
Abstract
The recent success of question answering systems is largely attributed to pre-trained language models. However, as language models are mostly pre-trained on general domain corpora such as Wikipedia, they often have difficulty in understanding biomedical questions. In this paper, we investigate the performance of BioBERT, a pre-trained biomedical language model, in answering biomedical questions including factoid, list, and yes/no type questions. BioBERT uses almost the same structure across various question types and achieved the best performance in the 7th BioASQ Challenge (Task 7b, Phase B). BioBERT pre-trained on SQuAD or SQuAD 2.0 easily outperformed previous state-of-the-art models. BioBERT obtains the best performance when it uses the appropriate pre-/post-processing strategies for questions, passages, and answers.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Language models pre-trained on large-scale text corpora achieve state-of-the-art performance in various natural language processing (NLP) tasks when fine-tuned on a given task [4, 13, 15]. Language models have been shown to be highly effective in question answering (QA), and many current state-of-the-art QA models often rely on pre-trained language models [20]. However, as language models are mostly pre-trained on general domain corpora, they cannot be generalized to biomedical corpora [1, 2, 8, 29]. Hence, similar to using Word2Vec for the biomedical domain [14], a language model pre-trained on biomedical corpora is needed for building effective biomedical QA models.
Recently, Lee et al. [8] have proposed BioBERT which is a pre-trained language model trained on PubMed articles. In three representative biomedical NLP (bioNLP) tasks including biomedical named entity recognition, relation extraction, and question answering, BioBERT outperforms most of the previous state-of-the-art models. In previous works, models were used for a specific bioNLP task [9, 18, 24, 28]. However, the structure of BioBERT allows a single model to be trained on different datasets and used for various tasks with slight modifications in the last layer.
In this paper, we investigate the effectiveness of BioBERT in biomedical question answering and report our results from the 7th BioASQ Challenge [7, 10, 11, 21]. Biomedical question answering has its own unique challenges. First, the size of datasets is often very small (e.g., few thousands of samples in BioASQ) as the creation of biomedical question answering datasets is very expensive. Second, there are various types of questions including factoid, list, and yes/no questions, which increase the complexity of the problem.
We leverage BioBERT to address these issues. To mitigate the small size of datasets, we first fine-tune BioBERT on other large-scale extractive question answering datasets, and then fine-tune it on BioASQ datasets. More specifically, we train BioBERT on SQuAD [17] and SQuAD 2.0 [16] for transfer learning. Also, we modify the last layer of BioBERT so that it can be trained/tested on three different types of BioASQ questions. This significantly reduces the cost of using biomedical question answering systems as the structure of BioBERT does not need to be modified based on the type of question.
The contributions of our paper are three fold: (1) We show that BioBERT pre-trained on general domain question answering corpora such as SQuAD largely improves the performance of biomedical question answering models. Wiese et al. [25] showed that pre-training on SQuAD helps improve performance. We test the performance of BioBERT pre-trained on both SQuAD and SQuAD 2.0. (2) With only simple modifications, BioBERT can be used for various biomedical question types including factoid, list, and yes/no questions. BioBERT achieves the overall best performance on all five test batches of BioASQ 7b Phase BFootnote 1, and achieves state-of-the-art performance in BioASQ 6b Phase B. (3) We further analyze the role of pre- and post-processing in our system and show that different strategies often lead to different results.
The rest of our paper is organized as follows. First, we introduce our system based on BioBERT. We describe task-specific layers of our system and various pre- and post-processing strategies. We present the results of BioBERT on BioASQ 7b (Phase B), which were obtained using two different transfer learning strategies, and we further test BioBERT on BioASQ 6b on which our system was trained.
2 Methods
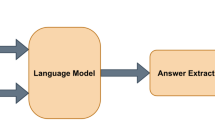
In this section, we will briefly discuss BioBERTFootnote 2 [8] and our modificationsFootnote 3 for the BioASQ Challenge (Fig. 1).

Overview of our system
2.1 BioBERT
Word embeddings are crucial for various text mining systems since they represent semantic and syntactic features of words [14, 22]. While traditional models use context-independent word embeddings, recently proposed models use contextualized word representations [4, 13, 15]. Among them, BERT [4], which is built upon multi-layer bidirectional Transformers [23], achieved new state-of-the-art results on various NLP tasks including question answering. BioBERT [8] is the first domain-specific BERT based model pre-trained on PubMed abstracts and full texts. BioBERT outperforms BERT and other state-of-the-art models in bioNLP tasks such as biomedical named entity recognition, relation extraction, and question answering [6, 19].
An input representation of BioBERT for a given token is composed of the corresponding token, segment, and position embeddings. BioBERT utilizes WordPiece embeddings [26] which use sub-word units to address the out-of-vocabulary (OOV) problem. Broken sub-word units are denoted by ## (e.g. organoid = organ + ##iod). Positional embeddings are learned during training and segment embeddings are used to mark the location of question and passage tokens in the input sequence. Following the design of BERT, a special token embedding for [CLS] was added to the beginning of every sequence to process yes/no type questions.

Example of a single sequence (Question-Passage pair) processed by the BioBERT.
2.2 Task-Specific Layer
The BioBERT model for QA is illustrated in Fig. 2. Following the approach of BioBERT [8], a question and its corresponding passage are concatenated to form a single sequence which is marked by different segment embeddings. The task-specific layer for factoid type questions and the layer for list type questions both utilize the output of the passage whereas the layer for yes/no type questions uses the output of the first [CLS] token.
Factoid and List Questions. In (Bio)BERT, the only additional trainable parameters needed for factoid and list type questions are the softmax layer for a linear transformation of hidden vectors from BioBERT. Following the notation used in the BERT study, we denote the trainable start vector as \(S \in \mathbb {R}^H\) and the trainable end vector as \(E \in \mathbb {R}^H\) where H denotes the hidden size of BioBERT. The probabilities of the i-th token being the start of the answer token and the j-th token being the end of the answer token can be calculated by the following equations:
where \(T_l \in \mathbb {R}^H\) denotes l-th token representation from BioBERT and \(\cdot \) denotes the dot product between two vectors.
Yes/No Questions. We use the first [CLS] for the classification of yes/no questions. Here, we denote the representation of the [CLS] token from BioBERT as \(C \in \mathbb {R}^H\). The parameter learned during training is a sigmoid layer consisting of \(W \in \mathbb {R}^{H}\) which is used for binary classification. The probability for the sequence to be “yes” is calculated using the following equation.
Loss. For the factoid/list question layer, we minimize Loss during training, which is defined below. Loss is the arithmetic mean of the \(Loss_{start}\) and \(Loss_{end}\), which correspond to the negative log-likelihood for the correct start and end positions, respectively. The ground truth start/end positions are denoted as \(y_s\) for the start token, and \(y_e\) for the end token. The losses are defined as follows:
where k iterates for a mini-batch of size N.
For yes/no questions, the binary cross entropy between probability \(P_{yes}\) and the corresponding ground truth was used as the training loss.
2.3 Pre-processing
3 Experimental Setup
3.1 Dataset
For factoid and list type questions, exact answers are included in the given snippets, which is consistent with the extractive QA setting of the SQuAD [17] dataset. Only binary answers are provided for yes/no questions. For each question, regardless of the question type, multiple snippets or documents are provided as corresponding passages.
The statistics of the BioASQ datasets are listed in Table 1. A list type question can have one or more than one answer; question-context pairs are made for every answer of a list type question. In our pre-processing step, 3,722 question-context pairs were made from 779 factoid questions in the BioASQ 7b training set. For yes/no questions, we undersampled the training data to balance the number of “yes" and “no" answers.
About 28.2% of factoid type questions and 5.6% of list type questions in the BioASQ 7b training set do not have an answer in their corresponding snippets. We excluded unanswerable questions, following the approach of Wiese et al. [24].
3.2 Training
Our system is composed of BioBERT, task-specific layers, and a post-processing layer. The parameters of BioBERT and a task-specific layer are trainable. Our training procedure starts with pre-training the system on the SQuAD dataset. The trainable parameters for factoid and list type questions were pre-trained on the SQuAD 1.1 dataset, and the parameters for yes/no type questions were pre-trained on the SQuAD 2.0 dataset. The pre-trained system is then fine-tuned on each task.
We tuned the hyperparameters on the BioASQ 4/5/6b training and test sets. We used a probability threshold of 0.42 as one of the hyperparameters for list type questions. The probability threshold was decided using the tuning procedure.
4 Results and Discussion
In this section, we first report our results for the BioASQ 7b (Phase B) Challenge, which are shown in Table 2. Please note that the results and ranks were obtained from the leaderboard of BioASQ 7b [3]. Then we evaluate our system and other competing systems on the validation set (BioASQ 6b). The results are presented in Table 3. Finally, we investigate the performance gain due to the sub-structures of the system (Tables 5 and 6). Mean reciprocal rank (MRR) and mean average F-measure (\(F_1\)) were used as official evaluation metrics to measure the performance on factoid and list type questions from BioASQ, respectively. We reported strict accuracy (SAcc), lenient accuracy (LAcc) and MRR for factoid questions and mean average precision, mean average recall, and mean average F1 score for list questionsFootnote 4. Since the label distribution was skewed, macro average F1 score was used as an evaluation metric for yes/no questions.
4.1 Results on BioASQ 7b
Our results on Task 7b (Phase B) of the BioASQ Challenge are reported in Table 2. Each participant can submit up to 5 systems per batch. We submitted 1 to 5 systems which use different combinations of pre- and post-processing strategies. We report the rankings and scores of our best performing system and those of other competing systems for each task in Table 2. Competing systems are the best and second best systems, other than our system, from distinct participants. Manually corrected gold-standard answers are not yet available at the time of writing; therefore, we report the scores based on the online leaderboardFootnote 5.
4.2 Validating on the BioASQ 6b Dataset
We compared the performance of existing systems and our system on the BioASQ 6b dataset from the last year (2018), which is shown in Table 3. We micro averaged the scores from five experiments and reported the scores in Table 3. Similarly, the leaderboard scores of the best performing system for each batch were micro averaged and reported as the Best System scores [5, 12, 27]. Our system obtained much higher scores on the BioASQ 6b dataset than the top systems from leaderboard of BioASQ 6b Challenge.
Pre-training. In Table 4, we compare the performance of the pre-trained models. BioBERT fine-tuned on the BioASQ 6b dataset outperformed BERTBASE fine-tuned on BioASQ in both factoid and list type questions. BioBERT first pre-trained on SQuAD and then fine-tuned on BioASQ 6b obtained the best performance over other two experiments, demonstrating the effectiveness of pre-training BioBERT on SQuAD, a comprehensive and large-scale question answering corpus.
Pre-/Post-processing. The performance of our system is largely affected by how the data is pre-processed (Table 5). However, the effectiveness of the pre-processing strategy varies depending on the type of question. For example, the Appended Snippet strategy and Full Abstract strategy obtained good performance on factoid questions, while the Snippet As-is strategy achieved the highest performance on list and yes/no type questions. Table 6 shows the effect of post-processing on the performance of a system evaluated on list type questions. In our study, both extracting the number of answers from questions and filtering predicted answers were effective.
Ensemble. Starting from test batch 4 of BioASQ 7b, we submitted model ensemble results as one of our systems. The performance gain of the model ensemble on our evaluation set was relatively small; the performance ranged from 0.2% to 2% depending on the task. The model ensemble improved the performance on factoid questions the most (2% gain), but applying the model ensemble to list questions did not obtain higher performance than the single model. Although the model ensemble obtained high scores in the BioASQ 7b Challenge, it could only obtain the highest score on factoid type questions in batch 5.
Qualitative Analysis. In Table 7, we show three predictions generated by our system on the BioASQ 6b factoid dataset. Due to the space limitation, we show only small parts of a passage, which contain the answers (predicted answers might be contained in other parts of the passage). We show the top five predictions generated by our system which can also be used for list type questions. In the first example, our system successfully finds the answer and other plausible answers. The second example shows that most of the predicted answers are correct and have only minor differences. In the last example, we observe that the ground truth answer does not exist in the passage. Also, the predicted answers are indeed correct despite the incorrect annotation.
The prediction result of list question from the BioASQ 6b is presented in Table 8. We found that our system is more likely to produce incorrect predictions on list questions than on factoid questions. Our system internally outputs a list of predictions and the list is likely to include prediction with erroneous span. Even though incorrect prediction (“JBP”) with erroneous span has a lower probability than the true prediction (“JBP1” and “JBP2”), it can have considerable absolute probabilities. On factoid questions, selecting a top one answer is required. Hence we can ignore incorrect prediction on factoid questions. On the contrary, on list questions, prediction with erroneous span gets higher probability through merging predictions in post-processing step. Since our model utilizes fixed threshold value, prediction with erroneous span is imperfect but achieved a higher possibility than the threshold.
5 Conclusion
In this paper, we proposed BioBERT based QA system for the BioASQ biomedical question answering challenge. As the size of the biomedical question answering dataset is very small, we leveraged pre-trained language models for biomedical domain which effectively exploit the knowledge from large biomedical corpora. Also, while existing systems for the BioASQ challenge require different structures for different question types, our system uses almost the same structure for various question types. By exploring various pre-/post-processing strategies, our BioBERT based system obtained the best performance in the 7th BioASQ Challenge, achieving state-of-the-art results on factoid, list, and yes/no type questions. In future work, we plan to further systematically analyze the incorrect predictions of our systems, and develop biomedical QA systems that can eventually outperform humans.
Notes
- 1.
- 2.
The source code for BioBERT is available at https://github.com/dmis-lab/biobert.
- 3.
The source code and pre-processed datasets are available at https://github.com/dmis-lab/bioasq-biobert.
- 4.
For more details, please visit http://participants-area.bioasq.org/Tasks/b/eval_meas_2018/.
- 5.
The official results of the competition will be provided at http://bioasq.org.
References
Alsentzer, E., et al.: Publicly available clinical BERT embeddings. ar**v preprint ar**v:1904.03323 (2019)
Beltagy, I., Cohan, A., Lo, K.: SciBERT: pretrained contextualized embeddings for scientific text. ar**v preprint ar**v:1903.10676 (2019)
BioASQ Participants Area BioASQ, May 2019. http://participants-area.bioasq.org/results/7b/phaseB/
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. ar**v preprint ar**v:1810.04805 (2018)
Dimitriadis, D., Tsoumakas, G.: Word embeddings and external resources for answer processing in biomedical factoid question answering. J. Biomed. Inform. 92, 103118 (2019)
Kim, D., et al.: A neural named entity recognition and multi-type normalization tool for biomedical text mining. IEEE Access 7, 73729–73740 (2019)
Krithara, A., Nentidis, A., Paliouras, G., Kakadiaris, I.: Results of the 4th edition of BioASQ challenge. In: Proceedings of the Fourth BioASQ Workshop, Berlin, Germany, August 2016, pp. 1–7. Association for Computational Linguistics (2016). https://doi.org/10.18653/v1/W16-3101, https://www.aclweb.org/anthology/W16-3101
Lee, J., et al.: BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics (2019). https://doi.org/10.1093/bioinformatics/btz682
Lim, S., Kang, J.: Chemical–gene relation extraction using recursive neural network. Database 2018 (2018)
Nentidis, A., Bougiatiotis, K., Krithara, A., Paliouras, G., Kakadiaris, I.: Results of the fifth edition of the BioASQ challenge. In: BioNLP 2017, pp. 48–57 (2017)
Nentidis, A., Krithara, A., Bougiatiotis, K., Paliouras, G., Kakadiaris, I.: Results of the sixth edition of the BioASQ challenge. In: Proceedings of the 6th BioASQ Workshop A Challenge on Large-Scale Biomedical Semantic Indexing and Question Answering, Brussels, Belgium, November 2018, pp. 1–10. Association for Computational Linguistics (2018). https://www.aclweb.org/anthology/W18-5301
Peng, S., Zhang, Y., You, R., **e, Z., Wang, B., Zhu, S.: The fudan participation in the 2015 BioASQ challenge: large-scale biomedical semantic indexing and question answering. In: CEUR Workshop Proceedings, vol. 1391. CEUR Workshop Proceedings (2015)
Peters, M., et al.: Deep contextualized word representations. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 2227–2237 (2018)
Pyysalo, S., Ginter, F., Moen, H., Salakoski, T., Ananiadou, S.: Distributional semantics resources for biomedical text processing. In: Proceedings of LBM, pp. 39–44 (2013)
Radford, A., Narasimhan, K., Salimans, T., Sutskever, I.: Improving language understanding with unsupervised learning. Technical report, OpenAI (2018)
Rajpurkar, P., Jia, R., Liang, P.: Know what you don’t know: unanswerable questions for squad. ar**v preprint ar**v:1806.03822 (2018)
Rajpurkar, P., Zhang, J., Lopyrev, K., Liang, P.: SQuAD: 100,000+ questions for machine comprehension of text. ar**v preprint ar**v:1606.05250 (2016)
Rosso-Mateus, A., González, F.A., Montes-y Gómez, M.: MindLab neural network approach at BioASQ 6B. In: Proceedings of the 6th BioASQ Workshop A Challenge on Large-Scale Biomedical Semantic Indexing and Question Answering, pp. 40–46 (2018)
Sousa, D., Lamurias, A., Couto, F.M.: Using neural networks for relation extraction from biomedical literature. ar**v preprint ar**v:1905.11391 (2019)
Talmor, A., Berant, J.: MultiQA: an empirical investigation of generalization and transfer in reading comprehension. ar**v preprint ar**v:1905.13453 (2019)
Tsatsaronis, G., et al.: An overview of the BioASQ large-scale biomedical semantic indexing and question answering competition. BMC Bioinform. 16(1), 138 (2015)
Turian, J., Ratinov, L., Bengio, Y.: Word representations: a simple and general method for semi-supervised learning. In: Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, pp. 384–394. Association for Computational Linguistics (2010)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Wiese, G., Weissenborn, D., Neves, M.: Neural domain adaptation for biomedical question answering. ar**v preprint ar**v:1706.03610 (2017)
Wiese, G., Weissenborn, D., Neves, M.: Neural question answering at BioASQ 5B. ar**v preprint ar**v:1706.08568 (2017)
Wu, Y., et al.: Google’s neural machine translation system: bridging the gap between human and machine translation. ar**v preprint ar**v:1609.08144 (2016)
Yang, Z., Zhou, Y., Nyberg, E.: Learning to answer biomedical questions: OAQA at BioASQ 4B. In: Proceedings of the Fourth BioASQ Workshop, pp. 23–37 (2016)
Yoon, W., So, C.H., Lee, J., Kang, J.: CollaboNet: collaboration of deep neural networks for biomedical named entity recognition. BMC Bioinform. 20(10), 249 (2019)
Zhu, H., Paschalidis, I.C., Tahmasebi, A.: Clinical concept extraction with contextual word embedding. ar**v preprint ar**v:1810.10566 (2018)
Acknowledgements
We appreciate Susan Kim for editing the manuscript. This work was funded by the National Research Foundation of Korea (NRF-2017R1A2A1A17069645, NRF-2016M3A9A7916996) and the National IT Industry Promotion Agency grant funded by the Ministry of Science and ICT and Ministry of Health and Welfare (NO. C1202-18-1001, Development Project of The Precision Medicine Hospital Information System (P-HIS)).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Yoon, W., Lee, J., Kim, D., Jeong, M., Kang, J. (2020). Pre-trained Language Model for Biomedical Question Answering. In: Cellier, P., Driessens, K. (eds) Machine Learning and Knowledge Discovery in Databases. ECML PKDD 2019. Communications in Computer and Information Science, vol 1168. Springer, Cham. https://doi.org/10.1007/978-3-030-43887-6_64
Download citation
DOI: https://doi.org/10.1007/978-3-030-43887-6_64
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-43886-9
Online ISBN: 978-3-030-43887-6
eBook Packages: Computer ScienceComputer Science (R0)
