
Abstract
Recently, advances in neuroscience have attracted attention to the diagnosis, treatment, and damage to schizophrenia-associated brain regions using resting-state functional magnetic resonance imaging (rs-fMRI). This research is immersed in the endowment of machine learning approaches for discriminating schizophrenia patients to provide a viable solution. Toward these goals, firstly, we implemented a two sample t-tests to find the activation difference between schizophrenia patients and healthy controls. The average activation in control is higher than the average activation of the patient. Secondly, we implemented the correlation technique to find variations on presumably hidden associations between brain structure and its associated function. Moreover, current results support the viewpoint that the resting-state function integration is helpful to gain insight into the pathological mechanism of schizophrenia. Finally, Lasso regression is used to find a low-dimensional integration of the rs-fMRI and their experimental results showed that SVM classifier surpasses nine algorithms provided the best results with good accuracy of 94%.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Schizophrenia is a complex mental disorder that can affect people's behavior, such as delusion, hallucination, and attention distraction. The diagnosis of a psychiatric disability such as schizophrenia is mainly based solely on clinical manifestations. However, the causes of heterogeneous symptoms, including perception, memory, attention, and other negative symptoms, are critical to future treatments. The validity of the disease limits remains unclear due to significant overlaps with other psychotic disorders. Primarily, the psychiatric symptoms were diagnosed through quantifiable examinations in order to achieve reliability.
The recent emphasis on dimensional approaches and criteria in translational bio-behavior research could help achieve a neuroscientific definition of schizophrenia. The focus of current advances in classifying schizophrenia patients from healthy control has focused on the biomarkers implementation [1–3]. This promoted the discovery of reliable biomarkers for the efficient and prompt treatment of schizophrenia patients. Efforts have recently been made to use functional magnetic resonance imaging (fMRI) of the whole brain to examine potential neuronal markers for schizophrenia and to better understand the pathology of schizophrenia that can be incorporated into clinical practice. Resting-state functional resonance imaging (rs-fMRI) is an active device for discovering impaired functional connectivity in the organization of the cerebrum that is relevant to cognitive abilities and disease status. Compared to task fMRI, rs-fMRI has no stimuli and is, therefore, easier to standardize. Since then, the researchers have considered rs-fMRI as a distinctive method for assessing the regional brain structures and functions in vitro of brain disorders. In order to uncover the features of the intrinsic functional brain organization, Resting-state functional connectivity as measured by fMRI, is a promising neuro-marker for characterizing the cognitive decline. [1, www.fil.ion.ucl.ac.uk/spm/) and MATLAB. During fMRI experiments, the head movement of the subject can possible. The movement of the head may occur in six directions where three translations and three rotations. To realign or correct an fMRI (time series of images) acquired from the same subject, we have used a least squares approach and a 6-parameter spatial transformation. The head movement of fMRI data can be adjusted by using a 6-parameter (3 translations, 3 rotations) spatial transformation in the statistical parametric map** (SPM) package. Using the realignment option in SPM the head movement was adjusted if the ranges of a translation vary between − 1 and + 1 mm and rotation vary between − 1 and + 1°. Ranges of translation and rotation depend upon the fMRI experiment and preprocessing steps. We will choose only those subject fMRI data which have head motion in the SPM-defined ranges. Beyond in this specific range, we excluded the fMRI experiments data for further analysis.
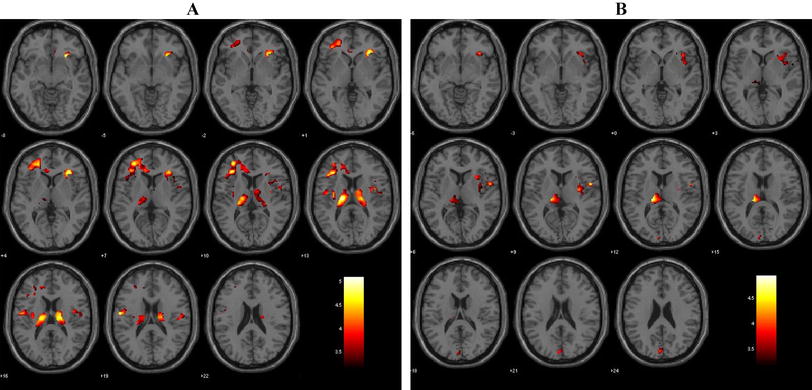
In our data the translation ranges were between − 0.2 and 1, and the rotation range mostly between − 0.5 and + 0.5. Then we normalized the individual data to transform the brain in MNI / EPI format so that we could apply the parameters of fMRI images. The smoothing depends on the Gaussian curve in SPM. After the realignment and normalization, we smoothed the images with a 8 × 8 × 8 mm Gaussian filter. After specifying the model, the next step is the estimation. All the subjects participating in the experiment differ in how contrasts are used. We used two types of contrast to estimate beta images: T-test and F-test. Contrast (1, 0) is used to activate schizophrenia and healthy control in this experiment. Next, we define the threshold p (0.05, 0.01, and 0.001) and the expansion value 0. We used the anatomical overlays better to view the activated area and the voxel's position, as shown in Fig. 1.

Glass brain view shows the activation in control and patient
Figure 1 shows the activation of control and SZC patients in anatomical overlays. The color bar shows the activated area and the t-value. This image has a much better view of the activated area of the brain. We appreciate that the healthy control has a more activated area of the brain regions than schizophrenia patients.
2.3 Functional connectivity measure
Four major and five sub Brodmann area (BAs: https://en.wikipedia.org/wiki/Brodmann_area) of brain are selected for regions of interests (ROIs), namely Hippocampus, Frontal Lobe, Occipital Lobe, Temporal Lobe, BA9, BA10, BA19, BA42, and BA47 which play important role in the human brain to controls the motions thinking and behavior. According to different reported studies, in the schizophrenia patient BA9, BA10, BA19, BA42 areas (neurons) are not behaving normally. Studies have also identified hippocampus, and selected BAs the most effected brain region in schizophrenic patients [1, 2]. To extract morphological patterns of the brain, all selected genres of learning algorithms have successfully classified patients from healthy controls with satisfactory classification accuracy (> 90%) using data of all regions.
To examine the correlation of activation obtained, this study also utilized the independent sample t-test and multivariate analysis of variance (MANOVA).
2.4 Rationale for the approach
One contribution of our work is to find a machine learning architecture that performs significantly better from several popular machine algorithms in terms of the performance level of generality and confirms the effectiveness of the proposed model for classifying schizophrenic subjects. Before proceeding with computational procedures, we will give a general rationale for the approaches used and outline the starting points for traditional inference-based approaches. Traditionally, statistical inference approaches have been used in brain imaging to identify significant differences between data from different populations, such as voxel-based morphometry (VBM) or in the analysis of task-based fMRI data. This traditional approach addresses the problem at the voxel level. For each voxel, the independent decision has been taken to reject the null hypothesis without differences between groups. For the known null hypothesis, the problem for each voxel is reduced to the calculation of a single threshold. Randomness avoids false positives when correcting multiple comparisons when the number of tests is large. It can reduce the detection of actual signals during multiple comparison corrections and increase the ratio. In contrast, machine learning is a more holistic approach, which is to decide on the subject as an entity. Machine learning does not emphasize the existence of statistically significant differences in voxels. Instead of assigning credit to each voxel, the purpose is to extract features that contribute to the overall classification performance. We are now formally presenting the algorithms we used to study the difference in brain structure between normal subjects and patients with schizophrenia, along with experimental parameters.
2.4.1 Independent sample t-test
We used standardized correlation matrices to evaluate functional connectivity. To determine the difference in significance for the selected brain ROIs in patient and healthy control group. We have used an independent sample t-test to compare the means of two independent groups. Hippocampus, occipital, frontal, temporal, Brodmann (areas 9, 10, 19, 42) and Brodmann (area 47).
where, y = variable and m = sample size.
Equation (1) represents formula of two independent sample t test, \(\overline{{y_{1} }}\) represents mean of first group and \(\overline{{y_{2} }}\) represents mean of second group, \({\text{sc}}\) represents combined standard deviation and \(m_{1}\) and \(m_{2}\) are number of observations of group 1 and 2, respectively. Equation (2) represents formula of combined standard deviation and \(s_{1}^{2}\) and \(s_{2}^{2}\) are standard deviations of group 1 and 2, respectively.
2.4.2 Artificial neural networks
An artificial neural network (ANN) is a self-learning approach inspired by biological neural networks. ANN is ideally designed for modeling agricultural and biological data that are complex and often nonlinear [12]. ANN contains the feed-forward network to recognize the patterns. Back propagation is a commonly used algorithm for training feedforward neural networks to predict the results of complex and outreach models. Following steps illustrate the architecture of processing units of ANN.
Step 1 compute the local slopes for the nodes:
Equation (3) represents the sigmoid activation function used in neural network for the classification purpose.
Step 2 calculating weights by using the learning rule:
In Eq. (4), \(w_{{\left( {m + 1} \right)}}\) represents the new weighted matrix.
Calculating bias term for moving activation function by following equation:
In this way, we calculate new values for weights and biases term for the classification.
2.4.3 Support vector machine
To distinguish patients from healthy controls, we conducted an analysis of machine learning algorithm named Support Vector Machine (SVM) in this study [13]. If the data is linear, SVM aims to find a hyperplane that maximizes the distance between the two classes. In addition, SVM appear to be particularly beneficial when data classes are heterogeneous with few training samples [14]. SVM can adapt nonlinear classifiers through a method called kernel trick. To separate the data linearly, the nonlinear SVM assigns the data to a higher-dimensional space. There exist several kernel functions that can be performed in nonlinear SVM. In this study, we used linear SVM and nonlinear SVM with radial basis function (RBF) and Gaussian kernels.
The Decision Surface (Hyperplane) used was:
where, xi are independent variables and wi are weight vectors (w0, w1, w2, w3……wd).
Now, \(y_{i} (W^{t} x_{i} + B) \le - 1\) for negative and \(y_{i} (W^{t} x_{i} + B) \ge 1\) for positive.
2.4.4 Naive bayes classifier
In our study, we also compare the performance of a normative model with traditional classification approaches. In the 1960s, normative models like the Bayes theorem were used as rough descriptions of judgment and decision behavior. Nevertheless, normative models, especially Bayes' theorem, still play a special role in decision research [18]. On the one hand, this is because they remain an important benchmark for rationality, and on the other hand, it is due to the view that the computing goals of the human brain are naturally Bayesian. At least one alternative hypothesis must test each hypothesis for medical diagnosis. The structuring of the hypothesis space must base on the probability rate. We consider Bayes' theorem to illustrate the difficulty in defining the hypothesis space for classification as:
Over outcome class variable, C with few classes or results, preventive on a few component factors H1 over Hn. Applying Bayes hypothesis, we combine
Equation (7) can be written as
Presently the Naive dependent freedom assumptions grow to be per chance the most necessary factor: receive that each aspect Hi is restrictively independent of every different component Hi for i ≠ j. This denotes:
For i ≠ j thus double model can explained as
This suggests under the above individuality possibilities; the prohibitive transport over the class variable 'C' can be informed along these lines
where S is a scaling factor secondary just on H1, H2, H3, …, Hm. Models of this form are appreciably extra sensible, for the reason that they aspect into a supposed category before P(C) and self-sufficient probability distributions P(Hi|C).
2.4.5 Quadratic discriminant analysis
The quadratic discriminant analysis differs from the linear discriminant analysis. In which the covariance matrix is estimated for each observation or data class. A quadratic discriminant analysis is particularly advantageous if you have prior knowledge that character classes have excellent covariance. A disadvantage of QDA is that it cannot be used as a method to reduce dimensionality. In quadratic discriminant analysis, we estimate covariance matrix (Σm) for each class m ∈ {1,…,M} instead of assuming Σm = Σ as in linear discriminant analysis.
Quadratic Discriminant Function:
In Eq. (13) \(\left( {x - \mu_{{\text{m}}} } \right)\) is deviation term from mean and \(\sum m\) is covariance matrix. Plugging \(\delta_{{\text{m}}} \left( x \right)\) in classification function we get classification rule,
where \(\delta_{{\text{m}}} \left( x \right)\) is discriminant function for class \(m\).
The classification rule is also related. You simply discover the class 'm' that extends the quadratic discriminant function. The selection limits are quadratic conditions in 'x'. A nonlinear Quadratic discriminant analysis (QDA) offers more flexibility for the covariance matrix and generally fits the data that is superior to linear discriminant analysis. Then, however, more parameters must be evaluated. QDA increased the parameters significantly. It provided better classification.
2.4.6 Decision tree
A decision tree (DT) is a powerful instrument used for classification and prediction. A DT is a flowchart work like a tree structure, where each internal node denotes a test on an attribute, each branch of the tree represents the test results, and each terminal node holds a class mark. DT is a kind of supervised learning; therefore, its algorithm links to the supervised learning algorithm; its algorithm is easy compared to other classifications. The common purpose of using DT is to generate the training model for class prediction by indirectly learning decision procedures from training data (prior data). Data variables comprise a vector of independent variables x = (x1, x2,…, xm) and y a dependent variable or target variable.
2.4.7 Reducing the dimensionality using lasso regression
To find the low-dimensional representation of abnormal resting-state functional connectivity patterns in patients, we used least absolute shrinkage and selection operator (LASSO) approach [15]. As a regression-based algorithm, LASSO approach can effectively identify the low-dimensional manifold structure associated with schizophrenia. In addition, the LASSO contributes to improving the predictive accuracy and the interpretability of the model by eliminating irrelevant variables not related to the response variable. This will also reduce overfitting. The Lasso regression model can be expressed as:
Lasso regression model used to remove multicollinearity problem in equation. In Eq. (15) \(\beta\) represents regression coefficient, \(x\) represents independent variables and \(y\) is dependent variable. λ is consider basically the amount of shrinkage that controls the strength. When λ = 0, no parameters are removed but if λ = 1, some parameters are removed. If λ increases, then the bias increases, and if λ decreases, then the variance increases.
2.5 Performance evaluation
We carried out the experiments in Python with the libraries Tensorflow v.1.4 [16] and Keras v.2.1 (https://keras.io/). We used the same validation division for every set of experiments. To quantify the performance of classifiers, we utilized Sensitivity (SS), Specificity (SC), Prevalence rate of disease (PRD), Positive and Negative predictive value (PPV and NPV), and Positive and Negative likelihood ratio (LR + and LR −), that are defined as:
where TP, TN, FP, and FN represent the number of correctly patients predicted, controls predicted correctly, controls predicted as patients, and patients predicted as controls. The sensitivity (SS) represents the proportion of patients in a papulation that were correctly predicted, while the proportion of controls that were correctly predicted is represented by the specificity (SC). The overall utility of diagnostic test was evaluated by the Likelihood ratios (LR).
3 Results
In this study, we applied k-fold cross-validation to classify the difference in brain structure between normal patients and schizophrenia patients by using eleven different classification methods (Linear and Nonlinear SVM, QDA, Gaussian Process, Nearest Neighbors, Neural Net, NaiveBayese, XgBoost, Adaboost, Decision Tree, and Random Forest). We used an independent sample t-test to determine functional activation, and correlation coefficients to verify functional connectivity in regions of interest (ROIs) and feature ranking method LASSO [16].
3.1 Independent two sample t-test results
We used an independent sample t-test to determine functional activation between regions of schizophrenia patients and healthy control. Table 1 shows a significant difference in mean activation in the Brodmann regions of the control and the schizophrenia patients (t-value = 380.7, p < 0.005). The average activation in the Brodmann control area is 33% higher than the average activation for the patient. There is a significant difference in mean activation in occipital between control and patient (t value = 635.4, p < 0.005).
Figure 2 illustrates the difference in activation between schizophrenia patients and healthy control in selected regions. The activation in healthy control regions (HC, OP, TR, FT BA 9, 10, 19, 42, and 47) is higher than in patients regions. Figures 3 and 4 show the correlation coefficients of patient and control functional connectivities in regions of interest (ROIs). A higher R-value refers to higher functional connectivity between regions of interest (ROIs).

Voxels activation of healthy controls and patients in the 9 ROIs of the brain

Correlations among ROIs of patients

Correlations among ROIs of healthy controls
Figures 3 and 4 show greater positive functional connectivity between ROIs in the schizophrenia patients and healthy control, respectively. Occipital Lobe, Frontal Lobe, Brodmann Areas 9, 10, 19, and 42 have higher positive functional connectivity. It also shows that all regions are highly connected.
3.2 Predictive power of different classification techniques
We have analyzed what is the best machine learning algorithm to classify the selected disease genre after comparing eleven standard machine learning algorithms in all selected regions as shown in Fig. 5. We used direct K-fold (fold = 8) cross validation scheme in the classification process for reliable results.

Visualize the accuracy of all machine learning approaches
By examining the results in Table 2 and Fig. 6, the general trend seen throughout all evaluation metrics is that the two SVM classifiers with different kernel functions and QDA, Gaussian Process, Nearest Neighbors, Neural Net, XgBoost, and Adaboost attain the correct classification rate above 90%. The others followed closely with an average accuracy of 87%. RBF SVM and QDA outperform nine architectures by showing the best results with the smallest variance and average accuracy of 94%.

Visualize the accuracy of most accurate machine learning approaches
Figure 7 illustrates ROC curves of eight learning algorithms with accuracy greater than 90%. Considering the area under the curve, the overall performance of RBF SVM is better than all others, with a percentage of sensitivity and specificity (94.00% and 95.00%). QDA almost equals the sensitivity and specificity values (98.00%, 91.00%), respectively. The SVM with radial basis function kernel classifies the decisions exceptionally efficiently.

Analysis for ROC curves with classifiers (accuracy > 90%) of two decisions (Schizophrenias (SP) and healthy controls (HC))
3.3 Important regions
Our goal was to find the most important brain regions of schizophrenia patients in contrast to healthy subjects. Figure 8 shows graphically the importance of dominant regions where HC region played most dominant role to develop the disease. In addition, revealed regions are used to improve classification. We can see that the hippocampus is the most important region and that BA42 is the least essential region of the brain. BD10 is the closest to the hippocampus, while others are relatively less important. These findings of normalized importance are used further to reducing the dimensionality. We used the standard LASSO approach to remove the low discriminant regions. Table 3 shows the removed regions FT and BD by LASSO.

Bar graph displays the importance (%) of dominated regions (ROIs)
To estimate the impact of the selected nine regions on the performance of classifiers, we repeatedly apply all selected classifiers under the same conditions. After the dimension reduction by LASSO for all N subjects, the SVM classifiers with different kernel functions boosted the final correct classification rate to 93%, as illustrated in Fig. 9. However, the accuracy is, on average, the same when applying all other classifiers. When SVM is used as a learning algorithm, the original input space is mapped into a higher-dimensional feature space in which an optimal separating hyperplane is constructed in order that the distance from the hyperplane to the next data point is maximized. In other words, we can say that a low-dimensional integration of the fMRI successfully extracted the efficient structure involved in the high-dimensional fMRI data and significantly improved the classification accuracy.

Shows the classification performance of linear support vector machine (SVM) and radial base function (RBF)–SVM. The RBF–SVM showed the best classification as compared to linear SVM
4 Discussion
This preliminary study showed that machine learning could extract exciting new information from a brain's schizophrenia activity at rest, improving the current diagnosis and treatment assessment of schizophrenia. We find a data-driven classifier that is based on a low-dimensional integration of the rs-fMRI for discriminating schizophrenia patients and significantly improves the accuracy of the classifier.
Generally, we have found that SVM-based classification is a promising approach to develo** an objective and quantitative assessment of schizophrenic patients. One of the primary contributions of current work was resting-state functional connectivity as a classification feature to differentiate schizophrenic patients from healthy controls. Figure 9 shows the classification performance of linear support vector machine (SVM) and radial base function (RBF)-SVM. The RBF-SVM showed the best classification as compared to linear SVM. The sensitivity of RBF SVM shows in Fig. 7 as well. The current results of resting-state function integration offer an insight into the pathological mechanism of this complex mental disorder. The results also indicate that we achieved better classification accuracy after the dimension reduction embedding of fMRI. The proposed classification framework can extract discriminating information to classify schizophrenia and is potentially useful for identifying diagnostic markers important for schizophrenia. This can be fundamental in schizophrenia pathology research, as our ultimate goal is to develop an imaging diagnostic tool to improve the accuracy of clinical diagnosis and treatment of schizophrenia. The advantage of this study was to differentiate clinically schizophrenia patients from healthy controls at every stage accurately [17, 18].
This study has some notable limitations. Although the classifiers we applied performed well, it was always difficult to generalize these results in clinical applications due to the limited sample size [19–23]. Evaluating the identified classifiers to reproduce these results in a larger sample would be very important. Second, the model trained extensively to improve its performance further.
5 Conclusion
This study successfully classified schizophrenia patients with the endowment of machine learning approaches using the low-dimensional embedding of fMRI. Analysis of the functional connectivity identified that some regions of the patient have a weak connection, such as the hippocampus, occipital lobe, temporal lobe, and BA 9 vice versa to all control regions. This means that brain regions in a healthy control are strongly interconnected compared to regions of schizophrenia patients. We applied the normalized importance method to identify the most important Brian regions of schizophrenia patients. These findings of normalized importance are used further to reduce the dimensionality. We used the LASSO approach to reduce the ratio of features to samples during the development of the classifier. This not only removes non-informative functions but also reduces the likelihood of overfitting. It leads the classifier to focus on informational features. The experimental results showed that our proposed approach achieved very high classification accuracy. We also suggest the strong connections between the brain regions i.e., hippocampus, occipital lobe, temporal lobe, and BA 9 in healthy controls, might play an important role in the explanation of symptoms of schizophrenia.
References
S.R. Sponhei, W.G. Iacono, P.D. Thuras, S.M. Nugent, M. Beiser, Sensitivity and specificity of select biological indices in characterizing psychotic patients and their relatives. Schizophr. Res. 63, 27 (2003)
X. Wang, M. **a, Y. Lai et al., Disrupted resting-state functional connectivity in minimally treated chronic schizophrenia. Schizophr. Res. 156, 150 (2014)
H. Shen, L. Wang, Y. Liu, D. Hu, Discriminative analysis of resting-state functional connectivity patterns of schizophrenia using low dimensional embedding of fMRI. Neuroimage 49, 3110 (2010)
J.D. Gabrieli, S.S. Ghosh, S. Whitfield-Gabrieli, Prediction as a humanitarian and pragmatic contribution from human cognitive neuroscience. Neuron 85, 11 (2015)
C.W. Woo, L.J. Chang, M.A. Lindquist, T.D. Wager, Building better biomarkers: brain models in translational neuroimaging. Nat. Neurosci. 20, 365 (2017)
E.L. Dennis, P.M. Thompson, Functional brain connectivity using fMRI in aging and Alzheimer’s disease. Neuropsychol. Rev. 24, 49 (2014)
D.M. Cole, S.M. Smith, C.F. Beckmann, Advances and pitfalls in the analysis and interpretation of resting-state FMRI data. Front. Syst. Neurosci. 4, 8 (2010)
Y.I. Sheline, M.E. Raichle, Resting state functional connectivity in preclinical Alzheimer’s disease. Biol. Psychiatry. 74, 340 (2013)
T.W. Su, T.H. Lan, T.W. Hsu et al., Reduced neuro-integration from the dorsolateral prefrontal cortex to the whole brain and executive dysfunction in schizophrenia patients and their relatives. Schizophr. Res. 148, 50 (2013)
S.M. Lawrie, C. Buechel, H.C. Whalley, C.D. Frith, K.J. Friston, E.C. Johnstone, Reduced frontotemporal functional connectivity in schizophrenia associated with auditory hallucinations. Biol. Psychiatry. 51, 1008 (2002)
G.D. Honey, E. Pomarol-Clotet, P.R. Corlett et al., Functional dysconnectivity in schizophrenia associated with attentional modulation of motor function. Brain 128, 2597 (2005)
R.L. Bluhm, J. Miller, R.A. Lanius et al., Spontaneous low-frequency fluctuations in the BOLD signal in schizophrenic patients: anomalies in the default network. Schizophr. Bull. 33, 1004 (2007)
J.H. Yoon, M.J. Minzenberg, S. Ursu et al., Association of dorsolateral prefrontal cortex dysfunction with disrupted coordinated brain activity in schizophrenia: relationship with impaired cognition, behavioral disorganization, and global function. Am. J. Psychiatry. 165, 1006 (2008)
S. Guo, C.C. Huang, W. Zhao et al., Combining multi-modality data for searching biomarkers in schizophrenia. PLoS One 13, 2 (2018)
G. Zhang, B.E. Patuwo, M.Y. Hu, Forecasting with artificial neural networks: the state of the art. Int. J. Forecast. 14, 35 (1998)
C. Cortes, V. Vapnik, Support-vector networks. Mach. Learn. 20, 273 (1995)
F. Melgan, L. Bruzzone, Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 42, 1778 (2004)
R. Tibshirani, Regression shrinkage and selection via the lasso. J. R. Stats. Soc. Ser. B (Methodol) 58, 267 (1996)
R. Mohammad, R. Arbabshirani, A. Kent et al., Classification of schizophrenia patients based on resting-state functional network connectivity. Front. Neurosci. 7, 133 (2013)
E. Kirino, S. Tanaka, M. Fukuta et al., Functional connectivity of the caudate in Schizophrenia evaluated with simultaneous resting-state functional MRI and electroencephalography recordings. Neuropsychobiology 77, 165–175 (2019)
P. Rafael, B. Segura, A. Inguanzo et al., Cognitive remediation and brain connectivity: a resting-state fMRI study in patients with schizophrenia. Psychiatr. Res. Neuroimaging 30, 303 (2020)
V. Nina, M.D. William, M. McDonald et al., Neuroimaging biomarkers in Schizophrenia. Psychiatry 6, 509–521 (2021)
W. Yan, M. Zhao, Z. Fua et al., Map** relationships among schizophrenia, bipolar and schizoaffective disorders: a deep classification and clustering framework using fMRI time series. Schizophr. Res. 245, 141–150 (2022)
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. The data are available at open source Brain Multimodality. (https://www.namic.org/wiki/Downloads).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ahmad, F., Ahmad, I. & Guerrero-Sánchez, Y. Classification of schizophrenia-associated brain regions in resting-state fMRI. Eur. Phys. J. Plus 138, 58 (2023). https://doi.org/10.1140/epjp/s13360-023-03687-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjp/s13360-023-03687-x