligent Systems and Computing, vol 1264. Springer, Cham. https://doi.org/10.1007/978-3-030-57811-4_38
Download citation
DOI: https://doi.org/10.1007/978-3-030-57811-4_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-57810-7
Online ISBN: 978-3-030-57811-4
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)